

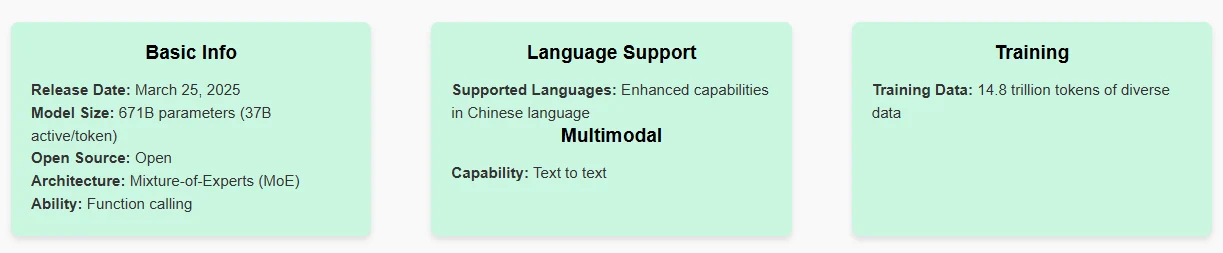
- Llama 4 Maverick vs Deepseek V3 0324: 基本紹介
- Llama 4 Maverick vs Deepseek V3 0324: ベンチマーク
- Llama 4 Maverick vs Deepseek V3 0324: 速度比較
- Llama 4 Maverick vs Deepseek V3 0324: ハードウェア要件
- Llama 4 Maverick vs Deepseek V3 0324: アプリケーション
- Llama 4 Maverick vs Deepseek V3 0324: タスク
- Novita API 経由で Llama 4 Maverick と Deepseek V3 0324 にアクセスする方法
主なハイライト
Llama 4 Maverick は堅牢でモジュール式であり、明確な論理と長いコンテキスト処理を必要とするタスクに特に優れています。
DeepSeek V3 0324 はコードと一般的なQAに非常に効率的で、コンパクトさとリソース節約に優れています。
Novita AI は安定したAPIサービスを提供するだけでなく、非常に費用対効果の高い価格設定も提供しています。たとえば、llama-4-maverickは入力トークン100万あたりわずか$0.17、出力トークン100万あたり$0.85です。一方、deepseek-v3-0324は入力トークン100万あたり$0.33、出力トークン100万あたり$1.3です。
Llama 4 Maverick vs Deepseek V3 0324: 基本紹介
Llama 4 Maverick

Deepseek V3 0324
Llama 4 Maverick vs Deepseek V3 0324: ベンチマーク
| カテゴリ | Llama 4 Maverick | DeepSeek V3 | DeepSeek V3 0324 | Qwen-Max | GPT-4.5 | Claude-Sonnet-3.7 |
|---|---|---|---|---|---|---|
| MMLU-Pro | 80.5% | 75.9% | 81.2% | 76.1% | 86.1% | 80.7% |
| GPQA Diamond | 69.8% | 59.1% | 68.4% | 60.1% | 71.4% | 68.0% |
| LiveCodeBench | 43.4% | 39.2% | 49.2% | 38.7% | 44.4% | 42.2% |
- Llama 4 Maverick は高品質な質問応答でわずかに優れています。
- DeepSeek V3 0324 は一般知識、特にコーディングタスクで優れています。
- 一般知識(MMLU-Pro)の差はごくわずかで、その点では両者はほぼ同等です。
Llama 4 Maverick vs Deepseek V3 0324: 速度比較
自分でテストしたい場合は、Novita AIのウェブサイトで無料トライアルを開始できます。

Llama 4 Maverick と Deepseek V3 0324 のデモを今すぐ試す!
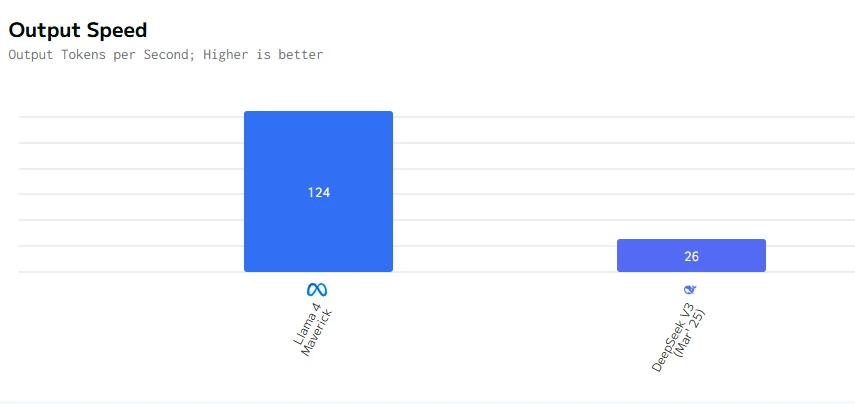
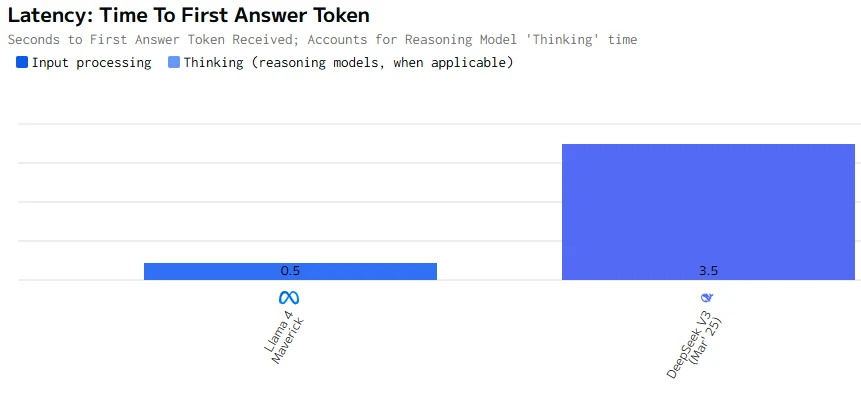
Llama 4 Maverick は出力速度と最初のトークンのレイテンシーの両方で DeepSeek V3 0324 よりもはるかに高速です。速度が重要なインタラクティブなシナリオでは、Llama 4 Maverick が明確な勝者です。
Llama 4 Maverick vs Deepseek V3 0324: ハードウェア要件
| モデル | 推定必要メモリ | GPU構成 | 合計GPUメモリ |
|---|---|---|---|
| DeepSeek V3 0324 | ~1532 GB | 24 × H100 (80 GB) | 1920 GB |
| Llama 4 Maverick | ~18.8 TB | 240 × H100 (80 GB) | 19200 GB |
標準の DeepSeek V3 0324 は、10Mトークンのコンテキストウィンドウで動作する Llama 4 Maverick よりもはるかに少ないGPUリソースを必要とします。ウルトラロングコンテキストモデル(10Mトークンの Llama 4 Maverick など)は、主にKVキャッシュのために、10倍以上の膨大なGPUメモリを必要とします。
Llama 4 Maverick vs Deepseek V3 0324: アプリケーション
Llama 4 Maverick
法務、コンプライアンス、科学文書の検索と分析
- 最大1000万トークンの非常に長いドキュメントを1つのコンテキストで処理でき、すべての情報と関係を保持します。
知識ベースの質問応答
- 大規模な知識ベースからの情報を統合および参照し、マルチドキュメントや複雑なクエリをサポートします。
財務レポート処理
- 長大な財務レポートやアナリストレポートを効率的に分析し、大量のテキストから切り捨てることなく洞察を抽出します。
Deepseek V3 0324
インテリジェントプログラミングアシスタント
- コード生成、コード補完、コード理解タスクに優れており、開発者ツールやIDE統合に最適です。
自動コードレビュー
- コードロジックとスタイルの分析、バグの検出、提案の提供に優れており、コードレビュープロセスを効率化します。
汎用質問応答
- 標準的なコンテキストシナリオで堅牢に動作し、カスタマーサービスボット、エンタープライズ知識アシスタントなどに適しています。
Llama 4 Maverick vs Deepseek V3 0324: タスク
プロンプト:
以下の条件をすべて満たす場合、パスワードは強力とみなされます:
- 少なくとも6文字、最大20文字であること。
- 少なくとも1つの小文字、1つの大文字、1つの数字を含むこと。
- 同じ文字が3つ連続して繰り返されていないこと(例:"Baaabb0" は弱い、"Baaba0" は強い)。
文字列 password が与えられたとき、パスワードを強力にするために必要な最小ステップ数を返してください。すでに強力な場合は0を返します。
1ステップでできること:
- パスワードに1文字挿入する、
- パスワードから1文字削除する、
- パスワードの1文字を別の文字に置き換える。
例1:
入力: password = "a"
出力: 5
例2:
入力: password = "aA1"
出力: 3
例3:
入力: password = "1337C0d3"
出力: 0
制約:
1 <= password.length <= 50
password は英字、数字、ドット '.'、または感嘆符 '!' で構成されます。
Llama 4 Maverick
Deepseek V3 0324
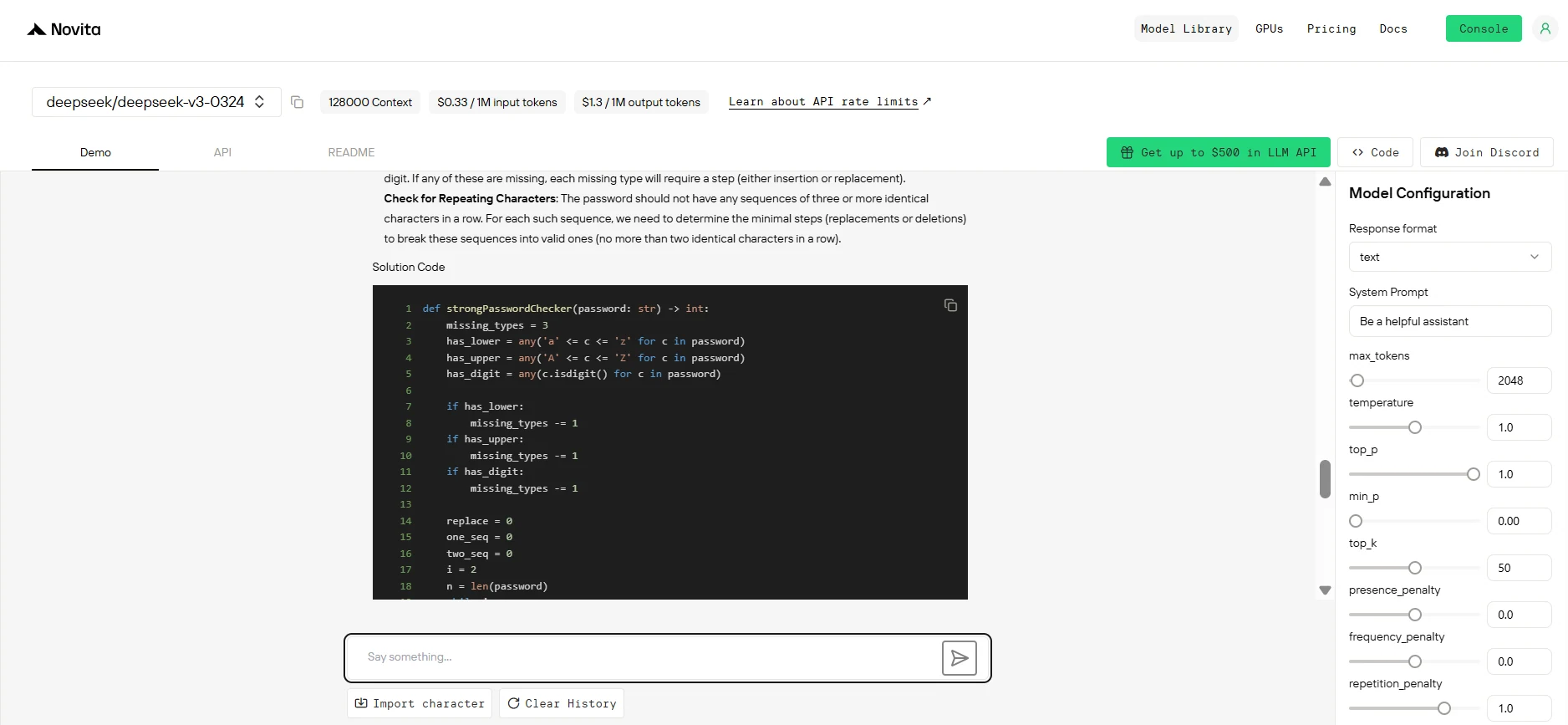
Llama 4 Maverick vs Deepseek v3 0324 タスク比較
llama 4 maverick:
- より堅牢でモジュール式であり、ロジックが明確でエッジケースを明示的に処理します。
- 長いパスワードや繰り返しシーケンスを、より透明性と最適化を備えて処理します。
- 明確さ、保守性、堅牢性が求められるシナリオに適しています。
deepseek v3 0324:
- よりシンプルなケースではよりコンパクトで効率的です。
- 複雑なシナリオも効果的に処理しますが、明確さは劣ります。
- 可読性よりもコンパクトさとパフォーマンスが優先されるシナリオに適しています。
Novita API 経由で Llama 4 Maverick と Deepseek V3 0324 にアクセスする方法
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Library ボタンをクリックします。

Llama 4 Maverick と Deepseek V3 0324 のデモを今すぐ試す!
ステップ 2: モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。
ステップ 3: 無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ 4: API キーを取得
API で認証するために、新しい API キーを提供します。「Settings」ページに入り、画像のように API キーをコピーします。

ステップ 5: API をインストール
プログラミング言語に応じたパッケージマネージャーを使用して API をインストールします。

インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは Python ユーザー向けのチャット完了 API の例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-maverick-17b-128e-instruct-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Llama 4 Maverick と DeepSeek V3 0324 のどちらを選ぶかは、ニーズによって異なります。超長いコンテキストと明確さが必要な場合は、Llama 4 Maverick が際立ちます。効率的なコーディングとコスト効果の高い展開には、DeepSeek V3 0324 が明確な勝者です。どちらのモデルも、それぞれの領域でトップクラスのパフォーマンスを発揮します。
よくある質問
Llama 4 Maverick と DeepSeek V3 0324 の主な違いは何ですか?
Llama 4 Maverick は、長いコンテキスト、高い透明性、速度が重要なタスクに適しています。DeepSeek V3 0324 は、コード関連およびリソース効率の高いシナリオで優れています。
ハードウェア要件は Llama 4 Maverick と DeepSeek V3 0324 でどのように比較されますか?
DeepSeek V3 0324 は、長いコンテキスト長でリソースを大量に消費する Llama 4 Maverick よりもはるかに少ない GPU メモリを必要とします。
法務や研究文書の分析にはどのモデルを選ぶべきですか?
Llama 4 Maverick は、非常に長い入力コンテキストを処理できるため、推奨されます。
*Novita AI *は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、手頃な価格で信頼性の高い GPU クラウドを構築・スケーリングのために提供しています。



