

- Quels problèmes le function calling peut-il résoudre ?
- Qu'est-ce que le function calling ?
- Modèles supportant le function calling
- Comment fonctionne le function calling ?
- Function calling vs. Mode JSON
- Avantages du function calling
- Applications pratiques du function calling
- Comment utiliser Llama 3.3 70B Function Calling via Novita AI
Points clés
Ce qu’il fait : Exécution de récupération de données en temps réel, opérations système et flux de travail automatisés.
Quels modèles le supportent : Llama 3 series, GPT series, Gemma 2, et Mistral nemo.
Comment l’implémenter : Installez les API via Novita AI “Model Library”, puis implémentez avec le framework Langchain.
Le function calling est une technique qui améliore considérablement les capacités des grands modèles de langage (LLM) en leur permettant d’interagir avec le monde extérieur. Au lieu de simplement générer du texte, les LLM peuvent utiliser le function calling pour exécuter des tâches spécifiques, accéder à des informations en temps réel et effectuer des opérations complexes. Cet article explorera le concept du function calling, ses applications pratiques et comment des modèles comme Llama 3.3 70B le rendent plus accessible.
Quels problèmes le function calling peut-il résoudre ?
- Accès à l’information en temps réel
- Vérifier les derniers cours de bourse
- Obtenir les données météo actuelles
- Accéder aux actualités de dernière minute
- Interactions systèmes
- Envoyer des e-mails
- Publier sur les réseaux sociaux
- Interroger et écrire dans des bases de données
- Automatisation des workflows
- Extraction et traitement de données
- Exécution de tâches en plusieurs étapes
- Automatisation d’analyses complexes
- Précision des données
- Assurer l’actualité des informations
- Fournir des résultats de requête précis
- Réduire les erreurs dues à des données obsolètes
Qu’est-ce que le function calling ?
Fondamentalement, le function calling est la capacité d’un LLM à reconnaître quand une tâche spécifique nécessite une fonction ou un outil externe, puis à générer des données structurées (généralement au format JSON) pour exécuter cette fonction. Ces données structurées incluent le nom de la fonction et les arguments nécessaires. Essentiellement, le function calling agit comme un pont entre la vaste connaissance de l’IA et les actions tangibles. Il permet aux agents IA ou chatbots d’effectuer des tâches spécifiques ou d’accéder à des données et services externes.
Modèles supportant le function calling
De nombreux LLM et plateformes supportent désormais le function calling. Vous pouvez installer l’API via la page “Model Library” de Novita AI, et implémenter le function calling via langchain.
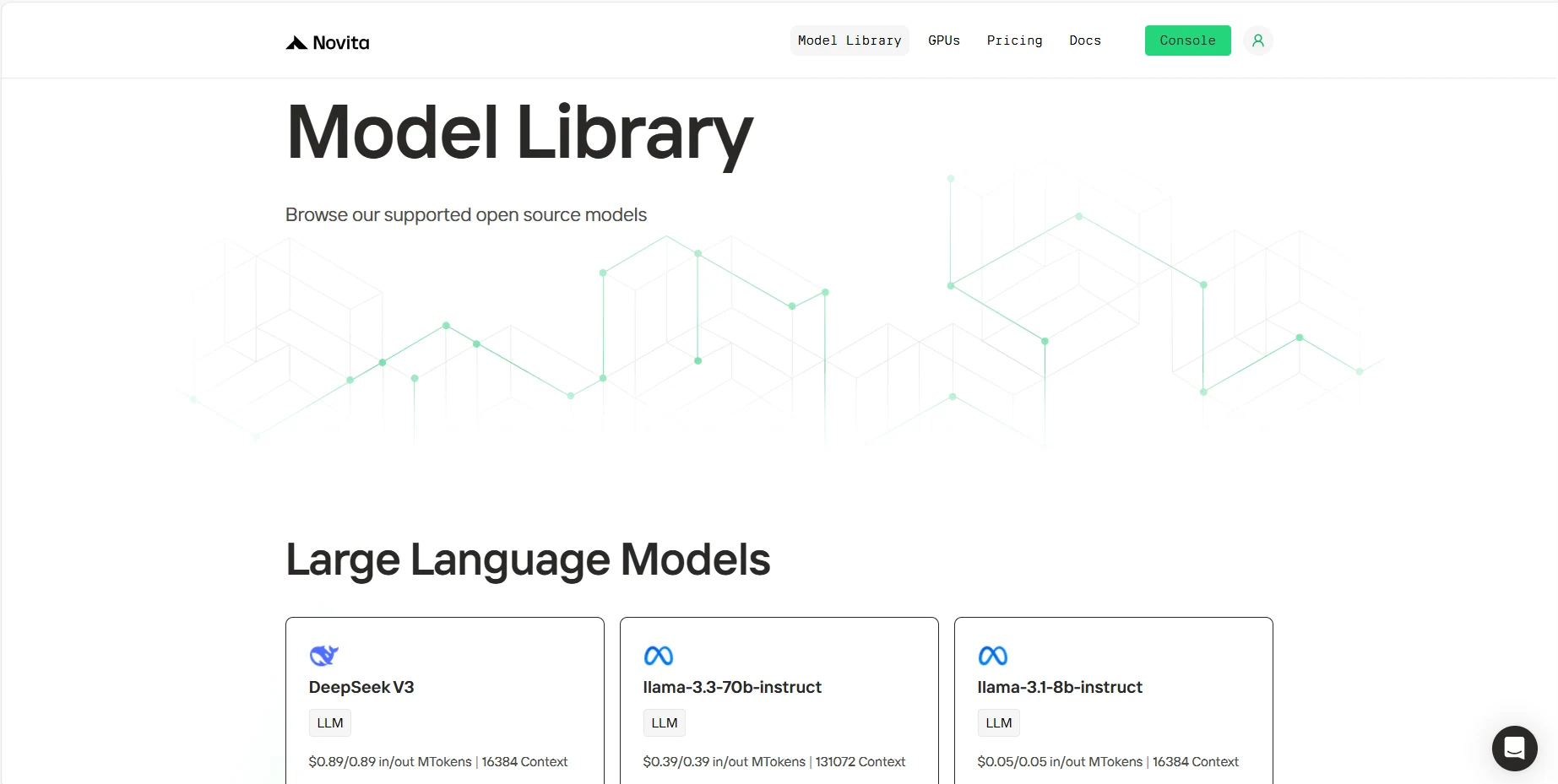
- Llama 3.3 : La version à 70 milliards de paramètres a montré de bonnes performances dans les tests de function calling en identifiant correctement quand et quelles fonctions appeler en fonction des demandes des utilisateurs.
- Mistral : Des modèles comme Mistral-Large-2 démontrent leur succès dans le function calling au sein d’environnements comme watsonx.ai.
- Gemini : Les modèles Gemini de Google supportent également le function calling avec divers exemples d’utilisation disponibles.
Comment fonctionne le function calling ?
- Déclaration de fonction : Le processus commence par la définition de blocs de code réutilisables appelés fonctions, ainsi que des descriptions de leurs capacités, entrées et sorties.
- Soumission de la requête : L’utilisateur soumet une requête au LLM accompagnée d’un ensemble de déclarations de fonctions. Cela informe le modèle des outils disponibles.
- Analyse du modèle : Le LLM analyse la requête et détermine s’il doit invoquer l’une des fonctions fournies pour répondre à la demande.
- Sortie structurée : Si un appel de fonction est nécessaire, le LLM génère une sortie structurée au format JSON comprenant le nom de la fonction et les valeurs de ses paramètres.
- Invocation de la fonction : L’application ou le système utilise cette sortie structurée pour appeler la fonction spécifiée en transmettant les paramètres.
- Exécution de la fonction : Le service externe ou l’API exécute la fonction en utilisant les paramètres fournis.
- Réponse de sortie : Le service externe envoie une confirmation ou un résultat à l’IA.
- Réponse du modèle : Le LLM utilise ensuite cette sortie pour générer une réponse en langage naturel à destination de l’utilisateur ou pour un traitement ultérieur.
- Notez que le modèle n’appelle pas directement la fonction ; c’est plutôt sa sortie structurée qui est utilisée par un programme externe pour le faire.
https://www.youtube.com/watch?v=Qor2VZoBib0
Function calling vs. Mode JSON

Avantages du function calling
- Efficacité accrue : L’appel direct de fonctions réduit les temps de traitement et la latence, ce qui est crucial pour les applications nécessitant une action immédiate.
- Flexibilité renforcée : Les développeurs peuvent facilement mettre à jour ou modifier des fonctions sans refaire toute l’application, permettant des ajustements rapides aux nouvelles exigences.
- Évolutivité : Facilite la scalabilité en permettant d’ajouter de nouvelles fonctions sans modifications importantes de l’infrastructure existante.
- Interactions personnalisées : Permet des expériences utilisateur personnalisées ; par exemple, accéder au calendrier d’un utilisateur pour suggérer des horaires de réunion sans conflit.
- Pont entre l’IA et les actions du monde réel : Permet à l’IA d’effectuer des tâches pratiques comme envoyer des e-mails ou des SMS au nom des utilisateurs.
- Agents conversationnels complexes : Peut créer des chatbots sophistiqués répondant à des questions complexes à l’aide d’API externes et de bases de connaissances.
Applications pratiques du function calling
- Agents conversationnels : Utilisés dans des chatbots avancés qui exploitent des API externes pour des informations actualisées.
- Compréhension du langage naturel : Extraction de données structurées à partir de texte pour des tâches comme la reconnaissance d’entités et l’analyse de sentiments.
- Intégration d’API : Permet aux LLM de s’intégrer à des API externes pour récupérer des données ou effectuer des actions basées sur les entrées utilisateur.
- Assistance financière : Construction de conseillers financiers IA qui accèdent à des données financières en temps réel et fournissent des conseils personnalisés.
- Automatisation des tickets de support : Automatisation de l’affectation des tickets de support en traitant les tickets selon des règles contextuelles.
- Récupération de connaissances : Aide à récupérer des informations à partir de bases de connaissances en créant des fonctions qui résument des articles académiques pour répondre à des questions et fournir des citations.
- Applications multimodales : Déclenchement de fonctions basées sur des images, vidéos, audios et PDF.
Comment utiliser Llama 3.3 70B Function Calling via Novita AI
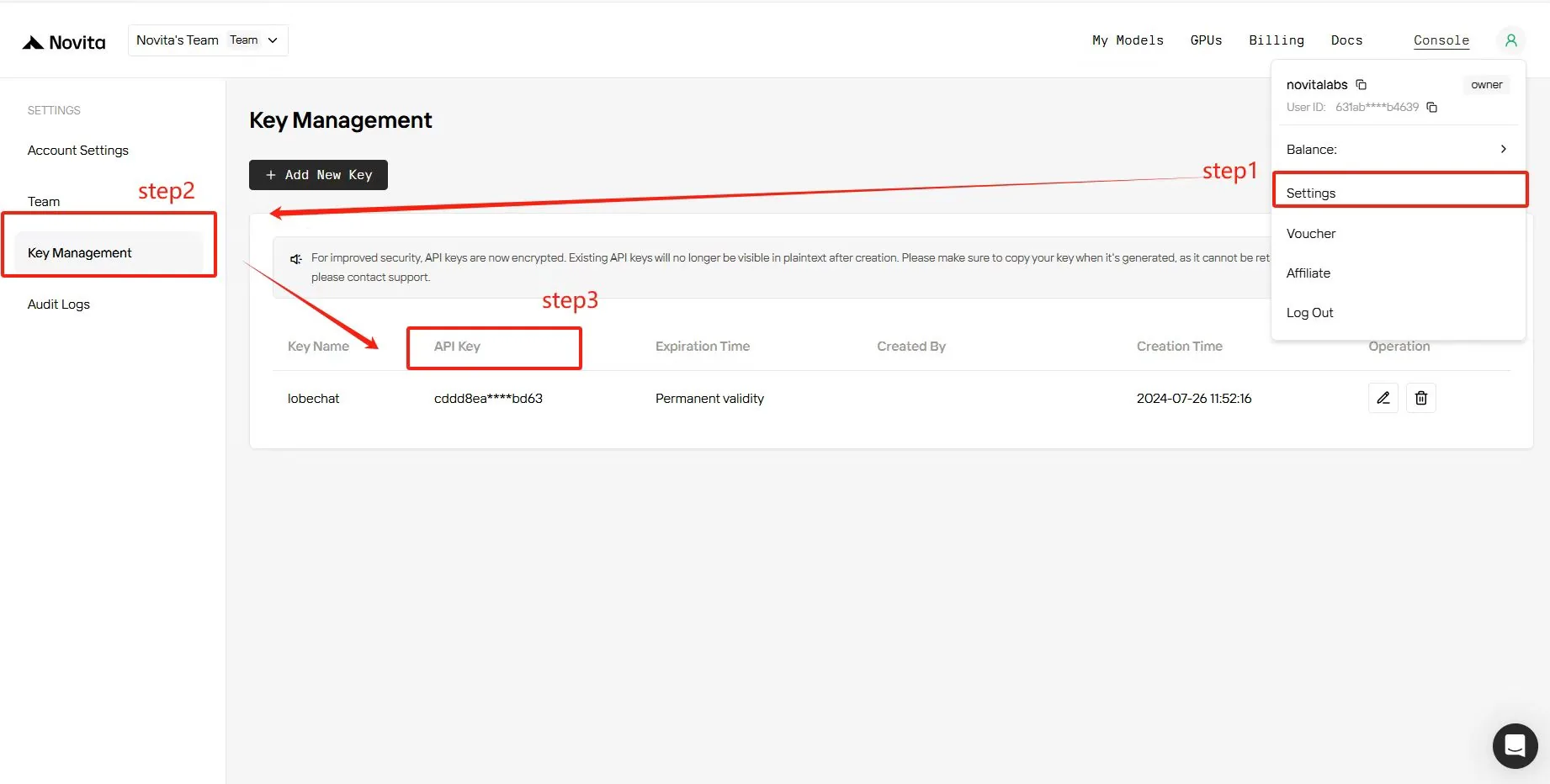
Étape 1 : Obtenir une clé API et l’installer !
Sur la page “Key Management”, vous pouvez copier la clé API comme indiqué dans l’image.
Vous pouvez trouver la page “Model Library” de Novita AI. Installez l’API Novita AI à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Lors de l’inscription, Novita AI vous offre un crédit de 0,5 $ pour démarrer !
Si le crédit gratuit est épuisé, vous pouvez payer pour continuer à l’utiliser.
Étape 2 : Utiliser Langchain pour implémenter le function calling
Nous allons créer une application mathématique simple capable d’effectuer des opérations d’addition et de multiplication.
💡 Bien que ce guide utilise LangChain par commodité, l’implémentation du function calling ne nécessite aucun framework spécifique. La clé réside dans la conception des bons prompts pour que le modèle comprenne et invoque correctement les fonctions. LangChain est utilisé ici simplement pour simplifier l’implémentation.
Prérequis
Commencez par installer les paquets requis :
pip install langchain-openai python-dotenv
Configuration de l’environnement
Créez un fichier .env à la racine de votre projet et ajoutez votre clé API Novita AI :
NOVITA_API_KEY=your_api_key_here
Étapes d’implémentation
1. Définir les outils
Créons deux outils mathématiques simples à l’aide du décorateur @tool de LangChain :
from langchain_core.tools import tool
@tool
def multiply(x: float, y: float) -> float:
"""Multiply two numbers together."""
return x * y
@tool
def add(x: int, y: int) -> int:
"""Add two numbers."""
return x + y
tools = [multiply, add]
2. Créer la fonction d’exécution des outils
Ensuite, implémentez une fonction pour exécuter les outils :
from typing import Any, Dict, Optional, TypedDict
from langchain_core.runnables import RunnableConfig
class ToolCallRequest(TypedDict):
name: str
arguments: Dict[str, Any]
def invoke_tool(
tool_call_request: ToolCallRequest,
config: Optional[RunnableConfig] = None
):
"""Execute the specified tool with given arguments."""
tool_name_to_tool = {tool.name: tool for tool in tools}
name = tool_call_request["name"]
requested_tool = tool_name_to_tool[name]
return requested_tool.invoke(tool_call_request["arguments"], config=config)
3. Configurer le pipeline LangChain
Créez une chaîne qui utilise le LLM de Novita AI pour sélectionner et préparer les appels d’outils :
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.tools import render_text_description
def create_chain():
"""Create a chain that uses the specified LLM model to select and prepare tool calls."""
model = ChatOpenAI(
model="meta-llama/llama-3.3-70b-instruct",
api_key=os.getenv("NOVITA_API_KEY"),
base_url="https://api.novita.ai/v3/openai",
)
rendered_tools = render_text_description(tools)
system_prompt = f"""\
You are an assistant that has access to the following set of tools.
Here are the names and descriptions for each tool:
{rendered_tools}
Given the user input, return the name and input of the tool to use.
Return your response as a JSON blob with 'name' and 'arguments' keys.
The `arguments` should be a dictionary, with keys corresponding
to the argument names and the values corresponding to the requested values.
"""
prompt = ChatPromptTemplate.from_messages(
[("system", system_prompt), ("user", "{input}")]
)
return prompt | model | JsonOutputParser()
4. Créer la fonction de traitement principale
Implémentez la fonction principale qui traite les requêtes mathématiques :
def process_math_query(query: str):
"""Process a mathematical query by using an LLM to select the appropriate tool and execute it."""
chain = create_chain()
message = chain.invoke({"input": query})
result = invoke_tool(message, config=None)
return message, result
5. Exemple d’utilisation
Voici comment utiliser l’implémentation :
if __name__ == "__main__":
message, result = process_math_query(
"meta-llama/llama-3.3-70b-instruct",
"what's 3 plus 1132"
)
print(result) # Output: 1135
En conclusion, le function calling transforme rapidement la manière dont les systèmes IA interagissent avec leur environnement, permettant des applications plus pratiques, efficaces et conviviales. Des modèles comme Llama 3.3 70B ouvrent la voie à un accès plus facile à cette technologie puissante, offrant de nombreuses possibilités pour le développement de l’IA.
Questions fréquentes
Qu’est-ce que le function calling dans le contexte des LLM ?
Le function calling est une technique qui permet aux grands modèles de langage de reconnaître quand une tâche spécifique nécessite une fonction ou un outil externe et de générer des données structurées pour exécuter cette fonction.
Quels sont les principaux avantages de l’utilisation du function calling ?
Les principaux avantages incluent une efficacité accrue dans le traitement des tâches, une flexibilité renforcée pour les développeurs afin de mettre à jour facilement les fonctions, une évolutivité pour ajouter de nouvelles fonctionnalités sans modifications importantes, et des interactions utilisateur personnalisées.
Quelles langues Llama 3.3 supporte-t-il ?
Anglais, français, allemand, hindi, italien, portugais, espagnol et thaï
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



