

Points clés
Gemma 3 27B est un LLM open-source et multimodal publié par Google en mars 2025.
Prend en charge plus de 140 langues avec un nouveau tokeniseur et une fenêtre de contexte de 128K tokens.
Gère les entrées texte et image, produit du texte.
Entraîné sur 14 000 milliards de tokens, excelle en mathématiques, code et suivi d’instructions.
Scores de référence : 1339 Elo, 69,0 (MATH), 67,5 (MMLU-Pro).
Peut fonctionner sur un seul NVIDIA H100 ou être déployé via Ollama (local) ou l’API / GPU Cloud Novita AI.
Gemma 3 27B est un LLM puissant et flexible développé par Google. Il combine portée multilingue, entrée multimodale et hautes performances, ce qui le rend idéal pour diverses charges de travail IA, en local ou dans le cloud.
Qu’est-ce que Gemma 3 27B ?
Caractéristiques notables
- Support multilingue avancé : Grâce à son nouveau tokeniseur, Gemma 3 est très efficace dans plus de 140 langues.
- Entrée multimodale : La capacité de traiter à la fois les images et le texte en fait un outil polyvalent pour une gamme d’applications.
- Fenêtre de contexte étendue : La capacité de 128K tokens permet de gérer des entrées longues et détaillées.
- Open source et convivial pour la communauté : En tant que modèle open source, il encourage l’expérimentation et une large adoption par la communauté.
| Catégorie | Élément | Détails |
|---|---|---|
| Infos de base | Date de publication | 12 mars 2025 |
| Taille du modèle | 27 milliards de paramètres | |
| Open source | Oui (publié par Google) | |
| Support linguistique | Langues multilingues prises en charge | Plus de 140 langues |
| Entraînement | Données d’entraînement | 14 000 milliards de tokens |
| Points forts | Mathématiques, codage, suivi d’instructions | |
| Multimodal | Capacité multimodale | Oui (traite images et texte, produit du texte) |
| Contexte | Fenêtre de contexte | 128K tokens |
| Taille du modèle par précision | bf16 (brut) | Poids : 54,0 Go ; Poids + Cache KV : 72,7 Go |
| INT4 | Poids : 14,1 Go ; Poids + Cache KV : 32,8 Go | |
| INT4 (blocks=32) | Poids : 15,3 Go ; Poids + Cache KV : 34,0 Go | |
| SFP8 | Poids : 27,4 Go ; Poids + Cache KV : 46,1 Go |
Benchmarks de Gemma 3 27B
| Benchmark | Gemma 3 27B | DeepSeek R1 | LLaMA 3.3 70B |
|---|---|---|---|
| Score Elo LMSys | 1339 | ~1360 | ~1260 |
| MMLU-Pro | 67,5 | 84,0 | 66,4 |
| LiveCodeBench | 29,7 | 65,9 | ~29 |
| GPQA Diamond | 42,4 | 71,5 | 50,5 |
| MATH | 69,0 | 97,3 | 77,0 |
Comment accéder à Gemma 3 27B en local ?
Configuration matérielle requise
Gemma 3 27B est décrit comme le “modèle le plus performant que vous puissiez exécuter sur un seul GPU” !
De Google
| Configuration | VRAM nécessaire | Remarques |
|---|---|---|
| Déploiement cloud | Environ 80 Go de VRAM (mono/multi-GPU) | Les GPU A100 ou H100 sont recommandés pour des performances optimales en cloud. Ou RTX 4090 24 Go (x3) |
| Apple Silicon | Gemma 3 4B supporté via mlx-vlm | Gemma 3 4B est disponible dès le premier jour dans mlx-vlm, une bibliothèque open-source pour exécuter des modèles vision-langage sur les appareils Apple Silicon, y compris Mac et iPhone. |
Processus pas à pas pour installer Gemma 3 27B en local
# Étape 0 : Vérifier le GPU NVIDIA
nvidia-smi
# Étape 1 : Mettre à jour les paquets Ubuntu
apt update
# Étape 2 : Installer les dépendances Ollama pour la détection GPU
apt install pciutils lshw
# Étape 3 : Installer Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Étape 4 : Démarrer le serveur Ollama (exécuter dans un terminal et le laisser ouvert)
ollama serve
# Étape 5 : (Dans un nouveau terminal) Vérifier qu'Ollama fonctionne
ollama
# Étape 6 : Installer les modèles Gemma-3 (choisir une option)
# Exécuter Gemma-3 1B
# ollama run gemma3:1b
# Exécuter Gemma-3 4B
# ollama run gemma3:4b
# Exécuter Gemma-3 12B
# ollama run gemma3:12b
# ✅ Recommandé : Exécuter Gemma-3 27B
ollama run gemma3:27b
# Étape 7 : Interagir avec le modèle directement par invite dans la console
# Exemple :
# Vous êtes un analyste de trading basé sur l'IA spécialisé dans les marchés de crypto-monnaies.
# Votre tâche est de concevoir un agent IA autonome capable de prédire les tendances du marché,
# d'exécuter des transactions et de gérer les risques efficacement. Votre réponse doit inclure :
# - Une stratégie pour analyser les données on-chain + off-chain
# - Le choix du modèle pour la prédiction des prix et le sentiment
# - Un extrait de code Python
# - Des méthodes de gestion des risques
# - Des considérations éthiques
Comment accéder à Gemma 3 27B via l’API Novita ?
Étape 1 : Se connecter et accéder à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez la démo de Gemma 3 27B maintenant !
Étape 2 : Démarrer votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 3 : Obtenir votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page “Paramètres”, vous pouvez copier la clé API comme indiqué sur l’image.

Étape 4 : Installer l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "google/gemma-3-27b-it"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Utiliser Gemma 3 27B via Chatbox
Étape 1 : Installer Chatbox
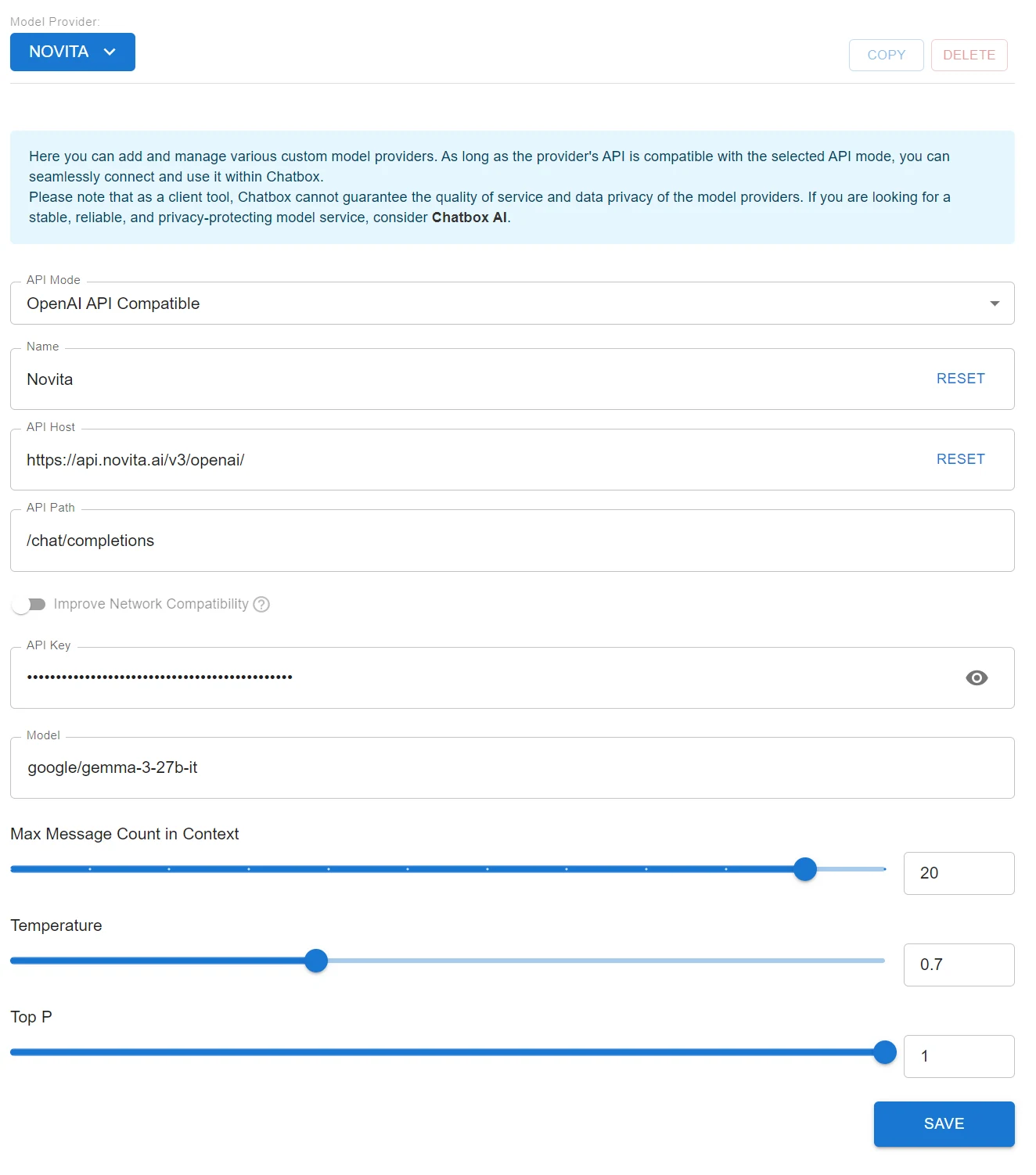
- Sélectionnez l’option “Paramètres”. Ce paramètre garantit la compatibilité avec les API respectant la norme OpenAI API, comme Novita AI.
- Remplissez les champs de configuration :
- URL de base : Entrez
https://api.novita.ai/v3/openai. - Clé API : Collez votre clé API Novita AI ici.
- Nom du modèle : Collez le nom du modèle que vous avez copié précédemment (par exemple,
google/gemma-3-27b-it).
- URL de base : Entrez
- Une fois la configuration remplie, cliquez sur Terminé.
Utiliser Gemma 3 27B via GPU Cloud
Étape 1 : Créer un compte
Si vous êtes nouveau sur Novita AI, commencez par créer un compte sur notre site web. Une fois inscrit, rendez-vous dans l’onglet “GPUs” pour explorer les ressources disponibles et commencer votre parcours.

Étape 2 : Explorer les modèles et les serveurs GPU
Commencez par sélectionner un modèle correspondant aux besoins de votre projet, comme PyTorch, TensorFlow ou CUDA. Choisissez la version qui correspond à vos exigences, par exemple PyTorch 2.2.1 ou CUDA 11.8.0. Ensuite, sélectionnez la configuration de serveur GPU A100, qui offre des performances puissantes pour gérer des charges de travail exigeantes avec une VRAM, une RAM et une capacité de disque importantes.

Essayez les GPU hautes performances de Novita AI
Étape 3 : Personnaliser votre déploiement
Après avoir sélectionné un modèle et un GPU, personnalisez les paramètres de déploiement en ajustant des paramètres comme la version du système d’exploitation (par exemple, CUDA 11.8). Vous pouvez également modifier d’autres configurations pour adapter l’environnement aux besoins spécifiques de votre projet.

Étape 4 : Lancer une instance
Une fois que vous avez finalisé le modèle et les paramètres de déploiement, cliquez sur “Lancer l’instance” pour configurer votre instance GPU. Cela démarrera la configuration de l’environnement, vous permettant de commencer à utiliser les ressources GPU pour vos tâches IA.

Avec des benchmarks solides et des options de déploiement simples, Gemma 3 27B est un choix de premier ordre pour les développeurs et les chercheurs à la recherche d’outils IA ouverts et de haute qualité.
Foire aux questions
Qu’est-ce que Gemma 3 27B ?
Gemma 3 27B est un modèle de langage de grande taille (LLM) open-source de 27 milliards de paramètres développé par Google. Il prend en charge les entrées multimodales (texte + image), plus de 140 langues et dispose d’une fenêtre de contexte de 128K tokens.
Quels sont les besoins matériels pour exécuter Gemma 3 27B en local ?
Vous aurez besoin d’environ 80 Go de VRAM. Un seul NVIDIA H100 est suffisant. Vous pouvez également l’exécuter avec plusieurs RTX 4090 (par exemple, 3×24 Go).
Existe-t-il une version API de Gemma 3 27B ?
Oui ! Vous pouvez accéder à Gemma 3 27B via l’API Novita AI, qui est entièrement compatible avec la norme API OpenAI.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API, tout en fournissant un GPU cloud abordable et fiable pour construire et faire évoluer.
Lecture recommandée
- Pourquoi les besoins en VRAM de LLaMA 3.3 70B sont un défi pour les serveurs domestiques ?
- Qwen 2.5 72b vs Llama 3.3 70b : Quel modèle correspond à vos besoins ?
- Qwen 2.5 vs Llama 3.2 90B : Une analyse comparative des capacités de codage et de raisonnement d’image
API simples et GPU évolutif
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API, tout en fournissant un GPU cloud abordable et fiable pour construire et faire évoluer.



