

ERNIE 4.5 300B A47B Base has officially launched on the Novita AI platform, offering users access to a model that surpasses DeepSeek V3 671B on 22 out of 28 benchmarks. Even compared to top-tier applications like DeepSeek R1, ERNIE 4.5 demonstrates outstanding performance. Even more exciting, the pricing is highly competitive!
| Model Name | Context Length | Input Price | Output Price |
|---|---|---|---|
| ERNIE 4.5 VL 28B A3B | 30k | Free | Free |
| ERNIE 4.5 VL 424B A47B | 123k | $0.42 / 1M tokens | $1.25 / 1M tokens |
| ERNIE 4.5 0.3B | 120k | Free | Free |
| ERNIE 4.5 21B A3B | 120k | Free | Free |
| ERNIE 4.5 300B A47B Paddle | 123k | $0.30 / 1M tokens | $1.00 / 1M tokens |
| DeepSeek R1 0528 | 163k | $0.70 / 1M tokens | $2.50 / 1M tokens |
| DeepSeek V3 0324 | 163k | $0.28 / 1M tokens | $1.14 / 1M tokens |
But does this price drop mean that the hardware requirements—especially VRAM—are also reduced? Or does running such a powerful model still demand significant resources? In the following sections, we’ll break down exactly how much VRAM ERNIE 4.5 requires natively.
ERNIE Model Family
| Model Name | Base Parameters | Active Parameters | Model Type | Modality | Training Type |
|---|---|---|---|---|---|
| ERNIE 4.5 VL 424B A47B | 424B | 47B | MoE | Text & Vision | PT |
| ERNIE 4.5 VL 424B A47B Base | 424B | 47B | MoE | Text & Vision | Base |
| ERNIE 4.5 VL 28B A3B | 28B | 3B | MoE | Text & Vision | PT |
| ERNIE 4.5 VL 28B A3B Base | 28B | 3B | MoE | Text & Vision | Base |
| ERNIE 4.5 300B A47B | 300B | 47B | MoE | Text | PT |
| ERNIE 4.5 300B A47B Base | 300B | 47B | MoE | Text | Base |
| ERNIE 4.5 21B A3B | 21B | 3B | MoE | Text | PT |
| ERNIE 4.5 21B A3B Base | 21B | 3B | MoE | Text | Base |
| ERNIE 4.5 0.3B | 0.3B | - | Dense | Text | PT |
| ERNIE 4.5 0.3B Base | 0.3B | - | Dense | Text | Base |
Innovations of the ERNIE Family
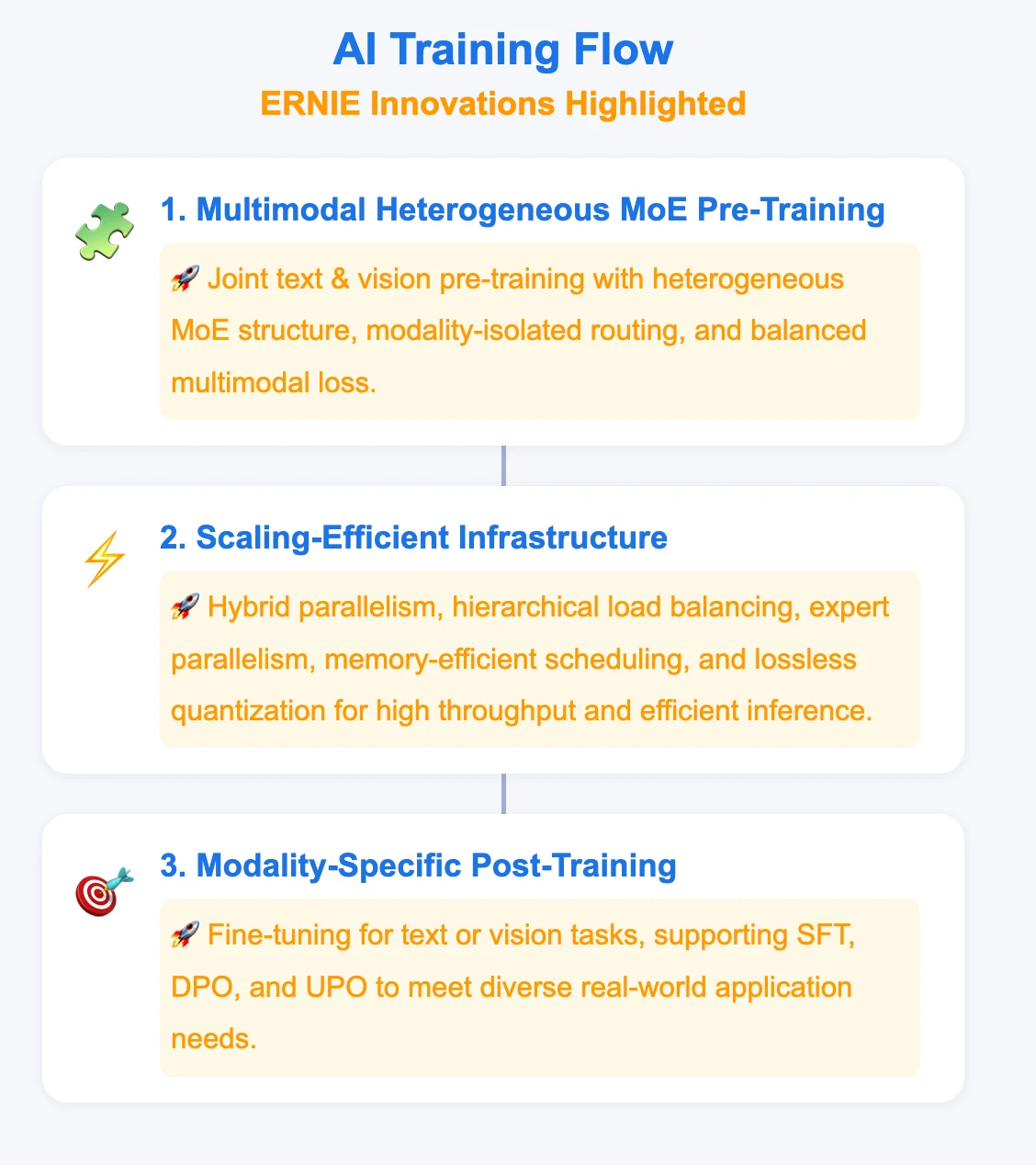
Excellent Performance of ERNIE Family
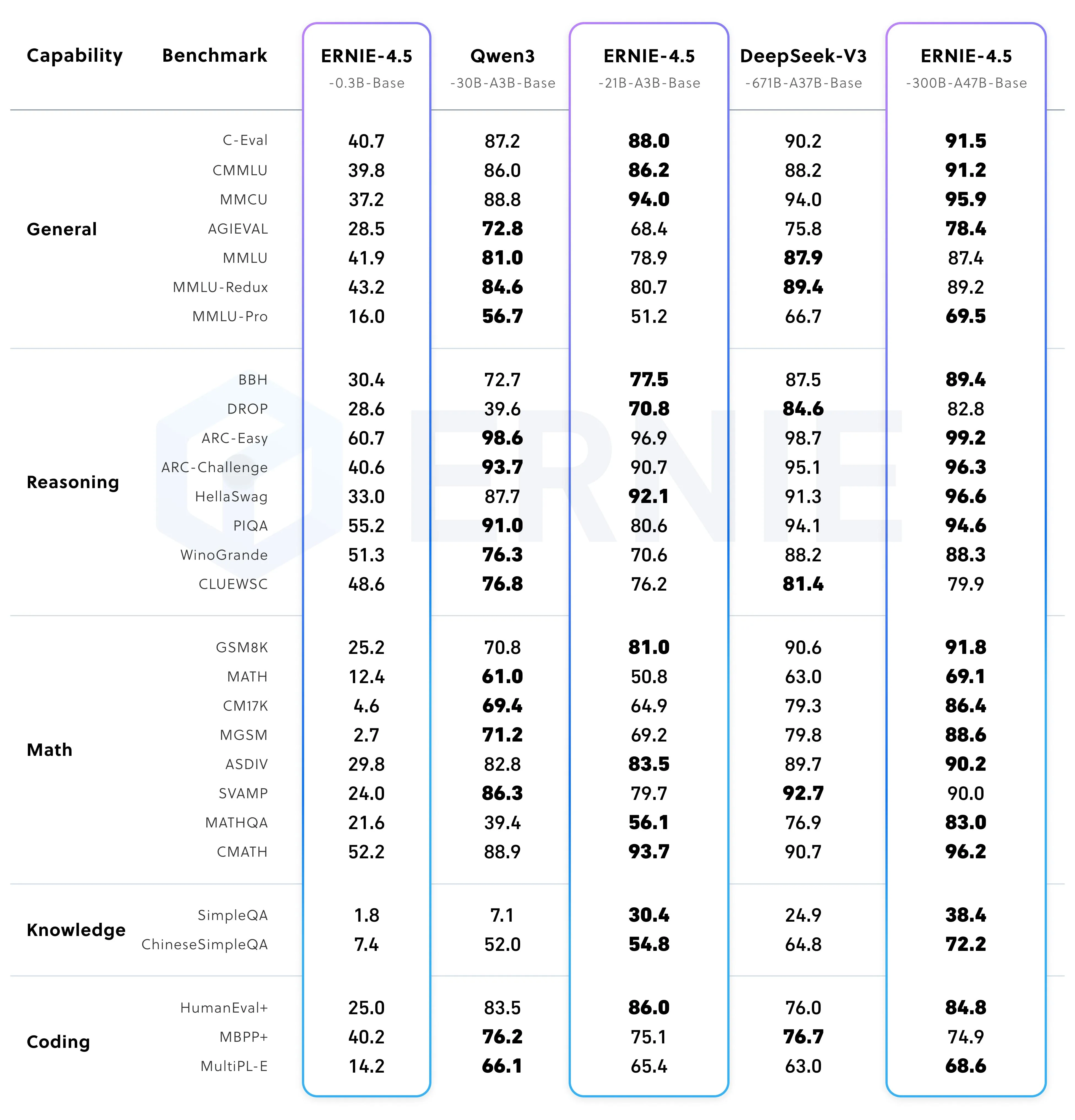
Performance of ERNIE 4.5 pre-trained models
- General: ERNIE 4.5 21B A3B Base and 300B A7B Base outperform in some C - Eval, CMMU, etc. Qwen3 30B A3B Base is strong in others.
- Reasoning: Qwen3 30B A3B Base leads in ARC series; ERNIE 4.5 21B A3B Base is good in BBH, Drop.
- Math: ERNIE 4.5 21B A3B Base and 300B A7B Base excel in parts like GSM8K, CMATH; Qwen3 30B A3B Base has strengths too.
- Knowledge: ERNIE 4.5 21B A3B Base does well in SimpleQA, ChineseSimpleQA.
- Coding: ERNIE 4.5 21B A3B Base and 300B A7B Base are competitive in HumanEval+, MultiPLE.
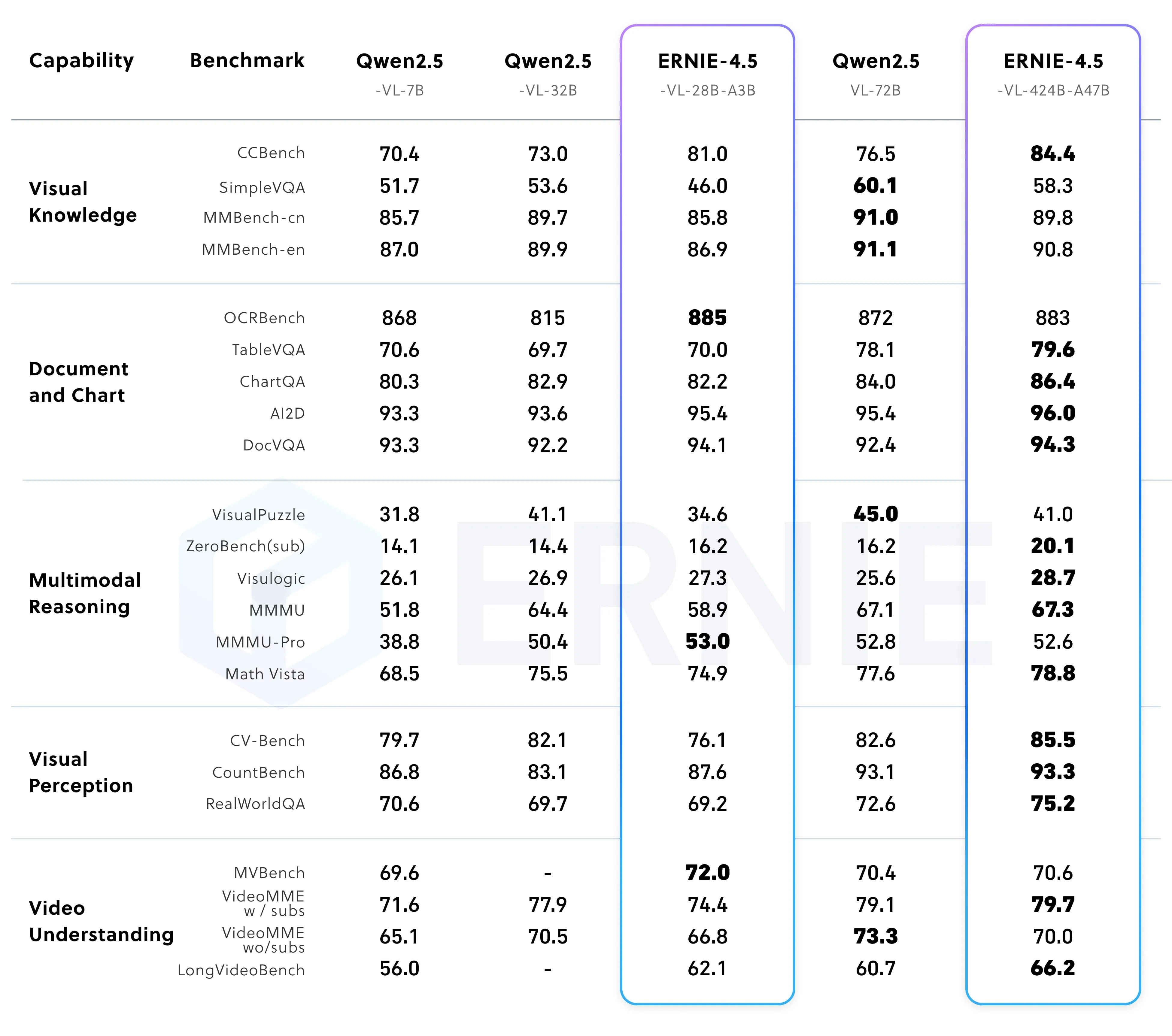
Performance of post-trained multimodal models in non-thinking mode
Qwen2.5
- Strengths: Excels in basic visual QA, some multimodal reasoning, and light video tasks. Strong in MMBench cn/en.
- Weaknesses: Struggles with complex document/chart tasks, deep multimodal reasoning, and detailed visual perception. Less capable in subtitle - based video understanding.
ERNIE 4.5
- Strengths: Dominates complex document/chart tasks, deep multimodal reasoning, precise visual perception and subtitle - video understanding. Strong overall in multi - modal complexity.
- Weaknesses: Less competitive in basic visual QA and simple video tasks.
So, How Much VRAM Does ERNIE Need?
🚀 FP16 Precision
| Model | Parameters (Active) | VRAM Needed | Ideal GPU(s) |
|---|---|---|---|
| ERNIE 4.5 VL 424B | 424B (47B active) | ~945 GB | NVIDIA H100 (80GB) × 12 |
| ERNIE 4.5 300B | 300B (47B active) | ~668 GB | NVIDIA H100 (80GB) × 9 |
| ERNIE 4.5 VL 28B | 28B (3B active) | ~64 GB | NVIDIA A100/H100 (80GB) |
| ERNIE 4.5 21B | 21B (3B active) | ~48 GB | NVIDIA RTX 6000 Ada (48GB) |
| ERNIE 4.5 0.3B | 300M | ~2.5 GB | NVIDIA RTX 4060 (8GB) / RTX 3060 (12GB) |
| Gemma 3 27B | 27B | ~65.2 GB | NVIDIA A100/H100 (80GB) |
⚡ INT4 Precision
| Model | Parameters (Active) | VRAM Needed | Ideal GPU(s) |
|---|---|---|---|
| ERNIE 4.5 VL 424B | 424B (47B active) | ~237 GB | NVIDIA H100 (80GB) × 3 |
| ERNIE 4.5 300B | 300B (47B active) | ~168 GB | NVIDIA H100 (80GB) × 3 |
| ERNIE 4.5 VL 28B | 28B (3B active) | ~17 GB | NVIDIA RTX 4090 (24GB) / A10G (24GB) |
| ERNIE 4.5 21B | 21B (3B active) | ~13 GB | NVIDIA RTX 4080 (16GB) / A10G (24GB) |
| ERNIE 4.5 0.3B | 300M | ~1.8 GB | Most GPUs with >4GB VRAM |
| Gemma 3 27B | 27B | ~14.1 GB | Any high-end GPU with ≥16GB VRAM |
The Downsides of High VRAM Requirements & Practical Tips
High VRAM requirements pose several challenges for users. First, hardware costs can skyrocket—top-tier GPUs like the NVIDIA H100 are expensive and often require multi-GPU clusters to run the largest models, making them unaffordable for individuals or small organizations. Second, power consumption and heat generation increase with more GPUs, leading to higher operational costs and more complex cooling solutions. Third, such setups can be difficult to maintain, requiring technical expertise in hardware, distributed computing, and software configuration.
These challenges can also limit accessibility: many researchers, developers, and enthusiasts simply don’t have access to the necessary infrastructure, which can slow innovation and experimentation.
Tips for Overcoming High VRAM Demands:
- Use Quantized Models: Opt for INT4 or other compressed/quantized versions to significantly reduce VRAM needs, often with minimal impact on performance for many tasks.
- Cloud Solutions: Consider using cloud platforms that allow you to rent high-end GPUs only when needed, rather than investing in expensive hardware.
- Model Offloading & Streaming: Use tools or platforms that support model offloading, splitting, or streaming, so that not all data must reside in GPU VRAM at once.
Novita AI: Access ERNIE with 0 VRAM Required
Getting started with ERNIE 4.5 on Novita AI is streamlined and risk-free.
New users receive $10 in free credits—sufficient to explore ERNIE 4.5 without upfront costs.
Use the Playground (No Coding Required)
- Instant Access: Sign up, claim your free credits, and start experimenting with ERNIE 4.5 and other top models in seconds.
- Interactive UI: Test prompts, chain-of-thought reasoning, and visualize results in real time.
- Model Comparison: Effortlessly switch between ERNIE 4.5, Qwen 3, Llama 4, DeepSeek, and more to find the perfect fit for your needs.
Integrate via API (For Developers)
Seamlessly connect ERNIE 4.5 to applications, workflows, or chatbots using Novita AI’s unified REST API. No model weight management or infrastructure concerns—Novita AI provides multi-language SDKs and advanced parameter controls.
1.Direct API Integration (Python Example)
curl "https://api.novita.ai/v3/openai/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer " \
-d @- << 'EOF'
{
"model": "baidu/ernie-4.5-300b-a47b-paddle",
"messages": [
{
"role": "system",
"content": Be a helpful assistant
},
{
"role": "user",
"content": "Hi there!"
}
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "baidu/ernie-4.5-300b-a47b-paddle"
stream = True # or False
max_tokens = 6000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
"response_format": { "type": "text" },
"max_tokens": 32768,
"temperature": 1,
"top_p": 1,
"min_p": 0,
"top_k": 50,
"presence_penalty": 0,
"frequency_penalty": 0,
"repetition_penalty": 1
}
EOF
2.Multi-Agent Workflows with OpenAI Agents SDK
Build advanced multi-agent systems by integrating Novita AI with the OpenAI Agents SDK:
- Plug-and-play: Use Novita AI’s RNIE 4.5 in any OpenAI Agents workflow
- Supports handoffs, routing, and tool use: Design agents that can delegate, triage, or run functions, all powered by RNIE 4.5’s capabilities
- Python integration: Simply point the SDK to Novita’s endpoint (
https://api.novita.ai/v3/openai) and use your API key
Connect ERNIE 4.5 API on Third-Party Platforms
-
Hugging Face: Use QERNIE 4.5 in Spaces, pipelines, or with the Transformers library via Novita AI endpoints.
-
Agent & Orchestration Frameworks: Easily connect Novita AI with partner platforms like Continue, AnythingLLM, LangChain, Dify and Langflow through official connectors and step-by-step integration guides.
-
OpenAI-Compatible API: Enjoy hassle-free migration and integration with tools such as Cline and Cursor, designed for the OpenAI API standard.
Even though running ERNIE 4.5 on your own hardware would need very powerful (and expensive) GPUs, Novita AI lets you use these large models easily, with zero VRAM required on your side. This makes advanced AI accessible to everyone, from beginners to developers.
Frequently Asked Questions
Is ERNIE 4.5 really better than other big AI models?
Yes, ERNIE 4.5 scores higher than DeepSeek V3 671B in most benchmarks and is very competitive with other top models.
Can ERNIE 4.5 be used for coding and math tasks?
Yes, ERNIE 4.5 models perform well in coding (like HumanEval+) and math benchmarks (like GSM8K, CMATH).
How much VRAM do I need to run ERNIE 4.5?
Running the largest versions of ERNIE 4.5 (like 424B or 300B) requires very high VRAM—hundreds of GBs and multiple high-end GPUs. Smaller or quantized versions need much less VRAM.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



