

Die hochmodernen Qwen-3-Sprachmodelle von Alibaba sind jetzt live auf der Novita AI Model API-Plattform!
Hier ist das aktuelle Qwen-3-Lineup und die Preisgestaltung auf Novita AI:
- Qwen3-235B-A22B: 0,20 $/M Input-Token, 0,80 $/M Output-Token
- Qwen3-30B-A3B: 0,10 $/M Input-Token, 0,45 $/M Output-Token
- Qwen3-32B: 0,10 $/M Input-Token, 0,45 $/M Output-Token
- Qwen3-14B: 0,07 $/M Input-Token, 0,275 $/M Output-Token
- Qwen3-8B: 0,035 $/M Input-Token, 0,138 $/M Output-Token
- Qwen3-4B: kostenlos
- Qwen3-1.7B: kostenlos
Betreiben Sie Ihre Chatbots, Apps und Workflows mit modernsten Sprachmodellen – Qwen 3 ist nur einen API-Aufruf entfernt.
Was ist Qwen 3?
Qwen 3 ist die neueste und fortschrittlichste Familie großer Sprachmodelle, die vom Qwen-Team von Alibaba Cloud entwickelt wurde. Aufbauend auf den Erfahrungen mit QwQ und Qwen2.5 setzt Qwen 3 mit wesentlichen Verbesserungen bei logischem Denken, Mehrsprachigkeit und agentischen Fähigkeiten einen neuen Standard für Open-Source-KI.
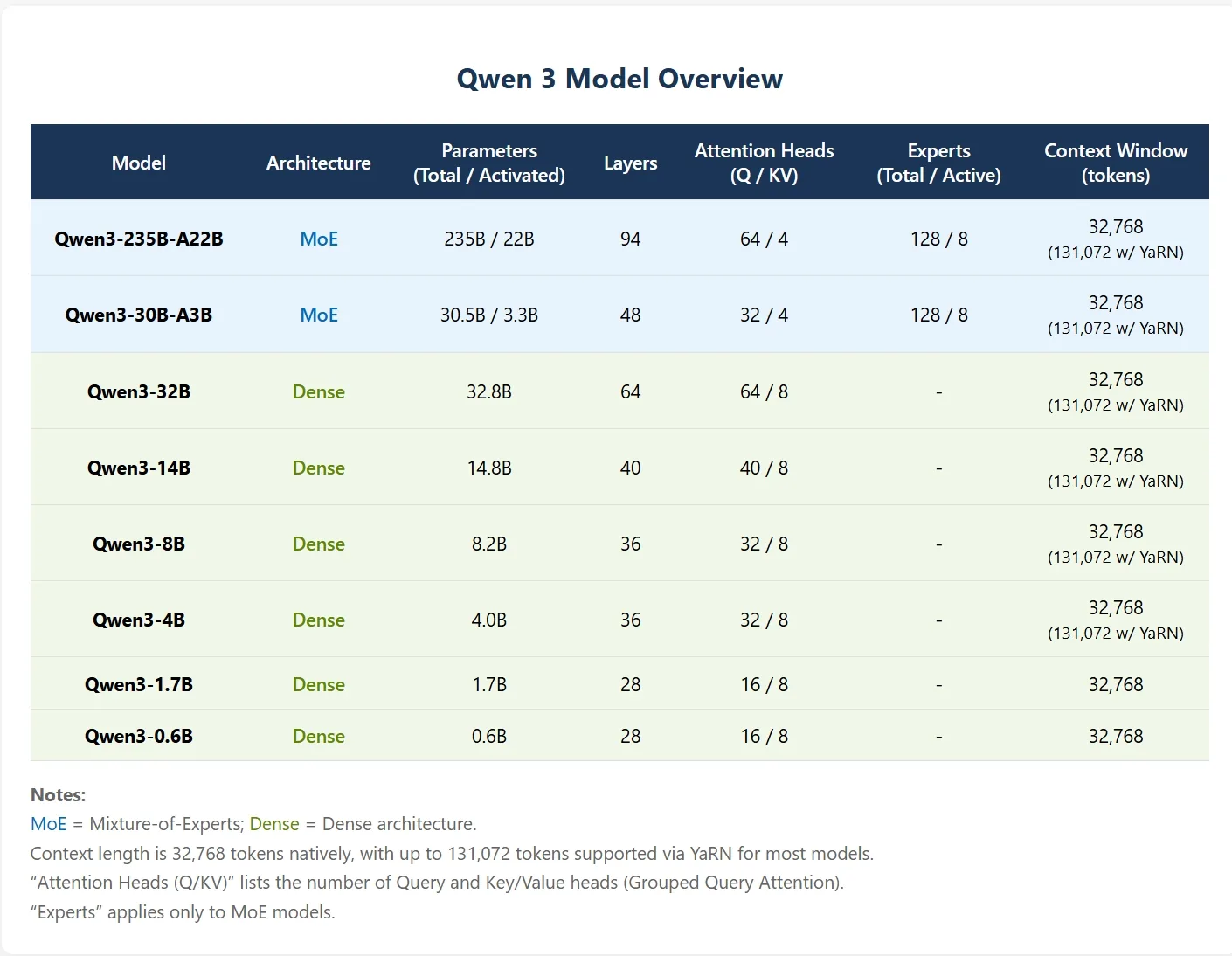
Wichtige Funktionen von Qwen 3
- Dichte Modelle und Mixture-of-Experts (MoE) in verschiedenen Größen: Qwen 3 ist sowohl in dichten als auch in MoE-Architekturen verfügbar, von leichten 0,6B- und 1,7B-Modellen bis hin zu groß angelegten 32B (dicht) und den Flaggschiff-Varianten 30B-A3B und 235B-A22B (MoE).
- Hybride Denkmodi: Das Modell ermöglicht ein nahtloses Umschalten zwischen dem Denkmodus (für komplexes, schrittweises logisches Denken, Mathematik und Codegenerierung) und dem Nicht-Denkmodus (für schnelle, effiziente, allgemeine Unterhaltungen).
- Deutlich verbesserte Denkfähigkeit: Qwen 3 übertrifft frühere Qwen-Modelle in Mathematik, Codegenerierung und allgemeinem logischen Denken. Es bietet außerdem stabilere und steuerbare Denkbudgets für verschiedene Aufgaben.
- Hervorragende Ausrichtung auf menschliche Präferenzen: Das Modell zeichnet sich durch kreatives Schreiben, Rollenspiele, Multi-Turn-Dialoge und Befolgung von Anweisungen aus, was zu natürlicheren und ansprechenderen Gesprächen führt.
- Fortschrittliche agentische Fähigkeiten: Qwen 3 wurde für agentenbasierte Workflows entwickelt und unterstützt die nahtlose Integration mit externen Tools und präzisen Funktionsaufrufen in beiden Denkmodi. Dies ermöglicht eine hochmoderne Leistung bei komplexen, agentengesteuerten Aufgaben.
- Robuste mehrsprachige Unterstützung: Mit Unterstützung für 119 Sprachen und Dialekte ist Qwen 3 in der Lage, mehrsprachige Anweisungen hochwertig zu befolgen und zu übersetzen, was die Tür zu wirklich globalen Anwendungen öffnet.

Benchmarks und Leistung
Die Qwen-3-Serie demonstriert branchenführende Leistung in einer umfassenden Reihe von KI-Benchmarks und zeichnet sich in den Bereichen Programmierung, Mathematik, allgemeines Denken und mehrsprachiges Verständnis aus.
Flaggschiff-Modell: Qwen3-235B-A22B
Das Flaggschiff-Modell Qwen3-235B-A22B erzielt im Vergleich mit den derzeit fortschrittlichsten Modellen wie DeepSeek-R1, OpenAI-01, OpenAI-o3-mini, Grok-3 Beta und Gemini-2.5-Pro durchweg Spitzen- oder nahezu Spitzenergebnisse.
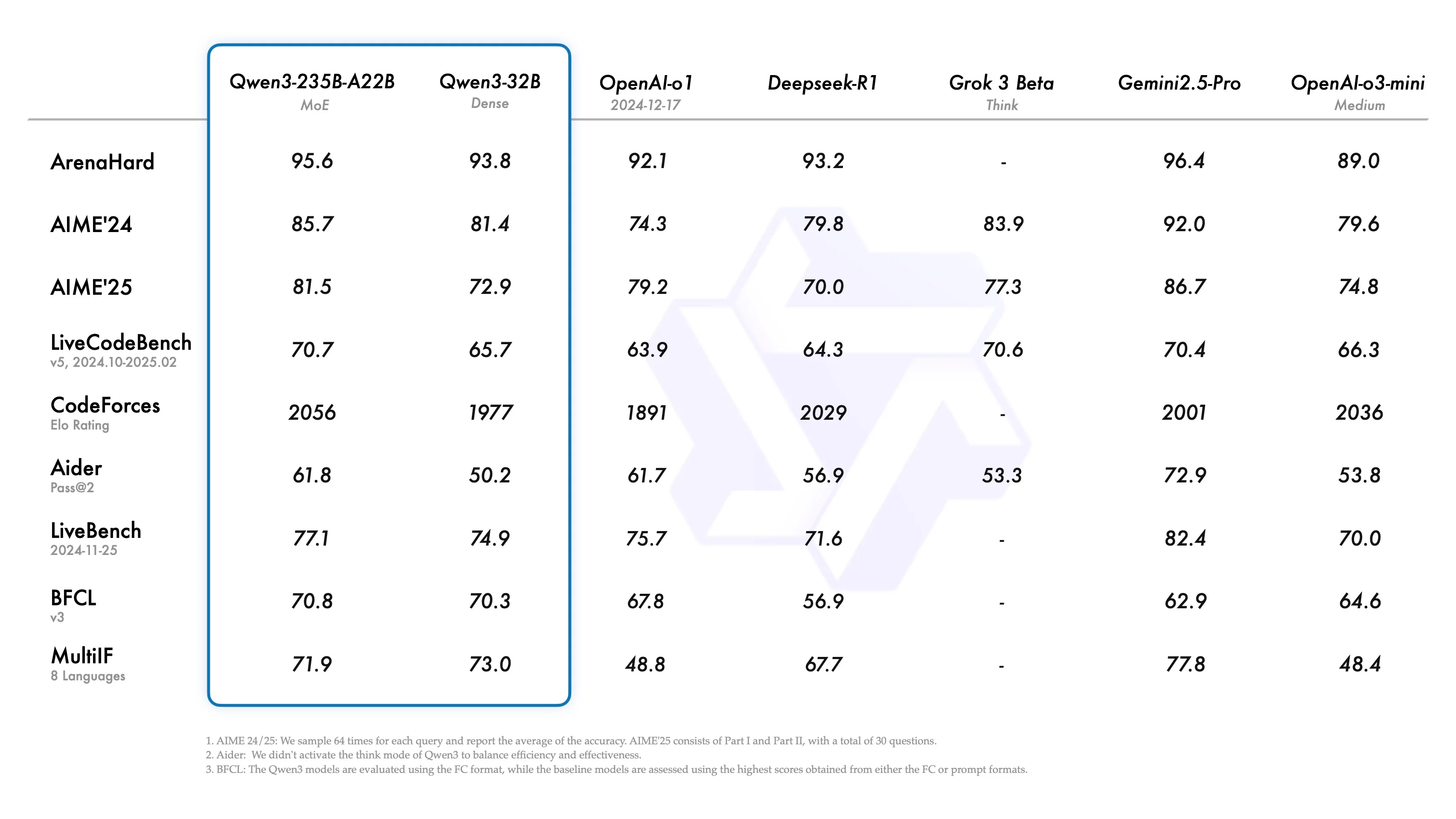
Quelle: Qwen
- Komplexes Denken: Höchste Punktzahlen auf ArenaHard (95,6), übertrifft oder erreicht alle Mitbewerber.
- Mathematik: Führende Ergebnisse bei AIME’24 (85,7) und AIME’25 (81,5), deutlich vor den meisten kommerziellen und Open-Source-Modellen.
- Programmierung: Außergewöhnliche Leistung bei LiveCodeBench (70,7) und CodeForces Elo (2056), was seine Stärke bei Software- und algorithmischen Aufgaben bestätigt.
- Mehrsprachige & allgemeine Fähigkeiten: Qwen3-235B-A22B erzielt starke Ergebnisse bei LiveBench und MultiF, was ein robustes reales und mehrsprachiges Verständnis demonstriert.
Andere kleinere Modelle
Die architektonischen Innovationen von Qwen 3 führen auch bei kleineren Modellgrößen zu herausragender Leistung:
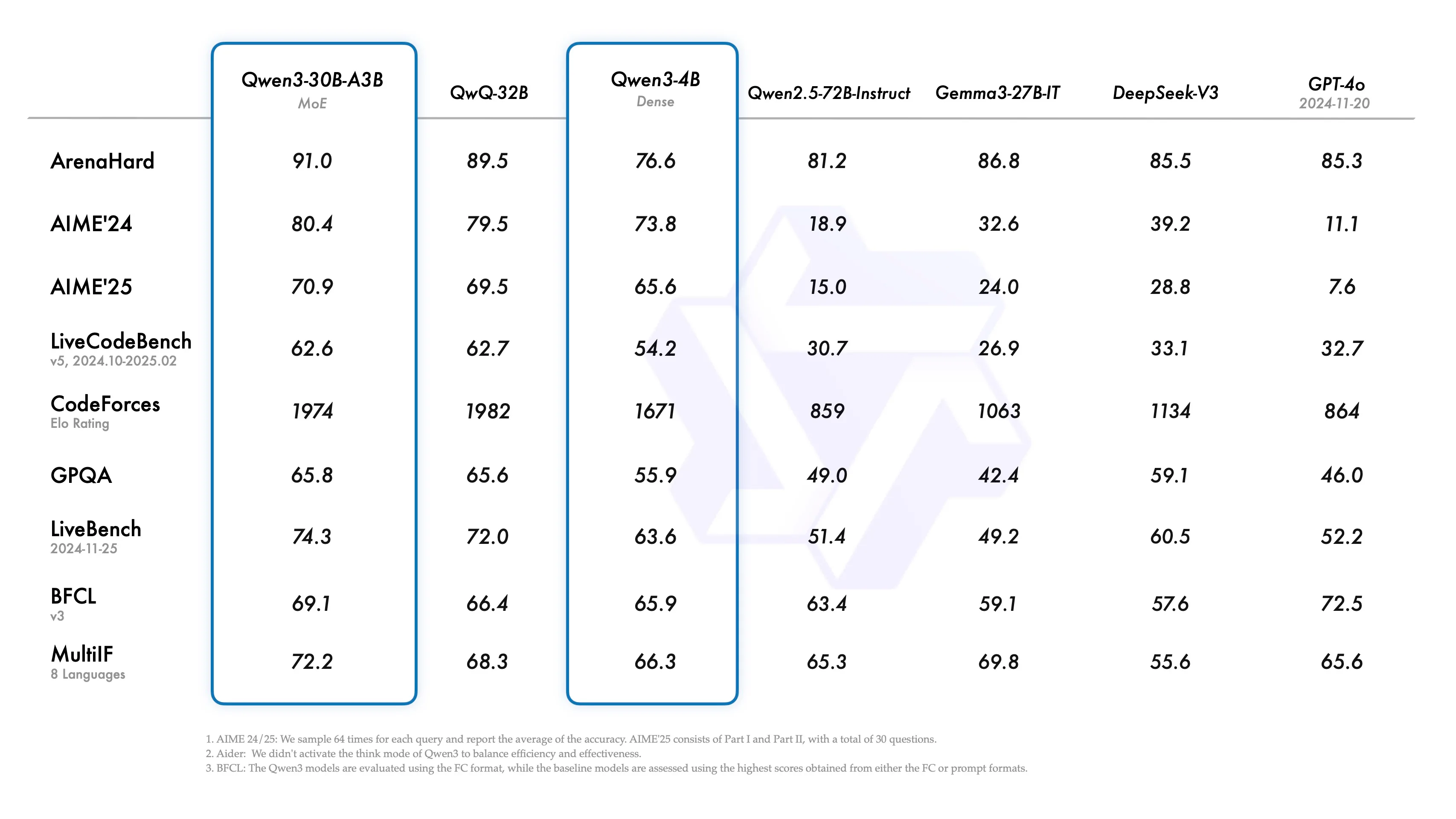
Quelle: Qwen
- Qwen3-32B (dicht): Liefert Ergebnisse knapp hinter dem Flaggschiff und übertrifft dennoch die meisten alternativen Modelle in allen Kategorien.
- Qwen3-30B-A3B (MoE): Übertrifft QwQ-32B, obwohl nur ein Zehntel der aktivierten Parameter verwendet wird – ein Beispiel für die Effizienz und intelligente Skalierung von Qwen.
- Qwen3-4B (dicht): Selbst dieses kompakte Modell kann mit der Leistung viel größerer Modelle wie Qwen2.5-72B-Instruct mithalten, insbesondere bei Denk- und mehrsprachigen Aufgaben.
So greifen Sie auf Qwen 3 auf Novita AI zu
Der Einstieg in Qwen 3 ist auf Novita AI schnell, einfach und risikofrei. Dank des Empfehlungsprogramms erhalten Sie $10 kostenlose Credits – genug, um die Leistungsfähigkeit von Qwen 3 vollständig zu erkunden, Prototypen zu erstellen und sogar Ihren ersten Anwendungsfall ohne Vorabkosten zu starten.
Nutzen Sie den Playground (keine Programmierkenntnisse erforderlich)
- Sofortiger Zugriff: Registrieren Sie sich, beanspruchen Sie Ihre kostenlosen Credits und experimentieren Sie in Sekundenschnelle mit Qwen 3 und anderen Top-Modellen.
- Interaktive Benutzeroberfläche: Testen Sie Prompts, Gedankenkettenlogik und visualisieren Sie Ergebnisse in Echtzeit.
- Modellvergleich: Wechseln Sie mühelos zwischen Qwen 3, Llama 4, DeepSeek und mehr, um die perfekte Lösung für Ihre Anforderungen zu finden.
Integration über API (für Entwickler)
Verbinden Sie Qwen 3 nahtlos mit Ihren Anwendungen, Workflows oder Chatbots über die einheitliche REST-API von Novita AI – ohne dass Sie Modellgewichte oder Infrastruktur verwalten müssen. Novita AI bietet mehrsprachige SDKs (Python, Node.js, cURL und mehr) sowie erweiterte Parametersteuerungen für Power-User.
Option 1: Direkte API-Integration (Python-Beispiel)
Verwenden Sie einfach das folgende Code-Snippet, um loszulegen:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen3-235b-a22b-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Hauptmerkmale:
- Einheitlicher Endpunkt:
/v3/openaiunterstützt das Chat Completions API-Format von OpenAI. - Flexible Steuerung: Passen Sie Temperatur, Top-p, Strafen und mehr an, um maßgeschneiderte Ergebnisse zu erzielen.
- Streaming & Batch-Verarbeitung: Wählen Sie den gewünschten Antwortmodus.
Option 2: Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agent-Systeme, indem Sie Novita AI mit dem OpenAI Agents SDK integrieren:
- Plug-and-Play: Verwenden Sie die LLMs von Novita AI in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwickeln Sie Agents, die Aufgaben delegieren, priorisieren oder Funktionen ausführen können – alle angetrieben von Novita AIs Modellen.
- Python-Integration: Richten Sie das SDK einfach auf den Endpunkt von Novita (
https://api.novita.ai/v3/openai) und verwenden Sie Ihren API-Key.
Verbinden Sie die Qwen 3 API auf Drittanbieter-Plattformen
- Hugging Face: Verwenden Sie Qwen 3 in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
- Agent- & Orchestrierungs-Frameworks: Verbinden Sie Novita AI problemlos mit Partnerplattformen wie Continue, AnythingLLM, LangChain, Dify und Langflow über offizielle Konnektoren und Schritt-für-Schritt-Integrationsleitfäden.
- OpenAI-kompatible API: Genießen Sie eine problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard entwickelt wurden.
Best Practices für optimale Qwen 3 Leistung
- Einstellungen der Sampling-Parameter
Denkmodus
enable_thinking=True
Temperatur: 0.6
TopP: 0.95
TopK: 20
MinP: 0
Tipp: Vermeiden Sie Greedy Decoding, um eine verminderte Leistung oder sich wiederholende Ausgaben zu verhindern.
Nicht-Denkmodus
enable_thinking=False
Temperatur: 0.7
TopP: 0.8
TopK: 20
MinP: 0
Wiederholungssteuerung
Passen Sie bei unterstützten Frameworks presence_penalty zwischen 0 und 2 an, um Wiederholungen zu reduzieren.
Hinweis: Höhere Werte können zu einer gewissen Sprachmischung oder einer leichten Verschlechterung der Modellleistung führen.
- Empfehlungen zur Ausgabelänge
- Setzen Sie für die meisten Abfragen die Ausgabelänge auf 32.768 Token.
- Erhöhen Sie bei komplexen Benchmark-Aufgaben (z. B. Mathematik- oder Programmierwettbewerben) die maximale Ausgabelänge auf 38.912 Token, um umfassendere Antworten zu erhalten.
- Standardisierung des Ausgabeformats
- Matheaufgaben: Fügen Sie dies in Ihren Prompt ein: “Bitte denken Sie Schritt für Schritt und setzen Sie Ihre endgültige Antwort in \boxed{}.”
- Multiple-Choice-Fragen: Standardisieren Sie Antworten mithilfe eines JSON-Feldes: “Bitte zeigen Sie Ihre Wahl im Antwortfeld nur mit dem Buchstaben der Wahl an, z. B. „answer“: „C“.”
- Verwaltung des Gesprächsverlaufs
- Fügen Sie bei Multi-Turn-Gesprächen nur die endgültige Ausgabe in den Chatverlauf ein. Lassen Sie jeglichen zwischenzeitlichen „Denk“-Inhalt weg.
- Wenn Sie eine Jinja2-Chatvorlage verwenden, wird dies automatisch erledigt. Stellen Sie bei anderen Frameworks sicher, dass diese Vorgehensweise manuell befolgt wird.
Wenn Sie diese Empfehlungen befolgen, stellen Sie sicher, dass Qwen 3 durchweg genaue und qualitativ hochwertige Ergebnisse in allen Anwendungsfällen liefert.
Fazit
Qwen 3 bietet erstklassige Leistung bei Programmier-, Denk- und mehrsprachigen Aufgaben – unabhängig von der Projektgröße. Bereit, es in Aktion zu sehen?
Probieren Sie jetzt die Qwen 3 Demo auf Novita AI aus und sichern Sie sich Ihre kostenlosen Credits!
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.



