

Wichtige Highlights
Bare Metal mit Novita AI: Novita AI bietet eine zuverlässige Plattform für die Anmietung von Bare Metal GPU-Servern wie H100 SXM und B200 – mit voller Kontrolle, planbaren Preisen und maximaler Leistung.
Warum Novita AI wählen?: Top GPUs: Zugang zu modernsten GPUs wie NVIDIA H100 und B200.
Skalierbarkeit: Unterstützung für Multi-GPU-Setups mit NVLink/InfiniBand.
Einfachheit: Benutzerfreundliche Plattform mit transparenten Preisen ab nur 1,70 $/Std. für H100 und 4,77 $/Std. für B200.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern erschwingliche und leistungsstarke Bare Metal GPU-Server zur Verfügung stellt. Durch direkten Hardwarezugriff und einen einfachen Bereitstellungsprozess ermöglicht Novita AI eine reibungslose Skalierung für KI/ML-Workloads, LLM-Training und Inferenzaufgaben.
Sichern Sie sich Ihre H100- oder B200-GPUs noch heute
Was ist Bare Metal?

Quelle: platform9
Bare Metal bezeichnet physische, dedizierte Server, die nicht virtualisiert oder mit anderen Nutzern geteilt werden. Im Gegensatz zu Cloud-VMs oder GPU-APIs, die auf Abstraktionsebenen aufbauen, bietet Bare Metal direkten Zugriff auf die Hardware – keine Hypervisoren, keine lauten Nachbarn und keine Überraschungen. Bare Metal Server können mit leistungsstarken GPUs (wie NVIDIA B200 oder H100), optimierten CPUs, schnellen NVMe-SSDs und sogar spezialisierten Verbindungen wie NVLink oder InfiniBand für Multi-GPU-Setups ausgestattet werden.
Stellen Sie es sich vor wie das Mieten eines ganzen Autos anstatt nur für eine Fahrt zu bezahlen. Sie bestimmen die Geschwindigkeit, die Route und den Treibstoff – Sie sitzen am Steuer.
Warum Bare Metal statt API oder Cloud GPU?
1. Maximale Leistung
- Kein Virtualisierungs-Overhead: Sie erhalten jeden Takt, den die Hardware liefern kann.
- Voller GPU-Zugriff: Ideal für das Feintuning von Modellen, lange Jobs oder latenzkritische Inferenz.
- Multi-GPU-Skalierung: Mit NVLink oder InfiniBand ist die Kommunikation zwischen GPUs deutlich schneller als in virtualisierten Cloud-Umgebungen.
2. Mehr Kontrolle und Sicherheit
- Volle Kontrolle über die Umgebung: Installation eigener Treiber, Betriebssystem-Images und Bibliotheken.
- Kein Risiko von API-Abkündigungen oder cloudseitigen Kontingentbeschränkungen.
- Luftdichte oder On-Premise-Optionen für sensible Daten.
3. Kostenvorhersagbarkeit und Effizienz
- Stündliche API-Preise summieren sich schnell – besonders bei langfristigen oder hochvolumigen Jobs.
- Bare Metal ermöglicht die Optimierung von Workloads auf Systemebene und reduziert Ineffizienzen.
- Feste Preise und reservierte Kapazitäten verhindern überraschende Abrechnungsspitzen.
4. Ideal für den Produktionseinsatz
- Keine API-Anfragebegrenzungen oder Drosselungen.
- Höhere Zuverlässigkeit und bessere Leistungsoptimierung für reale Anwendungsfälle.
- Unterstützt bedarfsgesteuerte Skalierung oder hybride Edge-Bereitstellungen.
Kriterien für ein gutes Bare Metal Setup
1. GPU-Generation
Wählen Sie GPUs passend zu Ihrem Workload:
- H100 – Ideal zum Trainieren großer Sprachmodelle und zur effizienten Verarbeitung komplexer multimodaler Workloads.
- B200 – NVIDIAs Next-Gen-Kraftpaket, entwickelt für extreme KI-Leistung bei Training und Inferenz in großem Maßstab.
2. Multi-GPU-Unterstützung
- Achten Sie auf NVLink oder InfiniBand für eine latenzarme, bandbreitenstarke Verbindung.
- Entscheidend für das Training großer Modelle oder den Einsatz von Modellparallelismus.
3. Netzwerkfähigkeiten
- Bevorzugen Sie Anbieter mit 25 Gbit/s+ Bandbreite oder dedizierten Switches.
- Latenzarmes Networking ist der Schlüssel für verteiltes Training und Orchestrierung.
4. Speichertyp
- Wählen Sie NVMe-SSDs anstelle von SATA für schnellere Datenladung.
- Hohe IOPS sind für vorverarbeitungsintensive Workflows wichtig.
5. CPU und RAM
- Passen Sie die Anzahl der CPU-Kerne und die RAM-Größe an Ihre Datenlade- oder Vorverarbeitungsengpässe an.
- CPUs mit vielen Kernen helfen, GPU-Unterbrechungen zu vermeiden.
6. Zuverlässigkeit und Support des Anbieters
- 24/7-Support mit schneller Ticketbearbeitung ist für den Produktionseinsatz unerlässlich.
- Suchen Sie nach Anbietern, die benutzerdefinierte Betriebssystem-Images, Fernzugriff (IPMI) und Nutzungs-Dashboards anbieten.
Bare Metal vs. Dedizierter Server vs. Virtueller Server
| Merkmal | Bare Metal Server | Dedizierter Server | Virtueller Server (VPS) |
|---|---|---|---|
| Leistung | 🔥 Maximal | ⚡ Hoch | ⚙️ Mittel |
| Isolation | ✅ Vollständig | ✅ Vollständig | ❌ Geteilt |
| Skalierbarkeit | 🔄 Eingeschränkt (manuell) | 🔄 Mittel | 🚀 Hoch (bedarfsgesteuert) |
| Anpassbarkeit | 🛠️ Vollständig | ⚙️ Mittel | 🔧 Eingeschränkt |
| Bereitstellungszeit | 🕒 Länger (manuelle Einrichtung) | ⏱️ Mittel | ⚡ Sofort |
| Anwendungsfall | KI/ML, HPC, FinTech | Web-, App-Server | Entwicklung/Test, leichte Apps |
| Kosten | 💰 Am höchsten | 💸 Mittel | 🪙 Niedrig |
| Verwaltungsaufwand | 🧠 Hoch (selbstverwaltet) | 🧩 Mittel | 🎛️ Niedrig (vom Anbieter verwaltet) |
Wann sollten Sie welche Option wählen?
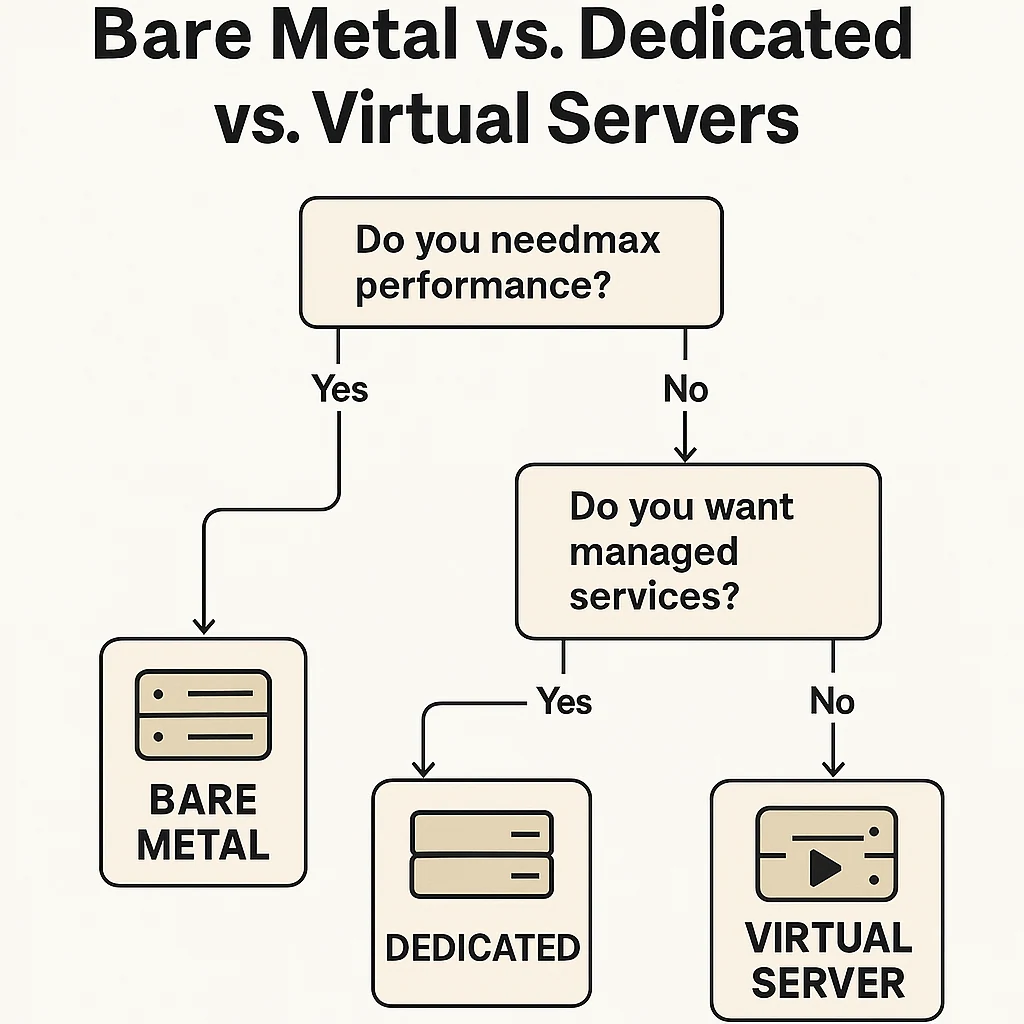
Wählen Sie Bare Metal, wenn:
- Sie maximale GPU-Leistung für das Training großer KI-Modelle benötigen.
- Ihr Workload vollständige OS- und Treiberkontrolle erfordert.
- Sie keine Störungen durch Nachbarn wünschen (Problem der lauten Nachbarn).
Wählen Sie Dedizierte Server, wenn:
- Sie Leistung + verwaltete Dienste möchten.
- Sie Webseiten, Datenbanken oder mittelgroße Anwendungen hosten.
- Sie weniger Hardware-Kontrolle, aber mehr Komfort bevorzugen.
Wählen Sie Virtuelle Server (VPS), wenn:
- Sie eine schnelle Bereitstellung zu geringen Kosten wünschen.
- Sie an Entwicklung, Staging oder kleinen Apps arbeiten.
- Sie keine dedizierten Ressourcen oder GPU-Zugriff benötigen.
Wie nutzt man Bare Metal kosteneffektiv?
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.
Schritt 1: Einloggen und auf GPU Bare Metal zugreifen
Loggen Sie sich in Ihr Konto ein und klicken Sie auf den Button „GPU Bare Metal".
Schritt 2: Wählen Sie Ihre GPU
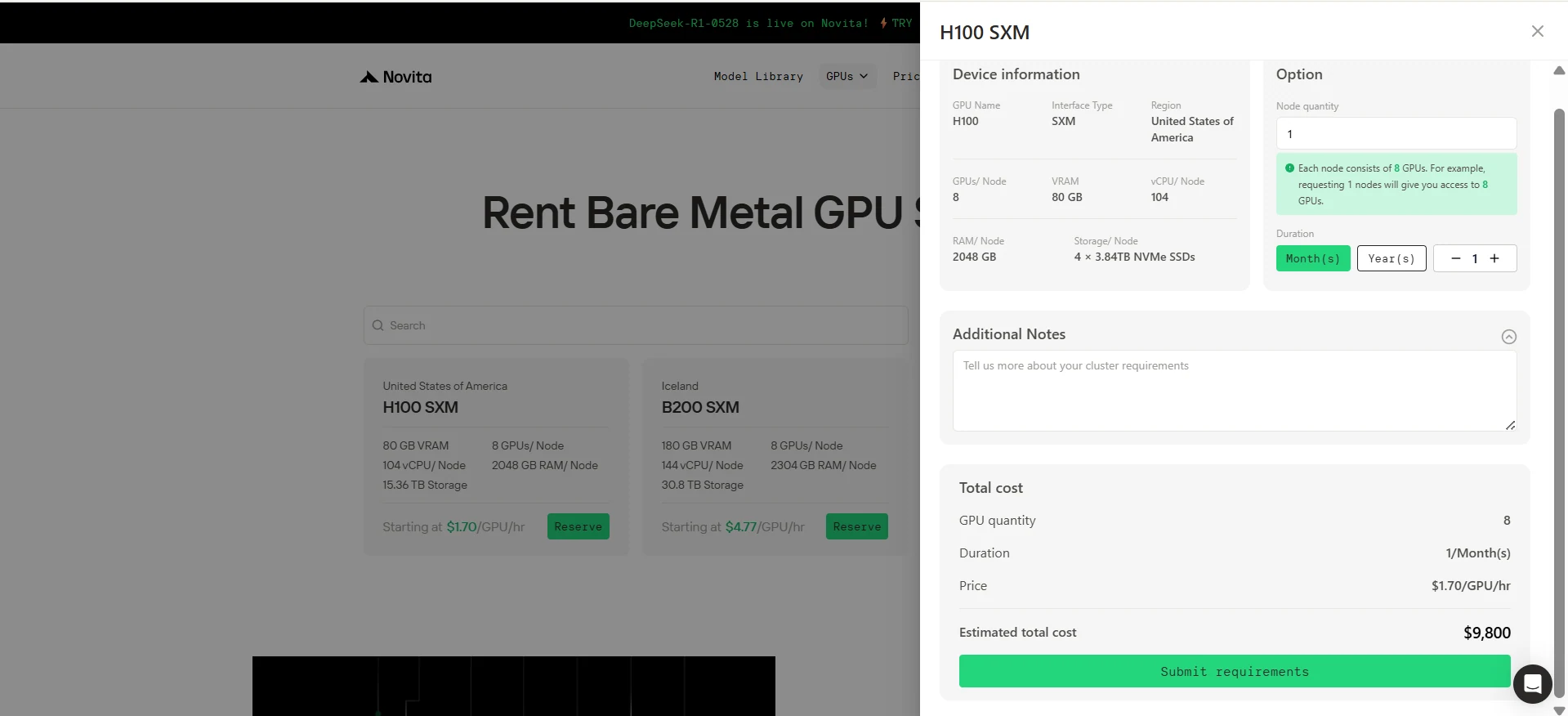
Gerät auswählen
- Gerätename: Wählen Sie H100 SXM oder B200 SXM.
- Region: Vereinigte Staaten von Amerika.
- Konfiguration (für H100 SXM):
- 8 GPUs
- 2048 GB Speicher
- 104 vCPU/Knoten
- 15,36 TB Speicher
- zu 1,70 $/Stunde.
- Konfiguration (für B200 SXM):
- 8 GPUs
- 2304 GB Speicher
- 144 vCPU/Knoten
- 30,8 TB Speicher
- zu 4,77 $/Stunde.
Anzahl und Mietdauer festlegen
- Passen Sie das Feld GPU-Anzahl an Ihre Bedürfnisse an. Wählen Sie z. B. 8 GPUs.
- Wählen Sie die Mietdauer. Stellen Sie sie z. B. auf 1 Monat ein.
Für Entwickler, die kostengünstige und leistungsstarke GPU-Lösungen suchen, ist Novita AI der ideale Partner. Mit modernsten GPUs wie H100 SXM, planbaren Preisen und einer intuitiven Plattform vereinfacht Novita AI den Aufbau und die Skalierung von KI-Modellen. Starten Sie noch heute mit Novita AI!
Häufig gestellte Fragen
Was ist ein Bare Metal Server?
Ein Bare Metal Server ist ein physischer, nicht virtualisierter Server, der direkten Zugriff auf die Hardware ohne Hypervisoren oder gemeinsam genutzte Ressourcen bietet.
Warum sollte man Bare Metal gegenüber GPU-APIs oder Cloud-VMs wählen?
Bare Metal bietet:
Maximale Leistung (kein Virtualisierungs-Overhead).
Volle Kontrolle (benutzerdefiniertes OS, Treiber, Bibliotheken).
Kosteneffizienz (planbare Preise, keine API-Beschränkungen).
Was macht Bare Metal kosteneffektiv?
Durch die Eliminierung von Virtualisierungs-Overhead und die Optimierung von Arbeitslasten auf Systemebene gewährleistet Bare Metal eine effiziente Hardware-Auslastung und vermeidet unvorhersehbare Cloud-Abrechnungen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.



