

重點摘要
開放原始碼可用性:Wan2.1 是一款開放原始碼的 AI 模型,能為學術界、研究人員和企業提供經濟高效、高品質的影片生成。
多元功能:支援 T2V、I2V、影片編輯、T2I,並能生成中英雙語字幕。
硬體需求:T2V-1.3B 僅有 13 億參數,大幅降低硬體門檻。
模型架構與創新:採用 Wan-VAE 進行 3D 編碼、Video Diffusion DiT,以及完善的訓練資料集處理流程。
VBench 效能評測:在 VBench 上以 86.22% 的成績超越 Sora 等競爭對手,在 ID 一致性、空間準確度與動作指令執行方面表現優異。
Novita AI 提供 Wan 2.1 的 API。只需註冊免費試用,即可透過簡單請求使用 API。
Wan2.1 是由 阿里巴巴雲端 ** 開發的開源 AI 模型,專為進階影片生成而設計。它以高效能、高效率與多功能為特色,能滿足廣泛的創意與專業應用需求。這些模型可在 ** 阿里巴巴雲端 AI 模型社群 ModelScope 及 Hugging Face 上取得。
來源:wan
立即在 Novita AI 開始免費試用。若要整合 Hunyuan Video API,請參閱我們的開發者文件以了解更多詳細資訊。
Novita 在市場上提供極具競爭力的定價。
例如,一部 Wan 2.1 720P 5 秒影片僅需 $0.3 美元
而在 Replicate 上,類似影片的費用為 $2.39 美元
開放原始碼可用性
阿里巴巴雲端已將其 Wan2.1 系列 AI 影片生成模型開放原始碼。此舉旨在降低使用門檻,使企業能夠以經濟高效的方式創作出高品質的視覺內容。透過將這些模型以開放原始碼形式釋出,學術界、研究人員及商業實體 無需承擔高昂的初始成本即可運用 AI 的力量於專案中。
Wan2.1 的多元功能
Wan2.1 在各種任務中表現卓越,使其成為影片生成的全能工具:
- 文字轉影片 (T2V)
- 圖片轉影片 (I2V)
- 影片編輯
- 文字轉圖片 (T2I)
值得注意的是,Wan2.1 是首個能夠生成中英文文字的影片模型,其強大的文字生成能力進一步提升了實際應用價值。
硬體需求
下表詳細總結了四款 Wan2.1 模型的硬體需求,列出每種模型的功能、支援解析度、模型大小、硬體需求及建議 GPU,以獲得最佳效能。
| **模型名稱 ** | ** 功能 ** | ** 支援解析度 ** | ** 模型大小 ** | ** 硬體需求 ** | ** 建議 GPU** |
|---|---|---|---|---|---|
| T2V-14B | 文字轉影片 (T2V) | 480P / 720P | 14B | ⭐⭐⭐⭐ | A100 / RTX 3090 / RTX 4090 |
| I2V-14B-720P | 圖片轉影片 (I2V) | 720P | 14B | ⭐⭐⭐⭐ | A100 / RTX 3090 / RTX 4090 |
| I2V-14B-480P | 圖片轉影片 (I2V) | 480P | 14B | ⭐⭐⭐ | RTX 3090 / RTX 4070 Ti |
| T2V-1.3B | 文字轉影片 (T2V) | 低解析度 | 1.3B | ⭐⭐ | RTX 3060 / RTX 4060 或更高 |
模型架構與關鍵創新
Wan2.1 基於 擴散變壓器(Diffusion Transformer) 架構,並以 Flow Matching 框架 強化。其主要創新包括:
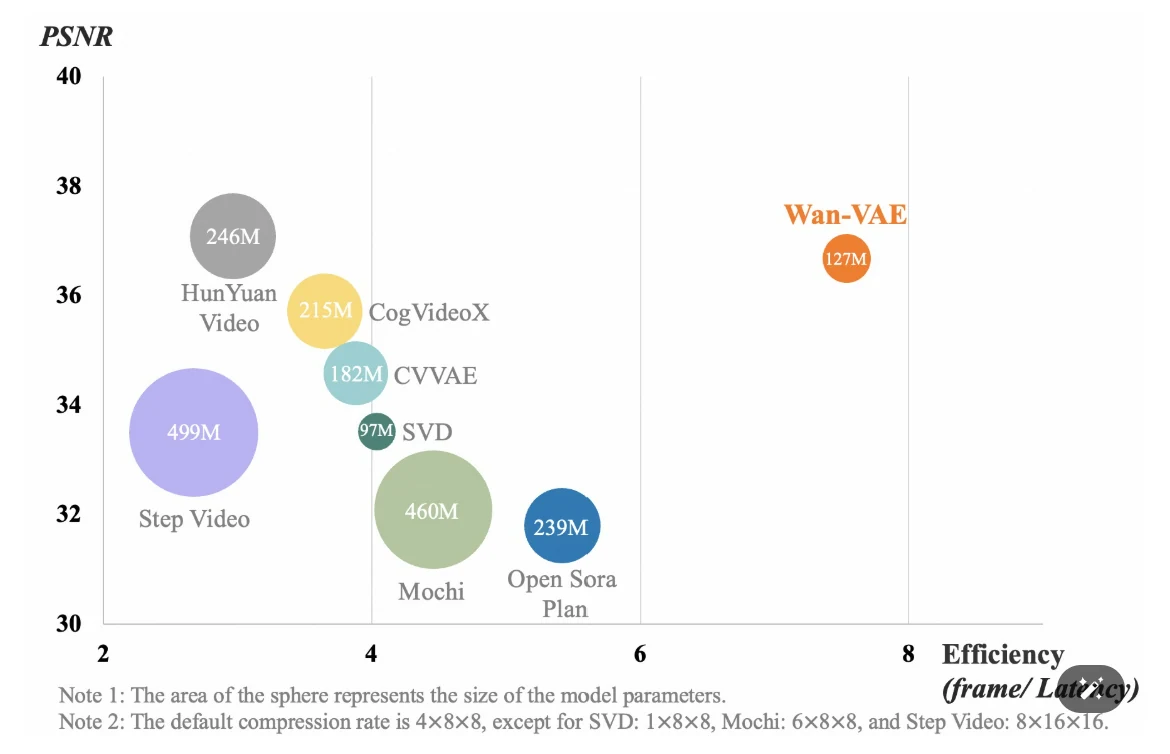
- Wan-VAE:一個 3D 變分自編碼器,專為高效壓縮和動作重現的高保真度而設計。它能對 1080P 影片進行編碼和解碼,同時維持時間一致性。該模型整合了多種策略,以優化 ** 時空壓縮 、減少記憶體使用,並確保 ** 時間因果性。
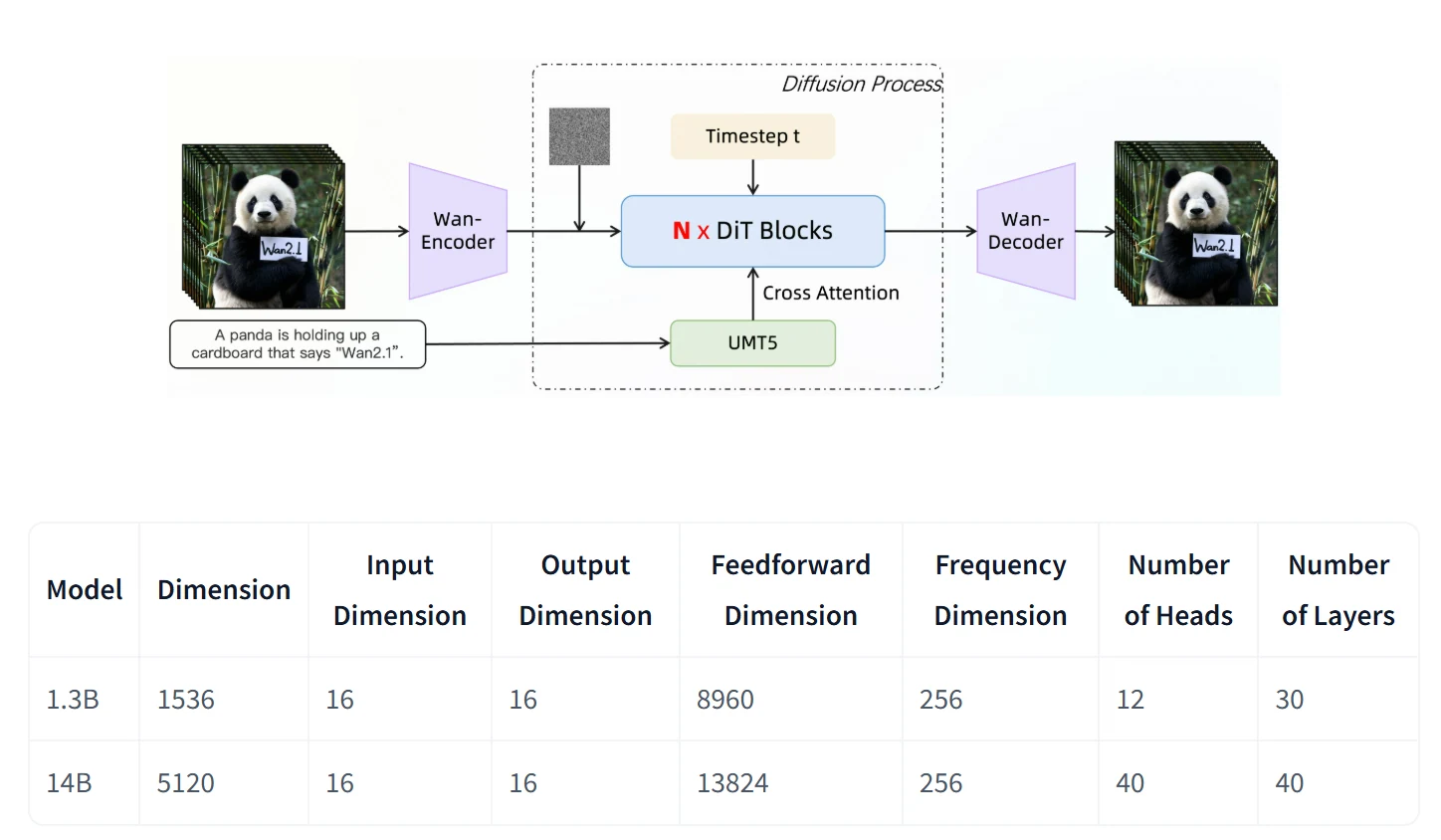
- Video Diffusion DiT:Wan2.1 利用擴散變壓器中的 Flow Matching 框架,採用 T5 編碼器處理多語言文字輸入,並透過交叉注意力將文字嵌入模型中。一個共享的 MLP(包含 SiLU 和線性層)會預測六個調製參數,用於時間嵌入,使每個變壓器區塊能學習不同的偏差。此架構在不增加參數規模的情況下,顯著提升了效能。
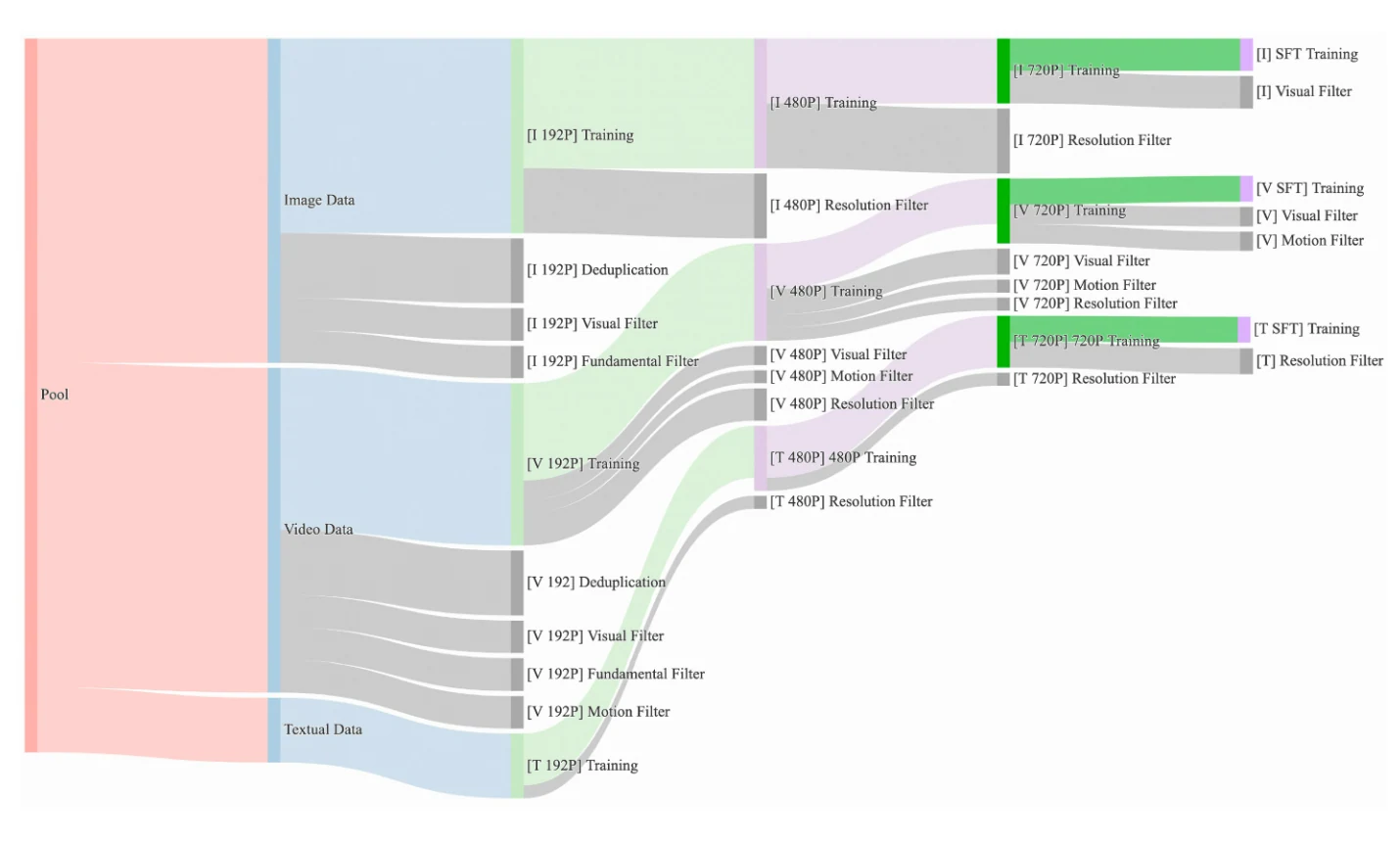
- 候選資料集:Wan 2.1 策劃並去重了一個包含大量圖片和影片資料的候選資料集。在資料策劃過程中,我們設計了四步驟的資料清洗流程,專注於基本維度、視覺品質和動作品質。透過強大的資料處理流程,我們能輕鬆獲得高品質、多樣化且大規模的圖片和影片訓練集。
VBench 評測
VBench 是一個強大且全面的基準測試套件,專為評估影片生成模型而設計。它將「影片生成品質」分解為層級化、分離且具體的維度,每個維度都配有量身定做的提示詞和評估方法。主要評估指標包括:
- 大動作生成
- 人類偽影
- 像素級穩定性
- ID 一致性
- 物理合理性
- 平滑度
- 綜合影像品質
- 場景生成品質
- 風格化能力
- 單一物體準確度
- 多重物體準確度
- 空間位置準確度
- 相機控制
- 動作指令跟隨
VBench 的目標是提供有價值的見解,揭示個別模型的優缺點,從而實現細緻且客觀的評估。這些見解不僅能引導未來影片生成的發展,也有助於提升模型效能。為確保與人類感知一致,VBench 納入了人類偏好註釋,驗證其作為基準的相關性與可靠性。Wan2.1 的效能如下圖所示:
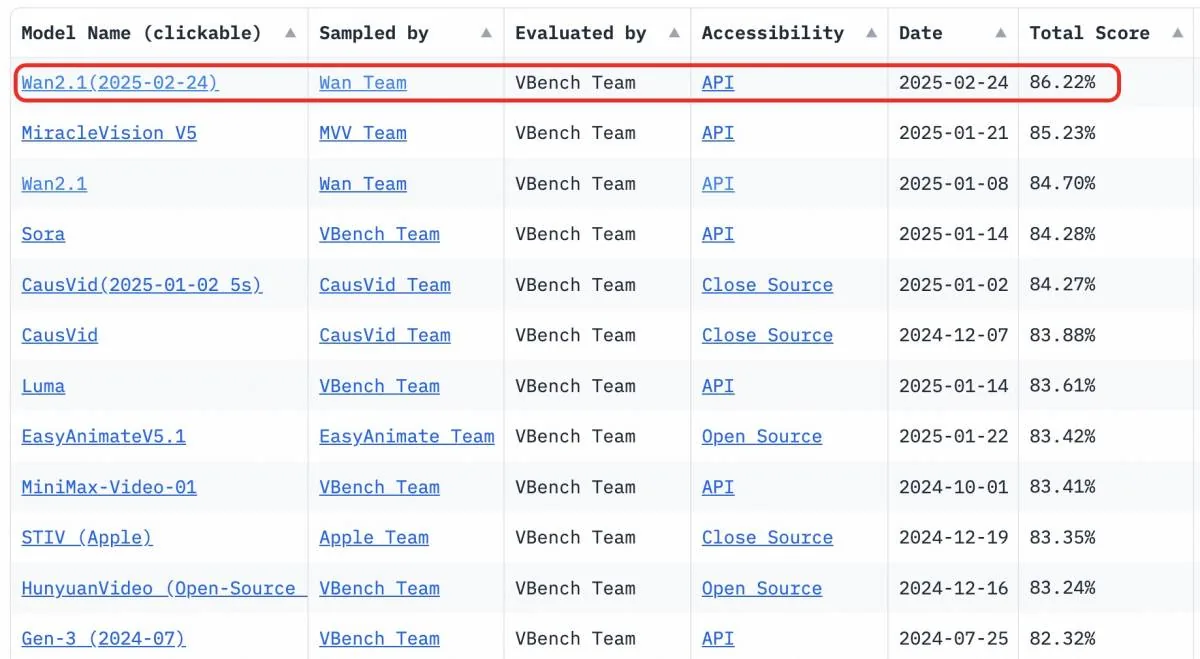
來源:Alizila
此外,Wan-Bench 被用於評估 T2V-1.3B 模型,結果顯示其在關鍵指標上超越了其他更大的開源模型。這些評估突顯了該模型在以下方面的進步:
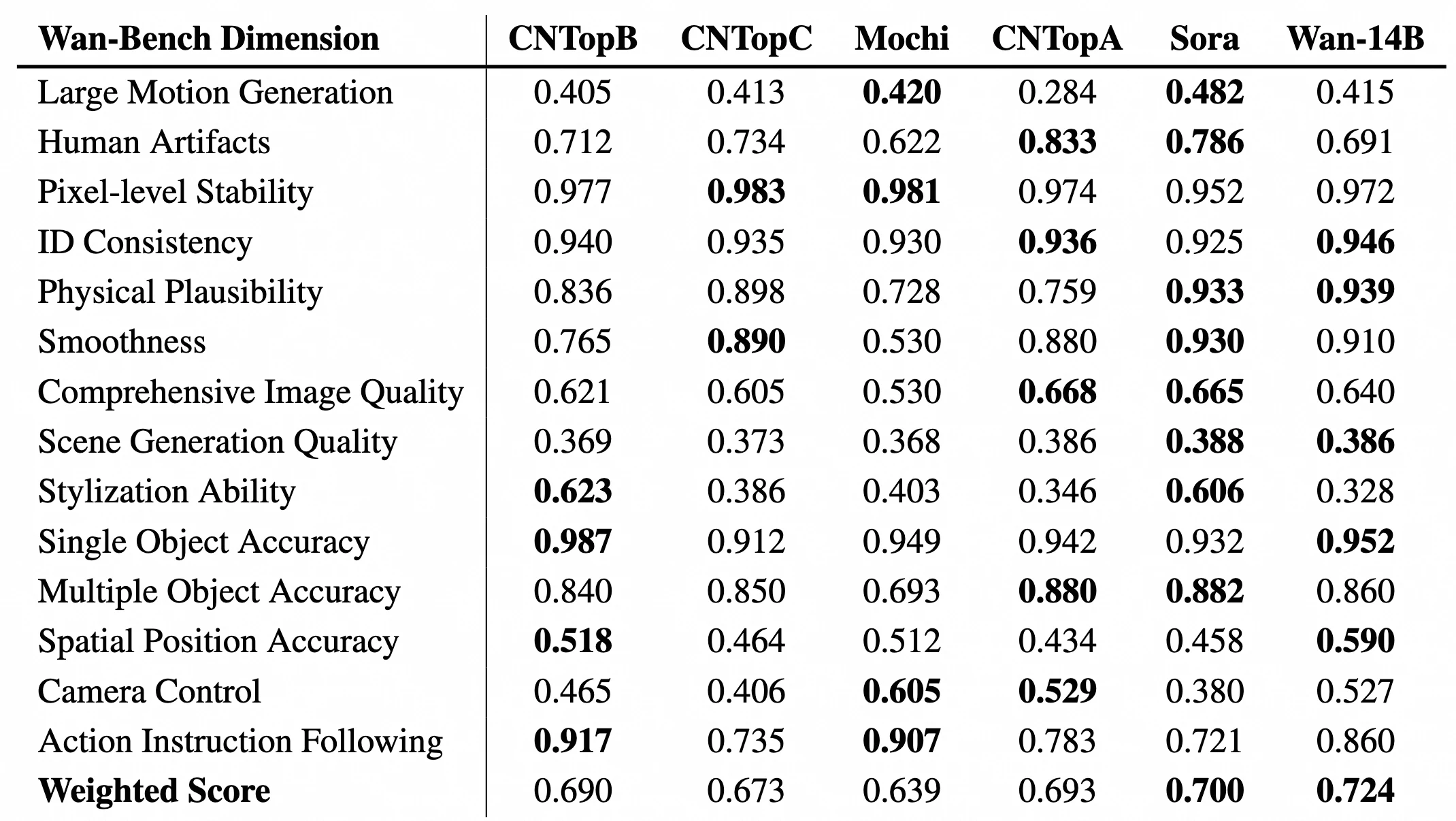
Wan 2.1 對比 Sora
綜合效能優勢:
- Wan2.1 在 VBench 上獲得 86.22% 的總分,超越 Sora 的 84.28%,並在多個子維度上表現更強。
支援中英文字幕生成:
- Wan2.1 是首個同時支援中英文影片字幕生成的模型,在多語言場景中具有獨特優勢。Sora 不提供此功能。
子維度表現:
- ID 一致性:Wan2.1 擅長維持影片中主體的一致性。
- 單一物體準確度:Wan2.1 在單一物體場景中生成結果更精確。
- 空間位置準確度:Wan2.1 在處理空間邏輯關係上顯著優於 Sora。
- 動作指令執行:Wan2.1 對複雜動作指令的理解與執行能力更佳。
開放原始碼與可及性:
- Wan2.1 提供開放原始碼,讓開發者更易於使用和整合。
- Sora 雖然提供 API,但並非開源,限制了靈活性。
有待改進之處:
- Wan2.1 在 動作平滑度 ** 和 ** 大動作生成 方面略遜於 Sora,但差距極小。
應用場景
內容創作
- 能自動為社交媒體、行銷和娛樂生成高品質影片。
- 支援風格化影片生成,以符合特定藝術或品牌需求。
教育與線上學習
- 生成帶有自訂視覺效果和中英文字幕的教育影片。
- 有助於創作具吸引力且個人化的學習內容。
電影與動畫
- 協助根據文字或圖片輸入創建故事板、影片原型或完整場景。
- 支援多語言字幕,適合全球觀眾。
廣告與行銷
- 為目標受眾量身打造客製化的影片廣告。
- 透過視覺引人且情境相關的內容強化行銷活動。
遊戲
- 根據文字描述或角色圖片生成遊戲過場動畫或動畫。
- 為遊戲開發與故事敘述創建動態影片素材。
多語言溝通
- 支援中英文字幕生成,特別適合多語言簡報與媒體。
原型設計與可視化
- 協助透過影片將概念、想法或建築設計視覺化。
- 為簡報或提案生成專案的動態展示。
無障礙與包容性
- 建立附帶字幕的影片,改善聽障人士的無障礙體驗。
- 多語言支援便於為不同使用者群體創作內容。
Wan2.1 代表了 AI 驅動影片生成領域的重大進展。其開放原始碼特性、多語言能力以及在 VBench 等基準測試中的優異表現,使其成為創意與專業應用的多功能且易於使用的工具。雖然在動作平滑度和大型動作生成方面略遜於 Sora,但其整體能力、創新架構與廣泛應用,使其成為教育、媒體、遊戲等行業的遊戲規則改變者。
Novita AI 是一個一站式雲端平台,助力您的 AI 願景。整合 API、無伺服器運算、GPU 實例——您所需的經濟高效工具。無需管理基礎設施,免費開始,讓您的 AI 願景成真。



