

核心亮点
开源可用:Wan2.1 是开源 AI 模型,为学术研究者、科研人员及企业提供高性价比、高质量的视频生成能力。
多功能能力:支持 T2V、I2V、视频编辑、T2I,并可生成中英文多语言字幕文本。
硬件要求:T2V-1.3B 仅有 1.3B 参数,大幅降低硬件门槛。
模型架构与创新:采用 Wan-VAE 进行 3D 编码、Video Diffusion DiT,以及用于高质量训练数据集的稳健流程。
VBench 与性能评估:在 VBench 上以 86.22% 的得分超越 Sora 等竞品,在 ID 一致性、空间准确性、动作指令执行方面表现出色。
Novita AI 提供 Wan 2.1 的 API。只需注册免费试用,通过简单请求即可使用 API。
Wan2.1 是由 阿里云 ** 开发的开源 AI 模型,专为高级视频生成设计。它兼具高性能、高效率与多功能性,适用于广泛的创意和专业应用。该模型已在 ** 阿里云 AI 模型社区 ModelScope 和 Hugging Face 上开源提供。
来源:wan
立即在 Novita AI 上开始免费试用。要集成 Hunyuan Video API,请访问我们的 开发者文档 了解更多详情。
Novita 在市场上提供极具竞争力的价格。
例如,一个 Wan 2.1 720P 5 秒视频仅需 $0.3
而 Replicate 上同类视频需 $2.39
开源可用
阿里云已将其 Wan2.1 系列视频生成 AI 模型开源。此举旨在降低使用门槛,使企业能够以高性价比的方式创建高质量视觉内容。通过将这些模型以开源形式发布,学术研究者、科研人员及商业实体 无需重大前期投入即可借助 AI 的力量推进项目。
Wan2.1 的多功能能力
Wan2.1 在多种任务中表现出色,使其成为视频生成的通用工具:
- 文生视频 (T2V)
- 图生视频 (I2V)
- 视频编辑
- 文生图 (T2I)
值得注意的是,Wan2.1 是首个能够同时生成中文和英文字幕的视频模型,其强大的文本生成能力增强了实际应用价值。
硬件要求
下表详细总结了四种 Wan2.1 模型的硬件要求。表格列出了各模型的功能、支持分辨率、模型大小、硬件需求以及推荐 GPU,以获得最佳性能。
| **模型名称 ** | ** 功能 ** | ** 支持分辨率 ** | ** 模型大小 ** | ** 硬件需求 ** | ** 推荐 GPU** |
|---|---|---|---|---|---|
| T2V-14B | 文生视频 (T2V) | 480P / 720P | 14B | ⭐⭐⭐⭐ | A100 / RTX 3090 / RTX 4090 |
| I2V-14B-720P | 图生视频 (I2V) | 720P | 14B | ⭐⭐⭐⭐ | A100 / RTX 3090 / RTX 4090 |
| I2V-14B-480P | 图生视频 (I2V) | 480P | 14B | ⭐⭐⭐ | RTX 3090 / RTX 4070 Ti |
| T2V-1.3B | 文生视频 (T2V) | 低分辨率 | 1.3B | ⭐⭐ | RTX 3060 / RTX 4060 或更高 |
模型架构与关键创新
Wan2.1 基于 **扩散 Transformer 范式 **,并采用 Flow Matching 框架 进行增强。其关键创新包括:
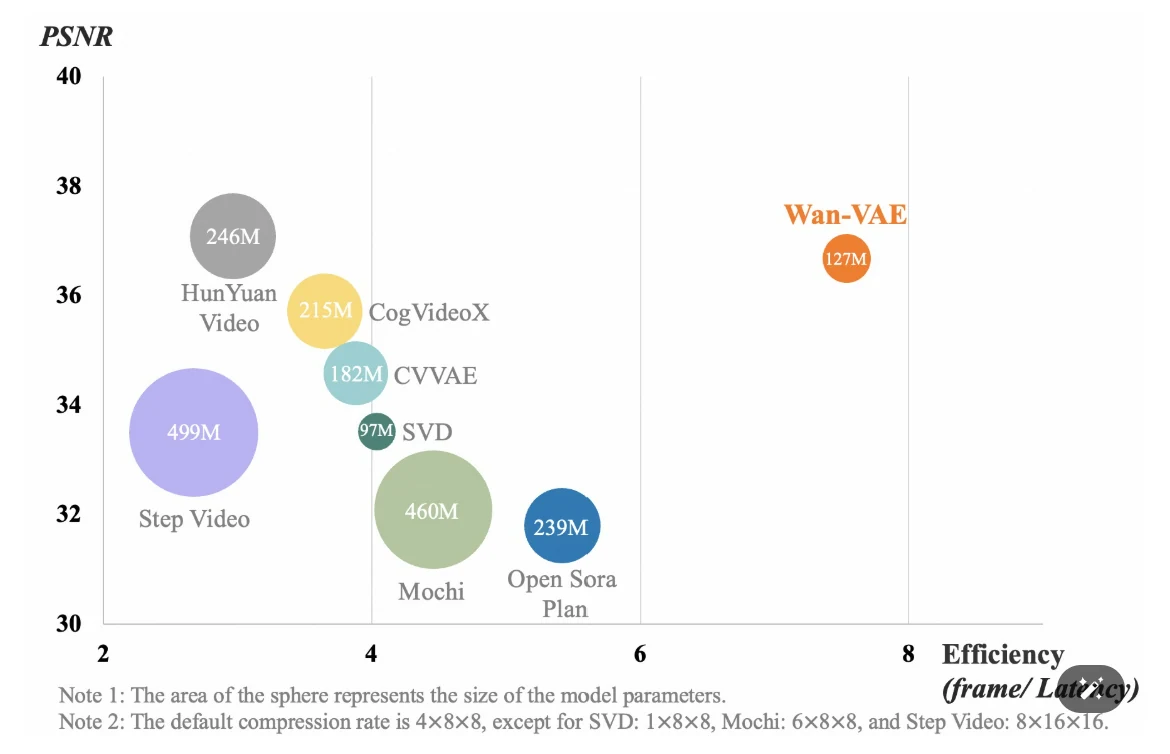
- Wan-VAE:一种 3D 变分自编码器,专为高效压缩和高保真运动再现而设计。它能够编解码 1080P 视频,同时保持时间一致性。该模型集成了多种策略以优化 ** 时空压缩 、减少内存使用并确保 ** 时间因果性。
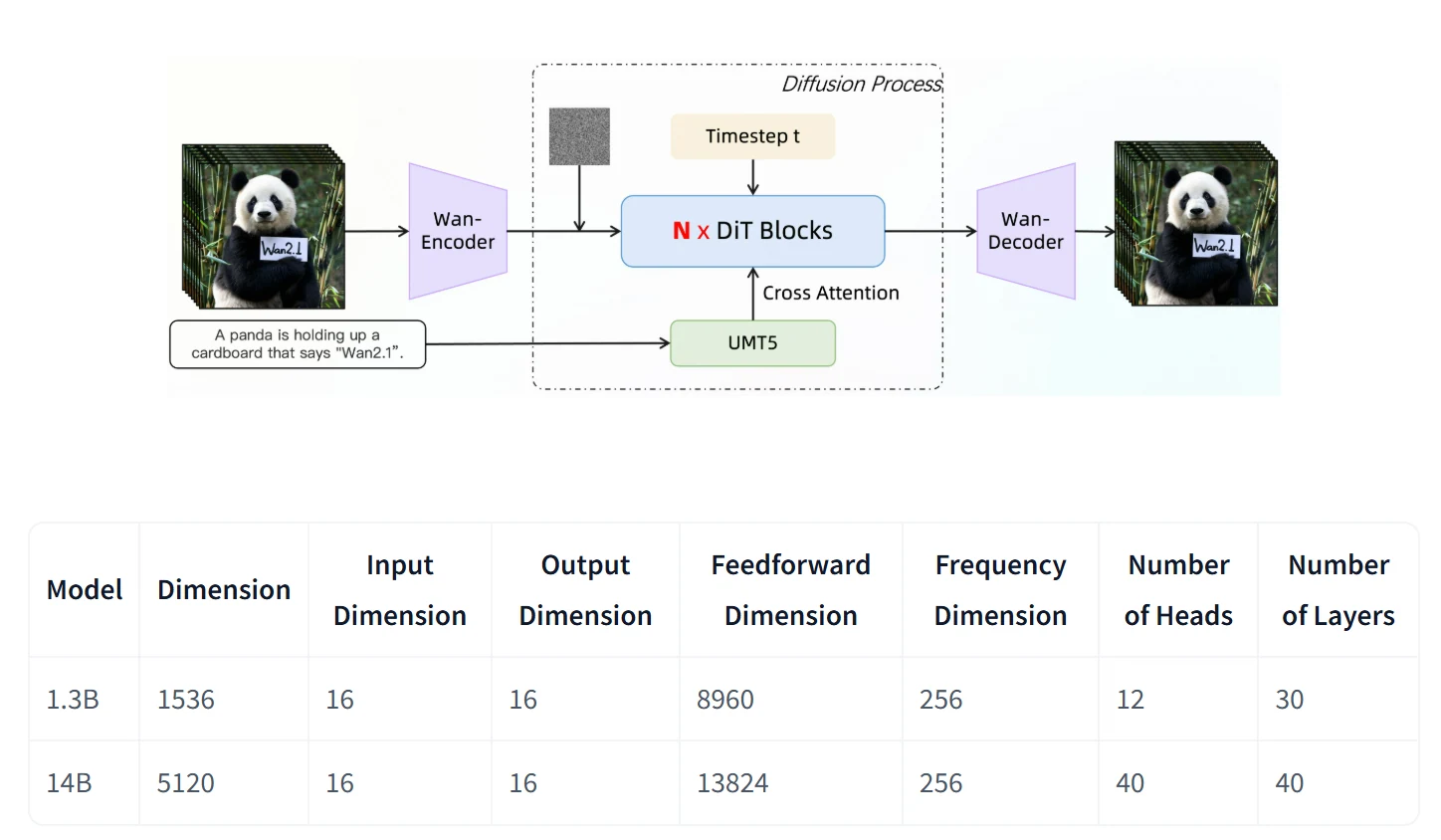
- Video Diffusion DiT:Wan2.1 在 Diffusion Transformer 中利用 Flow Matching 框架,使用 T5 编码器处理多语言文本输入,并通过交叉注意力将文本嵌入模型。一个共享的 MLP(含 SiLU 和线性层)为时间嵌入预测六个调制参数,使每个 transformer 块学习不同的偏置。该架构在不增加参数规模的情况下显著提升了性能。
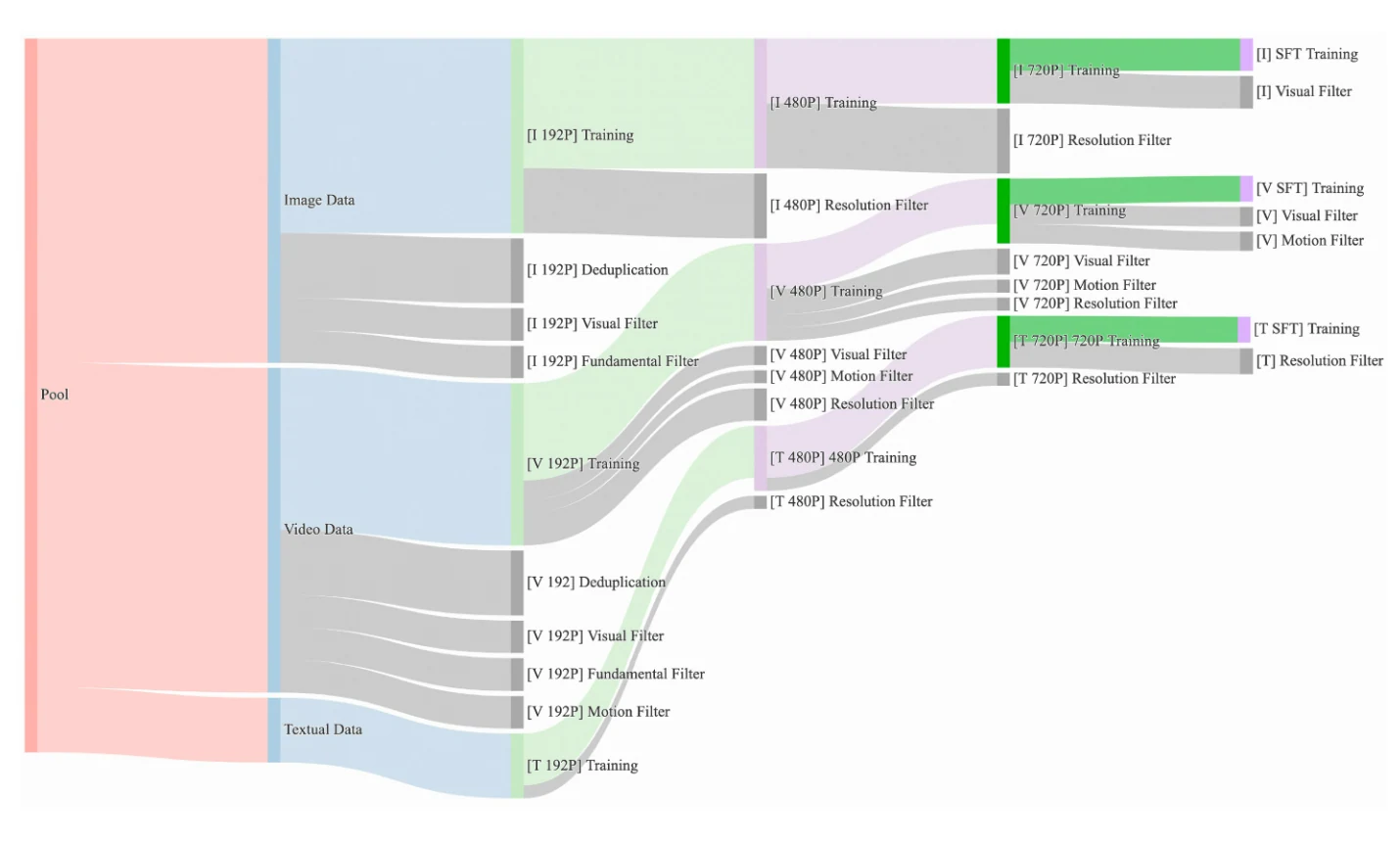
- 候选数据集:Wan 2.1 整理并去重了一个包含海量图像和视频数据的候选数据集。在数据整理过程中,我们设计了一个四步数据清洗流程,重点关注基础维度、视觉质量和运动质量。通过稳健的数据处理流程,我们可以轻松获得高质量、多样化且大规模的图像和视频训练集。
VBench 评估
VBench 是一个稳健且全面的基准测试套件,专门用于评估视频生成模型。它将“视频生成质量”分解为层次化、解耦且具体的维度,每个维度都配有专门的提示词和评估方法。主要评估指标包括:
- 大幅运动生成
- 人造痕迹
- 像素级稳定性
- ID 一致性
- 物理合理性
- 平滑度
- 综合图像质量
- 场景生成质量
- 风格化能力
- 单一物体准确性
- 多物体准确性
- 空间位置准确性
- 摄像机控制
- 动作指令遵循
VBench 旨在提供对单个模型优缺点的深入洞察,实现细粒度、客观的评估。这些洞察不仅指导视频生成的未来发展,还有助于改进模型性能。为了确保与人类感知一致,VBench 融入了人工偏好标注,验证了其作为基准的相关性和可靠性。Wan2.1 的性能如下表所示:
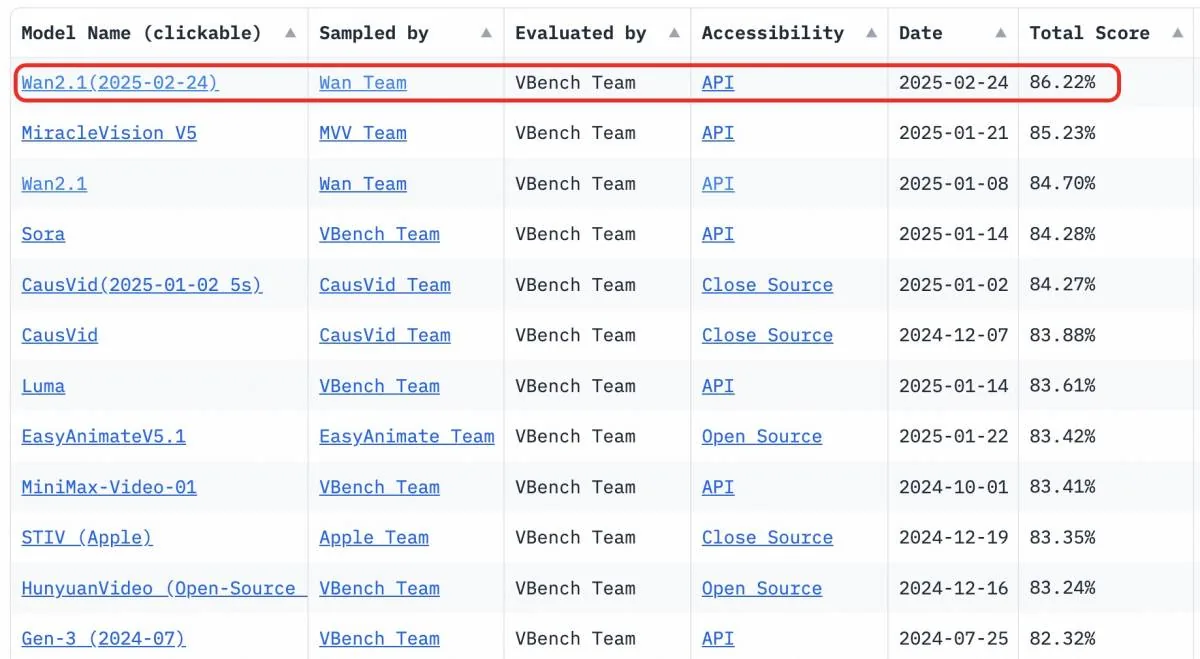
来源:Alizila
此外,Wan-Bench 用于评估 T2V-1.3B 模型,该模型在关键指标上超越了更大的开源同类模型。这些评估突显了该模型在以下方面的进步:
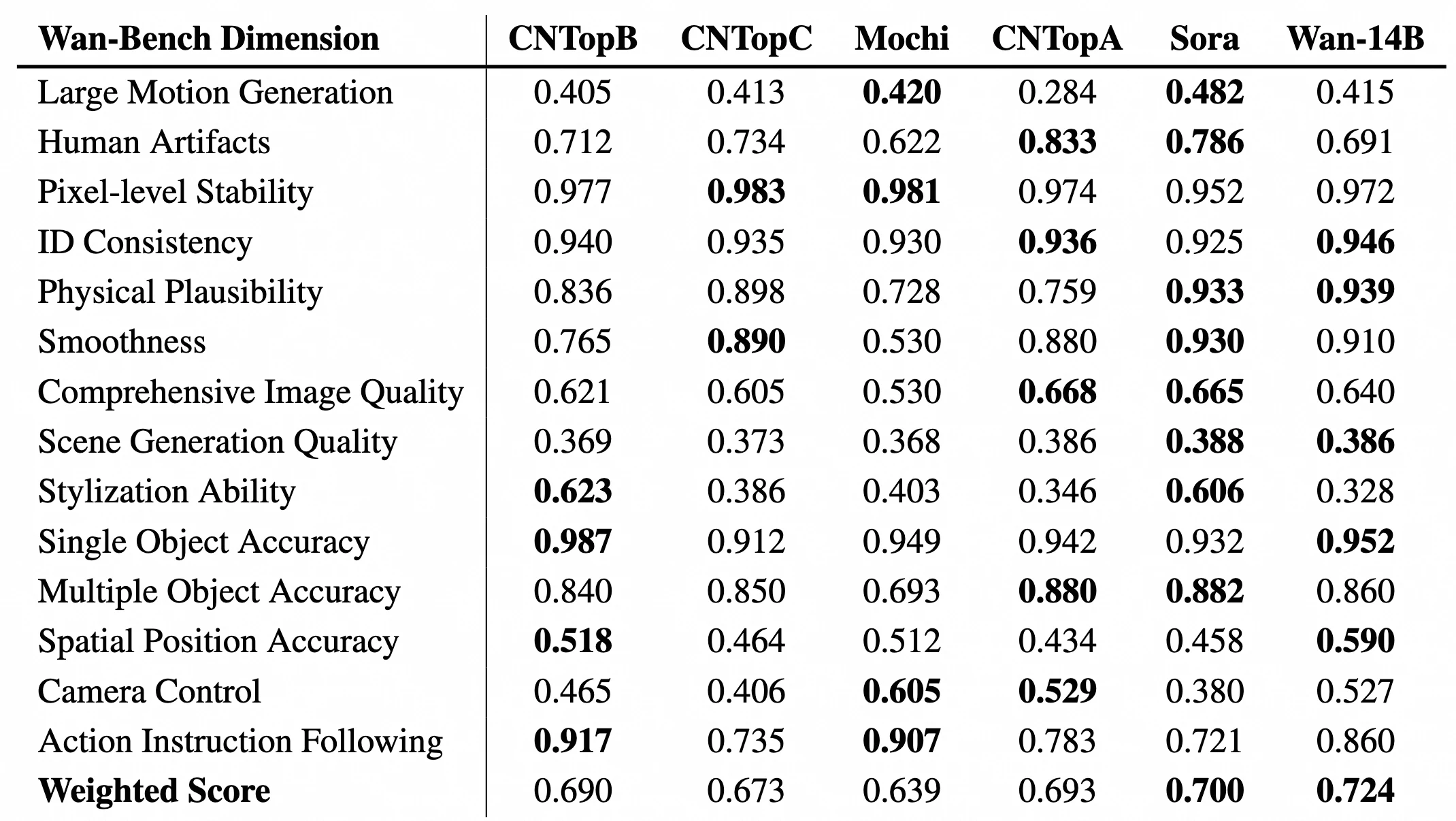
Wan 2.1 与 Sora 对比
综合性能优势:
- Wan2.1 在 VBench 上获得 86.22% 的更高总分,超过 Sora 的 84.28%,并在多个子维度上表现更强。
支持中英文字幕生成:
- Wan2.1 是首个同时支持中英文双语字幕生成的视频生成模型,在多语言场景中具有独特优势。Sora 不具备此功能。
子维度表现:
- ID 一致性: Wan2.1 在视频中保持主体一致性方面表现出色。
- 单一物体准确性: Wan2.1 在单个物体场景中生成结果更精确。
- 空间位置准确性: Wan2.1 在处理空间逻辑关系方面显著优于 Sora。
- 动作指令执行: Wan2.1 能更好地理解和执行复杂动作指令。
开源与可访问性:
- Wan2.1 提供开源代码,易于开发者使用和集成。
- Sora 虽然提供 API,但并非开源,灵活性受限。
有待改进之处:
- Wan2.1 在 运动平滑度 ** 和 ** 大幅运动生成 方面略逊于 Sora,但差距不大。
应用场景
内容创作
- 支持为社交媒体、营销和娱乐自动生成高质量视频。
- 支持风格化视频生成,以匹配特定艺术或品牌需求。
教育与在线学习
- 生成包含自定义视觉和中英文字幕的教育视频。
- 有助于创建吸引人且个性化的学习内容。
电影与动画
- 根据文本或图像输入协助创建故事板、视频原型或完整场景。
- 支持多语言字幕,适合全球受众。
广告与营销
- 为特定受众制作定制化视频广告。
- 通过视觉引人、情境相关的内容提升营销活动效果。
游戏
- 根据文字描述或角色图像生成游戏内过场动画或动画。
- 为游戏开发和叙事创建动态视频资源。
多语言交流
- 支持中英文字幕生成,非常适合多语言演示和媒体。
原型设计与可视化
- 帮助通过视频可视化概念、想法或建筑设计。
- 为演示或提案生成项目的动态展示。
无障碍与包容性
- 生成带字幕的视频,改善听障人士的可访问性。
- 多语言支持有助于为多元用户群体创作内容。
Wan2.1 代表了 AI 驱动视频生成的重大进步。其开源特性、多语言能力以及在 VBench 等基准测试中的卓越表现,使其成为创意和专业应用中通用且易用的工具。尽管在运动平滑度和大幅运动生成方面略逊于 Sora,但其整体能力、创新架构和广泛的应用场景使其成为教育、媒体、游戏等行业变革性的工具。
Novita AI 是集 API、无服务器、GPU 实例于一体的全能云平台,提供高性价比的工具,助力您的 AI 愿景。无需基础设施,免费开始,让您的 AI 梦想成真。



