

DeepSeek 已推出兩款突破性模型——DeepSeek-R1-0528 與 DeepSeek-R1-0528-Qwen3-8B——現已在 Novita AI 上線。Novita AI 是一個 AI 雲端平台,提供開發者透過直觀的 API 輕鬆部署 AI 模型。這些模型以具競爭力的價格帶來卓越的推理能力,比前代產品表現大幅提升。
Novita AI 以具競爭力的費率提供兩種 DeepSeek-R1-0528 模型,並採用透明的按用量計費方式:
DeepSeek-R1-0528(完整模型):
- 輸入 Token:每百萬個 Token 0.7 美元
- 輸出 Token:每百萬個 Token 2.5 美元
DeepSeek-R1-0528-Qwen3-8B(高效 8B 模型):
- 輸入 Token:每百萬個 Token 0.06 美元
- 輸出 Token:每百萬個 Token 0.09 美元
什麼是 DeepSeek-R1-0528?
DeepSeek R1 模型進行了小幅版本升級,當前版本為 DeepSeek-R1-0528。在這次最新更新中,DeepSeek R1 透過增加運算資源並在訓練後引入演算法最佳化機制,大幅提升了推理深度與推論能力。
該模型在數學、程式設計和一般邏輯等多項基準評測中展現了出色表現。其整體效能已接近 O3 和 Gemini 2.5 Pro 等頂級模型。
DeepSeek-R1-0528 的主要改善
🔹 基準測試表現提升:涵蓋數學、程式碼與推理任務
🔹 前端能力增強:帶來更好的使用者體驗
🔹 減少幻覺:輸出結果更可靠
🔹 支援 JSON 輸出與函式呼叫:可無縫整合
增強推理深度
與前版相比,升級後的模型在處理複雜推理任務時有顯著進步。例如在 AIME 2025 測試中,模型準確率從前版的 70% 提升至目前的 87.5%。
這項進展來自推理過程中思考深度的增強:在 AIME 測試集中,前版模型每題平均使用 12K Token,而新版本每題平均使用 23K Token。
與業界領先模型的競爭表現
DeepSeek-R1-0528 在多項具挑戰性的基準測試中,與業界頂尖模型相比展現了優異的性能:
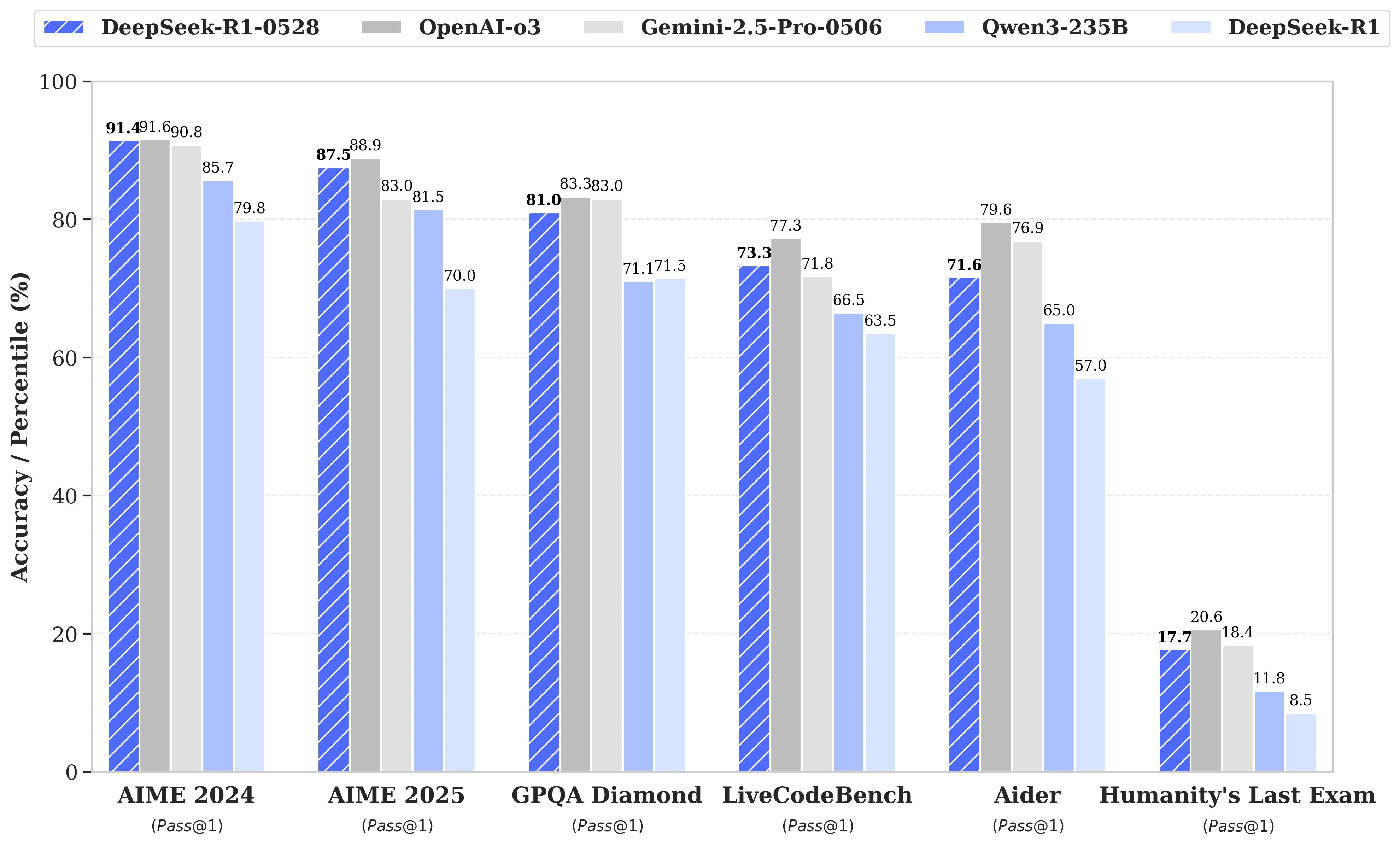
DeepSeek-R1 與 DeepSeek-R1-0528 比較
數學推理表現
| 基準測試 | DeepSeek R1 | DeepSeek R1-0528 | 改善幅度 |
|---|---|---|---|
| AIME 2024 (Pass@1) | 79.8 | 91.4 | +11.6 |
| AIME 2025 (Pass@1) | 70.0 | 87.5 | +17.5 |
| HMMT 2025 (Pass@1) | 41.7 | 79.4 | +37.7 |
| CNMO 2024 (Pass@1) | 78.8 | 86.9 | +8.1 |
程式碼編寫效能提升
| 基準測試 | DeepSeek R1 | DeepSeek R1-0528 | 改善幅度 |
|---|---|---|---|
| LiveCodeBench (Pass@1) | 63.5 | 73.3 | +9.8 |
| Codeforces-Div1 (Rating) | 1530 | 1930 | +400 |
| SWE Verified (Resolved) | 49.2 | 57.6 | +8.4 |
| Aider-Polyglot (Acc.) | 53.3 | 71.6 | +18.3 |
一般推理任務
| 基準測試 | DeepSeek R1 | DeepSeek R1-0528 | 改善幅度 |
|---|---|---|---|
| MMLU-Redux (EM) | 92.9 | 93.4 | +0.5 |
| MMLU-Pro (EM) | 84.0 | 85.0 | +1.0 |
| GPQA-Diamond (Pass@1) | 71.5 | 81.0 | +9.5 |
| SimpleQA (Correct) | 30.1 | 27.8 | -2.3 |
| FRAMES (Acc.) | 82.5 | 83.0 | +0.5 |
| Humanity’s Last Exam (Pass@1) | 8.5 | 17.7 | +9.2 |
全新工具整合能力
DeepSeek-R1-0528 在函式呼叫與工具整合方面引入了更強的能力:
- BFCL_v3_MultiTurn (Acc): 37.0%
- Tau-Bench (Pass@1): 53.5%(航空)/ 63.9%(零售)
DeepSeek-R1-0528-Qwen3-8B:卓越的輕量模型
DeepSeek 將 DeepSeek-R1-0528 的思考鏈(chain-of-thought)蒸餾至 Qwen3 8B Base 模型,打造出 DeepSeek-R1-0528-Qwen3-8B。此模型在 AIME 2024 上達到開放原始碼模型的最佳水準(SOTA),超越 Qwen3-8B 達 +10.0%,並與 Qwen3-235B-thinking 的表現相當。
這證明了 DeepSeek-R1-0528 的思考鏈對於推理模型的學術研究以及針對小型模型的工業開發都具有重要意義。
與頂尖模型的競爭分析
| 模型 | AIME 24 | AIME 25 | HMMT Feb 25 | GPQA Diamond | LiveCodeBench |
|---|---|---|---|---|---|
| Qwen3-235B-A22B | 85.7 | 81.5 | 62.5 | 71.1 | 66.5 |
| Qwen3-32B | 81.4 | 72.9 | - | 68.4 | - |
| Qwen3-8B | 76.0 | 67.3 | - | 62.0 | - |
| Phi-4-Reasoning-Plus-14B | 81.3 | 78.0 | 53.6 | 69.3 | - |
| Gemini-2.5-Flash-Thinking-0520 | 82.3 | 72.0 | 64.2 | 82.8 | 62.3 |
| o3-mini (medium) | 79.6 | 76.7 | 53.3 | 76.8 | 65.9 |
| DeepSeek-R1-0528-Qwen3-8B | 86.0 | 76.3 | 61.5 | 61.1 | 60.5 |
使用改善與技術細節
增強的使用性功能
與前版 DeepSeek-R1 相比,DeepSeek-R1-0528 的使用建議包含以下改善:
- 支援系統提示(System prompt):不同於早期版本,現在可以使用系統提示提供一致的上下文與指令
- 自動思考模式:無需手動啟用——模型會自動啟用推理能力,不需在輸出開頭加入「思考中\」
DeepSeek-R1-0528-Qwen3-8B 架構
DeepSeek-R1-0528-Qwen3-8B 的模型架構與 Qwen3-8B 完全相同,但使用與 DeepSeek-R1-0528 相同的分詞器(tokenizer)配置。此模型的運作方式與 Qwen3-8B 相同,請務必確保所有配置檔案來自 DeepSeek 的儲存庫,而非原始的 Qwen3 專案。
開發者為何選擇 Novita AI
簡化的 AI 模型部署
- 無基礎設施煩惱:專注於構建應用程式,無需管理伺服器
- 即時模型存取:透過單一 API 呼叫部署最新模型
- 可靠效能:企業級基礎設施,99.9% 正常運行時間
- 全球可用:從世界各地提供低延遲存取
適合任何規模
- 快速原型開發:立即存取模型,快速測試想法
- 生產就緒:從原型到生產無縫擴展
- 成本效益:透明定價,按用量付費
- 企業支援:針對高用量應用提供專屬支援
理想使用案例
- 數學 AI 應用:建立教學平台,在 AIME 2025 上達到 87.5% 準確率
- 程式碼生成工具:建立開發助手,在 LiveCodeBench 上成功率達 73.3%
- 研究平台:部署與業界領導者競爭的推理模型
- 教育軟體:開發逐步解題應用程式
在 Novita AI 上快速入門
- 註冊 Novita AI,立即獲得 $10 美元免費額度
- 探索 DeepSeek-R1-0528(完整能力)或 DeepSeek-R1-0528-Qwen3-8B(高效模型)
- 從控制台取得您的 API 金鑰
- 發送您的第一個 API 請求,使用相容 OpenAI 的端點
- 開始建構,享受業界領先的推理能力
給 Python 使用者:
from openai import OpenAI
base_url = "https://api.novita.ai/v3/openai"
api_key = "<Your API Key>"
model = "deepseek/deepseek-r1-0528"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # or False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
結論
DeepSeek-R1-0528 系列模型以具競爭力的價格提供業界領先的效能——在 AIME 2024 上達到 91.4%,在 LiveCodeBench 上達到 73.3%,同時與 OpenAI-o3 和 Gemini-2.5-Pro 的能力相抗衡。
透過 Novita AI 的開發者友善平台,您可以立即存取這些尖端模型,無需處理基礎設施的複雜性。透明的定價、$10 美元免費額度以及直觀的 API,讓您將世界級的推理能力整合到應用程式中,從未如此簡單。
Novita AI 是一個 AI 雲端平台,提供開發者透過簡單的 API 輕鬆部署 AI 模型,同時也提供價格合理且可靠的 GPU 雲端服務,用於建構和擴展應用程式。



