

随着 AI 模型日益复杂和数据密集,对 GPU 计算能力的需求急剧上升。训练大型语言模型可能需要数千 GPU 小时,而实时推理应用则需要持续、低延迟地访问加速计算资源。选择合适的云 GPU 提供商直接影响项目的成功、时间线和预算。
关键选择标准
评估云 GPU 提供商时,有几个关键因素决定了哪种方案最适合您的特定用例:
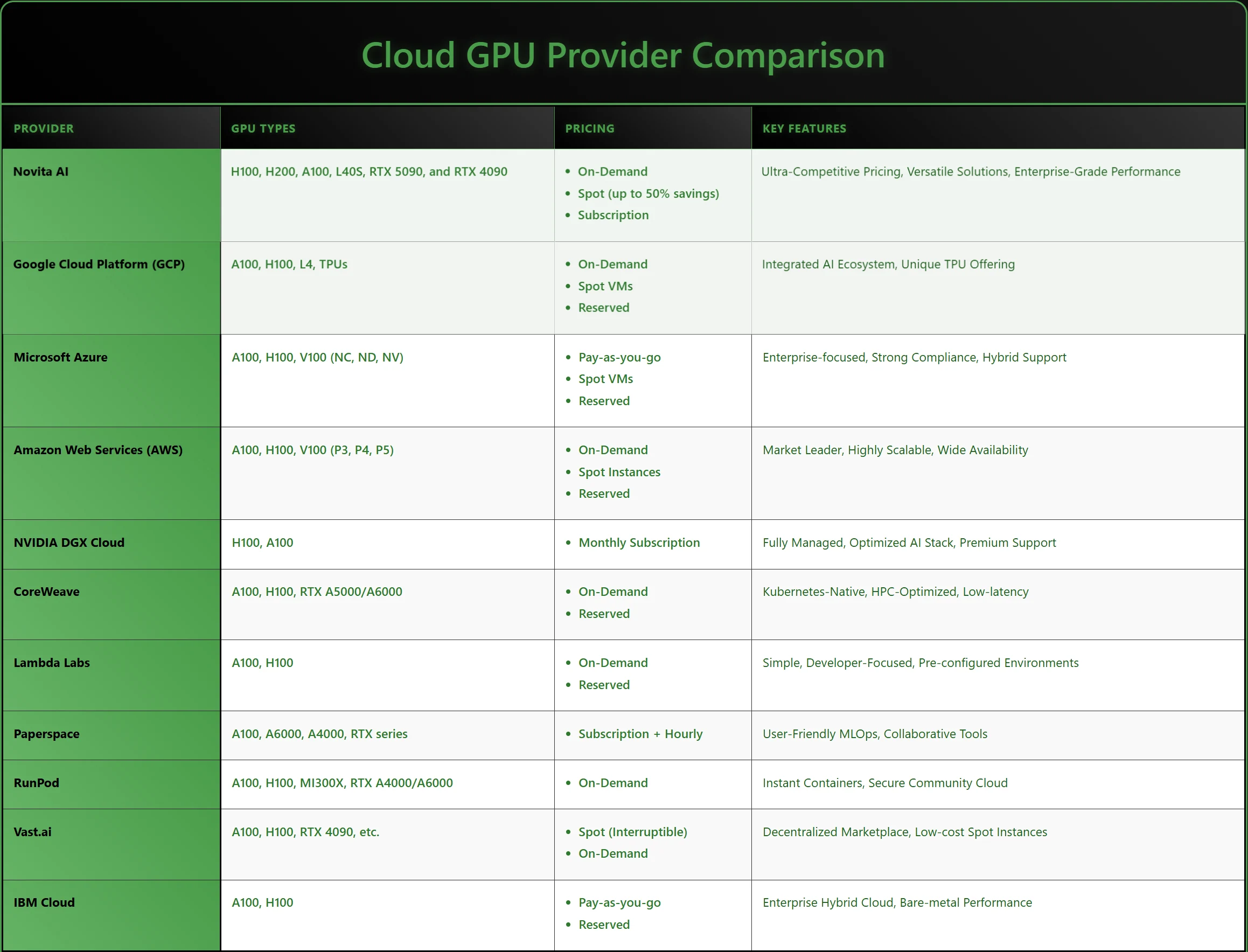
硬件组合:能否访问最新一代 GPU(H100、A100)以及预算友好型替代方案(RTX 系列等),并具备满足特定工作负载的足够显存和互联带宽。
定价灵活性:多种计费模式,包括 按需 即时访问、竞价实例 对容错工作负载提供大幅折扣,以及 订阅 提供成本可预测性和持续使用的节省。
基础设施可靠性:数据中心地理分布、网络性能、正常运行时间保证以及关键任务应用的灾难恢复能力。
开发者体验:预配置环境、API 可访问性、框架集成以及降低运营开销、加速开发周期的管理工具。
可扩展性:即时预配能力、从单 GPU 到分布式集群的弹性扩展,以及针对动态工作负载的自动化资源管理。
基于对这些标准的全面评估和实际使用经验,以下 11 家云 GPU 提供商在 AI 基础设施方面提供卓越的性能和价值:
1. Novita AI
Novita AI 提供可扩展且灵活的云 GPU 服务,针对 AI 训练、推理和高性能计算进行了优化。Novita AI 注重经济性和可靠性,通过透明且灵活的定价模型,为 AI 团队和企业提供即时访问尖端 GPU 硬件的途径。
主要特性:
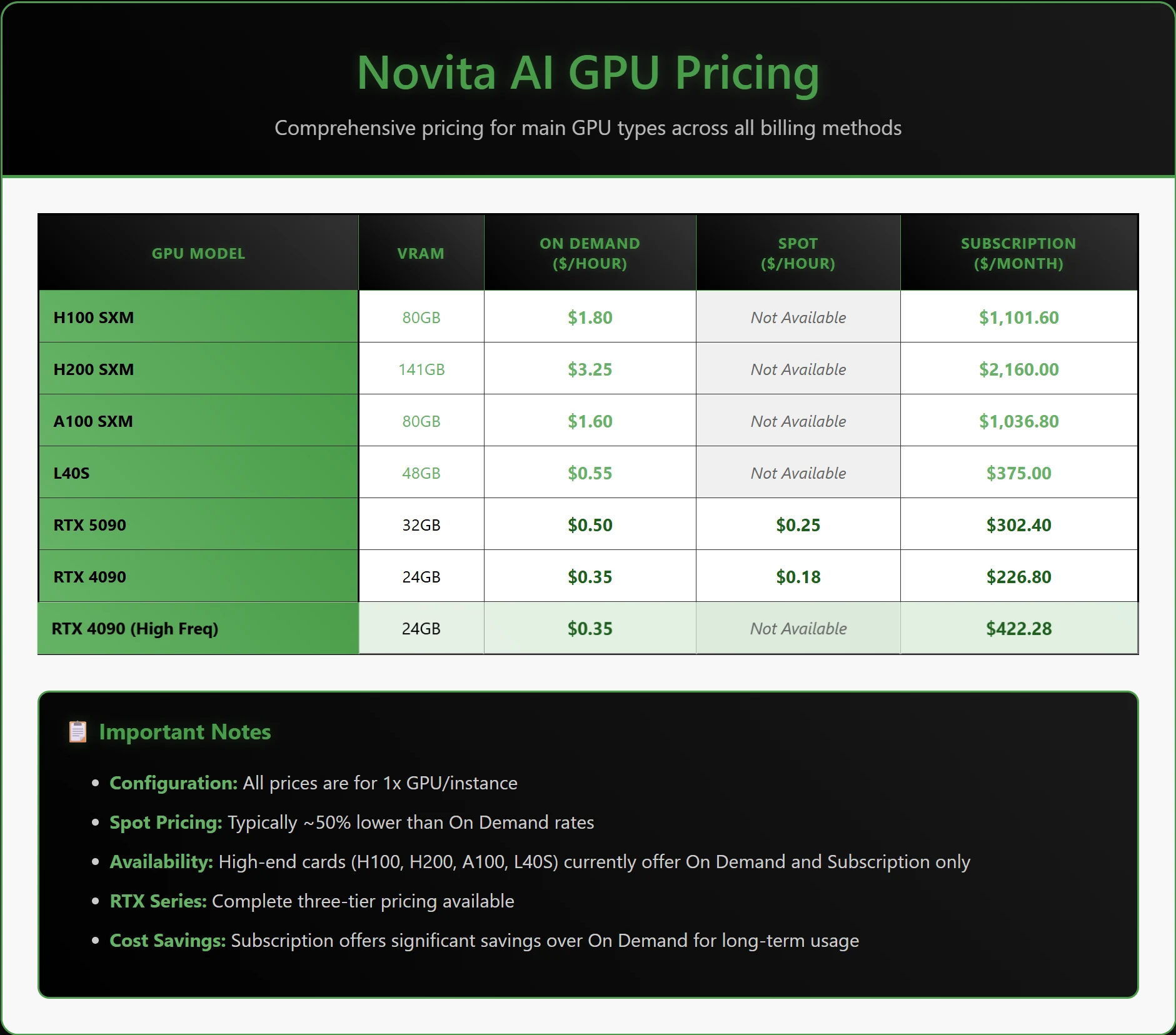
- 全面的 GPU 访问:提供多种 NVIDIA GPU,包括最新的 H100、H200、A100、L40S、RTX 5090 和 RTX 4090,适用于从小型实验到大规模模型训练的各种 AI 工作负载。
- 极其灵活的定价选项:提供灵活的定价模式,包括适用于稳定工作负载的按需实例、适用于可中断任务的 高达 50% 高折扣竞价实例、节省计划以及按量付费 API 模型。
- 全球分布式基础设施:GPU 实例部署在多个地理区域,确保分布式团队和应用的低延迟和高可用性。
- 集成监控与管理:实时了解 GPU 利用率和健康状况,配合易于使用的管理控制台,帮助用户优化性能和成本。
- 即用模板与自定义灵活性:预配置模板 消除了手动设置的复杂性,为流行模型提供优化配置,包括经过测试的部署参数、环境变量和容器配置。可立即开始使用 DeepSeek、Llama 及其他领先 AI 框架的模型。自定义模板支持为高级用户提供对其部署环境的完全控制权。创建具有个性化部署脚本、自定义软件栈和定制优化设置的专业配置。
定价
- 按需:随用随付的 GPU 资源,高可用性,即时访问。
- 竞价实例:针对容错工作负载的成本优化可中断 GPU 实例,最高节省 50%。
- 订阅:月度订阅,享受显著折扣。
Novita AI 最适合谁
- 需要广泛 GPU 选择、即时可扩展性且最少设置延迟的 AI 研究人员和开发者。
- 寻求经济高效、可靠且具有灵活计费和高可用性的 GPU 云基础设施的初创企业和企业。
- 运行分布式训练、批处理以及可使用竞价实例的推理工作流的团队。
- 希望通过 AI 模型 API 和托管 GPU 平台轻松集成,以加速创新和部署周期的企业。
开发者为何选择 Novita AI 作为云 GPU 提供商?
Novita AI 提供强大、可扩展的无服务器 GPU 解决方案,适用于各种用例,包括 AI 推理、机器学习、数据处理和渲染。借助灵活、按需的定价,用户无需前期成本即可访问高性能 GPU(如 NVIDIA A100),从而确保短期和长期项目的最高效率。Novita AI 支持无缝部署、自动扩展和微调,非常适合动态工作负载和资源密集型应用。此外,Novita AI 提供直观的控制面板,便于管理、高效分配资源并具有竞争力的定价,是寻求可靠、经济高效云 GPU 能力的开发者和企业的理想选择。
Novita AI 提供极具竞争力的高性价比定价——快来查看!
通过 API 设置竞价 GPU 的操作方式与其他 GPU 实例相同;唯一区别在于 billingMode 参数。
2. Google Cloud Platform (GCP)
将企业级 NVIDIA GPU 与专有 TPU 相结合,在 Google 强大的云生态系统内为 AI 训练和推理提供可扩展、灵活的基础。
主要特性:
- 高性能 GPU 和 TPU:将 NVIDIA GPU 与 Google 专有 TPU 结合,适用于多样化的 AI 工作负载。
- 集成 AI 生态系统:无缝连接 Vertex AI、BigQuery 和 Kubernetes Engine,实现端到端工作流。
- 灵活的 VM 配置:支持自动扩展和大规模部署的自定义。
- 全球私有网络:利用 Google 高性能全球网络,实现全球实例间的低延迟连接。
定价
- 按需实例
- 竞价实例
- 预留容量
最适合:需要可扩展、成熟的云解决方案进行实验和生产级 AI 规模化的企业和研究人员。
3. Microsoft Azure
提供一系列 GPU 增强型 VM,与微软生态系统紧密集成,专注于为企业 AI 工作负载提供安全、合规的混合云部署。
主要特性:
- 企业级安全与合规:支持受监管行业和混合云部署。
- 广泛的 GPU 产品:包括 NVIDIA A100、H100 和 V100 GPU,分布于 NC、ND 和 NV 系列 VM,适用于不同的 AI 和 HPC 应用。
- 微软生态系统集成:与微软服务紧密耦合,增强生产力和治理能力。
定价
- 按需实例
- 竞价实例
- 预留容量
最适合:需要与微软企业工具集成的安全、合规云 GPU 基础设施的组织。
4. Amazon Web Services (AWS)
提供全面的 NVIDIA GPU 驱动实例套件,拥有庞大的全球网络,适合已嵌入 AWS 生态系统、需要成熟可扩展 AI 基础设施的企业。
主要特性:
- 多样的 GPU 实例:提供 NVIDIA A100、H100 和 V100 GPU(P3、P4、P5 实例),适用于不同 AI 工作负载。
- 成熟的云生态系统:与 AI 和大数据服务深度集成。
- 灵活的实例类型:支持从初创公司到企业的大规模范围。
- Amazon SageMaker:一个全托管、端到端的平台,简化整个机器学习生命周期,从数据标注到模型部署。
定价
- 按需实例
- 竞价实例
- 预留容量
最适合:嵌入 AWS 生态、寻求可扩展、全球可用的 GPU 计算用于各种 AI 项目的团队。
5. NVIDIA DGX Cloud
提供基于 NVIDIA 最新硬件和软件的高性能、全托管 GPU 集群,针对大规模 AI 研究和企业训练。
主要特性:
- 托管多节点集群:专为大规模 AI 训练设计,配备顶级 NVIDIA GPU。
- 优化的 AI 软件:预配置的 NVIDIA AI 堆栈确保最佳性能。
- NVIDIA AI Enterprise 套件:包含全面的库、预训练模型以及 Triton 推理服务器和 TensorRT 等工具,针对 NVIDIA 硬件进行了优化。
- 直接访问 NVIDIA 专家:订阅包括 NVIDIA 专家的支持,帮助优化复杂的 AI 工作负载。
定价
- 月度订阅/租赁
最适合:需要超级计算级 AI 训练基础设施的研究实验室和企业。
6. CoreWeave
专注于高性能计算的云基础设施提供商,为要求苛刻的企业 AI 应用提供可扩展、灵活、低延迟的 GPU 资源。
主要特性:
- 弹性 GPU 基础设施:提供虚拟化和裸金属 GPU,灵活性高。
- 高可用性:适合 AI 工作负载和数字媒体渲染,支持快速扩展。
- Kubernetes 原生架构:GPU 作为 Kubernetes 的原生资源,相较于传统基于 VM 的方法,可实现更出色的调度、自动扩展和效率。
定价
- 按需实例
- 预留容量
最适合:需要可扩展、高性能 GPU 资源用于 AI 和媒体工作负载的企业。
7. Lambda Labs
专注于快速访问现代 NVIDIA GPU,预装 AI 框架,支持需要快速迭代的研究人员和开发者。
主要特性:
- 快速 GPU 预配:提供即时访问现代 NVIDIA GPU,并预装 AI 框架。
- 有竞争力的定价:针对快速研究和原型开发周期进行了优化。
- 持久文件系统:提供简单的共享存储,跨实例关闭持久化,便于管理数据集和代码。
定价
- 按需实例
- 预留容量
最适合:寻求快速 GPU 访问进行实验和模型迭代的开发者和研究人员。
8. Paperspace
提供用户友好的 GPU 云环境,预加载流行 ML 工具,适合开始 AI 项目的小团队和个人开发者。
主要特性:
- 开发者友好平台:包括预装的机器学习环境和 Jupyter 笔记本。
- 简单 UI 和 API:对初学者和专家都易于管理 GPU 实例。
定价
- 按需实例
- 订阅计划
最适合:需要快速、简单 GPU 云访问的小团队和个人开发者。
9. RunPod
提供即时容器化 GPU 环境,近乎零冷启动和灵活计费,满足敏捷原型开发和弹性 AI 工作负载。
主要特性:
- 即时容器化 Pod:近乎零冷启动延迟,灵活按秒计费。
- 广泛的 GPU 支持:自动扩展和多种 GPU 类型,满足弹性、突发工作负载。
定价
- 按需实例
最适合:需要快速、可扩展 GPU 访问进行原型设计和可变工作负载的团队。
10. Vast.ai
运营去中心化 GPU 市场,具有有竞争力的定价和灵活的硬件组合,吸引预算敏感型和突发工作负载用户。
主要特性:
- 众包 GPU 市场:连接用户与全球提供商未充分利用的 GPU,提高可用性。
- 成本高效的竞价定价:提供可中断和按需定价,大幅节省成本。
- 灵活访问:用户友好界面,支持 API 和 CLI。
定价
- 竞价实例
- 按需实例
最适合:寻求跨各种硬件的灵活、经济 GPU 租赁选项的成本敏感用户。
11. IBM Cloud
专注于安全、合规的混合云 GPU 解决方案,与 IBM AI 产品组合集成,服务于受监管行业和企业客户。
主要特性:
- 混合云 GPU 解决方案:强大的安全性和合规性,适用于受监管行业。
- IBM Watson 集成:与企业工作流深度集成 AI 平台。
定价
- 按需实例
- 预留容量
最适合:需要安全、混合 GPU 云基础设施的受监管企业。
根据需求选择合适的提供商
不同的用例对云 GPU 提供商有不同要求:
1. 成本敏感型应用
Novita AI:竞价实例最高可节省 50%,并提供灵活的按调用付费 API 定价。
Vast.ai:去中心化市场,针对预算敏感用户提供有竞争力的竞价定价。
Lambda Labs:针对快速研究和原型开发周期优化了竞争力的定价。
2. 性能关键型应用
NVIDIA DGX Cloud:超级计算级基础设施,配以优化的 AI 软件栈。
Novita AI:企业级性能,实时监控和全球分布。
CoreWeave:Kubernetes 原生架构,高性能、低延迟 GPU 资源。
3. 企业需求
Microsoft Azure:企业级安全、合规和混合云集成。
Amazon Web Services (AWS):成熟的生态系统,全面的 AI 服务和全球可用性。
IBM Cloud:针对受监管行业的安全合规解决方案,集成 Watson AI。
4. 开发者体验
Novita AI:通过 API 提供 200 多种预构建 AI 模型,部署无缝,DevOps 需求极低。
Paperspace:用户友好平台,预装 ML 环境,管理简单。
RunPod:即时容器化环境,近乎零冷启动。
常见问题解答
什么是 GPU 云提供商?
GPU 云提供商通过互联网提供对强大图形处理单元的远程访问,允许用户租用 GPU 计算能力用于 AI 和机器学习任务,而无需拥有物理硬件。
如何在云上使用 GPU?
在提供商处注册,选择 GPU 实例,启动预装框架的实例,然后通过 Web 界面或 API 运行工作负载。
哪个 GPU 实例提供商最好?
这取决于您的需求——Novita AI 具有竞争力的定价,AWS 提供全面生态系统,Google Cloud 则提供 TPU 集成。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的简便方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。



