

立即推荐好友,**你们双方均可获得 $10 的 LLM API 额度 **——总计最高 $500 奖励 等你来拿!
Llama 3.2 1B、Qwen2.5 7B、Qwen 3 (0.6B、1.7B、4B)、GLM 4 —— 现已在 Novita AI 上线,无需花费一分钱即可赋能您的项目!
重排序模型(Reranker)通过优化初始检索文档的顺序,在提升 AI 搜索系统准确性方面发挥着关键作用。
Qwen 3 Reranker 8B 在多语言和代码相关任务上展现出卓越的基准性能。通过 Novita AI 的 API 平台,开发者可以轻松地将其强大的重排序能力集成到自己的应用中。
什么是重排序模型?
重排序模型(Reranker)是一种专门的 AI 模型,它根据特定查询的相关性,对一组初始检索到的文档或条目进行重新排序。通常,在初始检索阶段(使用 BM25 或基于嵌入的搜索等方法)之后,重排序模型会更精确地评估 top-k 结果,以确保最相关的条目获得优先排序。
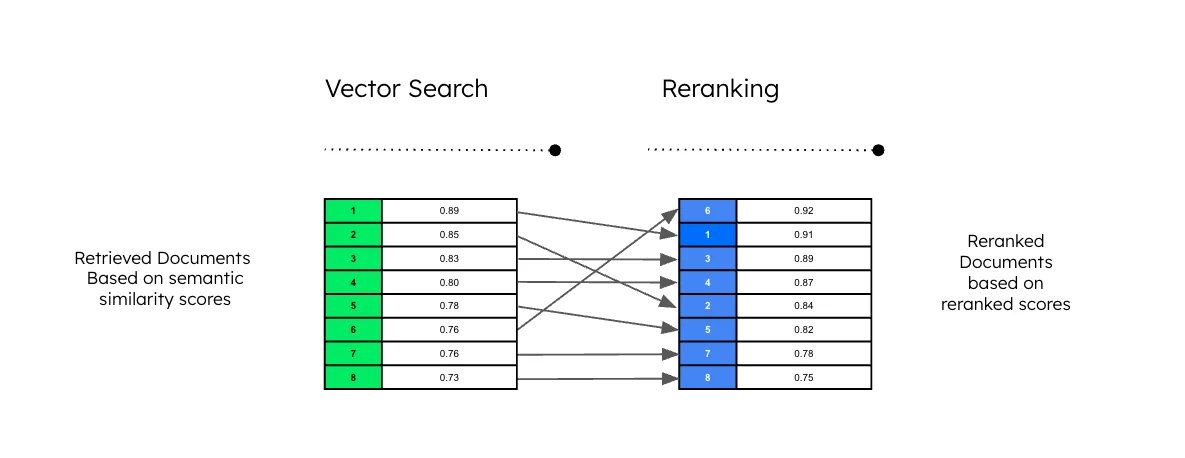
来自 mongodb
重排序模型是为查询和检索到的文档分配相关性分数的模型。通过基于相关性对文档进行评分,重排序模型能够选择出初始检索结果中最相关的文档子集,从而提升检索准确性。
重排序模型解决的问题
- 增强相关性:优化初始搜索结果,使其更好地匹配用户意图。
- 降低噪声:过滤掉不相关的条目,提升信息呈现质量。
- 改进 RAG 系统:在 RAG 流水线中,重排序模型确保最相关的文档被用于生成响应。
如何评估重排序模型
- MTEB-R:来自 MTEB(大规模文本嵌入基准)的英文检索任务。
- CMTEB-R:来自 MTEB 的中文检索任务(聚焦中文语言性能)。
- MMTEB-R:多语言检索任务(跨多种语言进行评估)。
- MLDR:多语言长文档检索(测试多种语言的长文本检索能力)。
- MTEB-Code:代码相关检索任务的基准测试(例如代码搜索、代码理解)。
- FollowIR:衡量模型在搜索查询中遵循复杂用户指令的能力。
重排序模型 vs 嵌入模型
| 方面 | 嵌入模型 | 重排序模型 |
|---|---|---|
| 功能 | 基于向量相似度检索文档 | 基于相关性重新排序检索到的文档 |
| 效率 | 高(适用于大规模检索) | 较低(用于对较小集合进行重新排序) |
| 准确性 | 中等 | 高 |
| 使用场景 | 初始检索 | 检索后精炼 |
什么是 Qwen 3 重排序模型?
| 模型 | 参数量 | 层数 | 序列长度 | 指令感知 |
| Qwen3-Reranker-0.6B | 28 | 32K | 32K | 是 |
| Qwen3-Reranker-4B | 4B | 36 | 32K | 是 |
| Qwen3-Reranker-8B | 8B | 36 | 32K | 是 |
Qwen 3 重排序模型如何工作?
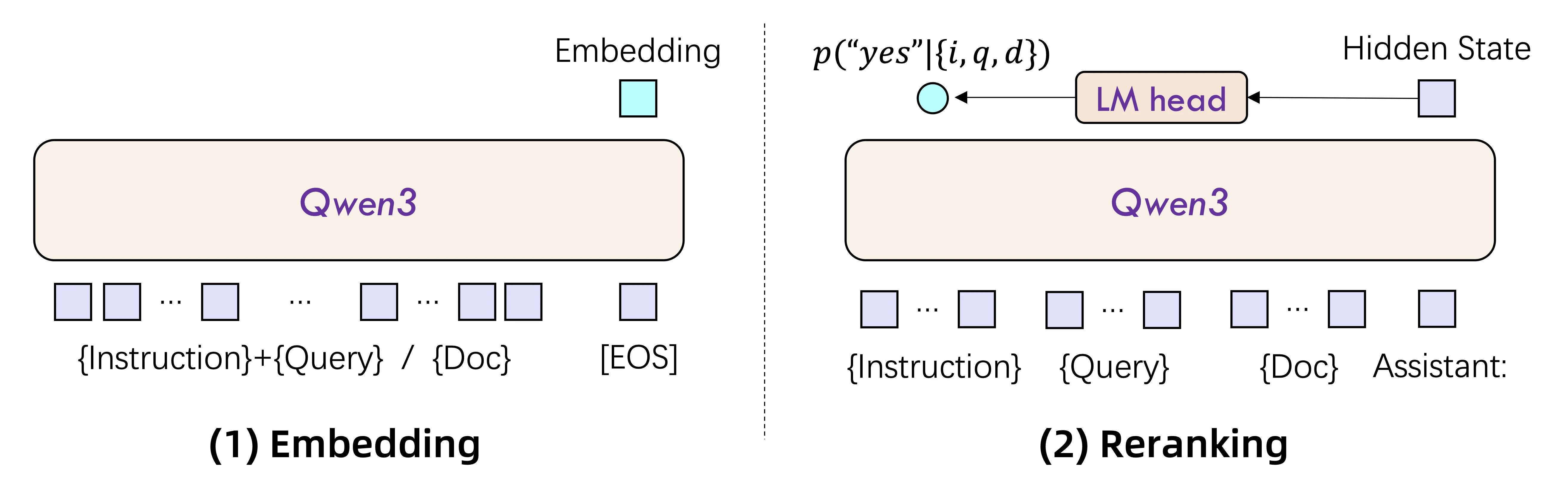
来自 Qwen
嵌入(Embedding)
目标:将文本转化为向量,以便高效搜索和比较。
-
输入:
{指令} + {查询} / {文档} [EOS]- 模型将 查询 ** 和 ** 文档 以组合输入格式呈现。
-
经过 Qwen3 模型 处理,在末尾(
[EOS]处)获取一个隐藏状态(类似于“摘要向量”)。 -
该向量即成为 **嵌入 ——一种用数字表示文本的方式,以便与其它文本 ** 进行比较。
重排序(Reranker)
目标:给出一个智能分数,指示文档与查询的匹配程度。
-
输入:
{指令} + {查询} + {文档} Assistant:- 这是一个更详细的输入——Qwen3 将查询和文档 一起 读取,如同逐行对比。
-
模型采用 交叉编码器 结构,对两段文本进行深度比较。
-
然后,LM 头(语言模型头)给出一个分数(例如“是”的概率)。
- 该分数告诉我们:“该文档与查询的相关性有多高?”
Qwen 3 重排序模型的基准性能
| 模型 | 参数量 | MTEB-R | CMTEB-R | MMTEB-R | MLDR | MTEB-Code | FollowIR |
|---|---|---|---|---|---|---|---|
| Jina-multilingual-reranker-v2-base | 0.3B | 58.22 | 63.37 | 63.73 | 39.66 | 58.98 | -0.68 |
| gte-multilingual-reranker-base | 0.3B | 59.51 | 74.08 | 59.44 | 66.33 | 54.18 | -1.64 |
| BGE-reranker-v2-m3 | 0.6B | 57.03 | 72.16 | 58.36 | 59.51 | 41.38 | -0.01 |
| Qwen3-Reranker-0.6B | 0.6B | 65.80 | 71.31 | 66.36 | 67.28 | 73.42 | 5.41 |
| Qwen3-Reranker-4B | 4B | 69.76 | 75.94 | 72.74 | 69.97 | 81.20 | 14.84 |
| Qwen3-Reranker-8B | 8B | 69.02 | 77.45 | 72.94 | 70.19 | 81.22 | 8.05 |
您可以在这个排行榜上查看嵌入模型的评估结果!
如何访问 Qwen 3 重排序模型?
Novita AI 是一个 AI 云平台,为开发者提供简单的 API 来部署 AI 模型,同时还提供经济可靠的 GPU 云用于构建和扩展。
除了 Qwen 3 Reranker 8B 和 Embedding 8B 之外,Novita AI 还免费提供 bge-m3 以支持开源社区的发展!
第 1 步:登录并访问 模型库
登录您的账户,点击 模型库 按钮。

第 2 步:选择模型并开始免费试用
浏览可用选项,选择适合您需求的模型。
第 3 步:获取您的 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“设置”页面,您可以按照图中所示复制 API 密钥。

第 4 步:安装 API
使用您编程语言对应的包管理器安装 API。
安装完成后,将必要的库导入到您的开发环境中。使用您的 API 密钥初始化 API,开始与 Novita AI 模型交互。这是一个面向 Python 用户的聊天补全 API 示例。
from openai import OpenAI
base_url = "https://api.novita.ai/v3/openai"
api_key = "<您的API密钥>"
model = "qwen/qwen3-reranker-8b"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # 或 False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
随着 AI 应用对用户意图理解精度的要求越来越高,重排序模型已成为提供更智能搜索结果的必备工具。作为初始检索后的第二层智能模块,重排序模型通过更深入的上下文分析来微调文档排名。**Qwen 3 重排序系列 ** 在该领域树立了新的标杆,在跨语言、长文档甚至代码检索任务上均表现出色。通过 Novita AI 的简化部署,开发者无需繁重的基础设施即可利用这些先进模型——让高精度检索变得比以往任何时候都更易获取。
常见问题
什么是重排序模型?
重排序模型通过对检索到的文档列表进行相关性评分并重新排序,从而提升 AI 搜索系统的精确度。
重排序模型与嵌入模型有何不同?
嵌入模型:将每个文本转换为向量,并通过相似度进行比较。
重排序模型:将查询和文档一起读取,并给出一个智能相关性分数。
Qwen 3 重排序模型的性能如何?
Qwen3-Reranker-8B 取得了顶尖分数:
MTEB-R:69.02,
CMTEB-R:77.45,
MTEB-Code:81.22
在多个类别中优于 BGE 和 GTE 等热门模型。
Novita AI 是一个一体化云平台,为您的 AI 愿景提供动力。集成 API、无服务器计算、GPU 实例——您需要的经济高效的工具。无需基础设施、免费开始,将您的 AI 愿景变为现实。



