What is LLM Embeddings: All You Need To Know

Discover the world of LLM embeddings, from classic techniques to modern advancements like Word2Vec and ELMo. Learn how fine-tuning and vector embeddings impact natural language processing tasks and find the right approach for your projects. Explore the democratization of advanced techniques with open-source LLM embeddings, and make informed decisions for optimal results.
Introduction
Embeddings serve as fundamental components within large language models, which in turn comprise various essential elements facilitating the adept processing and comprehension of natural language data.
A large language model (LLM) belongs to the realm of artificial intelligence models, trained extensively on vast troves of textual data. This corpus encompasses a diverse array of sources, ranging from literature and publications to online content like websites and social media interactions. By discerning and internalizing the statistical correlations between words, phrases, and sentences within this corpus, the LLM gains the capacity to generate text resembling that which it was trained on.

What is LLM Embedding
In the vibrant field of natural language processing (NLP), embeddings play a pivotal role. Put simply, they are mathematical depictions of words within a multi-dimensional space. Embeddings within large language models (LLMs) leverage the nuanced comprehension these models possess, consolidating intricate semantic and syntactic insights into a singular vector. It’s not just about generating text; it’s about encapsulating the very essence, the indefinable quality, of language in numerical representation.
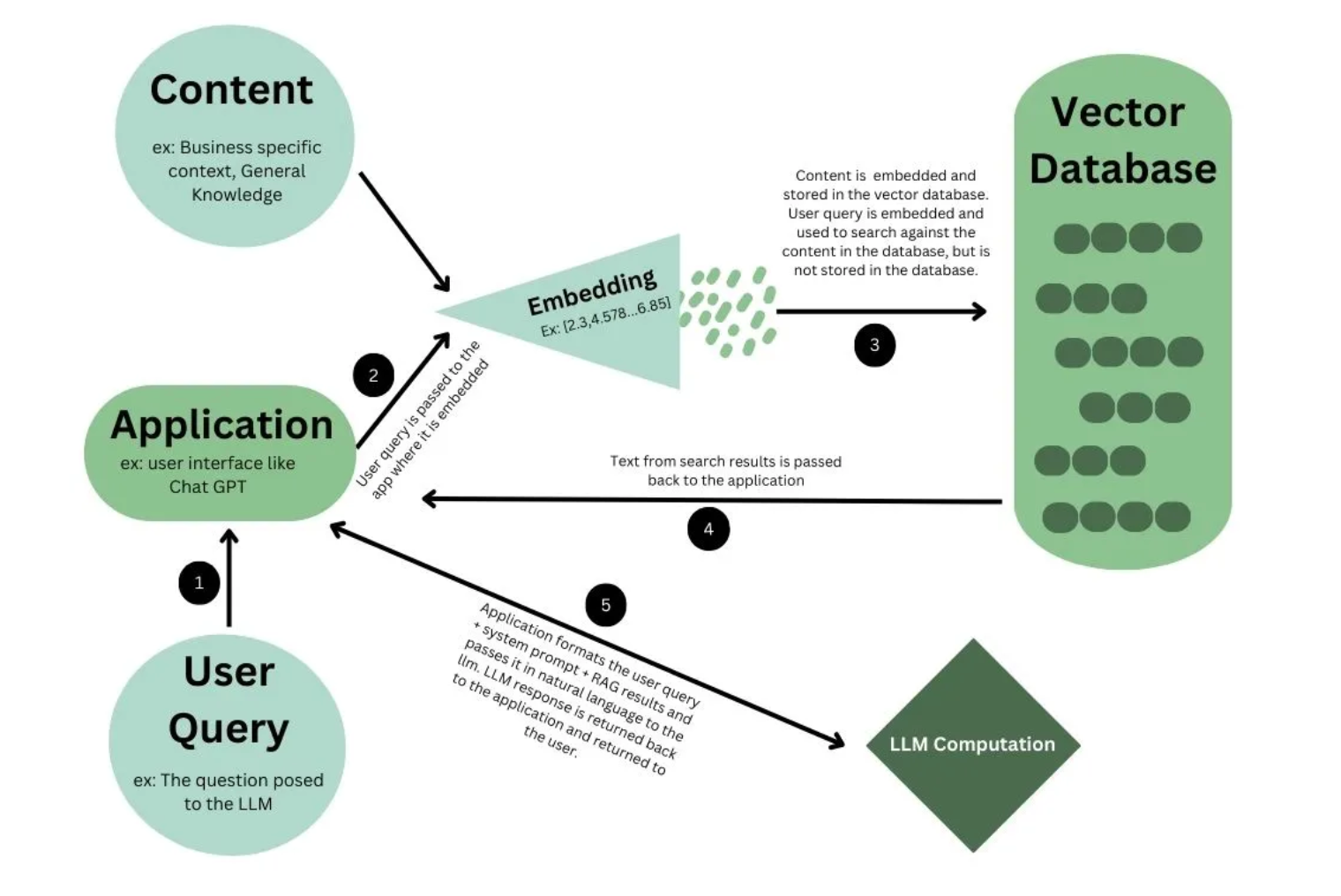
Types of embeddings

Classic approaches to embeddings
In the early days of natural language processing (NLP), embeddings were simply one-hot encoded. Zero vector represents each word with a single one at the index that matches its position in the vocabulary.
One-hot encoding
One-hot encoding stands as the simplest method for embedding words, representing each word with a vector of zeros except for a single one at the index corresponding to the word’s position in the vocabulary. For instance, in a vocabulary of 10,000 words, the word “cat” would be depicted as a vector with 10,000 zeros and a single one at index 0.
While one-hot encoding offers a straightforward and effective means to represent words as numerical vectors, it overlooks contextual nuances. This limitation becomes apparent in tasks like text classification and sentiment analysis, where a word’s meaning hinges on its context.
Take the word “cat,” for example, which can denote various concepts such as “a small furry mammal” or “to hit someone with a closed fist.” In one-hot encoding, both meanings would be represented by the same vector, posing challenges for machine learning models in discerning the intended meaning of words.
TF-IDF
TF-IDF (term frequency-inverse document frequency) serves as a statistical metric utilized to gauge the significance of a word within a document. It’s a prevalent technique in natural language processing (NLP) applied across tasks such as text classification, information retrieval, and machine translation.
The TF-IDF value is computed by multiplying the term frequency (TF), representing how frequently a word occurs in a document, by its inverse document frequency (IDF), which indicates the rarity of the word across the corpus of documents.
A high TF-IDF score is assigned to words that occur frequently within a document but are rare across the entire corpus. Consequently, TF-IDF scores assist in identifying words that hold importance within a document, even if they have low occurrence rates overall.
Count-based and TF-IDF
In response to the constraints of one-hot encoding, count-based and TF-IDF methods were introduced. These approaches consider the frequency of words within a document or corpus.
Count-based techniques involve straightforwardly tallying the occurrences of each word in a document. Conversely, TF-IDF methods incorporate both the word frequency and its inverse document frequency.
Compared to one-hot encoding, count-based and TF-IDF techniques offer improved efficacy in capturing word context. Nevertheless, they still fall short of capturing the semantic nuances inherent in words.
Semantic encoding techniques
The latest advancement in word embedding approaches involves semantic encoding techniques, which utilize neural networks to derive vector representations of words that encapsulate their semantic significance.
Among these techniques, Word2Vec stands out as one of the most prominent. Word2Vec employs a neural network to predict the neighboring words within a sentence, facilitating the learning of associations between words with similar semantic meanings, reflected in their vector representations.
Semantic encoding techniques represent the most efficient method for capturing the semantic essence of words. They excel in capturing intricate relationships between words across long distances within text, and they possess the capability to decipher the meaning of previously unseen words. Here are a few additional examples of semantic encoding techniques:
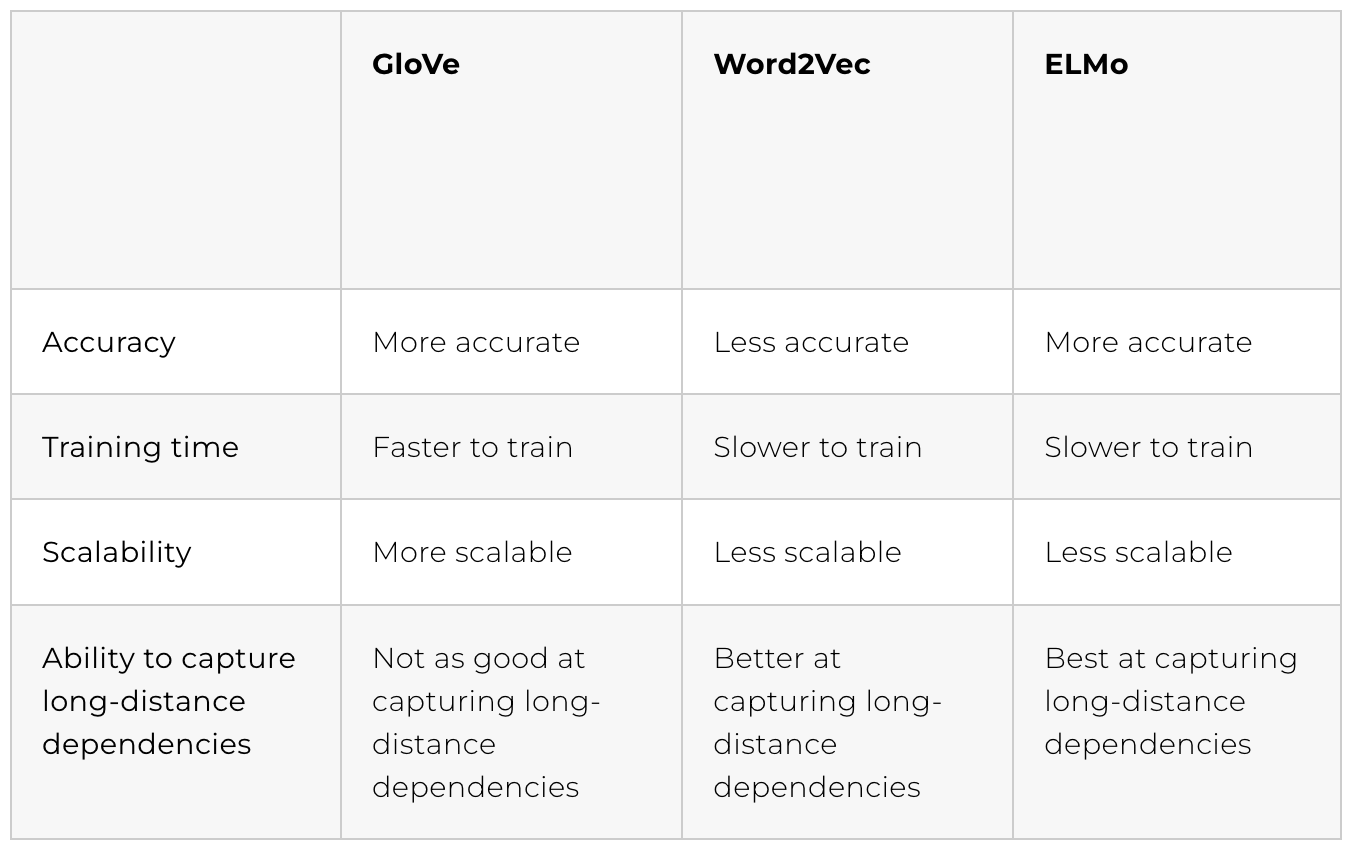
ELMo: Embeddings from language models
ELMo represents a novel form of word embedding that integrates both word-level attributes and contextual semantics. It achieves this by leveraging the outputs from all layers of a deep bidirectional language model (bi-LSTM) and aggregating them with weighted fusion. This unique approach enables ELMo to capture not only a word’s meaning within its context but also its inherent characteristics.
The rationale behind ELMo lies in the premise that the upper layers of the bi-LSTM model grasp contextual cues, whereas the lower layers capture syntactic nuances. Empirical evidence supports this, demonstrating that ELMo surpasses other word embedding techniques in various tasks such as part-of-speech tagging and word sense disambiguation.
During training, ELMo is tasked with predicting the subsequent word in a sequence, a task known as language modeling. Consequently, it develops a profound understanding of word relationships. When assigning an embedding to a word, ELMo takes into consideration its neighboring words within the sentence, enabling it to generate distinct embeddings for the same word based on its contextual usage.
GloVe
GloVe stands as a statistical technique employed to acquire word embeddings from a given corpus of text. Although akin to Word2Vec, GloVe adopts a distinct methodology for deriving vector representations of words.
Word2Vec
Word2Vec stands as a semantic encoding method utilized for acquiring vector representations of words, which in turn capture their meanings. These word vectors prove instrumental in bolstering machine learning models across various tasks such as text classification, sentiment analysis, and machine translation.
The operational principle of Word2Vec involves training a neural network on a given corpus of text. During this process, the neural network learns to forecast the neighboring words within a sentence. Through this training, the network establishes associations between words that share semantic similarities, thereby generating comparable vector representations.
Fine-Tuning vs Embedding
Imagine being tasked with deciphering a completely unfamiliar language from scratch — that’s akin to delving into the world of LLM embeddings for the first time. Here, fine-tuning and embedding strategies step in to aid understanding. Fine-tuning resembles the process of acquiring tailor-made clothing; it adapts the pre-trained LLM to suit specific tasks precisely. On the other hand, embedding is more universal and less bespoke, akin to off-the-shelf attire — functional but lacking personalized fit. Thus, when deciding between LLM fine-tuning and embedding, consider the level of customization you require.
Within the realm of machine cognition, the discourse around LLM fine-tuning versus embedding sparks vigorous debates. Despite their differences, both approaches share a common objective: enhancing the model’s contextual comprehension.
Fine-Tuning
Fine-tuning an LLM (Large Language Model) resembles a sculptor meticulously refining a block of marble. In this analogy, the base model represents the raw material, while fine-tuning transforms it into a masterpiece with distinct, tailored characteristics. Due to its intricate nature, fine-tuning typically necessitates substantial time and computational resources. However, it excels in projects demanding precision and customization, as it modifies the model to fulfill specific requirements, resulting in unparalleled accuracy and efficacy.
If you are interested in hot to fine-tune LLMs, you can get more detailed information in our blog: How to Fine-Tune Large Language Models?

Fine-tuning an LLM involves adjusting its internal configurations, akin to tuning a musical instrument for a specific composition. While resource-intensive and time-consuming, this method yields tailored outcomes tailored for specialized tasks.
In contrast, vector embedding serves as a snapshot of a language model’s essential linguistic attributes, emphasizing rapid retrieval over fine-grained precision. In essence, fine-tuning offers bespoke utility at a higher computational expense, while vector embedding provides a quick-and-dirty overview that’s more economical in terms of computing resources.
Vector Embedding: The Snapshot Technique
Vector embedding within LLMs can be likened to capturing a snapshot of a favorite moment from a video. In this analogy, the video represents the comprehensive LLM. The snapshot encapsulates the overall essence or context, albeit without the finer details. Generating vector embeddings is swift and requires fewer resources compared to fine-tuning. However, they tend to offer slightly lower accuracy and flexibility for specialized tasks. It’s akin to utilizing a versatile tool suitable for most purposes but potentially lacking the precision required for certain specialized endeavors.
Open-Source LLM Embeddings
The emergence of open-source LLM embeddings adds an intriguing dimension to the discourse. These open-source options democratize access to sophisticated machine-learning methods, dismantling barriers and facilitating the integration of LLM embeddings into various projects for developers and researchers alike. While they may lack the customized precision of fine-tuning, their accessibility and lower resource requirements render them highly favored for smaller projects or academic research endeavors.
Choose Your LLM Wisely
When confronted with an array of techniques, the choice of LLM approach transcends mere importance — it becomes indispensable. Do you opt for the labor-intensive, meticulously tailored path of fine-tuning, or does the swifter yet less specialized domain of vector embedding align better with your goals? Your decision hinges on a multifaceted balancing act, encompassing factors such as available computational resources, project scope, and specific requirements.

Conclusion
In the ever-evolving landscape of natural language processing, understanding the intricacies of LLM embeddings is essential. From classic techniques like one-hot encoding and TF-IDF to modern advancements such as semantic encoding with Word2Vec and ELMo, each approach offers unique insights into capturing the essence of language. Whether fine-tuning for precision or utilizing vector embeddings for efficiency, the choice of LLM approach depends on various factors, including computational resources and project requirements. With the advent of open-source LLM embeddings, accessibility to advanced techniques has never been easier, empowering developers and researchers alike. Ultimately, selecting the right LLM approach involves a careful consideration of these factors to achieve optimal results in natural language processing tasks.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
What is the difference between LLM and GPT
LLM Leaderboard 2024 Predictions Revealed
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available