Mixtral 8x7b quantized vs Mistral: Which One Is Better?

Key Highlights
Overview of Mistral 7B
- Parameters: 7.3 billion.
- Performance: Outperforms larger models like Llama 2 13B.
- Innovations: Grouped-query attention (GQA) for faster inference; Sliding Window Attention (SWA) for handling longer sequences.
- Licensing: Apache 2.0 license for unrestricted use.
Overview of Mixtral 8x7B Quantized Model
- Advanced Quantization: 4-bit quantization to reduce memory footprint.
- Efficient Inference: Faster and more resource-efficient, suitable for consumer-grade hardware.
- Mixture of Experts (MoE): Selects relevant “experts” for different input parts, scaling efficiently.
- Multilingual: Supports multiple languages and excels in coding tasks.
Introduction
Welcome to our comprehensive overview of the Mistral and Mixtral model families, two groundbreaking language models developed by Mistral AI. In this blog, we will explore the features, performance, and unique innovations of the Mistral 7B and Mixtral 8x7B quantized models. We will delve into the advanced techniques employed by these models, such as quantization and Mixture of Experts (MoE), and provide a detailed comparison of their capabilities and hardware requirements. Whether you’re an AI enthusiast or a professional in the field, this guide will help you understand the remarkable advancements these models bring to the table.
Overview of Mistral 7b
Mistral 7B is a powerful 7.3 billion parameter language model developed by Mistral AI. Its standout features include:
Superior Performance Over Llama
It outperforms larger models like Llama 2 13B on various benchmarks, showcasing efficiency.
Innovative Attention Mechanisms
Utilizes Grouped-query attention (GQA) for faster inference and Sliding Window Attention (SWA) to handle longer sequences effectively.
Open Licensing
Released under the permissive Apache 2.0 license, allowing unrestricted use and deployment across different platforms.
Overview of Mixtral 8x7b Quantized Model
Mixtral 8x7b quantized is a large language model that incorporates advanced quantization techniques to optimize performance and efficiency:
- Advanced Quantization: Utilizes state-of-the-art quantization methods such as 4-bit quantization, which significantly reduces the model’s memory footprint without substantially compromising performance.
- Efficient Inference: The quantized model enables faster and more resource-friendly inference, making it suitable for deployment on consumer-grade hardware with limited computational resources.
- Mixture of Experts: Integrates an MoE layer that efficiently processes information by selecting the most relevant “experts” for different parts of the input, allowing it to scale and perform like a much larger model.
- Multilingual Capabilities: Just like the full-precision model, the quantized Mixtral 8x7b supports multiple languages, including English, French, German, Spanish, and Italian, and also excels in coding tasks.
The Mixtral 8x7b Quantized can be seen as a successor or a specialized version of the Mistral 7B, incorporating both the architectural innovations of the MoE approach and the efficiency improvements brought by quantization. Therefore, in order to further understand the differences between Mixtral 8x7b quantized vs Mistral, we are going to explore quantization and the MoE approach.
Mixtral 8x7b quantized vs Mistral: Understanding Quantization
Quantization, one of the major distincetive features of Mixtral 8x7b quantized, as introduced in the provided article, pertains to the process of reducing the precision of the model’s weights to lower bits, which in turn significantly decreases the model’s memory footprint. This is achieved without substantially degrading the model’s performance on finetuning tasks. Here’s a concise and professional overview of how quantization is applied and its significance:
Application of Quantization in Mixtral 8x7b quantized
- QLORA Method: The QLORA (Quantized Low-rank Adapters) approach is utilized to finetune the Mixtral 8x7b model at a mere 4-bit precision. This method allows for the backpropagation of gradients through a frozen, 4-bit quantized pretrained language model into Low-Rank Adapters (LoRA).
- Innovations: The QLORA approach introduces several innovations such as:
- 4-bit NormalFloat (NF4): A new data type that is information-theoretically optimal for normally distributed weights, providing better empirical results than traditional 4-bit representations.
- Double Quantization: A technique that further reduces memory usage by quantizing the quantization constants themselves, leading to additional memory savings.
- Paged Optimizers: A strategy to manage memory spikes, particularly useful when processing mini-batches with long sequence lengths.
Significance of Quantization
- Memory Efficiency: The primary significance of quantization in the Mixtral 8x7b model is the dramatic reduction in memory requirements, making it feasible to finetune large models on GPUs with limited VRAM.
- Accessibility: By reducing the memory footprint, quantization democratizes access to finetuning large language models, as it becomes possible to perform such tasks on consumer-grade hardware that would typically be unable to handle the memory load of full-precision models.
- Performance Preservation: Despite the reduced precision, the QLORA method ensures that the finetuned model maintains performance comparable to that of a model finetuned at full 16-bit precision.
- Scalability: Quantization allows for the training of larger models than would otherwise be possible, given the memory constraints of standard hardware. This paves the way for further scaling in model size while keeping resource consumption in check.
Different types of Mixtral 8x7b Quantized Models
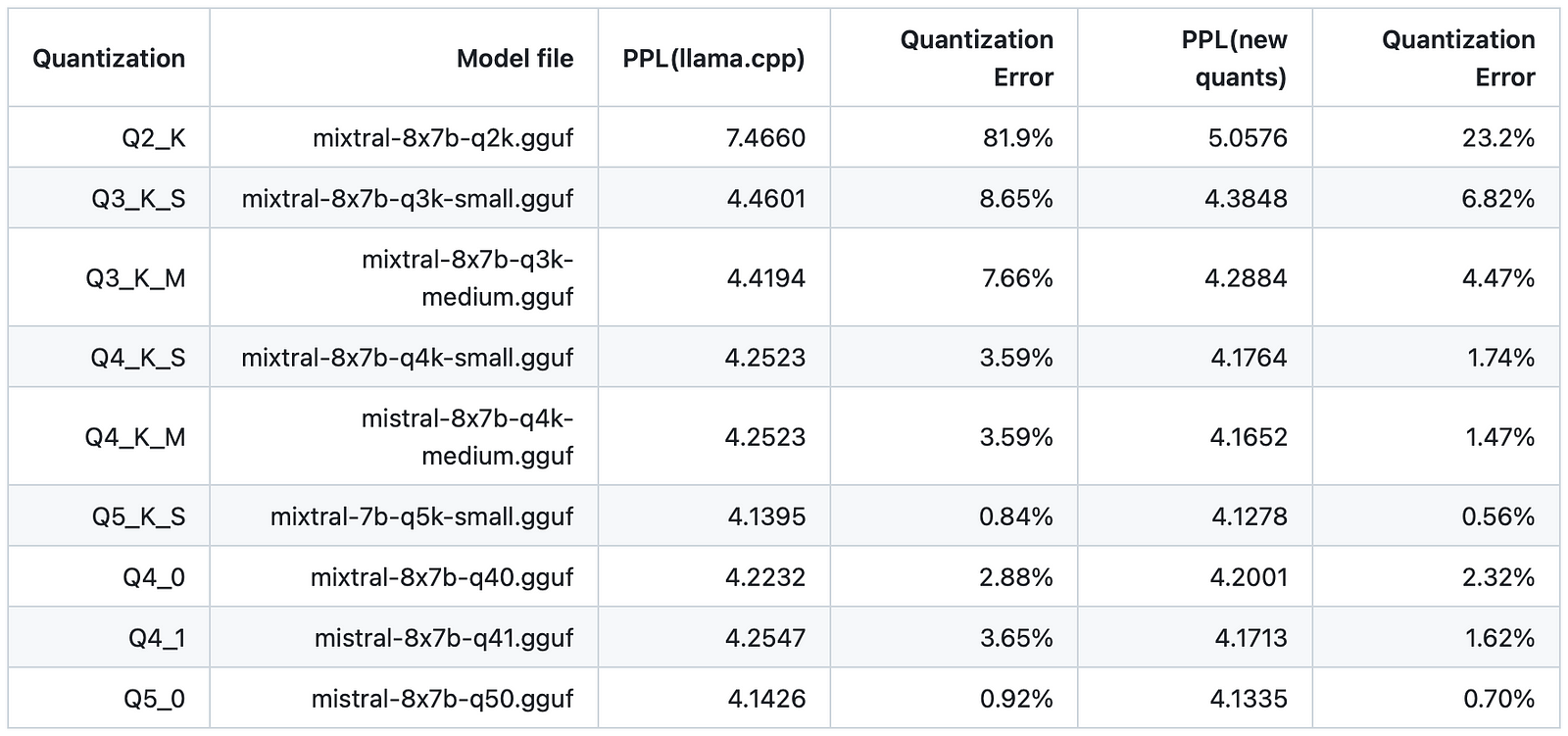
Ikawrakow on Github summarized a comparison between different types of Mixtral 8x7b quantized models and the current llama.cpp quantization approach using Wikitext perplexities for a context length of 512 tokens.
“Quantization Error” is defined as (PPL(quantized model) - PPL(int8))/PPL(int8).
Mixtral 8x7b quantized vs Mistral: Understanding MoE
Mixture of Experts (MoE) is an advanced machine learning paradigm that introduces sparsity into deep learning models, particularly in the context of neural networks. Traditional neural networks use the same set of parameters for all inputs. In contrast, MoE models consist of a pool of specialized experts, each capable of handling different subsets of the input space. A gating mechanism or router determines the activation of these experts based on the input data.
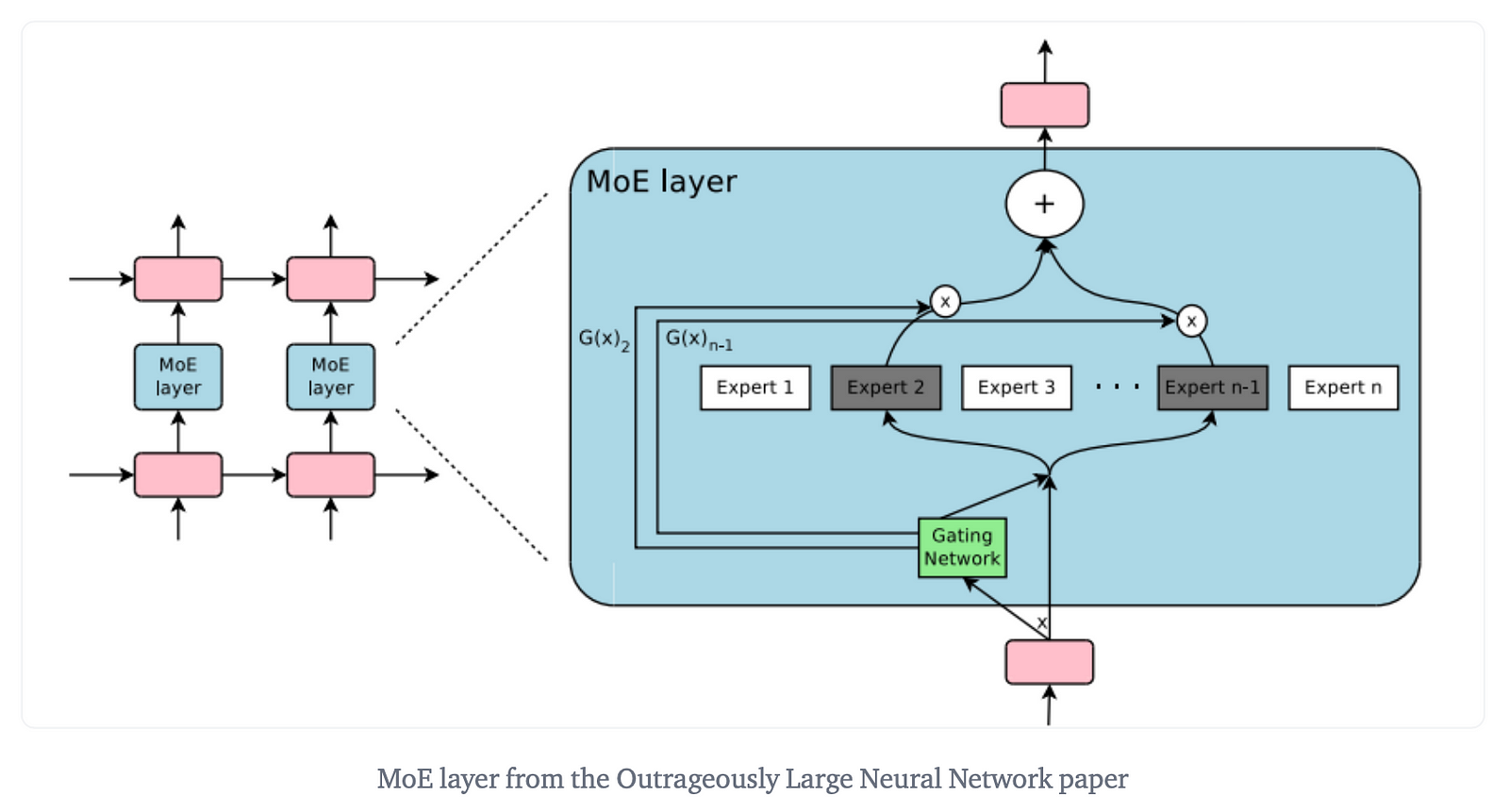
Application of MoE in Mixtral 8x7b
Mixtral 8x7b leverages the MoE framework to achieve high performance with efficient computation. In this model, the traditional dense feed-forward networks (FFNs) are replaced with MoE layers, which consist of multiple experts. Each expert is a smaller neural network that specializes in handling specific aspects of the input data. The router in Mixtral 8x7b dynamically selects the most relevant experts for each token, enabling the model to focus computational resources on the most informative parts of the input.
This application of MoE in Mixtral 8x7b allows the model to scale up to billions of parameters while maintaining fast inference speeds. It also enables the model to handle longer sequences and achieve state-of-the-art results in various natural language processing tasks.
Significance of MoE
The significance of MoE lies in its ability to combine the strengths of large-scale models with the efficiency of sparse computation. Here are some key points that highlight its importance:
- Scalability: MoE allows for the creation of models with an unprecedented number of parameters without a corresponding increase in computational costs, making it possible to train and deploy models that were previously unfeasible.
- Efficiency: By activating only a subset of experts for each input, MoE models can process information more efficiently, leading to faster inference times compared to dense models of similar size.
- Adaptability: MoE models can adapt to diverse and complex data distributions by specializing different experts to different aspects of the data, potentially improving performance on a wide range of tasks.
- Resource Optimization: MoE enables better utilization of hardware resources by reducing the need for excessive computational power and memory bandwidth, which is crucial for deploying models on resource-constrained devices.
Mixtral 8x7b quantized vs Mistral: Applications and Use Cases
Research and Development:
Both models can be valuable in research and development settings, where the exploration of cutting-edge language models can lead to advancements in AI technology. The choice between the two may depend on the specific focus of the research, such as the trade-off between performance and efficiency.
Commercial Deployments:
For commercial applications where the balance of performance and resource utilization is critical, the quantized Mixtral 8x7b might offer a more practical solution. It provides a good compromise between the model’s capabilities and the hardware requirements.
Multilingual Applications:
Given that both models are capable of handling multiple languages, they can be deployed in multilingual environments for applications like cross-lingual translation, multilingual content creation, and language learning tools.
Inference-Intensive Tasks:
The quantized Mixtral 8x7b may perform better in inference-intensive tasks where speed and efficiency are critical, such as real-time conversational AI, chatbots, and customer service automation.
Mixtral 8x7b quantized vs Mistral: Performance and Hardware Requirements
Mixtral 8x7b quantized vs Mistral: Performance Comparison
Although the performance data for Mixtral 8x7B in its quantized form is not publicly available, Ingrid Stevens conducted some experiments with various prompts to test Mixtral-8x7B on Vercel and Mixtral-8x7B Q3_K_M on an M1 chip, comparing them to ChatGPT 3.5. She concluded that there is no significant difference between the quantized and non-quantized versions of Mixtral 8x7B. Therefore, to compare the performance of Mixtral 8x7B quantized with Mistral 7B, it is practical to use the benchmark performance of Mistral 7B and Mixtral 8x7B as listed on the Huggingface Open LLM Leaderboard.

- Average Score: The Mixtral 8x7B has a higher average score (19.23) compared to the Mistral 7B (14.17), indicating that on average, the Mixtral 8x7B performs better across the evaluated tasks.
- IFEval: The Mixtral 8x7B achieves a higher score (23.5) on the IFEval benchmark, which assesses the model’s ability to follow instructions, compared to the Mistral 7B (22.66).
- BBH: On the BBH benchmark, which tests the model’s ability to answer questions about a given text, Mixtral 8x7B shows improved performance with a score of 29.73 versus 24.04 for Mistral 7B.
- MATH Lvl 5: For mathematical reasoning at the 5th level, Mixtral 8x7B significantly outperforms Mistral 7B, with a score of 8.84 compared to 2.64 for Mistral 7B, suggesting a much stronger capability in mathematical problem-solving.
- GPQA: On the GPQA benchmark, which evaluates the model’s performance on a range of question-answering tasks, Mixtral 8x7B again demonstrates superior performance with a score of 9.28, while Mistral 7B has a score of 5.59.
- MUSR: For the MUSR benchmark, which focuses on summarization, the Mixtral 8x7B achieves a higher score (12.55) than the Mistral 7B (8.36).
- MMLU-PRO: On the MMLU-PRO, a benchmark for professional-level multiple-choice questions across various domains, Mixtral 8x7B shows a substantial improvement with a score of 31.5, compared to 21.7 for Mistral 7B.
Mixtral 8x7b quantized vs Mistral: Hardware Requirements Comparison
A GPU device with at least 30GB VRAM to load Mixtral with 4-bit quantization. While for Mistral 7B, it can be trained on GPUs with at least 24GB of VRAM, making the RTX 6000 Ada or A100 suitable options for training. Novita AI offers cost-efficient, easy-access, pay-as-you-go GPU cloud, including RTX 4090 24GB, 1x RTX 3090 24GB, 1x A100 80GB, RTX A6000 48GB and L40 48GB. Moveover, it has instant access to Jupyter, pre-installed with Tensorflow, Pytorch, cuDNN, CUDA, TensorRT, Llama3 and Stable Diffusion. Check out the global cheapest Cloud for AI!
Exploring Other Mistral/Mixtral Models
The Mistral/Mixtral model family is extensive. According to the Huggingface Open LLM Leaderboard, there are many similar or fine-tuned Mistral/Mixtral models with superior performance or distinctive features. Do not miss out!
teknium/openhermes-2.5-mistral-7b on Novita AI
OpenHermes 2.5 Mistral 7B is a state of the art Mistral Fine-tune, a continuation of OpenHermes 2 model, which trained on additional code datasets.
Nous-Hermes-2-Mixtral-8x7B-DPO on Novita AI
Nous Hermes 2 Mixtral 8x7B DPO is the new flagship Nous Research model trained over the Mixtral 8x7B MoE LLM. The model was trained on over 1,000,000 entries of primarily GPT-4 generated data, as well as other high quality data from open datasets across the AI landscape, achieving state of the art performance on a variety of tasks.
mistralai/mistral-nemo on Novita AI
Mistral nemo is a 12B parameter model with a 128k token context length built by Mistral in collaboration with NVIDIA. The model is multilingual, supporting English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi. It supports function calling and is released under the Apache 2.0 license.
cognitivecomputations-dolphin-mixtral-8x22b on Novita AI
Dolphin 2.9 is designed for instruction following, conversational, and coding. This model is a finetune of Mixtral 8x22B Instruct. It features a 64k context length and was fine-tuned with a 16k sequence length using ChatML templates.The model is uncensored and is stripped of alignment and bias. It requires an external alignment layer for ethical use.
Conclusion
As we have explored, the Mixtral 8x7B quantized model, with its advanced quantization methods and MoE framework, sets a new standard for memory efficiency and computational resource optimization. Be sure not to miss out on the extensive range of Mistral/Mixtral models available on Novita AI, each offering unique features and performance enhancements.
FAQs
What is the best quantization for Mixtral?
Mixtral performs excellently with 3-bit quantization, fitting onto a single RTX 3090 and processing approximately 50 tokens per second.
When was Mixtral 8x7B released?
Mistral AI released Mixtral 8x7B on December 8th, 2023.
What is the ranking of Mistral 8x7B?
When examining the popular MMLU benchmark, the performance ranking of Mistral’s models is as follows: Mistral Large (84.0%) > Mistral 8x22B (77.8%) > Mistral Small (72.2%) > Mixtral 8x7B (70.6%) > Mistral Nemo (68%) > Mistral 7B (62.5%).
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading
Introducing Mistral’s Mixtral 8x7B Model: Everything You Need to Know
Developing Mistral Instruct: Success Strategies
Introducing Mixtral-8x22B: The Latest and Largest Mixture of Expert Large Language Model
Diving Into dolphin-2.1-Mistral-7B and Alternative Uncensored LLMs