

Novita AI의 VIDU Q2는 개발자 친화적인 API를 통해 프로덕션급 이미지-투-비디오 생성을 제공하며, 10초 만에 540p~1080p 클립을 생성하고 영화 같은 카메라 제어 및 다중 참조 이미지 융합을 지원합니다. U-ViT 아키텍처를 기반으로 일관된 모션, 미세 표정, 7개 이미지 참조 처리를 탁월하게 수행하며, 사용한 만큼 지불하는 가격 체계를 제공합니다.
Novita AI의 VIDU Q2란?
VIDU Q2는 Novita AI에서 여러 변형을 통해 제공되는 고급 이미지-투-비디오 AI 모델입니다:
- 시작-종료 프레임(Start-End Frame): 비디오의 시작과 끝을 정확히 정의하면 AI가 중간 과정을 알아서 처리합니다.
- 멀티 프레임(Multi-frame): 스토리보드처럼 여러 이미지를 제공하면 AI가 그 사이의 움직임을 애니메이션화합니다.
- Turbo: 속도와 효율성에 중점을 둔 변형 (더 저렴하거나 빠를 가능성이 높음).
- Pro: 시각적 품질, 프롬프트 준수, 디테일에 중점을 둔 변형 (더 느리고 비쌀 가능성이 높음).
- 참조 이미지(Reference Image): 이미지가 반드시 비디오의 첫 번째 프레임일 필요는 없으며, "무엇이 어떻게 보여야 하는지"에 대한 참조(예: 캐릭터 디자인) 역할을 합니다.
- 템플릿(Template): VIDU Q2 템플릿-투-비디오 API로, 다양한 효과 장면 템플릿을 지원하며 템플릿과 입력 이미지를 기반으로 효과 비디오 콘텐츠를 생성합니다.
| 카테고리 / 엔드포인트 이름 | 입력 유형 (업로드하는 항목) |
|---|---|
| VIDU Q2 텍스트-투-비디오 | 텍스트 프롬프트 |
| VIDU Q2 템플릿-투-비디오 | 템플릿 + 에셋 |
| VIDU Q2 참조 이미지-투-비디오 | 참조 이미지 + 텍스트 |
| VIDU Q2 Turbo 이미지-투-비디오 | 단일 이미지 |
| VIDU Q2 Turbo 시작-종료 프레임 | 시작 이미지 및 종료 이미지 |
| VIDU Q2 Turbo 멀티 프레임 | 여러 키프레임 |
| VIDU Q2 Pro 이미지-투-비디오 | 단일 이미지 |
| VIDU Q2 Pro 시작-종료 프레임 | 시작 이미지 및 종료 이미지 |
| VIDU Q2 Pro 멀티 프레임 | 여러 키프레임 |
| VIDU Q2 Pro Fast 이미지-투-비디오 | 단일 이미지 |
| VIDU Q2 Pro Fast 시작-종료 프레임 | 시작 이미지 및 종료 이미지 |
Novita AI에서 VIDU Q2의 핵심 아키텍처 특징
| 기능 | 사양 | 개발자 이점 |
|---|---|---|
| 다중 참조 융합(Multi-Reference Fusion) | 이미지 | 주제 간 일관된 정체성 유지 |
| 해상도 옵션 | 540p, 720p, 1080p | 품질과 생성 속도 간 균형 |
| 지속 시간 범위 | 1~10초 | 짧은 형식 콘텐츠에 최적화 |
| 모션 제어 | 자동/소형/중형/대형 진폭 | 애니메이션 강도 미세 조정 |
| 카메라 작업 | 푸시, 풀, 궤도, 팬, 줌 | 텍스트 프롬프트를 통한 영화 같은 샷 제어 |
Novita AI에서 VIDU Q2의 개발자를 위한 주요 기능
1. 다중 참조 이미지 융합
VIDU Q2의 핵심 기능은 여러 입력 이미지를 동시에 처리하는 능력입니다. 단일 이미지 모델과 달리 Q2의 다중 참조 융합은 복잡한 시나리오를 가능하게 합니다. 한 이미지의 캐릭터 얼굴을 다른 이미지의 소품과 혼합하거나, 단일 비디오에서 서로 다른 주제 간의 일관성을 유지할 수 있습니다. 이 모델은 시작/종료 프레임 잠금을 처리하여 클립 전체에서 특정 포즈나 로고 배치를 유지합니다.
사용 사례: (1) 브랜드 로고 이미지, (2) 제품 사진, (3) 손 제스처 참조를 결합하여 제품 데모를 생성합니다. Q2는 이 세 가지를 하나의 응집력 있는 5초 비디오로 융합하며, 브랜드 제품을 자연스러운 손 움직임으로 선보입니다.
2. 영화 같은 카메라 제어
Q2는 텍스트 프롬프트에서 영화 문법을 이해합니다: “돌리 줌”, “트래킹 샷”, “반시계 방향 궤도”. 이를 통해 수동 애니메이션 없이 정밀한 카메라 움직임이 가능합니다. "얼굴에 클로즈업 돌리 줌, 오른쪽으로 느린 팬"을 지정하면 Q2가 부드러운 전환으로 샷을 실행합니다.
3. 물리 인식 모션
Q2는 사실적인 물리 시뮬레이션에 탁월합니다. 사용자 테스트 결과 트랙에서의 정확한 자동차 가속, 자연스러운 천 움직임, 믿을 수 있는 물 역학이 입증되었습니다. 물리적 사실성이 필요한 액션 장면이나 제품 데모의 경우 Q2의 모션 엔진은 물리 인식이 부족한 모델보다 뛰어납니다.
4. 미세 표정 및 감정 제어
이 모델은 미묘한 얼굴 움직임을 포착합니다: 망설이는 미소, 시선 이동, 입술의 미세 움직임. 이는 캐릭터 중심 콘텐츠에 매우 중요합니다. 감정적 진정성이 중요한 경우, 애니메이션 발표자가 있는 설명 비디오, 사실적인 아바타가 있는 교육 비디오, 또는 표현력 있는 반응이 필요한 소셜 미디어 클립 등에 유용합니다.
Novita AI API와 VIDU Q2 통합
설정 요구 사항
Novita AI는 서버리스, 사용한 만큼 지불하는 API를 제공합니다. GPU 인프라가 필요하지 않습니다. 설정은 5분 미만이 소요됩니다:
- novita.ai에서 가입
- 대시보드에서 API 키로 이동
- 새 API 키 생성 (테스트용 무료 티어 제공)
- OpenAI 호환 엔드포인트 형식 사용
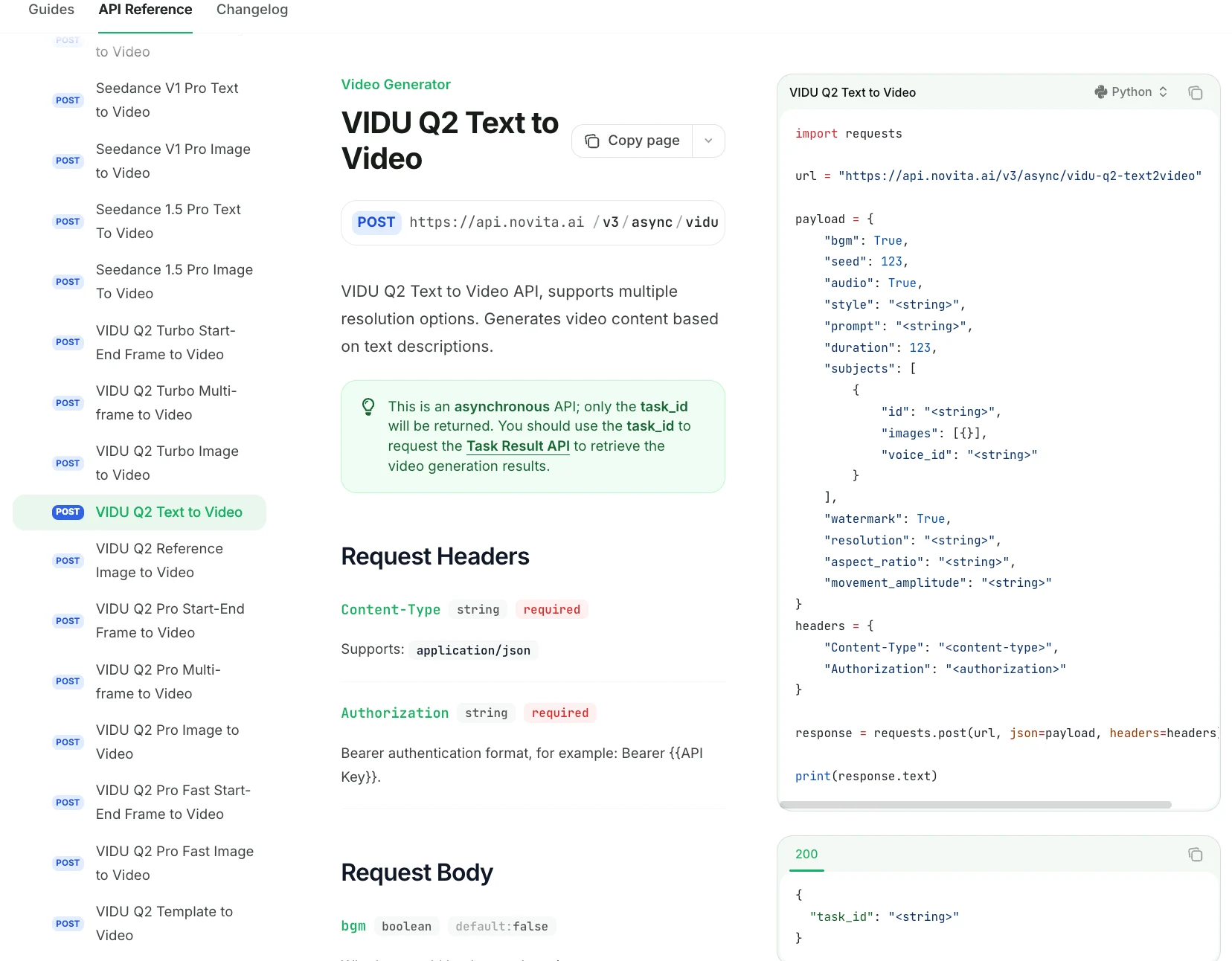
오디오 및 BGM 생성: Q2 Pro는
bgm및voice_id매개변수를 통해 배경 음악과 음성 합성을 지원합니다. 단일 API 호출로 동기화된 오디오가 포함된 완전한 비디오 클립을 생성할 수 있습니다.비수기 처리(Off-Peak Processing):
off_peak모드를 활성화하면 대기 시간이 약간 길어지지만 비용이 30~40% 절감됩니다. 실시간 요구 사항이 없는 배치 작업에 이상적입니다.
Novita AI에서 VIDU Q2의 성능 벤치마크
- Q2 Turbo는 Q1 대비 3배 속도 향상
- Q1 대비 향상된 얼굴/모션 일관성
- 카메라 움직임 간 더 선명한 전환 (덜 갑작스러움)
- 자연스러운 팬, 줌, 트래킹 샷을 위한 재구축된 모션 엔진
- Sora급 모델 대비 프레임 간 우수한 객체 보존
Novita AI에서 VIDU Q2의 가격
Novita AI는 생성당 지불(pay-per-generation) 가격 체계를 사용합니다. 구독이나 GPU 임대가 필요하지 않습니다. 비용은 해상도, 지속 시간 및 변형 선택에 따라 달라집니다:
| 모델 | 모드 | 지속 시간 | 해상도 | 가격 (/비디오) |
|---|---|---|---|---|
| VIDU Q2 | 텍스트-투-비디오 | 5초 | 540P | $0.0802 |
| VIDU Q2 | 텍스트-투-비디오 | 5초 | 720P | $0.1562 |
| VIDU Q2 | 텍스트-투-비디오 | 5초 | 1080P | $0.2677 |
| VIDU Q2 | 참조-투-비디오 | 5초 | 540P | $0.1562 |
| VIDU Q2 | 참조-투-비디오 | 5초 | 720P | $0.2008 |
| VIDU Q2 | 참조-투-비디오 | 5초 | 1080P | $0.5132 |
| VIDU Q2 Pro | 이미지-투-비디오 | 5초 | 540P | $0.1472 |
| VIDU Q2 Pro | 이미지-투-비디오 | 5초 | 720P | $0.2454 |
| VIDU Q2 Pro | 이미지-투-비디오 | 5초 | 1080P | $0.5135 |
| VIDU Q2 Pro Fast | 이미지-투-비디오 | 5초 | 720P | $0.0713 |
| VIDU Q2 Pro Fast | 이미지-투-비디오 | 5초 | 1080P | $0.1430 |
| VIDU Q2 Turbo | 이미지-투-비디오 | 5초 | 540P | $0.0624 |
| VIDU Q2 Turbo | 이미지-투-비디오 | 5초 | 720P | $0.2141 |
| VIDU Q2 Turbo | 이미지-투-비디오 | 5초 | 1080P | $0.3347 |
Novita AI에서 VIDU Q2의 모범 사례
Q2를 위한 프롬프트 엔지니어링
프롬프트는 100단어 미만으로 유지하고, 복잡한 서사보다는 모션과 카메라에 우선순위를 두세요. 좋은 프롬프트 구조:
[카메라 움직임] + [주제 동작] + [감정/표정] + [기술 사양]
예시: "여성 얼굴에 느린 돌리 줌, 망설이는 미소 형성, 눈이 아래를 보다가 위를 봄, 자연광, 24fps"
피해야 할 것: “햇볕이 좋은 공원의 아름다운 여성이 나무를 바라보며 새들이 날아다니는 가운데 과거를 생각하며 향수를 느낍니다…” (너무 복잡, 준수도가 떨어짐)
다중 참조 이미지 팁
- 보존할 요소를 명시적으로 프롬프트: “이미지 1의 얼굴, 이미지 2의 옷, 이미지 3의 배경 사용”
- 관련 없는 이미지는 안내 없이 잘 혼합되지 않음 — 얼굴 + 물체를 결합하는 경우 관계를 지정하세요
- 최상의 결과를 위해 3~4개의 참조로 제한 — 7개 이미지 용량은 복잡한 다중 주제 장면을 위한 것이며, 항상 최적은 아닙니다
반복 워크플로우
- 720p, 4초, 자동 모션으로 시작 — 가장 빠른 반복 주기
- 고정 시드로 3~5개의 프롬프트 변형 테스트 — 최상의 카메라/감정 조합 식별
- 최종 출력을 위해 우승 변형을 1080p, 6~8초로 확장
- 배치 작업에는 비수기(off-peak) 사용 (30% 비용 절감)
큐를 사용한 배치 처리
대량 생성의 경우:
- off-peak를 활성화한 상태로 50~100개 작업 제출
- 웹훅 콜백을 사용하여 결과를 비동기적으로 캡처
- 상태 추적을 위해 데이터베이스에 작업 ID 저장
- 실패한 작업에 대한 재시도 로직 구현 (속도 제한, 시간 초과)
긴 형식 콘텐츠를 위한 비디오 확장
Q2는 1~10초 클립을 생성합니다. 더 긴 비디오의 경우:
- 방법 1: VIDU의 확장 API를 사용하여 기존 클립에 점프 컷 없이 6초 이상 추가
- 방법 2: 겹치는 클립 생성 (클립 1의 마지막 프레임이 클립 2의 첫 번째 프레임이 됨) 후 FFmpeg로 연결
- 방법 3: Q2를 장면 생성기로 사용 — 5~10개의 개별 장면을 생성하고 전환으로 편집하여 내러티브 구성
Novita AI의 VIDU Q2는 개발자 친화적인 API를 통해 프로덕션급 이미지-투-비디오 생성을 제공하며, GPU 인프라 오버헤드를 제거하면서 영화 같은 카메라 제어, 다중 참조 이미지 융합, 15초 미만의 생성 시간을 제공합니다.
Q1 대비 3배 빠른 생성과 향상된 일관성을 갖춘 Q2 Turbo는 대량 소셜 미디어 콘텐츠, 빠른 프로토타이핑 및 반복 워크플로우에 최적화되어 있습니다.
Q2 Pro는 최종 상업용 에셋을 위해 미세 표정 제어 및 오디오 생성 기능을 추가하여 최대 충실도를 제공합니다.
비용 효율성 덕분에 Novita의 API는 매력적입니다. Pro Fast 1080p 클립은 $0.143부터 시작하며, off-peak 모드를 사용하면 비용을 30~40% 더 절감할 수 있습니다.
자주 묻는 질문
Novita AI에서 VIDU Q2 Turbo와 Q2 Pro의 차이점은 무엇인가요?
Q2 Turbo는 반복 워크플로우를 위해 속도에 중점을 둡니다(Q1보다 3배 빠름, 클립당 약 10초). Q2 Pro는 향상된 미세 표정, 립싱크 및 오디오 생성으로 최대 충실도를 제공합니다. 품질이 속도보다 중요한 최종 에셋에는 Pro를 사용하세요.
Novita AI에서 VIDU Q2 비디오당 비용은 얼마인가요?
가격은 변형, 해상도 및 지속 시간(기본 5초)에 따라 다릅니다:
Turbo: $0.0624 (540p) – $0.3347 (1080p)
Pro Fast: $0.0713 (720p) – $0.1430 (1080p)
Pro: $0.1472 (540p) – $0.5135 (1080p)
텍스트-투-비디오: $0.0802 (540p) – $0.2677 (1080p)
Novita에서 VIDU Q2에 적용되는 해상도 및 지속 시간 제한은 무엇인가요?
해상도 옵션에는 540p, 720p 및 1080p가 포함됩니다. 지속 시간은 클립당 1~10초입니다. 더 긴 비디오를 위해서는 VIDU의 확장 기능 또는 FFmpeg 연결을 사용하세요.
Novita AI는 개발자와 스타트업이 고성능, 신뢰성 및 비용 효율성으로 모델과 에이전트 애플리케이션을 구축, 배포 및 확장할 수 있도록 지원하는 AI 및 에이전트 클라우드 플랫폼입니다.



