

Llama 3.2 1B、Qwen2.5 7B、Qwen 3(0.6B、1.7B、4B)、GLM 4 — すべてNovita AIで今すぐ利用可能。プロジェクトを無料でパワーアップ!
DeepSeek R1 0528は、個人利用および企業利用で最も求められている大規模言語モデルの1つになりました。6850億パラメータという巨大なアーキテクチャと、蒸留版・フル版の両方のサポートにより、多くの開発者やAI愛好家はクラウドAPIに頼らずにローカルで実行したいと考えています。では、なぜDeepSeek R1 0528を自分のハードウェアで実行することにこれほど注目が集まっているのでしょうか?主な理由、メリット、課題を詳しく見ていきましょう。
DeepSeek R1 0528をローカルで実行するメリット
1. オフライン生成
- DeepSeek R1‑0528はセットアップ後、6850億パラメータモデルを搭載し、完全にオフラインで動作可能です。ネットワークが不要なため、接続が不安定または禁止されている環境に最適です。
2. 低レイテンシ性能
- クラウドベースのAPIは、ネットワークやサーバーの遅延により、応答に15~30秒かかることがよくあります。DeepSeek R1をローカルで実行すると、応答時間がサブ秒に短縮され、コーディングアシスタント、インタラクティブなデバッグ、ライブデータ分析に不可欠です。さらに、ローカル実行では、過負荷のクラウドエンドポイントでよく見られる「サービス利用不可」エラーがなくなります。
3. より強力なプライバシー保護
- モデルが完全に自分のマシン上で実行されるため、機密データがサードパーティのサーバーに送信されることはありません。すべてがローカルに留まり、完全な制御が可能です。
DeepSeek R1 0528をローカルで実行するためのハードウェア要件
| カテゴリ | フルモデル要件 | 8B蒸留モデル要件 |
|---|---|---|
| GPU | エンタープライズグレードGPU、最低80GB VRAM(例:NVIDIA H100/A100) | コンシューマーGPU、24GB VRAM(例:NVIDIA RTX 4090) |
| ディスク容量 | 約715GB | 大幅に少ない(量子化モデルサイズに依存) |
| システムメモリ | 256GB RAM以上 | 32~64GB RAM |
| メモリ帯域幅 | DDR5、クロック速度3200MHz以上 | DDR5、高速クロック推奨 |
| ストレージ性能 | NVMe SSD、PCIe Gen4またはGen5 | NVMe SSD、PCIe Gen4またはGen5 |
| 対象ユースケース | エンタープライズ、クラウド推論、研究 | 個人利用、小規模実験、開発/テスト |
| 価格見積もり | GPU:1枚あたり30,000ドル以上、ストレージとRAMは別途 | GPU:1枚あたり1,500~2,000ドル |
- 実行要件の具体例
VRAM (GPU) RAM (システム) Token/s 備考 24GB 64GB ~1.5 RTX 3090 + 64GB RAM。量子化モデルの標準的な構成。 24GB 96GB 1–2 RTX 3090TI + 96GB RAM。2k~16kコンテキストで1~2 token/s。同時推論スロットを最大8つまで増やして総スループット向上。 0GB(GPU無効) 96GB ~2.13 CPUのみ。動的量子化されたフルR1 671Bモデル(蒸留版ではない)、llama.cpp使用。
DeepSeek R1をローカルで実行する3つの方法
1. Ollamaを使用する
Ollamaは、DeepSeek R1-0528モデルをローカルで実行する最も簡単な方法を提供し、最小限の設定と自動GPU最適化を実現します。
# Ollamaのインストール
curl -fsSL https://ollama.com/install.sh | sh
# Ollamaデーモンの起動
ollama serve &
# 蒸留版8B(軽量、ラップトップ/デスクトップ向け)
ollama run hf.co/unsloth/DeepSeek-R1-0528-Qwen3-8B-GGUF:Q4_K_XL
# フル量子化版(より多くのRAMが必要、162GB)
ollama run hf.co/unsloth/DeepSeek-R1-0528-GGUF:TQ1_0
2. WebUIでビジュアルチャット
Open-WebUIは、Ollamaを介してローカルモデルと対話するためのブラウザベースのインターフェースを提供し、ChatGPTのような体験を実現します。
docker pull ghcr.io/open-webui/open-webui:cuda
docker run -d -p 3000:8080 \
--gpus all \
--add-host=host.docker.internal:host-gateway \
-v ollama:/root/.ollama \
-v open-webui:/app/backend/data \
--name open-webui \
ghcr.io/open-webui/open-webui:cuda
3. Python SDKによる開発者向け統合
DeepSeek R1-0528へのプログラムによるアクセスを希望する場合は、Hugging Face + transformers を使用します。
pip install transformers torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# モデルのロード
model_path = "deepseek-ai/DeepSeek-R1-0528"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# 応答の生成
def generate_response(prompt, max_tokens=512):
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
max_new_tokens=max_tokens,
temperature=0.6,
top_p=0.95,
do_sample=True
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
DeepSeek R1 0528を実行する際の課題
1.依存関係と互換性の問題
- PyTorchとシステムドライバ間の CUDAバージョンの不一致 が頻発。
- 複数のAIライブラリ(例:
transformers、accelerate)とのPython環境の競合。 - 量子化モデル形式(GGUF vs Safetensors)はツール間で 互換性がない ことが多い。
2.プラットフォーム固有の障壁
- Windows: CUDA + PATHの設定が複雑でエラーが発生しやすい。
- macOS: ネイティブGPU推論が不可。CPUのみにフォールバック。
- Linux: ディストリビューション(Debian、Archなど)によって異なり、パッケージマネージャーの問題が一般的。
3.電力と冷却要件
- 長時間の推論は、適切な冷却がないと サーマルスロットリング を引き起こす。
- ハイエンドGPU + マルチGPU構成では 1~3kWの電力を消費 する可能性がある。
- 長時間のセッション安定性のためには産業用冷却が必要。
4.セキュリティとプライバシーのリスク
- モデルの重みは プレーンテキストファイル として保存されることが多い。
- 推論ログには 機密性の高いプロンプト/応答 が含まれる可能性がある。
- ネットワークポート(例:WebUI)が認証なしで 露出したまま になることがある。
面倒を避けたいなら:Novita AI APIをお試しください

透明な価格設定
明確なコストで高性能を実現。
- コンテキストウィンドウ: 163,840トークン
- 価格: 入力トークン100万あたり0.70ドル、出力トークン100万あたり2.50ドル
- 初期GPU投資不要
- オフピークディスカウントとコンテキストキャッシュ利用可能
エンタープライズグレードのセキュリティ
組み込みの暗号化、アクセス制御、コンプライアンスサポート。
- エンドツーエンドの暗号化
- SOC 2対応
- GDPR、HIPAA準拠
- データレジデンシーオプション
簡単な統合
お気に入りのツールでDeepSeek R1 0528を使用。
- Hugging Face Spaces、Transformers
- LangChain、Continue、Dify、Langflow
- OpenAI APIツール(CursorやClineなど)と互換性あり
製品に集中、GPUにはこだわらない:Novita AI API 使用ガイド
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
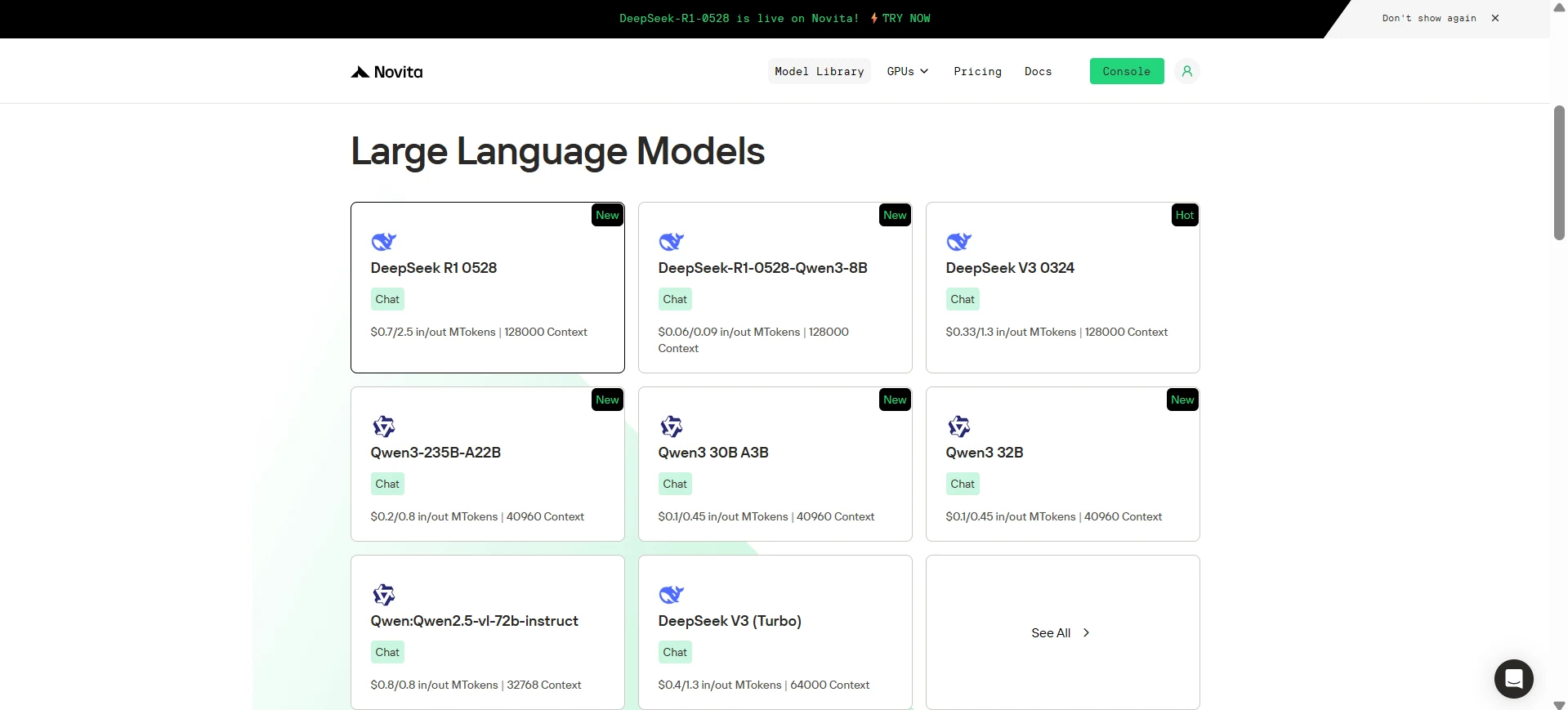
ステップ3:無料トライアルを開始
選択したモデルの機能を探索するために無料トライアルを開始します。
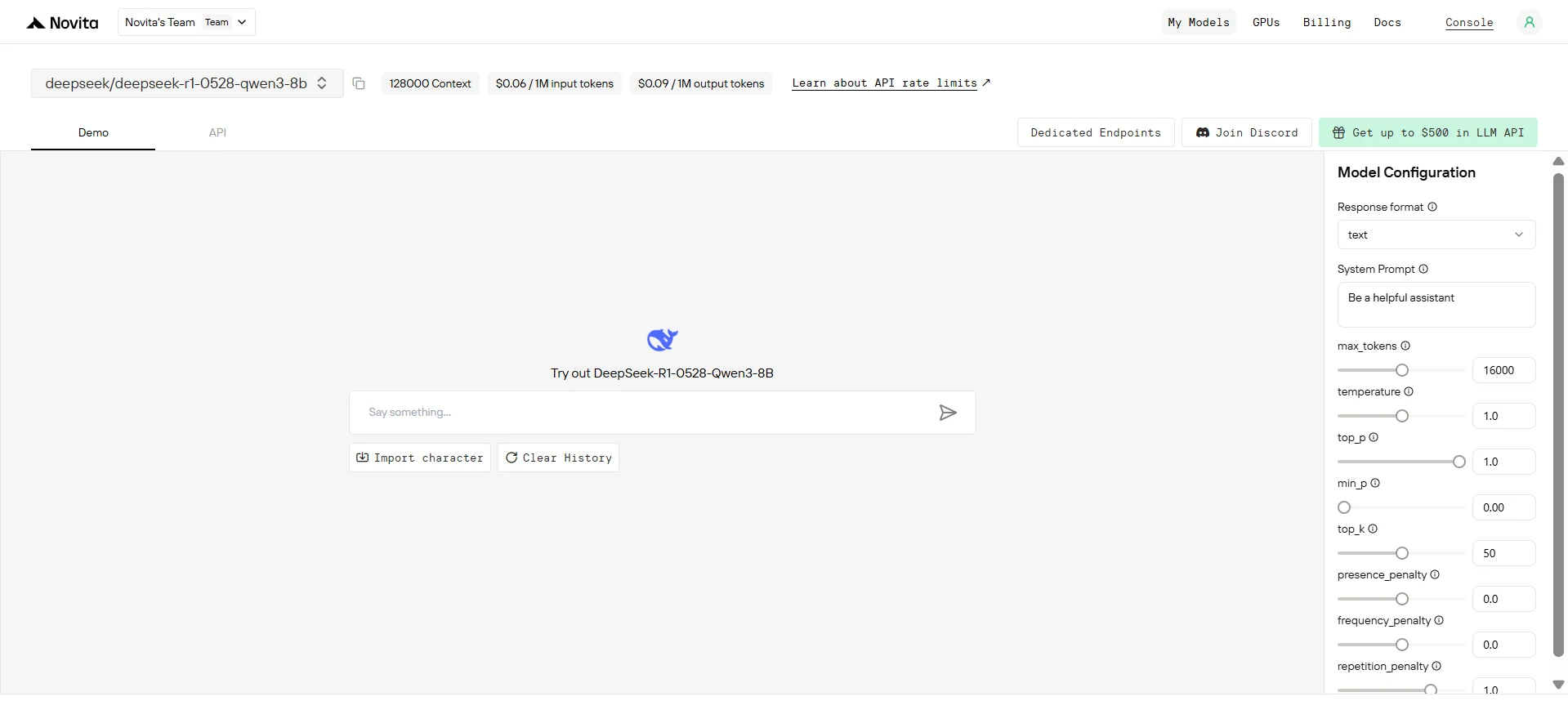
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動し、画像の指示に従ってAPIキーをコピーします。

ステップ5:APIをインストール
使用するプログラミング言語に固有のパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。これはPythonユーザー向けのチャット完了APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_H_85jwhkUyBsRipBTIU9n_adbP5B9Qvu0wxGGMN4Vq-BpFVKntQQXOAJF4IpkuDJh2e-NQkoJkcwMhus4t81PQ==",
)
model = "deepseek/deepseek-r1-0528-qwen3-8b"
stream = True # または False
max_tokens = 16000
system_content = ""役立つアシスタントとして振る舞ってください""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "こんにちは!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
ステップ6:LLM APIメトリクスを監視
体系的な評価により、特定の要件に基づいた最適なデプロイ戦略を決定するのに役立ちます。
- 応答時間: 一般的なリクエストのエンドツーエンドのレイテンシを測定。
- スループット: 同時リクエスト処理能力をテスト。
- 信頼性: 稼働時間とエラー率を経時的に監視。
- 品質: デプロイ方法間での出力の一貫性を比較。
これらのメトリクスは、LLMメトリクスコンソールからアクセスできます。
DeepSeek R1 0528をローカルで実行するための高いハードウェア要件により、速度、プライバシー、クラウドサービスの制限からの自由が得られます。しかし、それにはかなりのハードウェア、セットアップ、およびメンテナンスの負担が伴います。最大限の制御が必要で、ハイエンドハードウェアに投資する準備ができている人にとって、ローカルデプロイは比類のないものです。それ以外の人にとっては、Novita AIのようなマネージドAPIが、複雑さを減らして同じパワーを提供します。
よくある質問
DeepSeek R1 0528をローカルで実行する主な利点は何ですか?
オフラインアクセス、より高速な応答時間、データの完全なプライバシー。
DeepSeek R1 0528を実行するにはどのようなハードウェアが必要ですか?
最適なパフォーマンスを得るには、エンタープライズGPU(80GB以上のVRAM)と最低256GBのRAMが必要です。軽量な蒸留モデルは、24GB VRAMのGPUと32~64GBのRAMで実行できます。
ノートパソコンでDeepSeek R1 0528を実行できますか?
蒸留版または量子化版のみ、ハイエンドノートパソコン(例:RTX 4090 + 64GB RAM)で動作する可能性があります。フルモデルにはサーバーグレードのハードウェアが必要です。
Novita AIは、AIの野望を支援するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の高いツールを提供します。インフラを排除し、無料で始めて、AIのビジョンを現実にしましょう。



