

ShengShu TechnologyとTsinghua Universityの共同開発により、Vidu Q1は最先端のユニバーサルビジョントランスフォーマー(U-ViT)アーキテクチャを活用し、視覚的に一貫性の高い高品質な動画と同期した効果音を生成します。
テキストから動画を生成する**Text-to-Video、画像から動画を生成するImage-to-Video、開始・終了フレームから動画を生成するStart-End-to-Video、参照画像から動画を生成するReference-to-Videoのいずれのモードも、Novita AI上では1本あたりわずか0.36ドル**(1080P/5秒)で利用可能です。これによりVidu Q1は、解説動画、製品デモ、注目を集めるソーシャルメディアコンテンツの作成に適した、実用的かつスケーラブルなソリューションとなっています。簡単なAPIアクセスと高速なレンダリングにより、ユーザーは撮影や高度な編集を必要とせず、コンセプトや静止画をシームレスに洗練された動画クリップに変換できます。
Vidu Q1とは?視覚的一貫性と効果音に特化した5秒間1080p動画
**Vidu Q1は、ShengShu TechnologyとTsinghua Universityの共同イニシアティブであるViduが2025年4月にリリースした最先端のAI動画生成モデルです。マルチモーダル生成システムとして、Vidu Q1はテキストの説明、画像、参照ビジュアルなど複数の入力タイプを受け付け、同期したオーディオ付きの高品質な動画を出力します。ショートフォームコンテンツの作成に特化しており、1クリップあたり最大5秒間の1080p(フルHD)**動画を生成可能です。本モデルはMP4などの標準的な動画ファイルを出力し、1920×1080の鮮明な解像度の映像と一致するサウンドトラックを提供します。
https://www.youtube.com/watch?v=mHXshs0xqfA
Vidu Q1は最先端のユニバーサルビジョントランスフォーマー(U-ViT)アーキテクチャを基盤としており、高品質な画像生成に優れるDiffusionモデルと、コンテキストや複雑なプロンプトの理解に強みを持つTransformerモデルの長所を組み合わせています。このハイブリッド設計により、Vidu Q1は詳細なリクエストを正確に解釈し、動画フレーム全体で強力な視覚的一貫性を維持し、まとまりのある現実的な出力を実現します。
Vidu Q1は最大5秒間のプロ品質の1080p動画を生成します。各クリップには48kHz品質の同期高忠実度効果音と背景オーディオが含まれており、次世代AI動画生成のリーダーとなっています。
| 機能 | 使用方法 |
|---|---|
| Vidu Q1 T2V | 生成したいシーンやアクションを説明するテキストプロンプトを入力すると、AIが一致する動画を生成します。 |
| Vidu Q1 I2V | 静止画をアップロードすると、AIがその画像をアニメーション化したり、動的なショート動画に拡張したりします。 |
| Vidu Q1 Start-End to Video | 開始フレームと終了フレームをアップロードすると、AIが2つの間のスムーズなアニメーション遷移を作成します。 |
| Vidu Q1 Reference-to-Video | 1~7枚の参照画像またはクリップをアップロードすると、AIが視覚的に一貫性のある動画を生成します。 |
Vidu Q1のメリットとデメリットは?
メリット:
- 高品質な出力(1080p+音声付き): 1920×1080の鮮明なプロ仕様のHD動画を生成し、細部までこだわったビジュアルと背景音楽・48kHzの高忠実度効果音などの統合オーディオにより、没入感のある洗練された動画を作成できます。
- マルチモーダルな創作の柔軟性: テキスト、画像、参照入力をサポートしており、1つのプラットフォームでテキストから動画生成、画像のアニメーション化、開始・終了フレームの遷移、スタイルの一貫性維持を実現します。
- 使いやすさと処理速度: 初心者でも操作できるシンプルなインターフェースを搭載。プロンプトを入力するか画像をアップロードするだけで、最短10秒で結果を得られます。個人から企業まで利用しやすい料金プランを用意しています。
- 高度な機能(一貫性と遷移): 参照画像との視覚的一貫性を維持し、最初のフレームから最後のフレームまでのスムーズな遷移を実現するため、複雑なストーリーテリングや同じキャラクターの連続使用に適しています。
- 多様なスタイルの対応: フォトリアリスティックな表現からアニメを含むスタイリッシュな表現まで対応し、幅広い創作ニーズに応えます。
- 活発なコミュニティとアップデート: 迅速な機能改善、活発なユーザー層、充実しつつあるドキュメントやチュートリアル、API・サードパーティ連携が提供されています。
デメリット:
- ショートフォームに特化: リアルタイム動画や長編のナレーション動画、喋るキャラクターの生成には不向きで、短く創造的でビジュアル豊かなクリップの作成に最適です。
- 一貫性・整合性の問題が稀に発生: 複雑なシーンではアーティファクト(不自然な部分)が生じたり、詳細を誤って解釈したりする場合があり、特定のプロンプト指示を見落とすこともあります。
- 独自プラットフォーム(クローズドモデル): オープンソースではなく、セルフホスティングも不可能なため、ViduのスタジオまたはAPIをサブスクリプション・クレジット制で利用する必要があり、ベンダーロックインのリスクがあります。
- 最高の成果を得るためのリソースとスキル要件: 大規模利用には高い計算リソースが必要で、効果的なプロンプト作成や参照素材の準備には試行錯誤と学習が必要になる場合があります。
Vidu Q1のReference-to-Videoテスト
入力:『カウボーイビバップ』風のスタイル:画像1の人物が画像2の宇宙船を操縦し、宇宙の虚空を進む。漆黒の空間に星が点在し、遠方の星雲が背景を淡い色合いで染める。宇宙船は安定した速度で滑るように進み、エンジンは低く一定の唸りを上げている。パイロットの姿勢はリラックスしているが警戒心を怠らず、手を緩くコントロールに置き、小惑星の破片をかき分け、廃棄された衛星の横を漂う——これは広大で終わりのないフロンティアの、また一区間だ。


出力:
Vidu Q1は短い解説動画の作成に適しているか?
はい——Vidu Q1は短い解説動画の作成に非常に適しており、特に複数の短い高品質なセグメントに分けて作成するアプローチを取る場合に最適です。
プロンプト:ワイヤレスイヤホンがBluetoothでスマートフォンに接続する様子を示すシンプルなアニメーション。スマートフォンの画面には接続アイコンが表示され、明るい背景音楽が流れる。
メリット:
- 各シーンで統合オーディオ付きの鮮明な高品質1080pビジュアルを生成
- テキスト、画像、スタイル参照入力をサポートしており、ブランドの一貫性と創作の柔軟性を実現
- 非常に高速で使いやすく、初心者や迅速なプロトタイピングに最適
- 短くインパクトのあるクリップの連続による現代的な解説動画に最適
- 撮影や手動アニメーションが不要で、シンプルなプロンプトからAIがシーンを生成
- ショートクリップはソーシャルメディアでの共有(Instagramリール、TikTokなど)に最適化されている
デメリット:
- 吹き替え音声を生成しないため、ナレーションは別途追加する必要がある
- ワンショットの連続した長編動画やリアルタイムのプレゼンテーションには不向き
Vidu Q1 vs Wan・Kling・Hailuo
アーキテクチャ比較
| 項目 | Vidu Q1 | Alibaba Wan 2.1 | Kling 2.1 |
|---|---|---|---|
| 出力品質とスタイル | 高いビジュアル品質、強い感情表現;リアリスティックとアニメ/漫画スタイルの両方に対応 | 最高級のリアリズム、非常にクリーンな細部;幅広いアーティスティックスタイルのプリセット | 微細なモーション詳細とエフェクト(例:ジュージュー・泡立ち)に優れ、スムーズなリアルなアニメーションを実現 |
| 機能 | 内蔵オーディオ、複数参照の一貫性維持、開始・終了フレーム制御;「Proモード」は画像からプロンプトを生成 | 開始・終了フレーム制御、カスタム利用向けのオープンソース/API;テキスト/画像から動画生成、編集、オーディオに対応 | 「DeepSeek」がプロンプトの最適化をサポート;テキスト/画像入力に対応するがオーディオ統合は弱い |
| パフォーマンスと精度 | 複雑なシーン(例:複数の表情)に強い;まばたきのような小さな詳細を見落とす場合がある | プロンプトへの忠実度が高く、安定して信頼性が高い;大規模データで学習 | まばたきのような微細なモーションでより正確な場合があるが、稀に誤解釈が発生 |
| 速度とGPU要件 | 非公開;クローズドシステムで、内部で最適化されている可能性が高い | 効率的:1.3B版は約8GBのVRAM(例:RTX 4090でのローカルデプロイ)で動作 | 明確なスペックは公開されていないが、スムーズでリアルなモーションで知られる |
| オープン性とエコシステム | クローズドシステム、機能が豊富だがカスタマイズ不可 | 完全にオープンソース、カスタマイズ可能、活発な開発者コミュニティ、高速な反復 | クローズドシステム、商用プラットフォーム;オープンソースエコシステムの兆しなし |
| 最適なユースケース | 内蔵オーディオによる洗練されたビジュアルと感情的なストーリーテリングに最適 | カスタマイズ、ローカルデプロイ、マルチタスク対応が必要な開発者・企業に最適 | 微細なモーション詳細の正確性と簡単なプロンプト最適化が求められる場合に最適 |
パフォーマンス比較
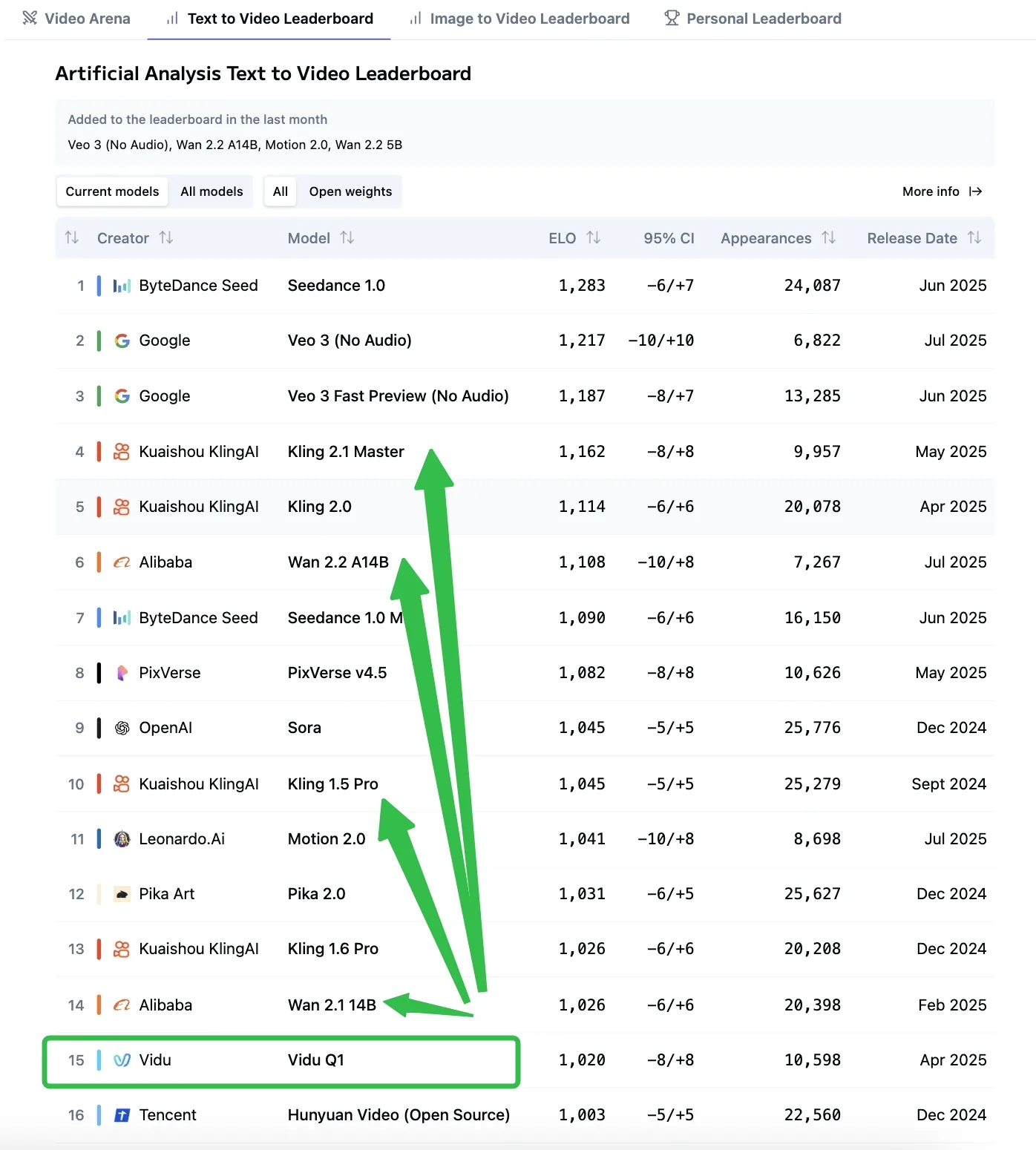
T2V比較元:AA
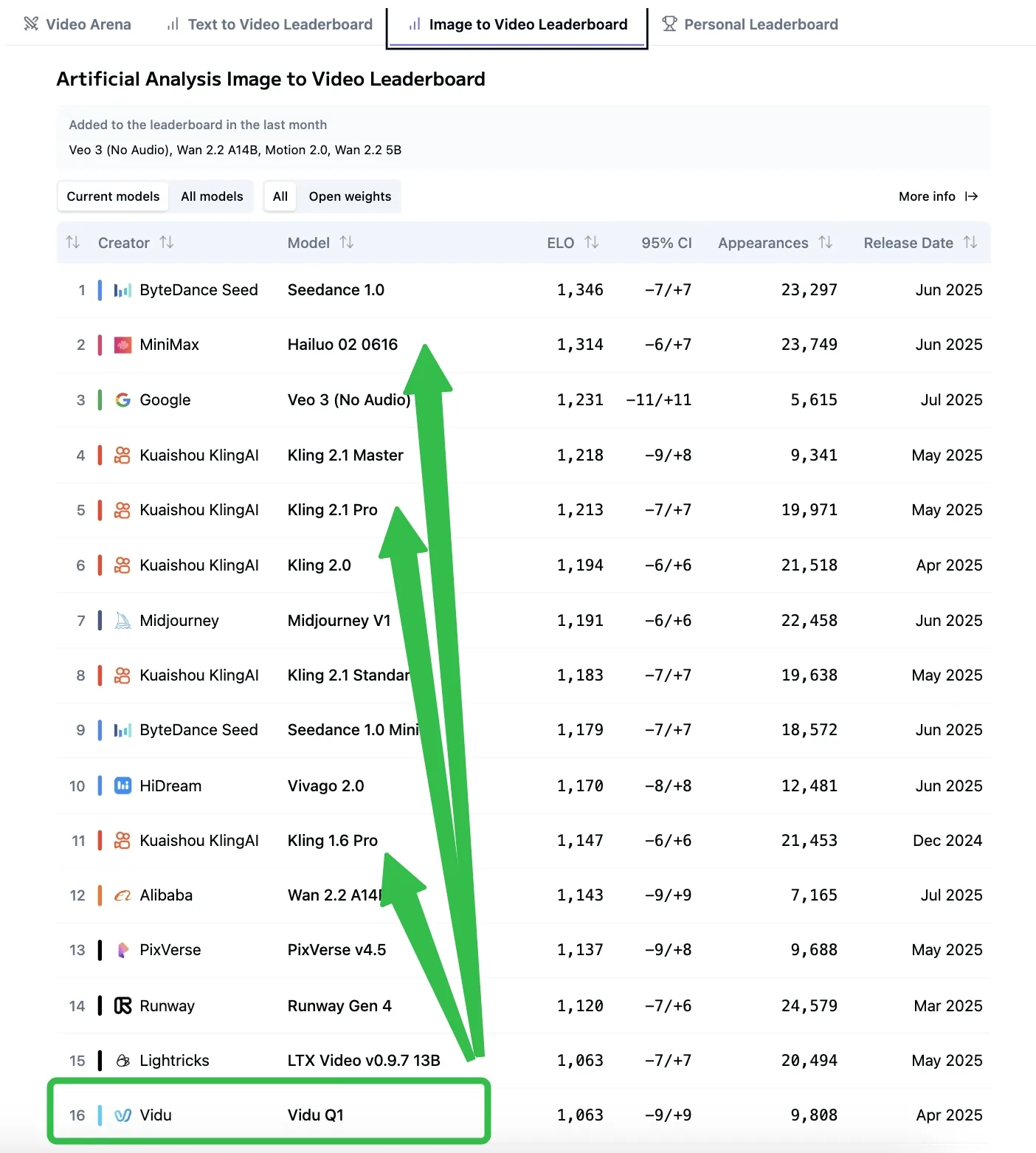
I2V比較元:AA
Wan、Kling、Hailuo、Hunyuanを試したい場合は、Novita AIにアクセスして無料トライアルを開始できます!
1本あたり0.36ドルでVidu Q1を利用する方法は?
ステップ1:ログインしてモデルライブラリにアクセス

ステップ2:モデルを選択
ステップ3:APIキーを取得
APIでの認証には、新しいAPIキーを発行します。「設定」ページにアクセスすると、画像の指示に従ってAPIキーをコピーできます。

ステップ4:APIをインストール
使用しているプログラミング言語に応じたパッケージマネージャーを使ってAPIをインストールします。
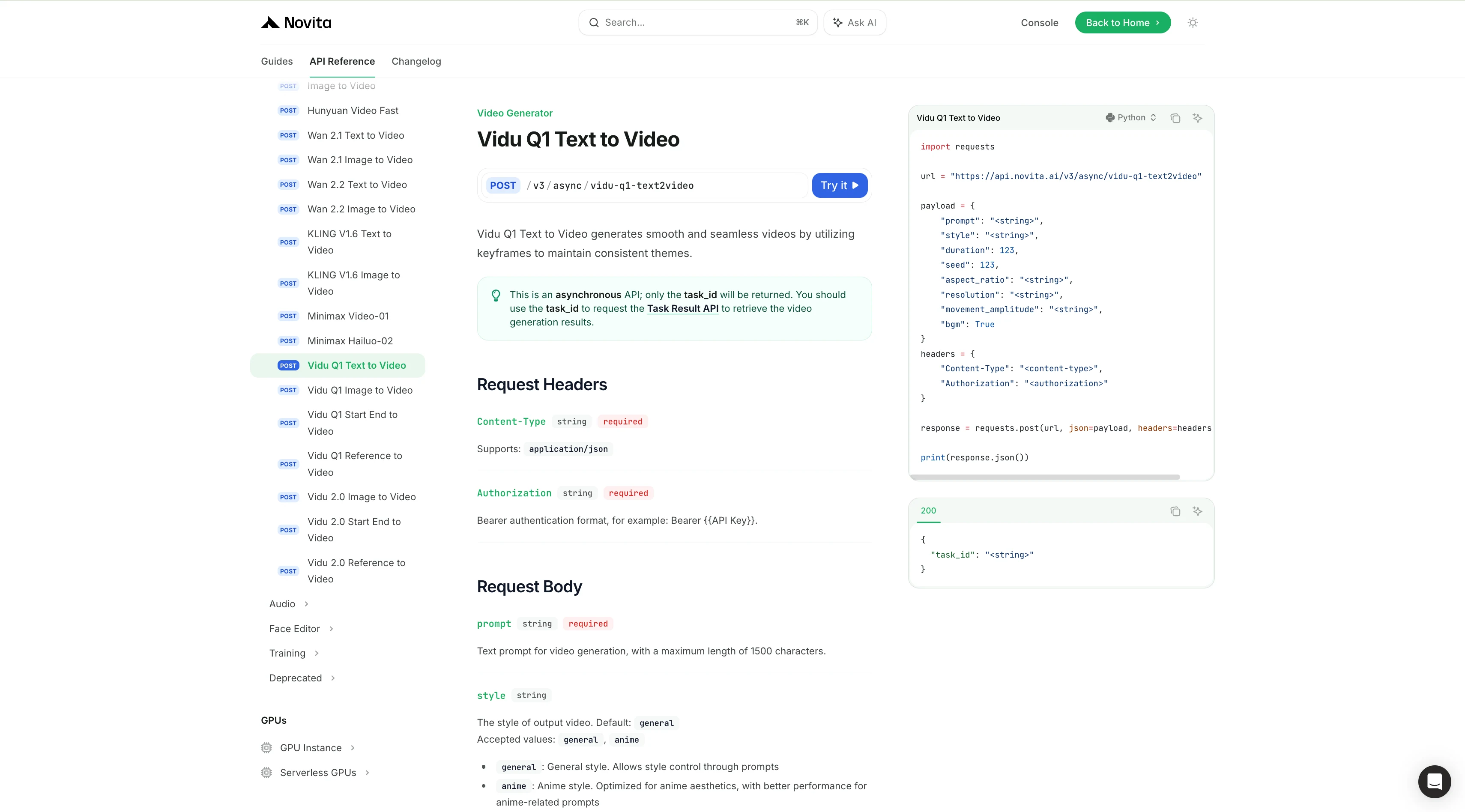
インストール後、開発環境に必要なライブラリをインポートします。APIキーを使ってAPIを初期化することで、Novita AI LLMとの連携を開始できます。以下はPythonユーザー向けのチャット補完APIの使用例です。
import requests
url = "https://api.novita.ai/v3/async/vidu-q1-text2video"
payload = {
"prompt": "<string>",
"style": "<string>",
"duration": 123,
"seed": 123,
"aspect_ratio": "<string>",
"resolution": "<string>",
"movement_amplitude": "<string>",
"bgm": True
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
Vidu Q1の強力なマルチモーダル機能、圧倒的な1080p品質、シームレスなAPIアクセスにより、動画制作を自動化・高度化したい開発者、マーケター、クリエイターにとって完璧なソリューションです。解説動画、ダイナミックな製品デモ、注目を集めるソーシャルメディアコンテンツの作成など、Vidu Q1はかつてないほど速く、低コストで洗練された成果物の作成を実現します。
よくある質問
Vidu Q1とは何ですか?また、そのAPIの独自性は何ですか?
Vidu Q1は、5秒間の1080p動画を同期した効果音付きで生成する高度なAI動画生成モデルです。そのAPIにより、マルチモーダルな動画生成(テキスト、画像、参照入力)を任意のワークフローやアプリケーションにシームレスに統合できます。
Vidu Q1がサポートする入力タイプは何ですか?
Vidu Q1のAPIは、テキストから動画(T2V)、画像から動画(I2V)、開始・終了フレームから動画、参照から動画の生成をサポートしており、柔軟で創造的なコンテンツ作成が可能です。
Vidu Q1を解説動画やマーケティング動画に使用できますか?
Wan 2.2はWan-VAEによる3D時空間圧縮を使用しており、スムーズな遷移と一貫した照明を実現します。aAbsolutely. Vidu Q1は、解説動画、製品ショーケース、ソーシャルメディア、ブランディングに最適な、簡潔で視覚的に印象的なクリップの生成に優れています。
Novita AIは、AIの野望を実現するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス——必要なコスト効率の良いツールを提供。インフラの管理を不要にし、無料で始めて、AIのビジョンを現実にしましょう。



