

大規模言語モデル(LLM)は、現代の開発者にとって不可欠なツールとなっており、特にPythonプログラミング、デバッグ、大規模なコードベース管理において重要です。オープンソースの有力な2つの候補は、DeepSeek V3.1と Qwen3-Coder-480B-A35B-Instruct です。
両モデルともMixture-of-Experts(MoE)アーキテクチャに依存していますが、その設計の優先順位は異なります。
- DeepSeek V3.1 は、推論の柔軟性、ハイブリッド推論モード(ThinkとNon-Think)、およびベンチマークにおける正確なコードの正確性に重点を置いています。
- Qwen3-Coder は、長文脈のコード理解、効率的なデプロイ、そして開発者ツールとの統合(例:CLIツールや関数呼び出し形式)に焦点を当てています。
この記事では、開発者が自身のコーディングワークフローに適したモデルを選択することを支援することを目的としています。リポジトリ規模のPythonプロジェクトの処理、高いベンチマーク精度の達成、または限られたリソースでの効率的なデプロイなど、さまざまなニーズに対応します。
Qwen3 CoderとDeepseek V3.1の主なアーキテクチャの違いは何ですか?
| 機能 | Qwen3-Coder-480B-A35B | DeepSeek-V3.1 |
|---|---|---|
| 総パラメータ数 | 480 B | 671 B |
| トークンあたりの活性化パラメータ | 35 B (MoE) | 37 B (MoE) |
| MoE構成 | 160エキスパート、8アクティブ | ~256ルーティング + 1共有エキスパート、8アクティブ |
| アテンションメカニズム | GQAヘッド(96 Q、8 KV) | MLA + 標準MoE + メモリ効率の良いキャッシュ |
| レイヤー数 | 62 | 未指定(V3アーキテクチャに準拠) |
| コンテキストウィンドウ | 256Kネイティブ、最大約1Mまで拡張可能 | 128K(2フェーズ学習で拡張) |
| 精度 | FP8バリアント利用可能 | FP8混合精度(UE8M0) |
| 推論モード | 非思考(出力のクリーンさ重視) | ハイブリッド:Think & Non-Think |
| エージェントツール統合 | CLIツール(Qwen Code)、関数呼び出し形式 | 学習後のツールスキル強化 |
| 焦点 | エージェント的なコーディング、長いコードコンテキスト、効率性 | 効率的な推論、柔軟性、エージェント的マルチモーダル相互作用 |
Qwen3-Coder-480B-A35B-Instruct は、非常に長いコンテキストサポートと統合された開発者ツールを備えた、効率的なコーディングとエージェントタスク向けに設計されています。
DeepSeek-V3.1 は、ハイブリッド推論動作、強化されたエージェント機能、および高精度な計算効率を導入することでDeepSeek-V3を拡張し、MoEと拡張コンテキスト処理を維持しています。
コード生成タスクにおけるQwen3 CoderとDeepseek V3.1のベンチマーク結果
| ベンチマーク | Deepseek V3.1 推論モード | Deepseek V3.1 非推論モード | Qwen 3 Coder |
| LivecodeBench | 78% | 58% | 59% |
| Scicode | 39% | 37% | 36% |
https://twitter.com/paradite\_/status/1961365802629697770
- DeepSeek V3.1(推論モード) は、LiveCodeBench(78%)とSciCode(39%)で明らかに優れた結果を示し、Aiderでは71.6%を達成しています。Codeforcesレーティング(約1189)も、実際のコーディング能力の高さを反映しています。ただし、推論モードは計算オーバーヘッドが高くなります。
- DeepSeek V3.1(非推論モード) は、精度と効率のトレードオフにより、LiveCodeBenchで58%に低下しますが、Aiderでは同じ71.6%を維持しています。
- Qwen3-Coder-480B-A35B は、LiveCodeBenchで59%、SciCodeで36%と、DeepSeekの推論モードよりもわずかに低いスコアです。公式の主張ではSWE-BenchやCodeForces ELOでSOTAパフォーマンスを強調していますが、具体的な数値スコアは公開されていません。強みは、長文脈のコード理解と開発者ワークフローへの統合にあります。
👉 結論:
- 生の推論力とコーディングベンチマークのパフォーマンスが必要な場合は、DeepSeek V3.1(推論モード)がリードします。
- 開発者ツール、統合、および長文脈処理が必要な場合は、Qwen3-Coderの方が専門的です。
初心者向けのQwen3 Coder vs Deepseek V3.1:速度と価格
| モデル | VRAM | 推奨GPU |
| Qwen 3 Coder | 1050GB | 8 x H100 NVL |
| Deepseek V3.1 | 1424.12GB | 8 x H100 NVL |
両モデルとも同じクラスのGPUを必要としますが、Qwen 3 CoderはVRAMフットプリントが小さいため、より高速かつ効率的に動作し、Deepseek V3.1は同じ条件下ではより重く、低速です。

Deepseek V3.1の価格
Qwen 3 Coderの価格
LLM API分野における最も重要なプロバイダーの1つであるNovita AIは、安定したコスト効率の高いAPIを提供しています。価格情報から、Qwen3-CoderはDeepseek V3.1よりもわずかに安価であることがわかります。
- Deepseek V3.1: 入力トークン100万あたり$0.55 / 出力トークン100万あたり$1.66、コンテキスト長は163,840トークンです。
- Qwen3-Coder (480B A35B Instruct): 入力トークン100万あたり$0.35 / 出力トークン100万あたり$1.50、コンテキスト長は262,144トークンです。
Qwen3 Coder vs Deepseek V3.1:Pythonプログラミングにはどちらが優れているか?
1. Pythonコード生成における経験的なパフォーマンス
DeepSeek V3.1
- Aiderプログラミングベンチマークでは、初回通過率41.3%、2回目通過率71.6%を達成し、機能的なPythonコードを生成する強力な能力を示しました。また、フォーマット精度(95.6%)に優れ、構文エラーやインデントエラーは0%であり、クリーンなPythonコードを記述する上で重要です。
- 独立した評価では、さまざまなプログラミング課題で71.6%の合格率を報告し、AnthropicのClaude 4をわずかに上回っており、Pythonまたは一般的なコードタスクでの競争力の高さを示唆しています。
Qwen3-Coder
- SWE‑Bench Verifiedでは、オープンソースモデルの中で最先端のパフォーマンスを達成したと報告されています。このベンチマークには、Pythonで一般的な高度なアルゴリズム課題が含まれています。
- 一般的なコーディング評価では、中程度のタスクにおいてプレミアムモデルと同等のパフォーマンスを発揮し、正確で簡潔なコードを生成するものの、特殊なパターンや厳密な出力フォーマット(「出力のみの差分」タスク)では苦戦する可能性があるとされています。
2. 全体的なフレームワークとコンテキストの強み
- DeepSeek V3.1 は、バランスが取れた非常に有能なモデルとして描かれており、コード生成、デバッグ、エージェントタスクに優れています。簡潔な出力を提供し、Pythonワークフローを含む実世界のシナリオで競争力を維持します。
- Qwen3‑Coder は、特に長文脈のエージェント的なコーディングタスク向けに構築されており、最大約100万トークンという広大なトークンウィンドウと強力なツールサポートを提供します。Pythonおよび複数のパラダイム(OOP、関数型)に最適化されており、リポジトリ規模のコード理解と自動化に優れています。
Pythonタスクにおいて、最大のコード正確性、フォーマット精度、信頼性の高い合格率を優先する場合、特に単独のコーディングチャレンジでは、DeepSeek V3.1が明確な優位性を持ちます。
しかし、複雑でマルチファイルまたは長文脈のPythonプロジェクトに取り組んでいる場合、またはツール、自動化、エージェントワークフローとの緊密な統合が必要な場合は、Qwen3-Coderが優れた選択肢です。
Qwen3 CoderとDeepseek V3.1のコード比較
Novita Playgroundに直接アクセスして無料トライアルを開始できます!
Qwen 3 Coderモデルとdeepseek V3.1を今すぐ試す!
qwen 3 coder 480b a35b と deepseek v3.1 を比較する、インタラクティブで簡潔なウェブサイトを作成してください。
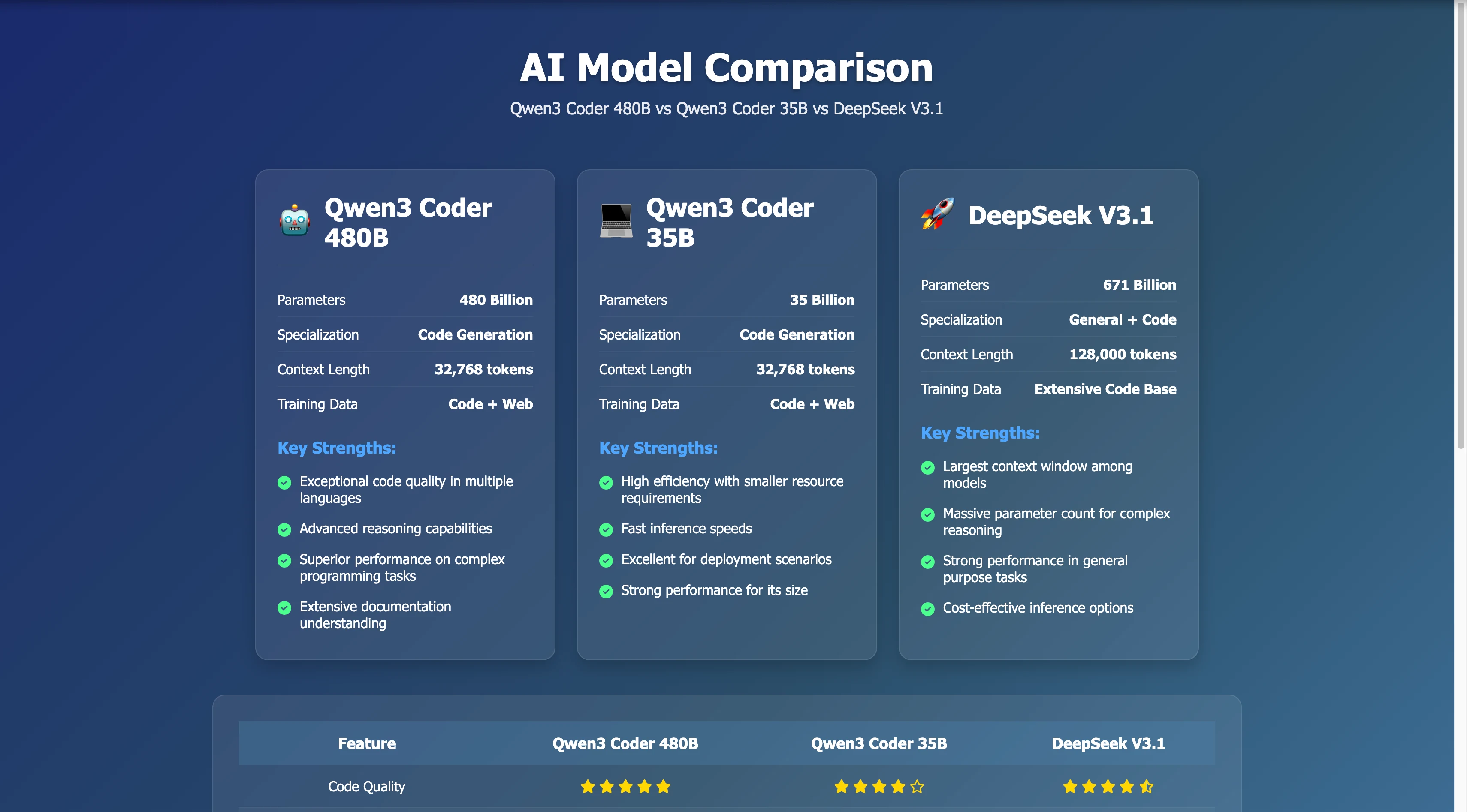
Qwen 3 Coder
強力なウェブページ生成能力: 情報レイアウトとビジュアルデザインが優れており、ユーザーフレンドリーな体験を提供します。言語は簡潔で専門的であり、よく作られた比較ページです。
高い情報精度: 主要なデータポイント、機能の位置づけ、長所/短所は、公開情報とよく一致しています。コンテキスト長は簡略化された方法で表示されていますが、全体的に大きな不正確さはありません。
高い参考価値: 一部の評価は主観的ですが、このページは異なるモデルを比較するための非常に価値の高いクイックリファレンスとして機能します。

Deepseek V3.1
このサイトは優れたUXと明確さを提供しますが、コンテンツの精度は不均一です。Qwen-3については正確ですが控えめであり、DeepSeekについては著しく不完全です。概要ツールとしては機能的ですが、正確な評価や技術的な判断には、公式のモデルドキュメントを補完することを強くお勧めします。
インタラクティブなチェスゲームを作成してください!
Qwen 3 Coder
Deepseek V3.1
Qwen 3 CoderとDeepseek V3.1にアクセスする方法
最初の方法:APIキーを取得する
ステップ1:アカウントにログインし、モデルライブラリボタンをクリックします。

Qwen 3 Coderモデルとdeepseek V3.1を今すぐ試す!
ステップ2:モデルを選択します
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始します
選択したモデルの機能を探索するために、無料トライアルを開始します。
ステップ4:APIキーを取得します
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動し、画像のようにAPIキーをコピーします。

ステップ5:APIをインストールします
使用しているプログラミング言語に固有のパッケージマネージャーを使用してAPIをインストールします。
インストール後、開発環境に必要なライブラリをインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。これは、Pythonユーザー向けのチャット補完APIの使用例です。
pip install 'openai>=1.0.0'
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
TraeでQwen 3 Coder 480B A35BおよびDeepseek V3.1を使用する
ステップ1:Traeを開き、モデルにアクセスする
Traeアプリを起動します。右上隅にある「Toggle AI Side Bar」をクリックしてAIサイドバーを開きます。次に、「AI Management」に移動し、「Models」を選択します。

ステップ2:カスタムモデルを追加し、プロバイダーとしてNovitaを選択する
「Add Model」ボタンをクリックして、カスタムモデルエントリを作成します。モデル追加ダイアログで、ドロップダウンメニューから「Provider」=「Novita」を選択します。


ステップ3:モデルを選択または入力する
「Model」ドロップダウンから、希望するモデル(DeepSeek-R1-0528、Kimi K2 DeepSeek-V3-0324、またはMiniMax-M1-80k)を選択します。目的のモデルがリストにない場合は、NovitaライブラリからメモしたモデルIDを直接入力します。使用するモデルの正しいバリアントを選択してください。
APIキーはNovitaコンソールで取得できます。
Claude CodeでQwen 3 Coder 480B A35BおよびDeepseek V3.1を使用する
ステップ1:Claude Codeのインストール
Claude Codeをインストールする前に、システムが最小要件を満たしていることを確認してください。ローカル環境にNode.js 18以上がインストールされている必要があります。ターミナルで node --version を実行してNode.jsのバージョンを確認できます。
Windowsの場合
コマンドプロンプトを開き、次のコマンドを実行します。
npm install -g @anthropic-ai/claude-code
npx win-claude-code@latest
グローバルインストールにより、システム上の任意のディレクトリからClaude Codeにアクセスできるようになります。npx win-claude-code@latest コマンドは、最新のWindows固有バージョンをダウンロードして実行します。
MacおよびLinuxの場合
ターミナルを開き、次のコマンドを実行します。
npm install -g @anthropic-ai/claude-code
Macユーザーは、追加のプラットフォーム固有のコマンドを必要とせずに、グローバルインストールを直接進めることができます。インストールプロセスは、必要な依存関係とPATH変数を自動的に構成します。
ステップ2:環境変数の設定
環境変数は、Claude CodeがNovita AIのAPIエンドポイントを介してKimi-K2を使用するように構成します。これらの変数は、Claude Codeにリクエストの送信先と認証方法を指示します。
Windowsの場合
コマンドプロンプトを開き、次の環境変数を設定します。
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Novita API Key>
set ANTHROPIC_MODEL="qwen/qwen3-coder-480b-a35b-instruct"
set ANTHROPIC_SMALL_FAST_MODEL=qwen/qwen3-coder-480b-a35b-instruct
<Novita API Key> を、Novita AIプラットフォームから取得した実際のAPIキーに置き換えてください。これらの変数は現在のセッション中はアクティブなままであり、コマンドプロンプトを閉じるとリセットする必要があります。
MacおよびLinuxの場合
ターミナルを開き、次の環境変数をエクスポートします。
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
export ANTHROPIC_MODEL="qwen/qwen3-coder-480b-a35b-instruct"
export ANTHROPIC_SMALL_FAST_MODEL="qwen/qwen3-coder-480b-a35b-instruct"
ステップ3:Claude Codeの起動
インストールと設定が完了したら、プロジェクトディレクトリでClaude Codeを起動できます。cd コマンドを使用して、目的のプロジェクトの場所に移動します。
cd <your-project-directory>
claude .
ドット(.)パラメータは、Claude Codeが現在のディレクトリで動作するように指示します。起動すると、インタラクティブセッションでClaude Codeのプロンプトが表示されます。
これにより、ツールが指示を受け付ける準備ができたことを示します。インターフェースは、自然言語プログラミングのインタラクションのためのクリーンで直感的な環境を提供します。
ステップ4:VSCodeまたはCursorでClaude Codeを使用する
Claude Codeは、一般的な開発環境とシームレスに統合されます。既存のワークフローを強化し、置き換えるものではありません。
VSCodeまたはCursor内のターミナルでClaude Codeを直接使用できます。これにより、AIアシスタンスを活用しながら、使い慣れた開発ツールへのアクセスを維持できます。
さらに、Claude CodeプラグインはVSCodeとCursorの両方で利用できます。これらのプラグインは、これらのエディターとのより深い統合を提供し、インラインAIアシスタンスやコード提案などを提供します。
Qwen CodeでQwen 3 Coder 480B A35BおよびDeepseek V3.1を使用する
Qwen CodeはGemini Codeをベースに開発されていますが、エージェント的なコーディングタスクでQwen3-Coderのパフォーマンスを最大化するために、プロンプトとツール呼び出しプロトコルを適応させています。
ステップ1:Qwen Codeをインストールする
前提条件: Node.jsバージョン20以上がインストールされていることを確認してください。 公式Node.jsウェブサイトからダウンロードできます。
パッケージをグローバルにインストールします。
npm install -g @qwen-code/qwen-code
ステップ2:環境変数を設定する
Windows(コマンドプロンプト)の場合:
set OPENAI_API_KEY=Your_Novita_API_Key
set OPENAI_BASE_URL=https://api.novita.ai/v3/openai
set OPENAI_MODEL=qwen/qwen3-coder-480b-a35b-instruct
LinuxおよびMac(Bash)の場合:
export OPENAI_API_KEY="Your_Novita_API_Key"
export OPENAI_BASE_URL="https://api.novita.ai/v3/openai"
export OPENAI_MODEL="qwen/qwen3-coder-480b-a35b-instruct"
ステップ3:コーディングを開始する
設定が完了したら、選択したNovita AIモデルでQwen Codeの使用を開始できます。これでツールは、すべてのコーディング支援タスクに指定されたモデルを使用するようになります。
cd <your-project-directory>
qwen .
効率的な統合、長文脈サポート、スケーラブルなコーディングワークフローが必要な場合は、Qwen3-Coderを選択してください。
生の推論力とベンチマークでトップクラスのPython精度が必要な場合は、DeepSeek V3.1を選択してください。
よくある質問
どちらのモデルがよりリソース効率的ですか?
Qwen3-Coderは軽量で、量子化なしで約250GBのVRAMを必要とし、FP8/4ビット量子化とCPUオフロードをサポートしているため、デプロイが容易です。 DeepSeek V3.1はより重く(671Bパラメータ)、より多くのメモリを必要としますが、低ビット量子化により少ないGPUでも使用可能になります。
Pythonプログラミングにはどちらのモデルが適していますか?
DeepSeek V3.1はベンチマークスコアが高く、フォーマットエラーが少なく、単独のコーディングタスクで優れています。 Qwen3-Coderは、マルチファイル推論が重要なリポジトリ規模の長文脈Pythonプロジェクトで優れたパフォーマンスを発揮します。
DeepSeek V3.1とQwen3-Coderは誰が使用すべきですか?
DeepSeek V3.1 → 競技プログラマー、研究者、最大の正確性と推論能力を必要とする開発者向け。 Qwen3-Coder → 大規模なコードベース、自動化パイプライン、長文脈タスクを管理するエンジニアやチーム向け。コンテキスト長とツールが重要な場合に最適です。
Novita AI は、AIの野望を実現するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の高いツールを提供します。インフラストラクチャを排除し、無料で始めて、AIのビジョンを現実にしましょう。
おすすめの記事
Llama 3.2 3B vs DeepSeek V3:効率性とパフォーマンスの比較.



