

主なポイント
適切なGPUの選択は、効率的なAIモデルのトレーニングとデプロイに不可欠です。
主な考慮事項として、処理能力、メモリ容量、電力効率、フレームワークとの互換性が挙げられます。
NVIDIAとAMDが市場を支配していますが、新興プレイヤーも競争力のあるソリューションを提供しています。
ベンチマークツールは、特定のAIタスクに基づいてGPUパフォーマンスを評価するのに役立ちます。
Novita AIのような専門家と提携することで、GPUニーズに合わせた貴重な洞察とカスタマイズされたソリューションを得ることができます。
AIモデリングのためのGPU比較は、人工知能が世界中の産業を変革するにつれて、非常に重要になっています。現代のAIモデリングにはますます強力なコンピューティングソリューションが求められており、GPUの選択は研究者や開発者にとって重要な決定となっています。広範なGPU比較を通じて、さまざまなAIモデリングタスクには特定のGPU機能と構成が必要であることがわかりました。この包括的なガイドでは、AIモデリングの主要なGPU仕様を分析し、さまざまなGPUオプションを比較して、AIプロジェクトに最適なハードウェアを選択するのに役立ちます。
AIモデリングのためのGPUアーキテクチャの理解

GPUアーキテクチャの基本
GPU(Graphics Processing Unit)は、多数の小さな専用コアを備えて設計されており、複数の計算を同時に実行できます。この並列処理能力により、GPUは特定の種類の計算タスク、特にAIモデリングに関わるタスクにおいて、CPU(Central Processing Unit)よりもはるかに効率的です。
CPUが通常、一度に一つのタスクを逐次的に処理するのに対し、GPUはタスクを多数の小さな類似サブタスクに分割することで優れた性能を発揮します。CPUはこれらのタスクを一つずつ処理しますが、GPUは多数のコアを使用して同時に処理します。これにより、GPUはAIやディープラーニングで一般的な行列乗算や画像処理などの高度に並列なタスクに非常に効果的です。
これをよりよく理解するために、多くの小さな反復部分に分割できるタスクを想像してください。CPUは各部分を逐次的に処理しますが、GPUはすべての部分を並列に処理します。これは、各作業者がタスクの一部を同時に処理する大規模なチームのようなものです。この並列性により複雑な計算が劇的に高速化され、大量のデータを迅速に処理する必要があるAIトレーニングや推論などのタスクにGPUが不可欠となります。
つまり、GPUは非常に効率的な作業チームのように機能し、各メンバーが同時に大きな仕事の一部を担当します。この集合的な努力により計算が高速化され、高いパフォーマンスを要求するAIやその他の計算集約型アプリケーションにとって、GPUが頼りになるハードウェアとなっています。
GPUがAIおよび機械学習タスクを高速化する方法
機械学習とディープラーニングは、良好なパフォーマンスを発揮するために膨大なデータ量に依存しています。GPUは大量のデータを迅速に分析できるため、このプロセスの高速化に不可欠です。これによりトレーニング時間が大幅に短縮され、AIモデルがより効率的にパターンを学習・認識できるようになります。トレーニングデータセットは通常、数百万のデータポイントで構成されており、GPUを使用すればこれらの多くを同時に処理できるため、トレーニングプロセス全体がはるかに高速になります。
例えば、アルゴリズムが画像を解釈・理解することを学習するコンピュータビジョンでは、GPUは数百万のピクセルを一度に処理できます。この並列処理能力により、AIモデルは画像内の複雑なパターンや特徴を検出できます。その結果、物体検出や画像分類などのタスクがより高速になるだけでなく、より正確になります。
さらに、GPUはAIモデルがリアルタイムアプリケーションで使用されるデプロイフェーズでも重要です。推論と呼ばれるこのフェーズでは、モデルは新しい未確認のデータを迅速に処理する必要があります。GPUはこれを可能にし、AIシステムがほぼリアルタイムで応答できるようにすることで、AI駆動型アプリケーションをエンドユーザーにとってより効率的で使いやすいものにします。
AIモデリングにおけるGPUの主要コンポーネント
いくつかの主要コンポーネントが、GPUをAIモデリングに非常に効果的にしています。主な要素はコア数とそのクロック速度です。コア数が多く、速度が速いほど、GPUはデータを処理し、AIモデルのトレーニングや実行に必要な複雑な数学的計算をより迅速に実行できます。
もう一つの重要な要素はメモリ帯域幅であり、これによりGPUがデータにアクセスして操作する速度が決まります。ディープラーニングで一般的に使用される大規模なニューラルネットワークは、トレーニングと推論中に膨大なデータ量を処理するために、十分なメモリ帯域幅を必要とします。これによりGPUのコアにデータが継続的に供給され、遅延が防止され、計算パフォーマンスが最適化されます。
さらに、特にデータセンターや大規模なAIプロジェクトでは、電力効率がますます重要になっています。最新のGPUは、消費電力を抑えながら優れたパフォーマンスを提供するように設計されています。これにより運用コストが削減されるだけでなく、AIプロセスがより持続可能になり、財務的な節約と環境へのメリットの両方に貢献します。
パフォーマンスのベンチマーク:AIモデリングのためのGPU比較における主要指標
処理能力と速度が重要な理由
処理能力は一般的にテラフロップス(TFLOPs)で測定され、GPUが計算を実行する速度を示します。TFLOPs値が高いほど、特にAIタスクで一般的な複雑な計算や大規模データセットを処理する際に、優れたパフォーマンスを意味します。
ベンチマークは、異なるGPUのパフォーマンスを比較するのに役立ちます。標準化されたテストを提供し、GPUがさまざまなAIワークロードをどの程度処理できるかを測定します。例えば、TFLOPsが多いGPUは、数百万のパラメータを含むディープラーニングモデルのトレーニングを大幅に高速化できます。場合によっては、性能の低いGPUと比較して、トレーニング時間を数日から数時間に短縮できます。
ただし、ベンチマークだけに頼るのは誤解を招く可能性があります。すべてのシナリオで実際のパフォーマンスを反映するとは限りません。実際に体験するパフォーマンスの向上は、作業しているAIモデルの特定のタイプ、フレームワークの最適化の程度、データセットのサイズや複雑さなど、いくつかの要因に依存します。システムアーキテクチャや冷却ソリューションなどの他の変数も、全体的なパフォーマンスに影響を与える可能性があります。
AIモデリングにおけるメモリ帯域幅と容量
メモリ帯域幅と容量は、GPUが複雑な計算をどれだけ効率的に処理するかに直接影響するため、AIモデリングにおいて重要な要素です。AI開発では、大量のデータを迅速に処理する必要があり、メモリ帯域幅と容量の両方がスムーズで効率的な動作を確保する上で重要な役割を果たします。
メモリ帯域幅は、GPUがデータにアクセスできる速度を決定し、特にトレーニングフェーズで重要です。高いメモリ帯域幅により、GPUとそのメモリ間のデータ転送が高速化され、ディープラーニングモデルのトレーニングに必要な大規模データセットへのアクセスが迅速になります。この速度はボトルネックを減らし、全体的な計算パフォーマンスを向上させます。
一方、メモリ容量は、大規模なデータセットとトレーニングされたモデル自体を保存するために不可欠です。ディープラーニングモデルは数百万(または数十億)のパラメータを持つことがあり、十分なメモリがない場合、GPUは必要な情報をすべて保存するのに苦労し、処理時間の遅延やシステムクラッシュにつながる可能性があります。
AI GPUの電力効率と熱設計
AI GPUでは、電力効率と熱設計がピークパフォーマンスを維持するために不可欠です。電力効率の高いGPUは、パフォーマンスを犠牲にすることなく長時間のトレーニングセッションを可能にし、運用コストの削減につながります。
熱設計は、GPUが重いワークロード下でも低温を維持し、過熱を防ぎ、一貫したパフォーマンスを維持することを保証します。最適化された冷却システムは、GPUの寿命を延ばし、パフォーマンスを低下させるサーマルスロットリングを防ぎます。
AIモデリングフレームワークとの互換性
AI開発は、TensorFlow、PyTorch、MXNetなどのソフトウェアフレームワークに依存しており、これらはAIモデルの構築とデプロイに必要な機能、ライブラリ、ツールを提供します。これらのフレームワークは開発プロセスを簡素化し、モデルトレーニングの効率を向上させます。
GPUを選択する際には、最も頻繁に使用するAIフレームワークとの互換性を確認することが重要です。異なるフレームワークは特定のGPUアーキテクチャで最適に動作するため、適切なものを選択することでパフォーマンスを大幅に向上させることができます。Novita AIのような主要なGPUメーカーは、優れたサポートとドライバーを提供し、一般的なAIフレームワークとのシームレスな統合を実現し、最適な結果をもたらします。
さらに、オープンソースライブラリの可用性と周囲のコミュニティの強さも考慮してください。オープンソースツールは、事前トレーニング済みモデル、データセット、カスタマイズ可能なコードを提供することで、AIモデルの開発を加速します。強力なコミュニティは、貴重な洞察、トラブルシューティングの支援、協力的な環境を提供し、イノベーションを促進し、AI開発を前進させます。
市場の主要GPU:AIモデリングのための包括的なGPU比較
NVIDIAの最新製品:概要
NVIDIA GPUはAIタスク向けに構築されています。ディープラーニング、自然言語処理、コンピュータビジョンと良好に連携します。これらのGPUには、AI計算用の専用コア、高速データアクセス用の高速メモリ、優れたエネルギー効率が備わっています。
AI研究に最適なGPUを検討する際、NVIDIAは非常に重要です。そのGPUは優れた計算能力と効率性を備えています。NVIDIA RTX 4090やNVIDIA RTX 3090のような人気モデルは、印象的なパフォーマンスと困難なAIタスクを処理する能力でAI開発者に好まれています。さらに、NVIDIA RTX 6000 AdaとA100 SXM4は、AI研究分野で強力なオプションです。RTX 6000 Adaは、AI駆動型ワークロード向けの高度な機能をもたらし、モデルトレーニングの限界を押し広げる卓越したメモリと処理能力を備えています。A100 SXM4は、大規模AIアプリケーション向けのトップクラスの選択肢であり、その高いスループットにより、AI開発における高性能コンピューティングタスクに最適な比類のないパワーを提供します。
これらのGPUは、研究者がモデルを迅速かつ効果的にトレーニングできるようにすることで、AI開発分野に貢献し、人工知能における発見と進歩を加速させています。
AMDの最新製品:概要
AMDはGPU市場で強力なプレイヤーになりました。AMDの成功の大きな理由は、オープンスタンダードとクロスプラットフォームでの動作に重点を置いていることです。AMD GPUは通常、価格対性能比に優れています。そのため、予算を重視する研究グループやスタートアップにとって賢い選択肢となっています。
AMDの最新製品には、RDNA 3アーキテクチャのRadeon RX 7900 XTXやRadeon RX 7900 XTなど、要求の厳しいタスク向けのトップクラスのパフォーマンスを提供する強力なGPUが含まれています。より手頃でありながら強力なオプションとして、RDNA 2シリーズのRadeon RX 6800 XTやRadeon RX 6700 XTも優れた選択肢です。さらに、AMDのRadeon Instinctシリーズ(MI100やMI50など)は高性能コンピューティング市場に対応し、AIトレーニングやデータセンターアプリケーション向けの専用ハードウェアを提供します。
GPUニーズにNovita AIを選ぶ理由
Novita AIは、GPUニーズに最適な選択肢です。新しいテクノロジーを活用してGPUを製造しています。これらのGPUはAI開発タスクを支援します。大規模データセットの処理を高速かつ効率的に行います。これは複雑なAIモデルのトレーニングにとって重要です。AI開発者はNovita AIを使用することで、より優れたパフォーマンスを得られます。また、データから貴重な洞察を得ることもできます。Novita AIは、AI分野で優れたサポートと専門知識を提供します。そのため、あらゆるAIモデリング作業において信頼できるパートナーとなります。Novita AIを選ぶことは、高品質なパフォーマンスとAIワークフローへの完璧な適合を意味します。
当社の製品にご興味があれば、以下の手順に従って詳細をご確認ください。
ステップ1:アカウント登録
初めて当社の製品を探索する場合は、ウェブサイトでアカウントを登録してください。登録後、ウェブページの 「GPUs」 ボタンをクリックして開始します。

[こちらをクリック](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_GPU Comparison for AI Modeling: A Comprehensive Guide)
ステップ2:GPUsをクリック
お客様の特定のニーズに合わせて、選択可能なテンプレートを提供しています。または、独自のカスタムテンプレートデータを作成することもできます。当社のサービスにより、NVIDIA RTX 4090などの高性能GPUにアクセスでき、十分なVRAMとRAMを備え、最も複雑なAIモデルでも効率的にトレーニングできます。最適なオプションをお選びください。
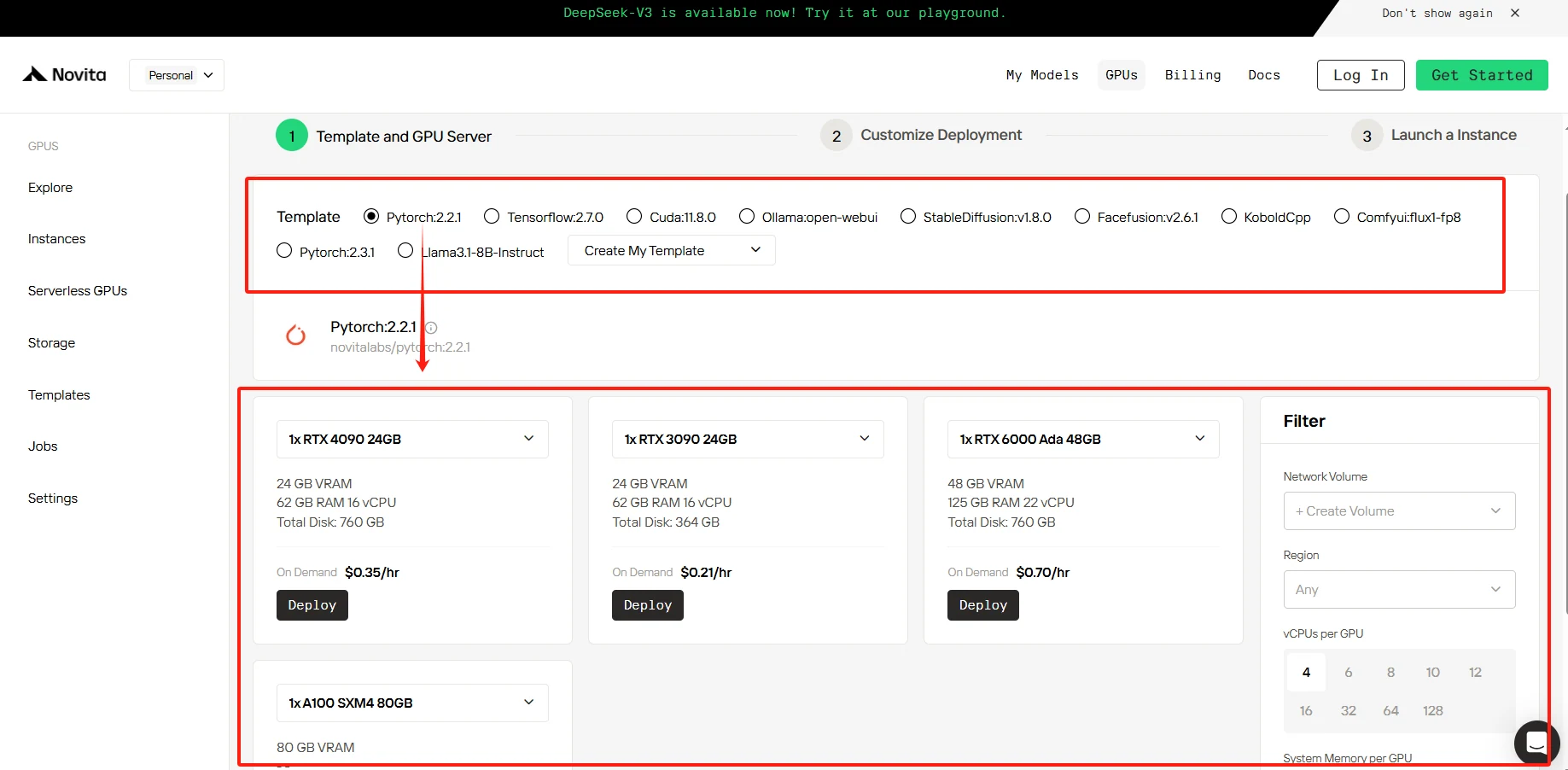
[こちらをクリック](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=GPU Comparison for AI Modeling: A Comprehensive Guide)
ステップ3:デプロイメントをカスタマイズ
このセクションでは、特定のニーズに合わせてデータを調整できます。コンテナディスクは60GBの無料ストレージ、ボリュームディスクは1GBの無料スペースを提供します。これらの制限を超えた場合、追加料金が発生します。
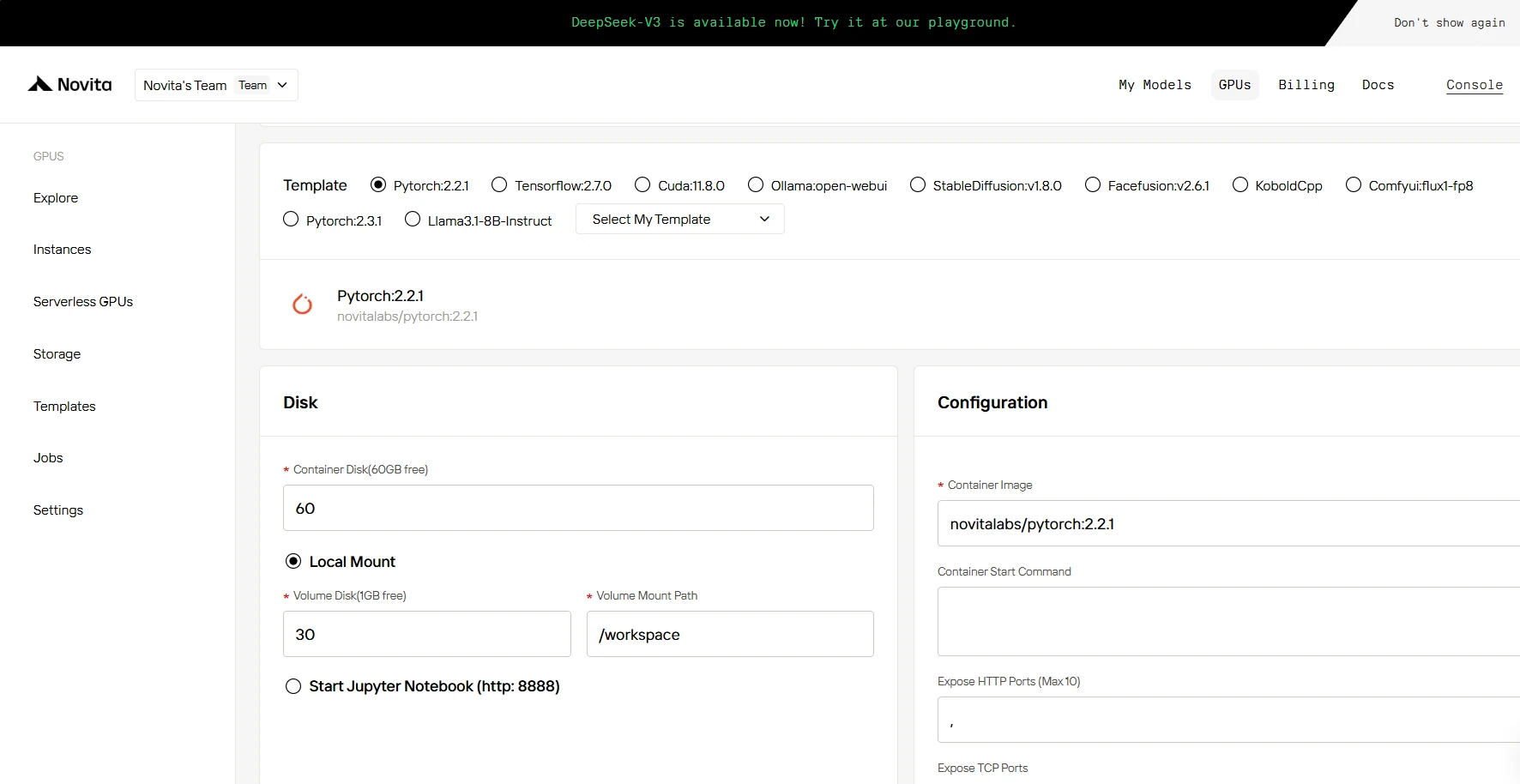
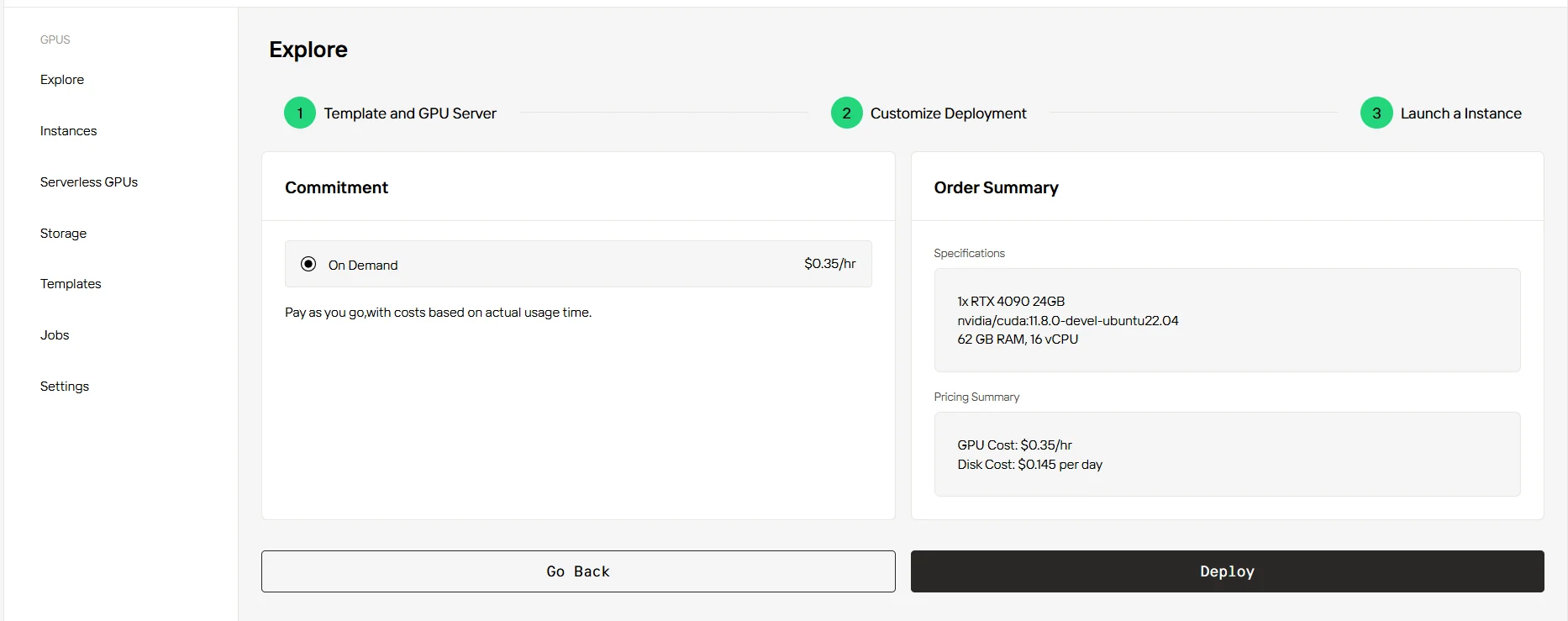
ステップ4:インスタンスを起動
Novita AI GPUインスタンスは、最先端のCUDA 12テクノロジーを活用し、高性能コンピューティングの要求を満たす、強力で効率的なクラウドベースのGPUコンピューティングソリューションを提供します。
結論
結論として、AIモデリングのためにはGPU設計を理解し、パフォーマンスを測定することが重要です。処理能力、メモリサイズ、AIツールとの連携の良さは、タスクに適したGPUを選択する際に重要です。NVIDIAとAMDは依然として主要プレイヤーですが、新たな競合他社も市場に参入しています。AIプロジェクトに包括的なGPUソリューションが必要な場合は、Novita AIとの提携を検討してください。ベンチマークと実際のパフォーマンスに基づいて賢明に選択することで、AI研究とモデリング業務を改善できます。
よくある質問
サーバーレスGPUと従来のGPUは、AIタスクにおいてどのように比較されますか?
サーバーレスGPUは、AIタスクのための簡単なスケーリングと適応の方法を提供します。ユーザーはインフラストラクチャを管理することなく、必要なときにGPUリソースを取得できます。従来のGPUはより多くの制御を提供しますが、サーバーレスGPUは継続的な管理の必要性を排除します。
サーバーレスGPUは大規模なAIモデルトレーニングを処理できますか?
サーバーレスGPUは、大規模なAIモデルのトレーニングに適しています。これは、サービスが十分なGPUリソースと、複数のシステムにわたってトレーニングする方法を備えている場合に当てはまります。サーバーレスコンピューティングは、大規模なデータセットや複雑なモデルを簡単に処理できます。
AIアプリケーションにサーバーレスGPUを使用する際の課題は何ですか?
サーバーレスGPUの課題には、潜在的な遅延、特定のベンダーへの依存、分散環境でのデバッグの難しさが含まれます。AIアプリケーションをデプロイして使用する際には、これらの問題を考慮することが重要です。
[Novita AI](https://novita.ai/?utm_source=blogs_gpu&utm_medium=article&utm_campaign=GPU Comparison for AI Modeling: A Comprehensive Guide) は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを構築およびスケーリングのために提供します。
おすすめの記事



