

開発者は、芸術的自由に最適化された画像モデルと、商用の信頼性のために設計された画像モデルの間で、ますます深刻なジレンマに直面しています。
プロダクションAPIを構築するチームは、Nano Banana 2.0のようなアート指向のジェネレーターから、一貫性のないテキストレンダリング、指示への弱い従順性、予測不可能なレイアウトに悩まされています。本稿では、GLM-Imageをプロダクショングレードの代替案として位置づけ、そのアーキテクチャ、ベンチマーク、速度、ハードウェアプロファイルを分析し、開発者が構造化・テキストクリティカル・多言語アプリケーションに適したモデルを選択できるようにします。

GLM Image より
GLM Imageのアーキテクチャ概要
GLM-Imageはハイブリッド自己回帰+拡散デコーダアーキテクチャを採用し、コンテンツの推論とピクセルレンダリングを分離します。自己回帰コンポーネントはセマンティックレイアウトと指示解釈を担当し、拡散デコーダが高解像度の詳細を埋め込みます。この構造は、ピクセルのノイズ除去に最適化されているものの、正確な指示遵守とテキストの明瞭さにしばしば失敗する純粋な拡散モデルとは異なります。
| コンポーネント | 役割 | パラメータ数 |
|---|---|---|
| 自己回帰生成器 | セマンティックプランとレイアウトトークンの生成 | 9B(GLM-4-9Bベース) |
| 拡散デコーダ(シングルストリームDiT) | 高周波画像詳細のレンダリング | 7B |
| 合計 | ハイブリッド表現 | 16Bパラメータ |
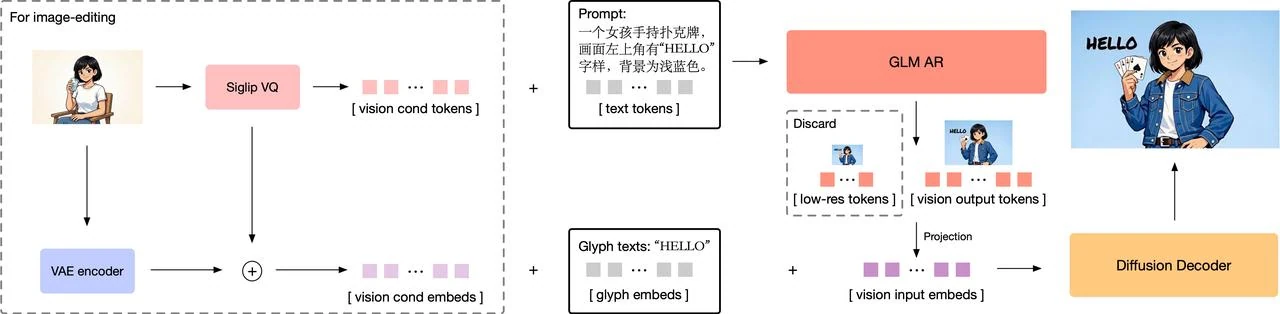
GLM より
GLM ImageとNano Bananaのベンチマーク性能比較
GLM-Imageは構造化テキストレンダリング、特に複数領域のテキストにおいて優れており、一方Nano Bananaは主観的なアーティスティック出力で優位に立つ傾向があります。
読みやすいテキストと構造化図表にはGLM-Imageの方が信頼性の高い出力を生成しがちです。スタイルの豊かさと主観的な構図の質では、Nano Bananaおよび独自のジェネレーターが依然としてリードしている可能性があります。
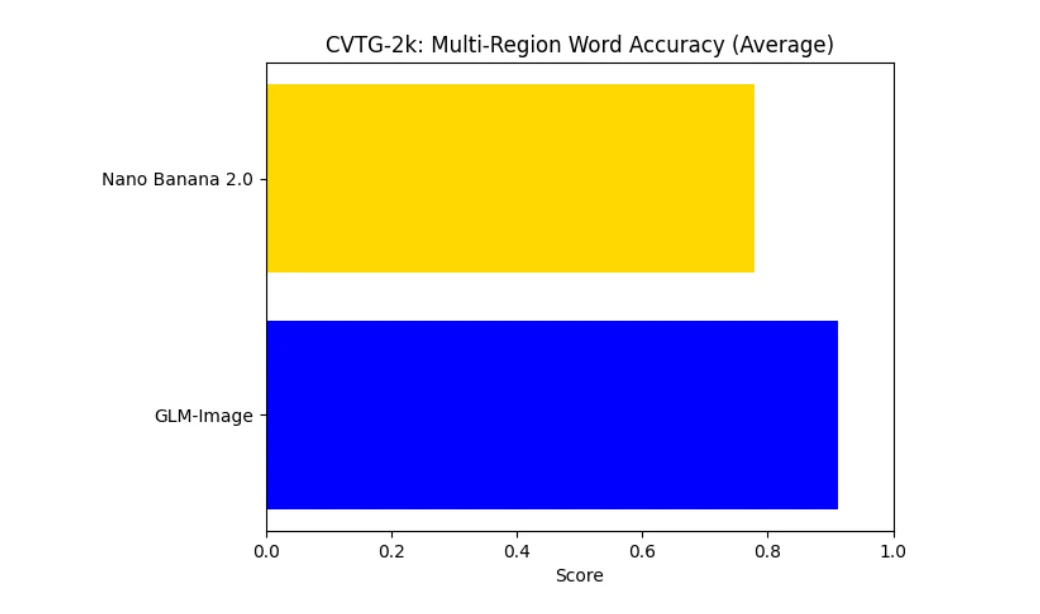
CVTG-2kにおいて、GLM-Imageは複数領域の単語精度でNano Bananaを大幅に上回ります。これは、より強い文字レベルの忠実度と、複数のテキストブロックが共存する場合の高いロバスト性を示しています。この差は、レイアウトの複雑さが認識品質を即座に低下させない、制御可能なテキスト生成に特化したGLM-Imageの特性を反映しています。
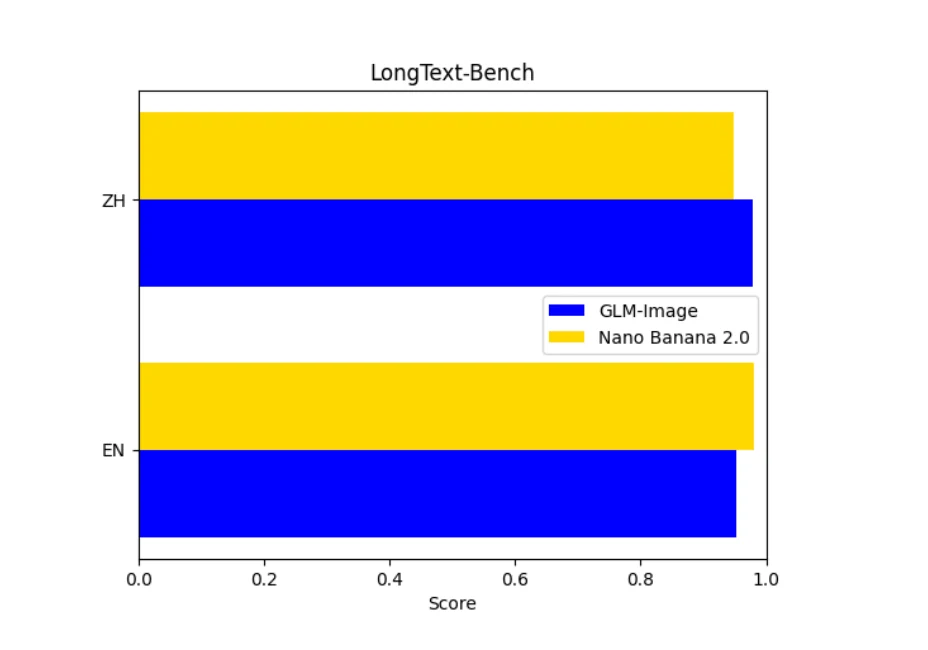
LongText-Benchでは、優位性は言語に依存します。Nano Bananaは英語の長文テキストでわずかにリードし、長いラテン文字列に対する全体的な一貫性が優れていることを示唆しています。GLM-Imageは中国語の長文で圧倒し、より信頼性の高い文字の連続性、改行、密集したグリフレンダリングを提供します。このため、GLM-Imageは中国語のポスター、インフォグラフィック、説明図にはより安全な選択肢となり、Nano Bananaは英語のスローガンや段落に対してより高い上限を提供します。
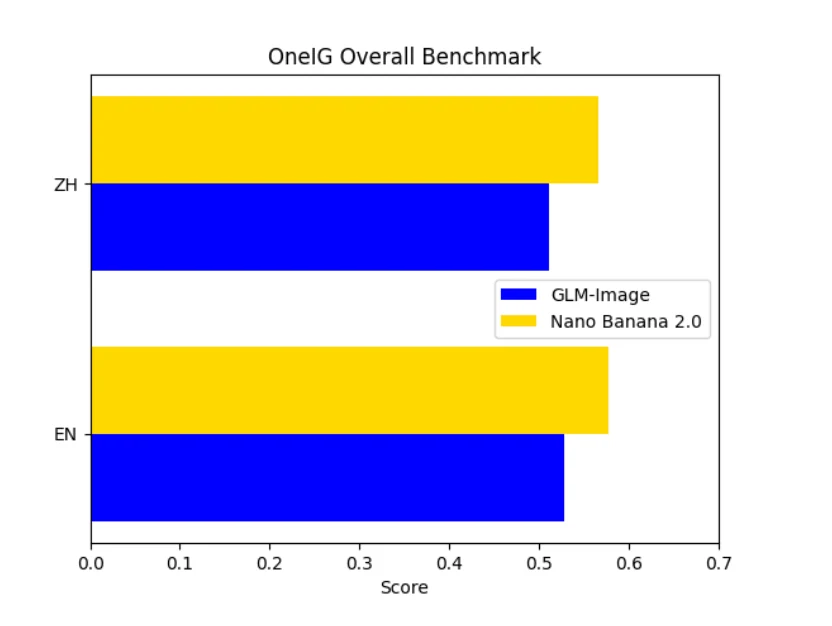
OneIG全体では、Nano Bananaが両言語で一貫して高いスコアを記録しています。これは、より強力なアライメント、スタイル表現、全体的な視覚的構成を反映しています。GLM-Imageはテキストの忠実度で非常に優れているものの、芸術的な豊かさと意味的統合では劣ります。
GLM Imageのハードウェア要件
| 展開タイプ | 推奨GPU | VRAM要件 |
|---|---|---|
| 高スループットAPI | NVIDIA H100 / A100 | 80GB |
| 単一インスタンステスト | NVIDIA A40 / RTX 6000 | 48GB |
| 低コスト量子化 | TensorRT/FP16対応GPU | 24GB |
デュアルモジュール設計と比較的大きなパラメータ数により、効率的な拡散モデルと比較してメモリフットプリントが大きくなります。特別に最適化されていない限り、アーキテクチャのシャードを同時に常駐させる必要があります。
GLM Imageの商用利用における考慮事項
GLM-Imageを選ぶべき場合:
- インフォグラフィック、図表、ポスターの自動生成で正確なラベルが必要な場合。
- 多言語テキストを意識したビジュアルアセットパイプライン。
- 仕様への準拠が美的考慮よりも優先される商用API。
Nano Bananaが適している可能性がある場合:
- スタイルの豊かさとアーティストレベルの詳細を伴うクリエイティブなアート生成。
- 視覚的多様性とフォトリアリズムを優先するアプリケーション。
- 外部知識の統合(検索など)が出力を強化するケース。
プロンプト比較
Novita AIでGLM Imageにアクセス
GLM Imageのテキストから画像への生成ツールは、テキストプロンプトから高品質な画像を生成し、細かい詳細と高い一貫性を持つHD画像を生成します。
これは非同期APIです。task_idのみが返されます。task_idを使用してタスク結果APIにリクエストし、動画生成結果を取得してください。
import requests
url = "https://api.novita.ai/v3/async/glm-image"
payload = {
"size": "<string>",
"prompt": "<string>",
"quality": "<string>",
"watermark_enabled": True
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
GLM-Imageは正確性を重視した計画第一の画像モデルであり、Nano Banana 2.0は芸術的表現を優先します。
GLM-Imageは複数領域のテキストレンダリング、セマンティック忠実度、多言語安定性に優れ、予測可能な出力を要求する商用APIに最適です。Nano Banana 2.0はクリエイティブでスタイル重視のタスクで引き続き強みを発揮します。選択は、プロダクションの信頼性と芸術的自由のトレードオフです。
GLM-ImageとNano Banana 2.0のどちらを選ぶべきですか?
製品に正確なテキスト、構造化レイアウト、または多言語コンテンツが必要な場合はGLM-Imageを選択し、アート主導の創造性を重視する場合はNano Banana 2.0を選択してください。
アーキテクチャ的にGLM-ImageとNano Banana 2.0はどのように異なりますか?
GLM-Imageは自己回帰プランナーと拡散デコーダを使用しますが、Nano Banana 2.0は視覚スタイルに最適化された純粋な拡散設計に従います。
テキストベンチマークではどちらのモデルが優れていますか?
GLM-ImageはCVTG-2kの複数領域単語精度でリードし、構造化テキストタスクでNano Banana 2.0を上回ります。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを構築とスケーリングのために提供しています。



