

GLM-4.7-Flashは、30Bクラスのモデルであり、パフォーマンスと効率性の実用的なバランスを追求しています。30B-A3B MoEアーキテクチャを採用し、200Kコンテキストをサポート。さらに大規模な生成上限(Novitaでは**~131,100最大出力トークン**と記載)を持ち、長文書、大規模コードベース、マルチステップワークフローに適しています。また、推論、関数呼び出し、構造化出力をサポートし、より信頼性の高いツール利用とパイプライン構築を実現します。
この記事では、そのアーキテクチャ、ベンチマークの解釈、最適なシナリオ、そして**Novita AIのAPI**を介したアクセス方法を説明します。
GLM-4.7-Flashのアーキテクチャとは
||| |:—:|:—:|:—:| |アーキテクチャ/機能|内容|実際の重要性| |30B-A3B MoE|総モデル容量は大きく、トークンあたりの活性化パラメータは少ない|本番ワークロードにおいてコスト・スループット・品質のバランスが向上(大規模推論が効率的に)| |200Kコンテキスト|プロンプト+履歴+文書に対して非常に長いコンテキストウィンドウ|大規模コードベース、長いPRD/ログ、複数文書の統合を、あまりチャンク分割や検索ホップを必要とせずに処理| |~131,100最大出力(Novita上限)|Novitaのモデルページに記載されている高い生成上限(プラットフォームの制限は異なる場合あり)|長文出力に有用:マルチファイルパッチ、詳細レポート、構造化計画、大規模JSONレスポンス| |推論モード|オプションでより深いマルチステップ推論動作|困難なマルチステップタスクや長期的計画の信頼性を向上| |関数呼び出し|構造化ツールスキーマによるネイティブなツール呼び出し|予測可能なツール連携(検索、テストランナー、リトリーバーなど)を実現| |構造化出力|スキーマに準拠した出力|自動化パイプラインにおけるパース失敗やグルーコードのバグを低減|
💡要するに: GLM-4.7-Flashは、効率的な 30B-A3B MoE 設計と 200Kコンテキスト、大容量出力、制御可能な統合機能(推論、関数呼び出し、構造化出力)を組み合わせており、長いワークフローや本番パイプラインに実用的です。
GLM-4.7-Flashのパフォーマンスベンチマーク
このチャートでは6つのベンチマークを評価し、エージェントコーディング+ツール駆動ワークフローに直接対応します。以下は各スコアの意味と、GLM-4.7-Flash (30B-A3B) が Qwen3-30B-A3B-Thinking-2507 および GPT-OSS-20B と比較してどうかを示しています。
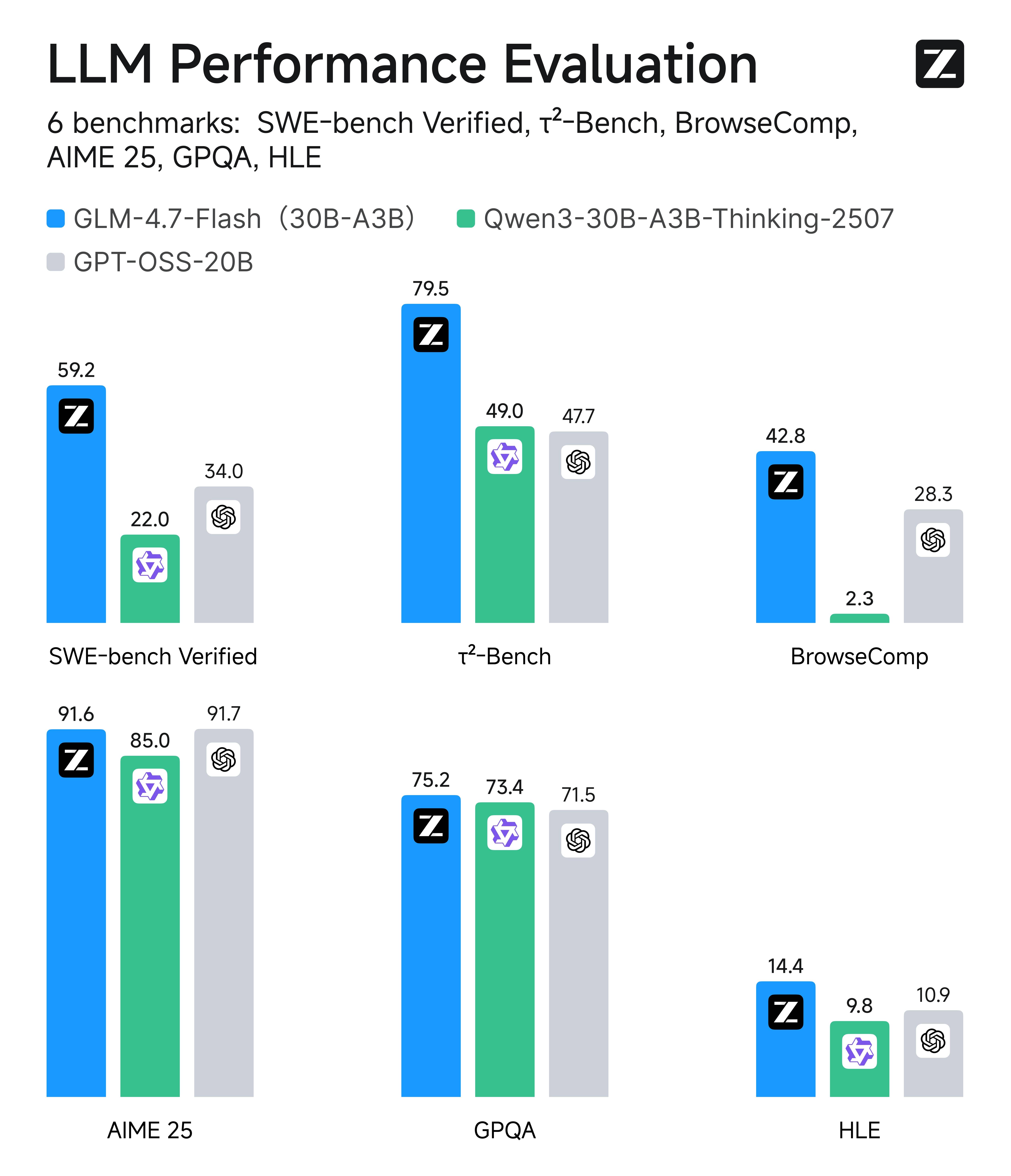
ベンチマーク → 能力マッピング
| ベンチマーク | 測定内容(能力) | GLM-4.7-Flash | Qwen3-30B-A3B | GPT-OSS-20B | 要点 |
| SWE-bench Verified | 実際のリポジトリでのバグ修正(パッチ → テスト合格) | 59.2 | 22 | 34 | Flashが大きくリード → エージェントによるコード修正ループに優れる |
| τ²-Bench | マルチステップツール推論(計画 → ツール呼び出し → 適応) | 79.5 | 49 | 47.7 | Flashが約30ポイントリード → ツールオーケストレーションの安定性が高い |
| BrowseComp | Webナビゲーションと情報収集 | 42.8 | 2.3 | 28.3 | Flashが最良 → より信頼性の高いブラウジング+統合エージェント |
| AIME 25 | 競技レベルの数学推論 | 91.6 | 85 | 91.7 | Flash ≈ GPT-OSS → 速度を犠牲にせず強力な数学能力 |
| GPQA | 大学院レベルの科学推論 | 75.2 | 73.4 | 71.5 | Flashがわずかにリード → 高難度QAに優れる |
| HLE | 困難な論理/エッジケース推論 | 14.4 | 9.8 | 10.9 | Flashがリード → トラップに対する頑健な推論が強い |
🤖主なポイント
- エージェントコーディングの信頼性: 実際のリポジトリでテスト合格する修正を生成する能力が高い(SWE-bench Verified)。
- 安定したマルチステップツール実行: 計画 → ツール呼び出し → 反復のループ(τ²-Bench)で優れたパフォーマンスを発揮し、ツール拡張エージェントの堅固な基盤となる。
- 頑健なブラウジング+統合: 研究スタイルのワークフロー向けにWebナビゲーション、情報検索、要約(BrowseComp)で効果的。
- 競争力のあるコア推論: 速度重視の設計を犠牲にせず、数学/科学/論理推論(AIME 25、GPQA、HLE)で強力なパフォーマンスを維持し、複雑な判断をサポート。
GLM-4.7-Flashが最適なシナリオ
ローカル/プライベートデプロイメント: プライバシー、コンプライアンス、予測可能なレイテンシのためにオンプレミス推論が必要で、かつ強力な汎用能力を維持したい場合に最適な、導入しやすい30B-A3B MoEモデル。
コスト重視のスケール: Novitaの価格設定に加えキャッシュ読み取りにより、繰り返し使用されるプロンプトプレフィックス(システムプロンプト、ツールスキーマ、ルーティングルール)の単価を削減。特に高スループットアプリケーションで効果的。
コーディング成果物(パッチ→テスト→反復): バグ修正、リファクタリング、CI対応の修復タスクなど、実際にテストに合格する変更が重要な実践的なエンジニアリングループに最適(SWEスタイルワークフロー)。
長いコンテキストのドキュメントとコードベース: 200Kコンテキストにより、大規模PRD、長いログ、複数ファイルにわたるコードベースの統合を、過度なチャンク分割や検索ステッチングなしで処理。
ツール拡張パイプラインとJSON: 関数呼び出しと構造化出力をサポートし、スキーマ検証済みJSONと決定論的なダウンストリームアクションを必要とする本番システムへの組み込みが容易。
APIでGLM-4.7-Flashにアクセスする方法
価格(Novita)
- モデル:
zai-org/glm-4.7-flash - コンテキスト: 200K
- 価格: 入力 $0.07 / 100万トークン、出力 $0.4 / 100万トークン、キャッシュ読み取り $0.01 / 100万トークン
🙌Novitaでは、この価格設定によりGLM-4.7-Flashは本番ワークロードを大規模に実行するためのコスト効率の高い選択肢となります。
ステップ1: ログインしてモデルライブラリにアクセス
Novita AIのダッシュボードにログインし、Model Library / Model APIsセクションを開きます。
ステップ2: モデルを選択
GLM-4.7-Flashを選択し、モデル識別子がzai-org/glm-4.7-flashであることを確認します。
ステップ3: 無料トライアルを開始
(アカウントで利用可能な場合)無料トライアルを開始し、Playgroundで簡単な動作確認を行います。
ステップ4: APIキーを取得
Settingsに移動し、APIキーをコピーします。

OpenAI互換APIの例(Python)
OpenAI SDKを使用し、NovitaのベースURLを設定します。
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
OpenAI Agents SDKでGLM-4.7-Flashにアクセスする方法
OpenAI Agents SDK内でNovita AIモデルを実行することで、マルチエージェントワークフローを構築できます。
- プラグイン互換性: Novita AIはOpenAI互換APIを公開しているため、Agentsワークフローの設計を変更することなく、NovitaがホストするGLMモデルに差し替え可能です。
- エージェントオーケストレーション対応: ハンドオフ、ルーティング、ツール/関数呼び出しを使用して、エージェントがタスクを委任、トリアージ、実行できるようにしつつ、モデル層はNovitaに維持します。
- 簡単なPython設定: SDKを
https://api.novita.ai/openaiに向け、NOVITA_API_KEYを設定し、モデルzai-org/glm-4.7-flashを選択します。
サードパーティプラットフォームでGLM-4.7-Flashにアクセスする方法
GLM-4.7-Flashは、Novitaのサービスと統合することで、サードパーティプラットフォームでも利用できます。
- エージェントフレームワーク&アプリビルダー: Novitaのステップバイステップ統合ガイドに従って、Continue、AnythingLLM、LangChain、Langflow などの人気ツールと接続できます。
- Hugging Face Hub: NovitaはHugging FaceでInference Providerとしてリストされているため、Hugging Faceのプロバイダーワークフローとエコシステムを通じてサポート対象モデルを実行できます。
- OpenAI互換API: NovitaのLLMエンドポイントはOpenAI API標準と互換性があるため、既存のOpenAIスタイルのアプリを簡単に移行でき、多くのOpenAI互換ツール(Cline、Cursor、Trae、Qwen Code)に接続できます。
- Anthropic互換API: NovitaはAnthropic SDK互換のアクセスも提供しており、Novitaバックエンドのモデルを**Claude Code** スタイルのエージェントコーディングワークフローに統合できます。
- OpenCode: Novita AIは**OpenCode** にサポートプロバイダーとして直接統合されているため、ユーザーは手動設定なしでOpenCode内でNovitaを選択できます。
まとめ
GLM-4.7-Flashは、軽量で効率的なモデルでありながら、実世界のタスクでも優れたパフォーマンスを発揮するため、強力な選択肢です。Novita AIのAPIを通じた柔軟なアクセスと幅広い統合オプションにより、コーディング、長いコンテキスト、ツールベースのワークフローを大規模に採用しやすくなっています。
よくある質問
GLM-4.7-Flashのパラメータサイズは?
GLM-4.7-Flashは30B-A3BのMixture-of-Experts(MoE)モデルです(総パラメータ30B、トークンあたりの活性化パラメータ約3B)。
GLM-4.7-Flashをローカル/プライベートデプロイメントで使用できますか?考慮すべき点は?
はい、GLM-4.7-Flashはローカル/プライベートデプロイメントのニーズに適合できます。主な考慮点はハードウェア容量、スループット要件、および200Kコンテキストのワークロードが必要かどうかです。これによりメモリと計算コストが大幅に増加する可能性があります。
GLM-4.7-Flashはいつリリースされましたか?
GLM-4.7-Flashは2026年1月20日に正式にリリースされ、オープンソース化されました。
Novita AI は、AIの野望を実現するためのオールインワンクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の高いツールを提供します。インフラストラクチャの手間を省き、無料で始めて、AIのビジョンを現実にしましょう。



