

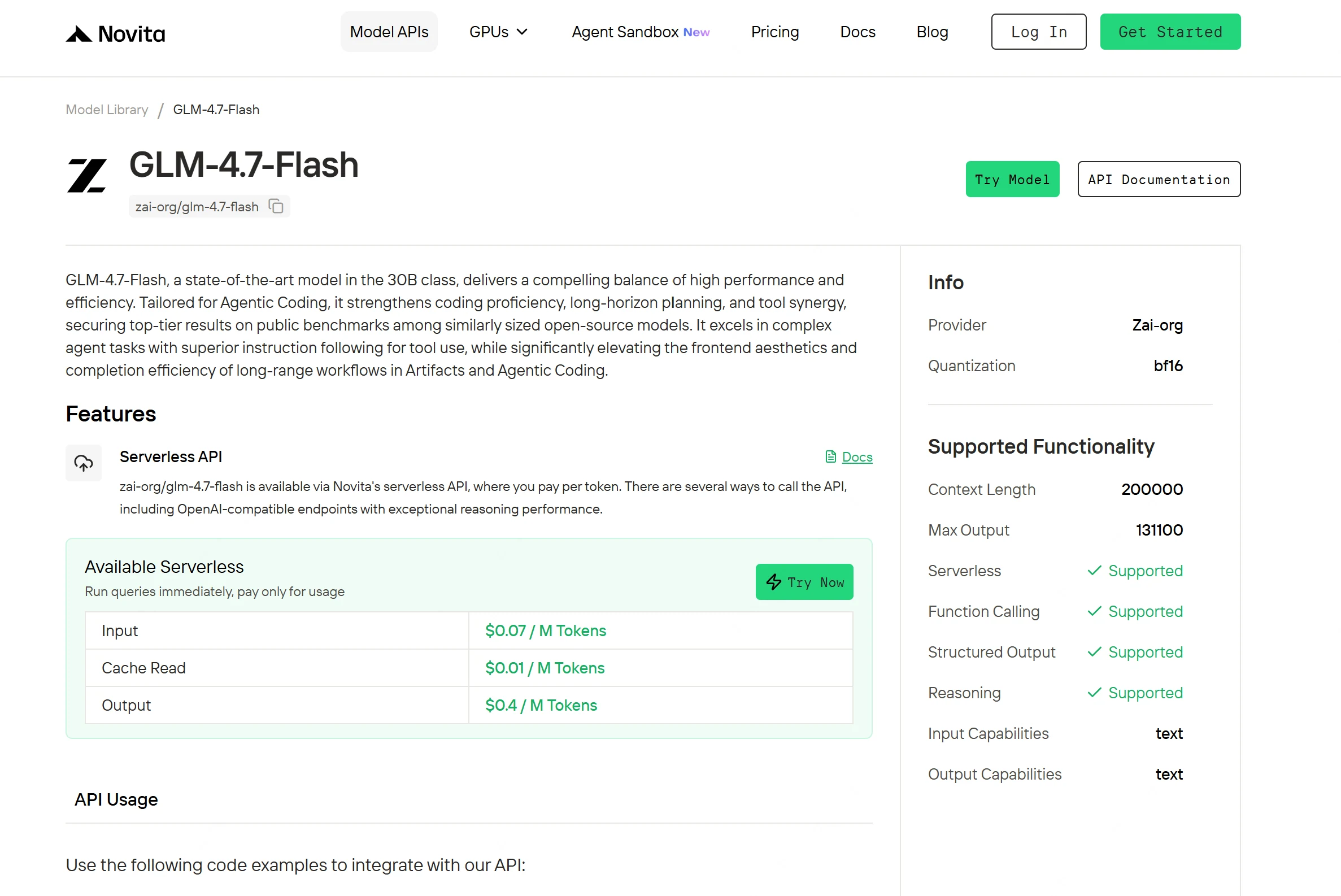
GLM-4.7-Flash es un modelo de la clase 30B que busca un equilibrio práctico entre rendimiento y eficiencia. Utiliza un diseño 30B-A3B MoE y admite contexto de 200K con un alto límite de generación (Novita enumera ~131,100 tokens máximos de salida), lo que lo hace adecuado para documentos largos, bases de código grandes y flujos de trabajo de múltiples pasos. También admite razonamiento, llamadas a funciones y salidas estructuradas, lo que permite un uso más fiable de herramientas y pipelines.
En este artículo, explicaremos su arquitectura, interpretaremos su perfil de benchmarks, describiremos los escenarios más adecuados y mostraremos cómo acceder a él a través de la API de Novita AI.
¿Cuál es la arquitectura de GLM-4.7-Flash?
| Arquitectura / Característica | Qué es | Por qué es importante en la práctica |
| 30B-A3B MoE | Gran capacidad total del modelo mientras activa menos parámetros por token | Mejor equilibrio entre costo, rendimiento y calidad para cargas de trabajo de producción (inferencia más eficiente a escala) |
| Contexto de 200K | Ventana de contexto muy larga para prompts + historial + documentos | Maneja bases de código grandes, PRDs/registros largos, síntesis multidocumento con menos fragmentación y menos saltos de recuperación |
| ~131,100 salida máxima (límite de Novita) | Alto límite de generación listado en la página del modelo de Novita (los límites de la plataforma pueden variar) | Útil para salidas de formato largo: parches multiarchivo, informes detallados, planes estructurados, respuestas JSON grandes |
| Modo de razonamiento | Comportamiento opcional de razonamiento multi-paso más profundo | Mejora la fiabilidad en tareas complejas de varios pasos y planificación a largo plazo |
| Llamadas a funciones | Invocación nativa de herramientas mediante esquemas estructurados de herramientas | Permite una coordinación predecible de herramientas (búsqueda, ejecutores de pruebas, recuperadores, etc.) |
| Salidas estructuradas | Salidas amigables con esquemas | Reduce fallos de análisis y errores de código de unión en pipelines de automatización |
💡En resumen: GLM-4.7-Flash combina un diseño eficiente 30B-A3B MoE con contexto de 200K, gran capacidad de salida y funciones de integración controlables (razonamiento, llamadas a funciones, salidas estructuradas), lo que lo hace práctico para flujos de trabajo largos y pipelines de producción.
Benchmarks de rendimiento de GLM-4.7-Flash
El gráfico evalúa 6 benchmarks que se asignan directamente a codificación agéntica + flujos de trabajo basados en herramientas. A continuación se muestra qué mide cada puntuación y cómo GLM-4.7-Flash (30B-A3B) se compara con Qwen3-30B-A3B-Thinking-2507 y GPT-OSS-20B.
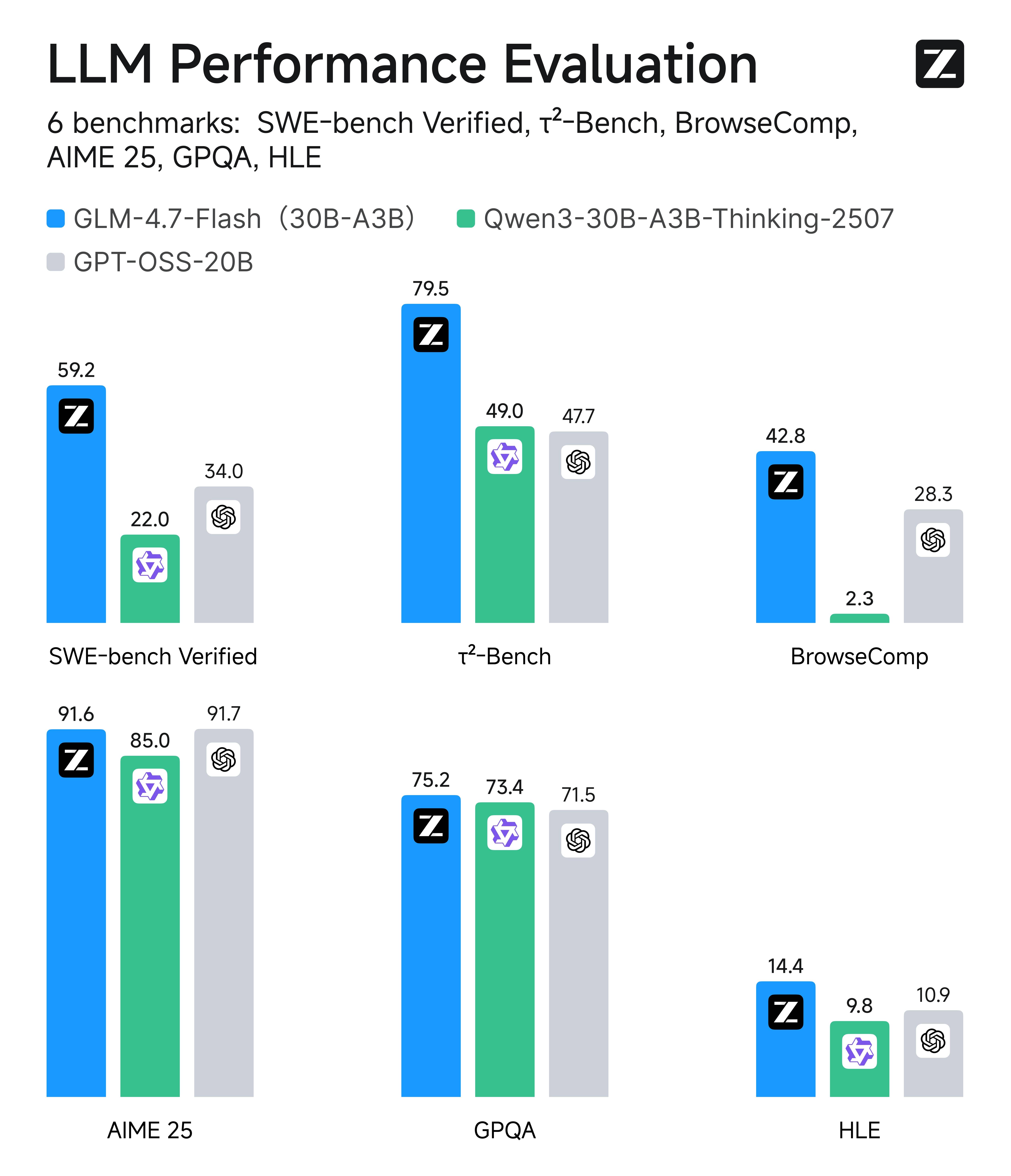
Mapeo de benchmark → capacidad
| Benchmark | Qué mide (capacidad) | GLM-4.7-Flash | Qwen3-30B-A3B | GPT-OSS-20B | Conclusión clave |
| SWE-bench Verified | Corrección de errores en repositorios reales (parche → pruebas pasan) | 59.2 | 22 | 34 | Flash lidera fuertemente → mejores bucles de reparación de codificación agéntica |
| τ²-Bench | Razonamiento multi-paso con herramientas (planificar → llamar herramientas → adaptarse) | 79.5 | 49 | 47.7 | Flash lidera por ~30 pts → mayor estabilidad en orquestación de herramientas |
| BrowseComp | Navegación web y recopilación de información | 42.8 | 2.3 | 28.3 | Flash es el mejor → agentes de navegación y síntesis más fiables |
| AIME 25 | Razonamiento matemático a nivel de competencia | 91.6 | 85 | 91.7 | Flash ≈ GPT-OSS → matemáticas sólidas, no sacrificadas por velocidad |
| GPQA | Razonamiento científico a nivel de posgrado | 75.2 | 73.4 | 71.5 | Flash ligeramente por delante → mejor QA de alta dificultad |
| HLE | Razonamiento lógico complejo / casos límite | 14.4 | 9.8 | 10.9 | Flash lidera → razonamiento robusto más fuerte bajo trampas |
🤖Conclusiones clave
- Fiabilidad en codificación agéntica: Fuerte en la producción de correcciones que pasan las pruebas en repositorios reales (SWE-bench Verified).
- Ejecución estable multi-paso con herramientas: Se desempeña bien en bucles de planificación → llamada a herramientas → iteración (τ²-Bench), lo que lo convierte en una base sólida para agentes aumentados con herramientas.
- Navegación y síntesis robustas: Efectivo en navegación web, recuperación de información y resumen para flujos de trabajo de investigación (BrowseComp).
- Razonamiento central competitivo: Mantiene un rendimiento fuerte en razonamiento matemático/científico/lógico (AIME 25, GPQA, HLE), apoyando decisiones complejas sin sacrificar el diseño enfocado en velocidad.
¿Para qué escenarios es mejor GLM-4.7-Flash?
Implementación local/privada: Un modelo 30B-A3B MoE amigable para el despliegue cuando necesitas inferencia on-prem para privacidad, cumplimiento normativo o latencia predecible, manteniendo al mismo tiempo una capacidad general sólida.
Escala sensible al costo: El precio de Novita más lectura de caché ayuda a reducir el costo unitario para prefijos de prompt repetidos (system prompts, esquemas de herramientas, reglas de enrutamiento), especialmente en aplicaciones de alto rendimiento.
Entrega de código (parche → prueba → iterar): Ideal para bucles de ingeniería prácticos como corrección de errores, refactorizaciones y tareas de reparación orientadas a CI donde te importan los cambios que realmente pasan las pruebas (flujos de trabajo estilo SWE).
Documentos y bases de código de contexto largo: Con contexto de 200K, maneja PRDs grandes, registros largos y síntesis de bases de código multi-archivo sin fragmentación agresiva ni costura de recuperación excesiva.
Pipelines aumentados con herramientas y JSON : Admite llamadas a funciones y salidas estructuradas, facilitando la integración en sistemas de producción que requieren JSON válido según esquema y acciones posteriores deterministas.
Cómo acceder a GLM-4.7-Flash a través de la API
Precios (Novita)
| Modelo | Contexto | Precio |
|---|---|---|
zai-org/glm-4.7-flash |
200K | Input $0.07 / 1M tokens, Output $0.4 / 1M tokens, Cache Read $0.01 / 1M tokens |
🙌En Novita, este precio hace de GLM-4.7-Flash una opción rentable para cargas de trabajo de producción a escala.
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu panel de Novita AI y abre la sección Model Library / Model APIs.
Paso 2: Elige tu modelo
Selecciona GLM-4.7-Flash y confirma el identificador del modelo zai-org/glm-4.7-flash
Paso 3: Inicia tu prueba gratuita
Inicia la prueba gratuita (si está disponible en tu cuenta) y realiza una verificación rápida en Playground:
Paso 4: Obtén tu clave de API
Ve a Settings y copia tu clave de API.

Ejemplo de API compatible con OpenAI (Python)
Utiliza el SDK de OpenAI y configura la URL base de Novita:
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Cómo acceder a GLM-4.7-Flash con el SDK de OpenAI Agents
Crea flujos de trabajo multi-agente ejecutando modelos de Novita AI dentro del SDK de OpenAI Agents:
- Compatibilidad directa: Novita AI expone una API compatible con OpenAI, por lo que puedes intercambiar los modelos GLM alojados en Novita sin cambiar el diseño de tu flujo de trabajo de Agents.
- Orquestación de agentes lista: Usa traspasos, enrutamiento y llamadas a herramientas/funciones para que los agentes deleguen, clasifiquen y ejecuten tareas, manteniendo la capa del modelo en Novita.
- Configuración rápida en Python: Apunta el SDK a
https://api.novita.ai/openai, establece tuNOVITA_API_KEY, luego elige el modelozai-org/glm-4.7-flash
Cómo acceder a GLM-4.7-Flash en plataformas de terceros
GLM-4.7-Flash también se puede usar en plataformas de terceros integrándolas con los servicios de Novita.
- Frameworks de agentes y creadores de aplicaciones: Sigue las guías de integración paso a paso de Novita para conectar con herramientas populares como Continue, AnythingLLM, LangChain y Langflow.
- Hugging Face Hub: Novita aparece como Inference Provider en Hugging Face, por lo que puedes ejecutar modelos compatibles a través del flujo de trabajo de proveedores y el ecosistema de Hugging Face.
- API compatible con OpenAI: Los endpoints LLM de Novita son compatibles con el estándar de la API de OpenAI, lo que facilita la migración de aplicaciones existentes de estilo OpenAI y la conexión de muchas herramientas compatibles con OpenAI (Cline, Cursor , Trae y Qwen Code).
- API compatible con Anthropic: Novita también proporciona acceso compatible con el SDK de Anthropic para que puedas integrar modelos respaldados por Novita en flujos de trabajo de codificación agéntica al estilo de Claude Code.
- OpenCode: Novita AI ahora está integrada directamente en OpenCode como un proveedor compatible, por lo que los usuarios pueden seleccionar Novita en OpenCode sin configuración manual.
Conclusión
GLM-4.7-Flash es una excelente opción cuando necesitas un modelo ligero y eficiente que aún así rinda bien en tareas del mundo real. Con acceso flexible a través de la API de Novita AI y amplias opciones de integración, es fácil de adoptar para flujos de trabajo de codificación, contexto largo y basados en herramientas a escala.
Preguntas frecuentes
¿Cuál es el tamaño de parámetros de GLM-4.7-Flash?
GLM-4.7-Flash es un modelo Mixture-of-Experts (MoE) 30B-A3B (30B parámetros totales, ~3B activados por token).
¿Puedo usar GLM-4.7-Flash para implementación local/privada? ¿Qué debo considerar?
Sí, GLM-4.7-Flash puede satisfacer las necesidades de implementación local/privada. Las consideraciones clave son la capacidad del hardware, los requisitos de rendimiento y si necesitas cargas de trabajo de contexto de 200K, lo que puede aumentar significativamente los costos de memoria y cómputo.
¿Cuándo se lanzó GLM-4.7-Flash?
GLM-4.7-Flash se lanzó oficialmente y se abrió su código el 20 de enero de 2026.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, serverless, instancias de GPU — las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



