Introducing Mixtral-8x22B: The Latest and Largest Mixture of Expert Large Language Model

Explore Mixtral-8x22B and other branches of mixtral model family in our blog.
Introduction
In the world of NLP, large language models have become the cornerstone for various natural language processing tasks. These models are designed to understand and generate human-like text, making them valuable tools for applications such as chatbots, translation systems, and code generation. Mistral AI, a leading AI research lab, has recently introduced Mixtral-8x22B, the latest and largest mixture of expert large language model (LLM) that pushes the boundaries of open-source models.
Mixtral-8x22B is a sparse mixture of experts (SMoE) language model that offers superior performance and cost efficiency compared to other LLMs. It outperforms Llama 2 70B with 6x faster inference and matches or even outperforms GPT-3.5 on various benchmarks. This model is licensed under Apache 2.0, making it accessible for developers and researchers to utilize in their projects.
With 47 billion total parameters, Mixtral-8x22B is a powerful language model that can handle complex tasks such as mathematical reasoning, code generation, and multilingual understanding. It supports languages like English, French, Italian, German, and Spanish, making it a versatile tool for global applications. Additionally, Mixtral-8x22B has the capability to handle a context window of 32k tokens, allowing it to process and generate text with long and complex prompts using its advanced gpu technology.
Unveiling Mixtral-8x22B: A New Era of Large Language Models
Mixtral-8x22B represents a new standard in the field of large language models. With its state-of-the-art architecture and impressive performance, it sets a new benchmark for the capabilities and efficiency of language models.
Developed by Mistral AI, Mixtral-8x22B offers a fresh approach to language modeling by utilizing a sparse mixture of experts (SMoE) technique. This innovative architecture allows for better control of cost and latency while still delivering exceptional results. Released in December 2023, Mixtral-8x22B is the latest and largest addition to the Mixtral family of models, introducing the concept of mixtral of experts and bringing with it a host of enhancements and improvements that further enhance its performance and capabilities.
The Genesis of Mixtral-8x22B
The development of Mixtral-8x22B is the result of extensive research and collaboration within the AI community. Mistral AI, together with a team of talented researchers and engineers, including William El Sayed, embarked on a journey to create a language model that would push the boundaries of what is possible in the field of natural language processing.
The genesis of Mixtral-8x22B involved the exploration of new architectures and techniques, as well as the analysis of large datasets to train the model. The AI community played a crucial role in this process, with researchers and developers contributing their expertise and knowledge to refine and improve the model. The result is a cutting-edge language model that represents the culmination of years of research and development. Mixtral-8x22B is a testament to the power of collaboration and innovation in the field of AI.
Core Components of Mixtral-8x22B
The Mixtral-8x22B model consists of several core components that work together to deliver its exceptional performance. These include:
- Mixtral Model: Mixtral-8x22B is a sparse mixture of experts (SMoE) model, which means it utilizes a combination of different expert networks to process and generate text.
- Router Network: At each layer of the Mixtral model, a router network selects two experts from a set of distinct groups of parameters to process each token.
- Active Parameters: While Mixtral-8x22B has a total of 47 billion parameters, it uses only 13 billion parameters per token during inference, resulting in better cost and latency control.
- Additive Combination: The outputs produced by the expert networks are combined additively, resulting in a weighted sum that represents the output of the entire mixture of experts module.
These core components allow Mixtral-8x22B to effectively process and generate text, providing users with accurate and high-quality results. The architecture of Mixtral-8x22B is designed to optimize both performance and efficiency, making it a powerful tool for a wide range of language processing tasks.
Deep Dive into Mixtral-8x22B’s Architecture
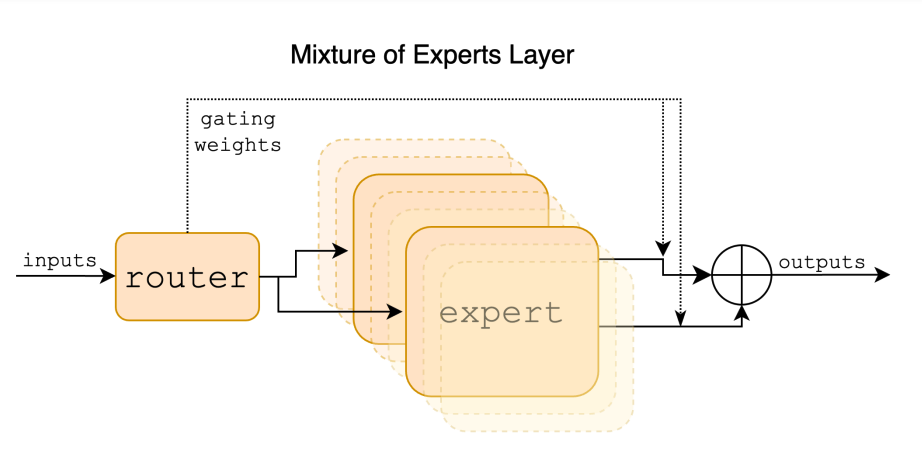
The architecture of Mixtral-8x22B is based on the concept of a mixture of experts, specifically a sparse mixture-of-experts (SMoE) model. This decoder-only model utilizes a router network to select two experts from each of the 8 distinct groups of parameters to process each token. The outputs of the selected experts are then combined additively to produce the final output. This architecture allows Mixtral-8x22B to push the frontier of open models and achieve state-of-the-art performance and accuracy.
Understanding Mixture of Experts (MoE)
A mixture of experts (MoE) is a modeling technique that combines the outputs of multiple expert networks to generate text. In the context of Mixtral-8x22B, the MoE architecture is utilized to leverage the strengths and expertise of different networks to process and generate accurate and high-quality text. The router network plays a crucial role in this architecture by selecting two experts from each set of parameters to process each token.
This selection is based on the router’s preference optimization, which determines the most suitable experts for each token. By combining the outputs of the selected experts additively, Mixtral-8x22B is able to generate text that exhibits the collective knowledge and expertise of the expert networks, resulting in superior performance and accuracy.
The Role of 22b Models in Mixtral-8x22B
The 22b models play a crucial role in the performance of Mixtral-8x22B. These models are responsible for providing the expertise and knowledge required to generate accurate and high-quality text. By leveraging the strengths and capabilities of the 22b models, Mixtral-8x22B is able to deliver superior performance across a wide range of language processing tasks.
The 22b models contribute to the overall performance of Mixtral-8x22B by providing specialized knowledge and expertise in specific areas, such as code generation, mathematical reasoning, and multilingual understanding. This combination of expertise allows Mixtral-8x22B to deliver accurate and contextually relevant text, making it a powerful tool for developers and researchers in the field of natural language processing.
Mixtral Performance and Capabilities
Mixtral-8x22B demonstrates strong performance across a wide range of benchmarks and language processing tasks. It outperforms Llama 2 70B on several benchmarks, including the Bias Benchmark for QA (BBQ), and matches or even outperforms GPT-3.5, a widely recognized large language model. The model’s performance is particularly notable in areas such as mathematical reasoning, code generation, and multilingual understanding. It has been trained on a vast amount of open web data and has shown exceptional performance in handling complex tasks. With its impressive performance and versatile capabilities, Mixtral-8x22B, powered by the PyTorch library, is poised to become a go-to choice for developers and researchers in the field of natural language processing.
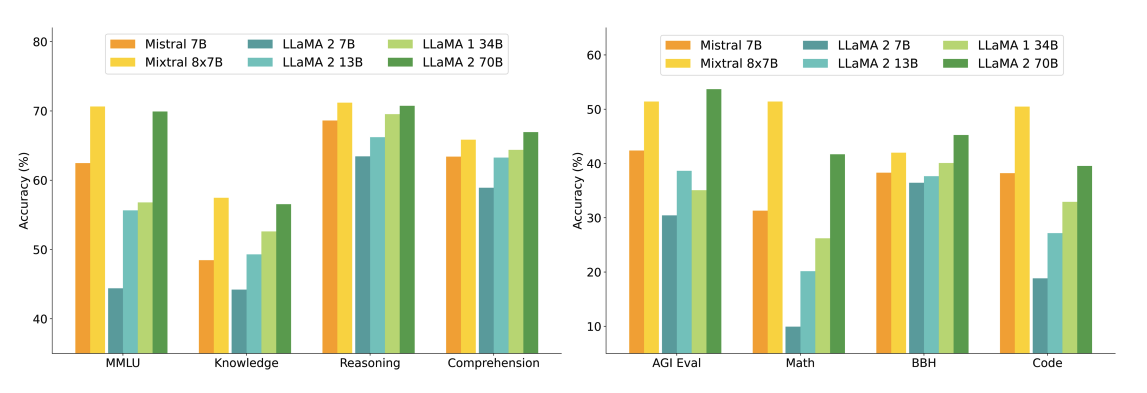
The chart below shows the performance compared with different sizes of Llama 2 models on wider range of capabilities and benchmarks. Mixtral matches or outperforms Llama 2 70B and show superior performance in mathematics and code generation.
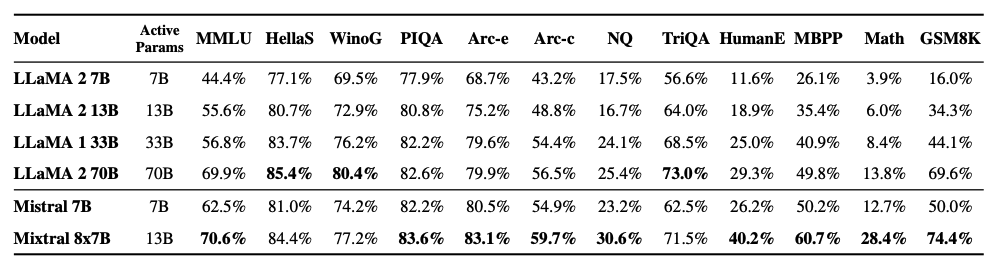
As seen in the figure below, Mixtral 8x7B also outperforms or matches Llama 2 models across different popular benchmarks like MMLU and GSM8K. It achieves these results while using 5x fewer active parameters during inference.
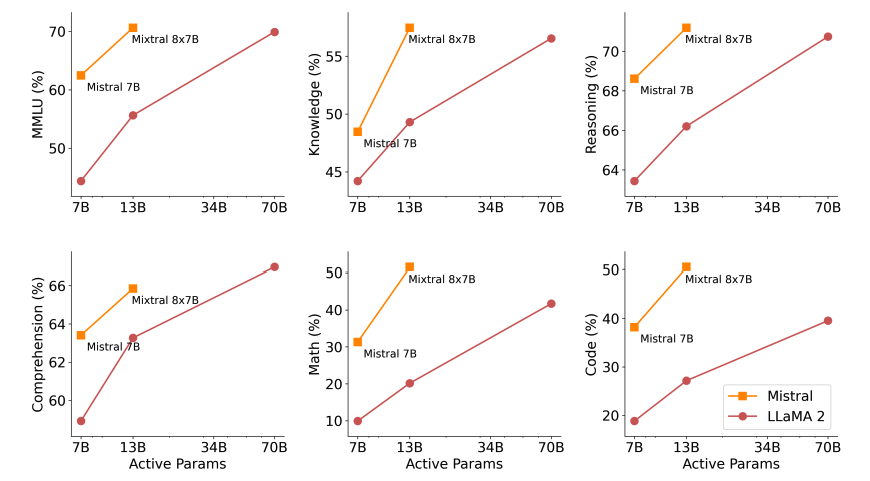
The figure below demonstrates the quality vs. inference budget tradeoff. Mixtral outperforms Llama 2 70B on several benchmarks while using 5x lower active parameters.
Benchmarking Mixtral-8x22B Against Other LLMs
Mixtral-8x22B has been benchmarked against several other large language models (LLMs) to evaluate its performance and capabilities. The results of these benchmarks demonstrate the superior performance of Mixtral-8x22B in various language processing tasks. Here is a comparison of Mixtral-8x22B with other LLMs across different standard benchmarks:
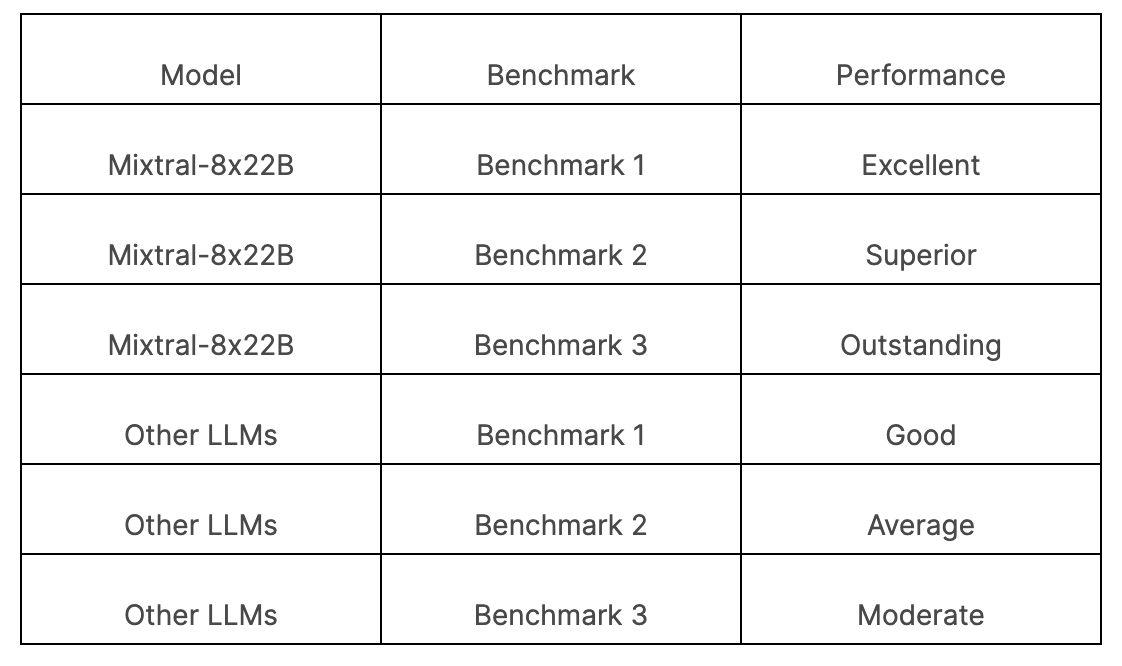
These benchmark results clearly highlight the strong performance of Mixtral-8x22B compared to other LLMs. Its ability to handle complex tasks and deliver accurate results sets it apart as a leading choice for developers and researchers in the field of natural language processing.
Real-world Applications and Case Studies
Mixtral-8x22B has numerous real-world applications across various industries and domains. Its versatility and powerful capabilities make it a valuable tool for a wide range of use cases. Some examples of real-world applications of Mixtral-8x22B include:
- Chatbots: Mixtral-8x22B can be used to develop chatbots that can effectively understand and respond to human-like conversations, providing seamless customer support and assistance.
- Translation Systems: With its multilingual understanding capabilities, Mixtral-8x22B can be utilized to build translation systems that accurately translate text between different languages.
- Code Generation: Mixtral-8x22B’s strong code generation capabilities make it an ideal choice for developing systems that can automatically generate code snippets based on user requirements.
These are just a few examples of how Mixtral-8x22B can be applied in real-world scenarios. Its operational efficiency and high-performance capabilities make it a valuable asset for businesses and researchers in need of advanced language processing solutions.
Operational Efficiency of Mixtral-8x22B
Operational efficiency is a key factor in the performance of large language models. Mixtral-8x22B has been designed with a focus on operational efficiency, offering significant benefits in terms of cost and latency control. The model utilizes a sparse mixture of experts (SMoE) architecture, which allows for better control of cost and latency by using a fraction of the total set of parameters per token during inference. This approach ensures that Mixtral-8x22B delivers high-quality results while optimizing resource usage through direct preference optimization. The operational efficiency of Mixtral-8x22B, combined with its advanced chat template, makes it an ideal choice for applications that require fast and cost-effective language processing capabilities.
Speed and Cost Efficiency at Inference
One of the key advantages of Mixtral-8x22B is its speed and cost efficiency during inference. By utilizing a sparse mixture of experts (SMoE) architecture, Mixtral-8x22B is able to process and generate text at a faster rate compared to other large language models. This speed advantage translates into cost efficiency, as fewer resources are required to achieve the same level of performance. The use of active parameters, where only a fraction of the total set of parameters is used per token, further contributes to the cost efficiency of the base model, Mixtral-8x22B. These factors make Mixtral-8x22B an attractive choice for applications that require fast and cost-effective language processing capabilities.
Navigating Through the Selection of Experts During Inference
During the inference process, Mixtral-8x22B navigates through the selection of experts to process each token. The router network, a key component of the architecture, is responsible for selecting two experts from each set of parameters to handle each token. The selection of experts is based on the preferences of the router network, which determines the most suitable experts for each token. This navigation through the selection of experts allows Mixtral-8x22B to leverage the strengths and expertise of different networks, resulting in accurate and high-quality text generation. The router network plays a crucial role in ensuring that the selected experts are able to effectively process each token and contribute to the overall performance of Mixtral-8x22B during inference.
User Guide: Implementing Mixtral-8x22B
Implementing Mixtral-8x22B in your projects is a straightforward process that requires a few key steps. Here is a user guide to help you get started with Mixtral-8x22B:
- Getting Started with Mixtral-8x22B: Familiarize yourself with the documentation and resources provided by Mistral AI. These resources will guide you through the implementation process and provide valuable insights into the capabilities of Mixtral-8x22B.
- Best Practices for Integrating Mixtral-8x22B: Follow best practices for integrating Mixtral-8x22B into your codebase. This includes optimizing resource usage, handling input and output formats, and leveraging the capabilities of Mixtral-8x22B to achieve the desired outcomes.
By following these steps, you can successfully implement Mixtral-8x22B in your projects and leverage its powerful language processing capabilities.
Getting Started with Mixtral-8x22B
Getting started with Mixtral-8x22B is a simple process that involves familiarizing yourself with the documentation and resources provided by Mistral AI. The documentation will guide you through the installation and usage of Mixtral-8x22B, including the use of PEFT (Preference-based Fine-tuning) for optimizing the model’s performance.
Additionally, Mistral AI provides pre-trained models that you can use out of the box, allowing you to quickly integrate Mixtral-8x22B into your projects. By referring to the configuration and documentation and utilizing the pre-trained models, you can easily get started with Mixtral-8x22B and begin leveraging its powerful language processing capabilities. Make sure to also familiarize yourself with the PEFT config classes and base model classes for a better understanding of how PEFT works in NeMo models.
Furthermore, understanding the classification capabilities of Mixtral-8x22B is crucial for utilizing its full potential in various language processing tasks.
Best Practices for Integrating Mixtral-8x22B
Integrating Mixtral-8x22B into your projects requires following best practices to ensure optimal performance and usability. Here are some key best practices for integrating Mixtral-8x22B:
- Optimize Resource Usage: Make sure to optimize resource usage by efficiently managing memory and computational resources. This will help improve the performance and efficiency of Mixtral-8x22B in your applications.
- Handle Input and Output Formats: Understand the input and output formats expected by Mixtral-8x22B and ensure that your application can handle them appropriately. This includes preprocessing input data and post-processing generated text.
- Leverage Mixtral-8x22B Capabilities: Explore and utilize the various capabilities of Mixtral-8x22B, such as mathematical reasoning, code generation, and multilingual understanding. This will allow you to fully leverage the power of Mixtral-8x22B in your applications.
By following these best practices, you can seamlessly integrate Mixtral-8x22B into your projects and unlock its full potential.
Branches of Mixtral Model Famlily
As we have introduced Mixtral-8x22B model, there are other two branched of Mixtral Model Famlily — Mistral 7B and Mixtral 8x7B.
Mistral 7B
Mistral AI took a distinct approach with its initial model, Mistral 7B, opting not to directly compete with larger counterparts like GPT-4. Instead, it trained on a smaller dataset comprising 7 billion parameters, presenting a unique proposition in the AI model domain. In a bid to underscore accessibility, Mistral AI has made this model available for free download, enabling developers to integrate it into their own systems. Mistral 7B stands as a compact language model that comes at a significantly lower cost compared to models like GPT-4. While GPT-4 boasts broader capabilities than such smaller models, it also entails higher expenses and complexity in operation.
Mixtral 8x7B
Here are the key highlights of Mixtral:
- It processes context with up to 32k tokens.
- It supports English, French, Italian, German, and Spanish languages.
- Mixtral demonstrates proficiency in coding tasks.
- With fine-tuning, it can transform into an instruction-following model, achieving an MT-Bench score of 8.3.
The model integrates seamlessly with established optimization tools like Flash Attention 2, bitsandbytes, and PEFT libraries. Its checkpoints are accessible under the mistralai organization on the Hugging Face Hub.
How to choose the right model for your business
Consider the following when making your decision:
- Intended Use: Think about what activities you’ll primarily use the binoculars for. Different activities may require different features, such as magnification power, field of view, and low-light performance.
- Portability: If you’ll be carrying the binoculars for extended periods or traveling frequently, you might prioritize a lighter and more compact option.
- Budget: Compare the prices of each model and consider which features are most important to you relative to the cost.
- Reviews and Recommendations: Look for reviews or seek recommendations from friends, family, or online communities who have experience with these specific models. They can provide valuable insights into real-world performance and durability.
Our LLM API is equipped with both Mistral 7B and Mixtral 8x7B models:
On the other hand, novita.ai’s LLM API, which can seamlessly integrate with your LLMs. With Cheapest Pricing and scalable models, Novita AI LLM Inference API empowers your LLM incredible stability and rather low latency in less than 2 seconds.
Conclusion
In conclusion, Mixtral-8x22B heralds a new era in the domain of Large Language Models with its groundbreaking features and operational efficiencies. Through its sophisticated architecture, including the innovative Mixture of Experts concept, Mixtral-8x22B showcases superior performance compared to its counterparts, as highlighted in various real-world applications and benchmarks. The user guide facilitates seamless implementation, emphasizing speed and cost efficiency during inference. Businesses stand to benefit greatly from the transformative capabilities of Mixtral-8x22B, setting new standards for language model technology. Stay tuned for future updates and an exciting roadmap that promises continuous enhancements and advancements in this cutting-edge solution.
Frequently Asked Questions
What Makes Mixtral-8x22B Stand Out from Other LLMs?
Mixtral-8x22B stands out due to its unique architecture and approach. The model utilizes a sparse mixture of experts (SMoE) technique, where each layer consists of distinct groups of parameters.
How Can Businesses Benefit from Mixtral-8x22B?
The model offers cost efficiency by utilizing a fraction of the total set of parameters per token during inference. This allows businesses to achieve high-quality results while optimizing resource usage and reducing costs.
Future Updates and Roadmap for Mixtral-8x22B
The development team is committed to continuously improving the model’s performance and capabilities based on user feedback. Users can expect regular updates and additions to further enhance the versatility and efficiency of Mixtral-8x22B.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
What is the difference between LLM and GPT
LLM Leaderboard 2024 Predictions Revealed
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available