Introducing Llama 2: All Worthwhile After Llama 3 Released

Introduction
Llama 3 has been crashing the party ever since its release from MetaAI. But it does not mean that we should replace Llama 2 with the newest generation of Llama model.
Released by Meta AI in 2023, Llama 2 offers a range of pre-trained and fine-tuned models that are capable of various natural language processing (NLP) tasks. Unlike its predecessor, LLaMa 1, Llama 2 is available free of charge for both AI research and commercial use, making it more accessible to a wider range of organizations and individuals. With comprehensive integration in Hugging Face, Llama 2 Chat models are set to revolutionize the way we approach NLP tasks.
What is LlaMA 2?

LlaMA 2, the successor to LlaMA version 1 released by Meta in July 2023, outshines its predecessor in several aspects. It introduces three different sizes: 7B, 13B, and 70B parameter models. Upon its debut, LlaMA 2 quickly rose to the top spot on Hugging Face, surpassing all other models across all segments. This achievement is notable considering its superior performance even when compared to LlaMA version 1.
LlaMA 2 was trained on an extensive dataset of 2 trillion pretraining tokens, doubling the context length of LlaMA 1 to 4k. Its superiority extends beyond just Hugging Face, outperforming other state-of-the-art open-source models like Falcon and MPT in various benchmarks such as MMLU, TriviaQA, Natural Question, and HumanEval. Detailed benchmark scores can be found on Meta AI’s website.
Additionally, LlaMA 2 underwent fine-tuning specifically for chat-related applications, incorporating feedback from over 1 million human annotations. These chat models are now readily accessible on the Hugging Face website for use.
Why Llama 2 Remains Relevant
Llama 2 remains relevant because it offers advancements in context length, accessibility, and training techniques. These improvements make Llama 2 a valuable resource for AI researchers, developers, and businesses in need of powerful language generation capabilities.
Understanding the Core Technology Behind Llama 2
To fully grasp the capabilities of Llama 2, it is essential to understand its core technology and architecture. Llama 2 is a family of transformer-based autoregressive causal language models. These models take a sequence of words as input and predict the next word(s) based on self-supervised learning. The models are pre-trained with a massive corpus of unlabeled data, allowing them to learn linguistic and logical patterns and replicate them in their predictions. Llama 2 has achieved key innovations in training techniques, such as reinforcement learning from human feedback, which helps align model responses with human expectations. These innovations contribute to the improved performance and versatility of Llama 2 in various NLP tasks.
The Architecture of Llama 2
The architecture of Llama 2 is based on transformer-based autoregressive causal language models. These models consist of multiple layers of self-attention and feed-forward neural networks. Llama 2 models are designed to predict the next word(s) in a sequence based on the input provided.
In terms of parameters, Llama 2 models offer a choice of seven billion (7B), 13 billion (13B), or 70 billion (70B) parameters. These parameter counts determine the complexity and capacity of the models. While larger parameter counts may result in higher performance, smaller parameter counts make Llama 2 more accessible to smaller organizations and researchers.
Key Innovations in Llama 2
Llama 2 has introduced several key innovations in the field of large language models. These innovations have been detailed in the Llama 2 research paper, which has been well-received by the AI community.
One of the key innovations is the use of reinforcement learning from human feedback (RLHF) to fine-tune the models. This helps align the model responses with human expectations, resulting in more coherent and accurate language generation.
Furthermore, Llama 2 has focused on advancing the performance capabilities of smaller models rather than increasing parameter count. This approach makes Llama 2 more accessible to smaller organizations and researchers who may not have access to the computational resources required for larger models.
Practical Applications of Llama 2
Llama 2 has practical applications across various industries and domains. Its versatile language generation capabilities make it a valuable tool for developers, researchers, and businesses. Some of the practical applications of Llama 2 include:
- Text generation: Llama 2 can be used to generate natural language text for content creation, chatbots, virtual assistants, and more.
- Code generation: Llama 2 can generate programming code for various languages, aiding developers in their coding tasks.
- Creative writing: Llama 2 can assist with creative writing, generating stories, poems, and other forms of creative content.

Compared with Llama 3 models of novita.ai LLM API, Llama 2 has larger datasets and is more cost-effective.
With Llama 2 models, you can easily perform such tasks in the image below:
How to Get Started with Llama 2
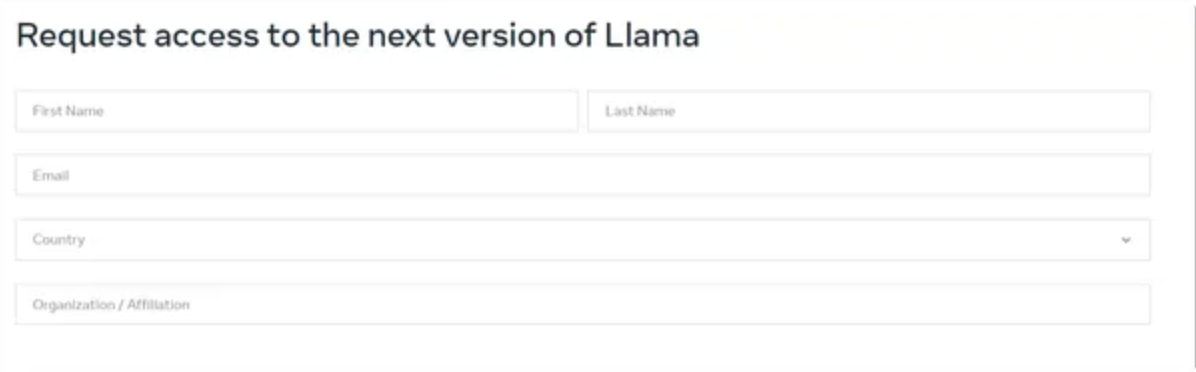
You can access the source code for LlaMA 2 on GitHub. If you wish to utilize the original weights, they are also accessible, but you’ll need to provide your name and email address on Meta AI’s website. To do so, click on the provided link, enter your name, email address, and organization (select “student” if applicable). After filling out the form, scroll down and click on “accept and continue.” Following this, you’ll receive an email confirming your submission and providing instructions on how to download the model weights. The form will resemble the example below.
Now, there are two methods to utilize the model. The first involves directly downloading the model through the instructions and link provided in the email. However, this method may be challenging if you lack a decent GPU. Alternatively, you can use Hugging Face and Google Colab, which is simpler and accessible to anyone.
To begin, you’ll need to set up a Hugging Face account and create an Inference API. Then, navigate to the LlaMA 2 model on Hugging Face by clicking on the provided link. Next, provide the email you used on the Meta AI website. Once authenticated, you’ll be presented with something akin to the example below.
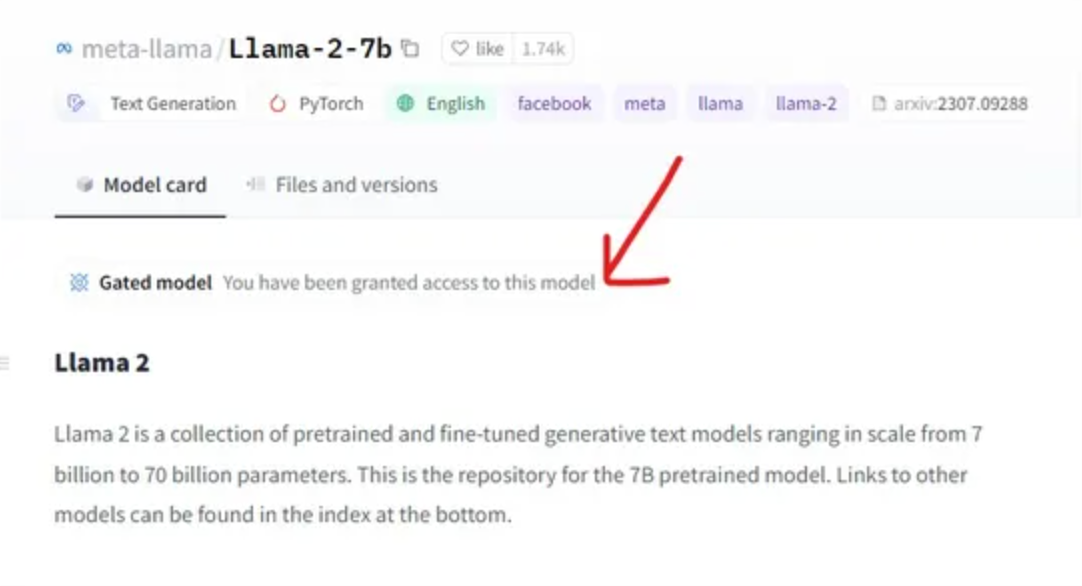
Now, we can download any Llama 2 model through Hugging Face and start working with it.
Using LlaMA 2 with Hugging Face and Colab
In the preceding section, we covered the prerequisites before experimenting with the LlaMA 2 model. Now, let’s initiate by importing the necessary libraries in Google Colab, which can be achieved using the pip command.
!pip install -q transformers einops accelerate langchain bitsandbytes
To begin working with LlaMA 2, we need to install several essential packages. These include the transformers library from Hugging Face, which facilitates model downloading. Additionally, we require the einops function, which streamlines matrix multiplications within the model by leveraging Einstein Operations/Summation notation. This function optimizes bits and bytes to enhance inference speed. Finally, we’ll utilize langchain to integrate our LlaMA model.
To access Hugging Face through Colab using the Hugging Face API Key and download the LlaMA model, follow these steps.
!huggingface-cli login
After entering the Hugging Face Inference API key we previously generated, if prompted with “Add token as git credential? (Y/n)”, simply respond with “n”. This action will authenticate us with the Hugging Face API Key, enabling us to proceed with downloading the model.
There is a more straightforward way to integrate Llama 2 with your existing system — Applying novita.ai’s LLM API, which is reliable, cost-effecvtive and privacy-ensured.
Optimizing Your Use of Llama 2
Optimizing your use of Llama 2 involves following best practices and addressing any potential issues or challenges that may arise. Here are some tips to optimize your use of Llama 2:
- Understand the limitations: Familiarize yourself with the limitations and constraints of the Llama 2 models. This will help you set realistic expectations and avoid potential pitfalls.
- Experiment with hyperparameters: Fine-tune the model by experimenting with different hyperparameters, such as learning rates and batch sizes. This can lead to improved performance and generation quality.
- Regularly update and retrain the model: Stay up to date with the latest model updates and improvements. Periodically retrain the model on new data to ensure optimal performance.
- Monitor and address biases: Be mindful of potential biases present in the training data and generated output. Regularly evaluate and address any biases to ensure fair and unbiased language generation.
Best Practices for Efficient Use of Llama 2
When maximizing the efficiency of Llama 2, it’s essential to streamline workflow by optimizing model weights and parameters. Utilize the preferred Python or PyTorch framework, manage context length judiciously, and ensure responsible use based on guidelines from Facebook. Regularly update the model, leveraging human feedback for enhancements. Consider cloud services like Microsoft Azure for scalable performance. Implement stringent data use policies and follow best practices for secure deployment and maintenance, including reporting any issues with the model to github.com/facebookresearch/llama. These practices foster optimal performance and longevity for Llama 2.
Troubleshooting Common Issues with Llama 2
One common issue encountered with Llama 2 is related to model weights convergence during training. This could be due to insufficient data for the specific task or training for too few epochs. Another issue is the model failing to generalize well to new data, indicating potential overfitting. In such cases, fine-tuning the model with additional diverse data or adjusting hyperparameters like learning rate can often resolve these challenges. Regularly monitoring training progress and experimenting with different configurations are key steps in troubleshooting llama 2.
The Future of Llama 2 Post Llama 3 Release
With the release of Llama 3, the future of Llama 2 remains bright and promising. Meta AI is committed to the continued development and support of Llama 2, ensuring that it remains a valuable resource for the AI community. As the AI landscape continues to evolve, Llama 2 will adapt and incorporate new advancements in generative AI and reinforcement learning. The open foundation of Llama 2 allows for collaboration and innovation, making it an essential tool for researchers, developers, and organizations alike.
Continued Development and Support for Llama 2
By actively engaging with the user community and incorporating feedback, Meta AI can address any issues or challenges that may arise. Additionally, Meta AI is committed to providing resources and documentation to assist users in effectively utilizing Llama 2. The open-source nature of Llama 2 encourages collaboration and innovation, allowing researchers and developers to contribute to its ongoing improvement. With Meta AI’s dedication to the continued development and support of Llama 2, users can expect a robust and evolving platform for their AI needs.
How Llama 2 Fits into the Evolving AI Landscape
Llama 2 plays a crucial role in the constantly evolving AI landscape by providing a powerful and accessible tool for natural language processing tasks. With its generative AI capabilities and reinforcement learning, Llama 2 enables developers to create more human-like and contextually aware applications.
Furthermore, Llama 2’s open approach to AI fosters transparency, collaboration, and responsible development. In an era where AI technologies are rapidly advancing, Llama 2 offers a foundation for innovation and exploration. By leveraging Llama 2’s capabilities, developers can stay at the forefront of the AI landscape and harness the full potential of generative AI and reinforcement learning. [INST] Llama 2 is an essential tool for developers looking to create more human-like and contextually aware AI applications. Its open approach to AI fosters transparency and collaboration, making it a valuable asset in the constantly evolving AI landscape.
Conclusion
In conclusion, Llama 2 continues to hold its own even after the release of Llama 3, boasting unique advantages and practical applications. Getting started with Llama 2 involves setting up your environment and optimizing its use with best practices. As the future of Llama 2 unfolds post Llama 3, continued development and support ensure its alignment with the evolving AI landscape. Explore the FAQs to understand how Llama 2 competes with Llama 3 and how migration between the two is facilitated.
Frequently Asked Questions
Can Llama 2 Still Compete with Llama 3?
Yes, Llama 2 continues to be a valuable resource for AI research and commercial use. While Llama 3 offers new advancements, Llama 2 remains a powerful tool with its diverse models and open foundation.
What Are the Main Reasons to Choose Llama 2 Over Llama 3?
Llama 2 offers several advantages, including greater accessibility, and more cost-effective.
How to Migrate from Llama 2 to Llama 3 if Needed?
To migrate from Llama 2 to Llama 3, users can refer to the user guide provided by Meta AI. The guide outlines the upgrade path and provides detailed instructions for migrating model weights and adapting code.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
What is the difference between LLM and GPT
LLM Leaderboard 2024 Predictions Revealed
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available