

Créer des applications IA prêtes pour la production nécessite bien plus que de simples modèles puissants : il vous faut une infrastructure d’inférence fiable et économique, qui s’adapte à vos besoins et offre des performances constantes.
Choisir le bon fournisseur d’inférence IA est essentiel pour optimiser la latence, maîtriser les coûts et garantir que vos applications peuvent gérer efficacement des charges de travail réelles en production.
Avec la récente percée de DeepSeek R1 (sortie le 28 mai 2025), qui démontre des capacités de raisonnement exceptionnelles, le paysage de l’inférence IA est devenu plus compétitif que jamais. Dans ce guide complet, nous comparerons les 10 principaux fournisseurs d’inférence IA en 2025 pour vous aider à prendre la décision la plus éclairée en fonction de votre cas d’usage et de vos besoins spécifiques.
Comparaison rapide des performances
Pour évaluer les performances des fournisseurs, nous analyserons les coûts, le débit et la latence en utilisant DeepSeek R1 (sortie le 28 mai 2025) comme modèle de référence. Voici comment se comparent les principaux fournisseurs :
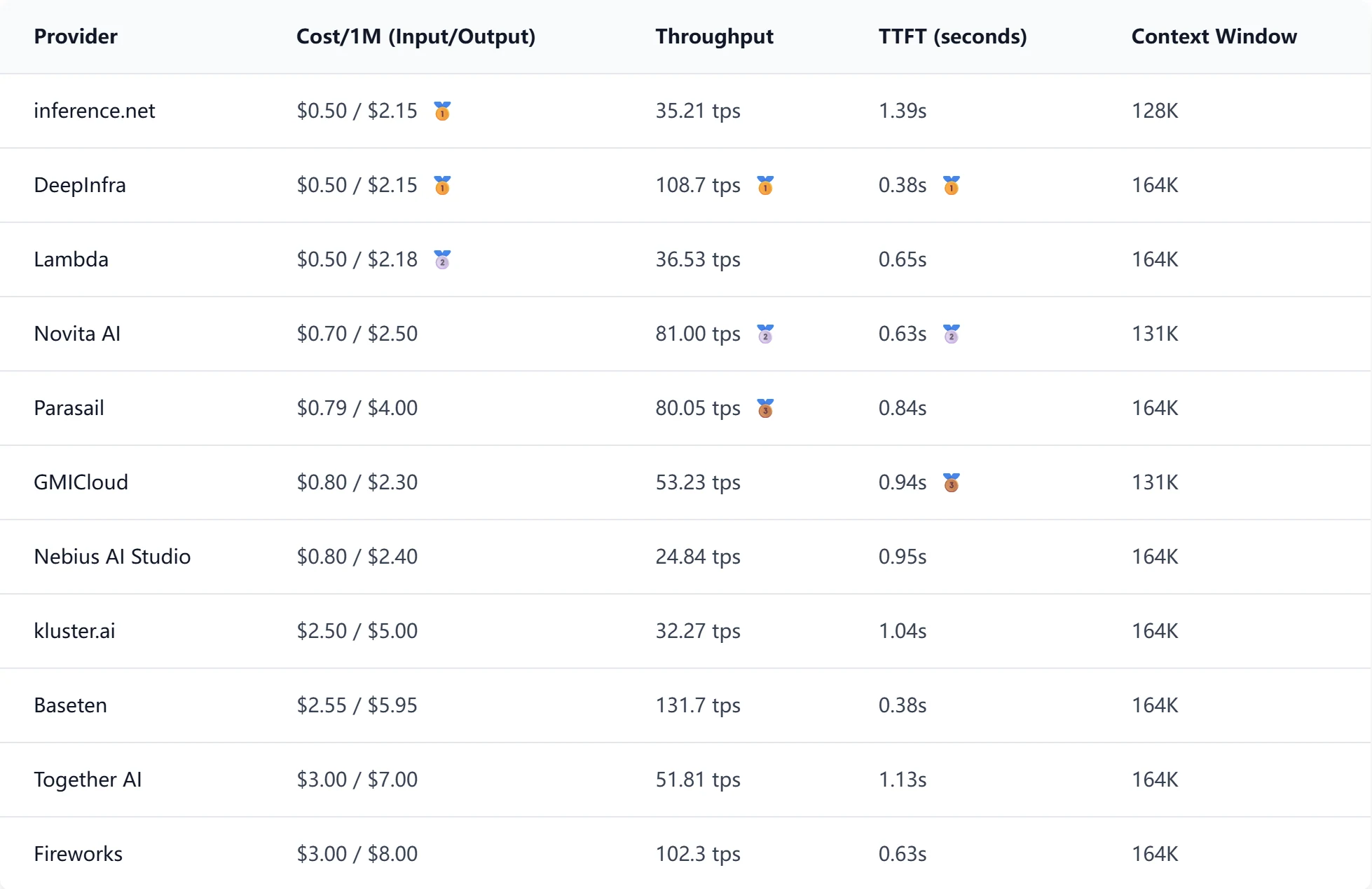
Source : Openrouter
💡 Note rapide sur cette comparaison :
Les métriques de performance sont basées sur l’inférence de DeepSeek R1 (sortie le 28 mai 2025) dans des conditions de test standardisées. Certains fournisseurs peuvent proposer des variantes optimisées ou des versions de modèle différentes qui pourraient affecter ces métriques.
Novita AI est un fournisseur d’inférence IA de premier plan qui offre un déploiement de modèles haute performance via des API simples, combinant des prix compétitifs avec une fiabilité de niveau entreprise. Alors que les organisations recherchent de plus en plus des solutions d’inférence IA efficaces, Novita AI se distingue par son équilibre optimal entre rentabilité, écosystème de modèles varié et intégration conviviale pour les développeurs.
Commencez un essai gratuit sur Novita AI dès aujourd’hui pour profiter des meilleurs fournisseurs d’inférence IA.
1. Novita AI
Meilleur pour : Inférence distribuée mondialement avec mise à l’échelle automatique intelligente et efficacité des coûts
Qu’est-ce que Novita AI ?
Novita AI est une plateforme d’infrastructure cloud qui expose des API de modèles pour divers modèles d’IA et propose également des ressources GPU dédiées pour des déploiements personnalisés. Un réseau GPU multi-régions maintient une faible latence pour les utilisateurs du monde entier et prend en charge à la fois les options serverless et dédiées.
Le service ajuste automatiquement la capacité à la hausse ou à la baisse en fonction du trafic, et son modèle de facturation à l’utilisation permet de maîtriser les coûts lors de charges de travail variables.
Pourquoi les développeurs choisissent-ils Novita AI ?
Novita AI offre des économies significatives par rapport aux grands fournisseurs cloud grâce à une allocation optimisée des ressources et une facturation à la seconde près. Le déploiement global en périphérie de la plateforme réduit la latence, quel que soit l’emplacement de l’utilisateur, ce qui la rend efficace pour les applications internationales.
La plateforme offre une flexibilité avec des API serverless et des instances GPU dédiées, permettant aux équipes de choisir la configuration d’infrastructure qui correspond le mieux à leur budget et à leurs besoins de performance. La fonction de mise à l’échelle automatique de Novita s’adapte automatiquement aux schémas de trafic, contribuant ainsi à maintenir l’efficacité des coûts lors des pics d’utilisation.
Tarifs de Novita AI
- Pay-as-you-go : tarification basée sur les tokens
- Crédits d’essai : disponibles pour l’évaluation et le développement
- GPU dédié : tarification horaire
- Plans entreprise : tarification personnalisée avec support dédié
Consultez les tarifs de Novita AI pour les prix actuels
Exemple d’intégration
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "deepseek/deepseek-r1-0528"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
En résumé
Novita AI offre un excellent équilibre entre rentabilité et portée mondiale, ce qui la rend particulièrement adaptée aux équipes cherchant à optimiser les coûts d’infrastructure IA tout en maintenant des performances internationales fiables.
Commencez un essai gratuit sur Novita AI dès aujourd’hui pour profiter des meilleurs fournisseurs d’inférence IA.
2. DeepInfra
Meilleur pour : Hébergement cloud économique et scalable de grands modèles d’IA open source.
Qu’est-ce que DeepInfra ?
DeepInfra est une plateforme d’inférence IA simple, scalable et économique qui regroupe des modèles de pointe dans des API REST faciles à utiliser. Elle prend en charge les points de terminaison compatibles OpenAI pour les complétions de chat, les embeddings et les points de terminaison d’inférence dédiés pour des modèles spécifiques, permettant aux développeurs de créer des applications avec un minimum de frais généraux.
Pourquoi les développeurs choisissent-ils DeepInfra ?
Les développeurs choisissent DeepInfra pour son accès API simple, sa compatibilité avec les bibliothèques OpenAI et ses points de terminaison flexibles pour les modèles. Son accent sur la scalabilité et la rentabilité le rend adapté à un large éventail de besoins d’inférence IA sans gestion complexe de l’infrastructure.
Tarifs de DeepInfra
- Pay-as-you-go : tarification basée sur les tokens
- Nœuds LLM personnalisés : tarification à l’heure GPU
- Plans entreprise : tarification sur demande
En résumé
DeepInfra propose des API simples et compatibles OpenAI avec une gestion automatisée des GPU, ce qui le rend idéal pour les développeurs et les PME recherchant un déploiement d’inférence IA rapide et efficace.
3. Inference.net
Meilleur pour : Inférence serverless à faible coût de très grands LLM avec des API flexibles de style OpenAI.
Qu’est-ce qu’Inference.net ?
Inference.net fournit un accès direct aux derniers modèles d’IA avec des prix compétitifs. En tant que fournisseur officiel de nombreux modèles de pointe, inference.net offre un accès fiable à des capacités de pointe avec une intégration API simple.
La plateforme se concentre sur la simplicité et l’accès direct aux modèles, offrant aux développeurs des performances constantes et une documentation complète.
Pourquoi les développeurs choisissent-ils Inference.net ?
Inference.net propose une tarification simple avec un modèle de paiement à l’utilisation. Son accès direct aux modèles garantit la disponibilité rapide des nouvelles versions et mises à jour, ce qui le rend adapté aux développeurs souhaitant travailler avec les dernières capacités d’IA.
La plateforme offre des performances fiables avec une intégration facile et une documentation claire. Inference.net se concentre sur la simplicité, ce qui le rend accessible aux équipes pour démarrer sans configuration ni prérequis complexes.
Tarifs d’Inference.net
- Pay-as-you-go : tarification basée sur les tokens
- Plans entreprise : tarification sur demande
En résumé
Inference.net offre l’accès le plus économique aux modèles de pointe avec une tarification transparente, ce qui le rend idéal pour les développeurs soucieux des coûts qui ont besoin d’un accès fiable aux dernières capacités d’IA.
4. Baseten
Meilleur pour : Débit maximum pour les applications d’entreprise à volume élevé.

Qu’est-ce que Baseten ?
Baseten est une plateforme ML axée sur les entreprises, fournissant une infrastructure de service de modèles haute performance. La plateforme est conçue pour les applications à l’échelle de la production nécessitant un débit maximal et une fiabilité de niveau entreprise.
L’infrastructure de Baseten comprend des techniques d’optimisation avancées, des ressources dédiées et des fonctionnalités d’entreprise telles que des garanties de niveau de service (SLA) et un support prioritaire.
Pourquoi les développeurs choisissent-ils Baseten ?
Baseten propose des fonctionnalités de niveau entreprise, notamment des instances dédiées, des garanties SLA et des capacités de surveillance complètes. Sa plateforme est conçue pour les équipes qui ont besoin de performances garanties et peuvent justifier un prix premium pour une fiabilité et un support supérieurs.
La plateforme offre des options de déploiement avancées, y compris les tests A/B, les déploiements progressifs et une surveillance sophistiquée qui aide les équipes à gérer des workflows ML de production complexes. L’infrastructure de Baseten est optimisée pour des performances constantes, quels que soient les schémas de trafic ou le nombre d’utilisateurs simultanés.
Tarifs de Baseten
- Pay-as-you-go : tarification basée sur les tokens
- GPU dédié : tarification à l’utilisation facturée à l’heure
- Plans entreprise : tarification sur demande
En résumé
L’infrastructure premium et les fonctionnalités d’entreprise de Baseten en font le choix privilégié pour les organisations qui ont besoin de performances garanties, d’un support complet et d’une gestion avancée des workflows ML.
5. Lambda
Meilleur pour : Inférence serverless économique et scalable de grands modèles de langage, avec des points de terminaison API flexibles de style OpenAI pour la production et l’expérimentation.
Qu’est-ce que Lambda ?
Lambda fournit des instances GPU cloud à la demande et des clusters gérés que les équipes peuvent utiliser pour déployer leurs propres serveurs d’inférence. La plateforme offre un service stable et prévisible avec des fonctionnalités d’entreprise conçues pour les applications critiques.
L’infrastructure de Lambda est conçue pour les charges de travail de production qui nécessitent des performances fiables et des capacités de traitement de contexte étendu.
Pourquoi les développeurs choisissent-ils Lambda ?
Lambda offre une fiabilité de niveau entreprise avec une disponibilité éprouvée et des performances constantes dans son catalogue de modèles.
La plateforme se concentre sur la stabilité et la prévisibilité, ce qui la rend adaptée aux applications critiques qui nécessitent des capacités d’IA fiables. L’infrastructure de Lambda comprend des mécanismes de redondance et de basculement qui garantissent une disponibilité constante du service.
Tarifs de Lambda
- Pay-as-you-go : tarification basée sur les tokens
- GPU dédié : tarification horaire
- Plans entreprise : tarification sur demande
En résumé
Lambda fournit une inférence fiable et axée sur les entreprises avec des capacités de contexte étendu, ce qui en fait un excellent choix pour les applications professionnelles nécessitant des performances et une fiabilité constantes.
6. Fireworks
Meilleur pour : Plateforme d’inférence et de fine-tuning haute performance de niveau entreprise avec des techniques avancées d’ajustement des modèles et un déploiement mondial.
Qu’est-ce que Fireworks ?
Fireworks AI se spécialise dans l’inférence IA à grande vitesse en utilisant leurs optimisations propriétaires basées sur Flash-Attention v2 et le décodage spéculatif. La plateforme offre une inférence ultra-rapide pour les modèles de texte, d’image et audio tout en maintenant la sécurité et la conformité de niveau entreprise.
Fireworks se concentre sur l’optimisation de la vitesse et les capacités multi-modales, prenant en charge divers types de modèles d’IA via une plateforme unique.
Pourquoi les développeurs choisissent-ils Fireworks ?
Fireworks offre une vitesse exceptionnelle sur l’ensemble de son catalogue de modèles grâce à son moteur d’optimisation propriétaire. Ses capacités multi-modales permettent aux développeurs d’intégrer le traitement du texte, de l’image et de l’audio via une seule API, simplifiant ainsi le développement d’applications complexes.
La plateforme est conforme aux normes HIPAA et SOC2 pour les exigences de sécurité des entreprises tout en maintenant des performances élevées sur différents types de modèles. La technologie d’optimisation de Fireworks fonctionne sur diverses architectures de modèles, garantissant une inférence rapide et constante, quelle que soit la complexité du modèle.
Tarifs de Fireworks
- Pay-as-you-go : tarification basée sur les tokens
- GPU dédié : tarification horaire
- Plans entreprise : tarification sur demande
En résumé
Fireworks excelle en termes de vitesse et de capacités multi-modales, ce qui le rend idéal pour les applications nécessitant une inférence ultra-rapide sur différents types de modèles, bien qu’à un prix premium.
7. Together AI
Meilleur pour : Écosystème complet de modèles open source avec capacités de fine-tuning.
Qu’est-ce que Together AI ?
Together AI propose des clusters GPU à grande échelle alimentés par les GPU NVIDIA GB200, B200, H200 et H100, interconnectés pour l’entraînement et l’inférence IA haute performance. Il offre un accès à des ressources GPU massives avec des piles logicielles optimisées et des services de conseil experts.
Il fournit une infrastructure à la fois pour l’inférence et l’entraînement, ce qui en fait une plateforme complète pour les workflows de développement IA open source.
Pourquoi les développeurs choisissent-ils Together AI ?
Together AI offre la bibliothèque de modèles open source la plus complète avec des capacités avancées de fine-tuning. La plateforme facilite l’expérimentation avec différents modèles, le passage fluide entre eux et la personnalisation des modèles pour des cas d’usage spécifiques.
La plateforme propose une documentation extensive, un support communautaire et des ressources éducatives qui aident les équipes à apprendre et à mettre en œuvre efficacement l’IA open source. Together AI prend en charge à la fois les workflows d’inférence et d’entraînement, ce qui le rend idéal pour les équipes travaillant avec des exigences de modèles variées et des besoins de développement personnalisés.
Tarifs de Together AI
- Pay-as-you-go : tarification basée sur les tokens
- GPU dédié : tarification horaire
- Plans entreprise : tarification sur demande
En résumé
L’écosystème open source étendu de Together AI et ses capacités de fine-tuning en font un bon choix pour les équipes travaillant avec des modèles variés et nécessitant des options de personnalisation complètes.
8. Parasail
Meilleur pour : Infrastructure de calcul IA scalable et économique avec des options de déploiement flexibles et une orchestration automatique des charges de travail.

Qu’est-ce que Parasail ?
Parasail fournit une inférence IA axée sur les entreprises avec des capacités avancées d’analyse, de surveillance et de gestion des workflows. La plateforme est conçue pour les applications professionnelles nécessitant une observabilité complète et des fonctionnalités avancées.
Parasail se concentre sur les exigences des entreprises, notamment des analyses détaillées, des workflows personnalisés et des capacités de surveillance avancées pour les applications IA de production.
Pourquoi les développeurs choisissent-ils Parasail ?
Parasail offre des capacités d’analyse et de surveillance complètes qui fournissent des informations approfondies sur les performances des modèles, les schémas d’utilisation et les opportunités d’optimisation des coûts. Sa plateforme comprend des outils avancés de gestion des workflows qui aident les équipes à orchestrer des pipelines IA complexes.
La plateforme propose des fonctionnalités de niveau entreprise, notamment des rapports détaillés, des tableaux de bord personnalisés et des alertes avancées, ce qui la rend adaptée aux organisations nécessitant une observabilité et une gouvernance complètes de leur infrastructure IA.
Tarifs de Parasail
- Inférence en temps réel : tarification basée sur les tokens
- GPU dédié : tarification horaire
- Plans entreprise : tarification sur demande
En résumé
Parasail offre des fonctionnalités d’entreprise complètes et des analyses avancées, ce qui le rend adapté aux organisations nécessitant une observabilité et une gouvernance détaillées de leur infrastructure IA.
9. Nebius
Meilleur pour : Infrastructure IA d’entreprise avec accès anticipé aux derniers GPU NVIDIA et forte conformité en matière de confidentialité des données.
Qu’est-ce que Nebius ?
Nebius fournit une infrastructure IA scalable avec accès aux GPU NVIDIA, prenant en charge à la fois l’entraînement et l’inférence. Il propose des clusters pré-optimisés et la possibilité de passer d’un seul GPU à de grandes fermes de GPU, ciblant les explorateurs d’IA et les entreprises.
Pourquoi les développeurs choisissent-ils Nebius ?
Les développeurs choisissent Nebius pour sa scalabilité, ses clusters GPU haute performance et son infrastructure de niveau entreprise qui prend en charge les charges de travail IA. Sa plateforme est conçue pour simplifier le passage des projets IA à petite échelle aux déploiements à grande échelle.
Tarifs de Nebius
- Pay-as-you-go : tarification basée sur les tokens
- Options d’essai : 1 $ de crédits gratuits
- Cloud GPU : tarification horaire
En résumé
Nebius cible les entreprises avec du matériel GPU haute performance et une forte conformité en matière de confidentialité des données, idéal pour les secteurs réglementés et les charges de travail IA à grande échelle.
10. GMI Cloud
Meilleur pour : Service fiable avec un équilibre entre performances et coût.
Qu’est-ce que GMI Cloud ?
GMI Cloud fournit des services d’inférence IA fiables avec des performances équilibrées et des prix compétitifs. La plateforme se concentre sur un service cohérent et fiable pour les charges de travail IA standard, avec un déploiement et une gestion simples.
GMI Cloud offre une inférence IA stable avec des performances fiables adaptées à la plupart des applications et cas d’usage standard.
Pourquoi les développeurs choisissent-ils GMI Cloud ?
GMI Cloud offre un service fiable et cohérent avec une tarification simple et des performances fiables pour les applications standard. Sa plateforme offre des performances adéquates pour la plupart des cas d’usage, sans optimisation premium ni fonctionnalités spécialisées.
La plateforme se concentre sur la simplicité et la fiabilité, ce qui la rend adaptée aux équipes qui ont besoin d’une inférence IA fiable sans fonctionnalités complexes ni optimisation maximale des performances. GMI Cloud propose une approche équilibrée de l’infrastructure IA pour les cas d’usage standard.
Tarifs de GMI Cloud
- Cloud GPU : tarification horaire
- Cloud GPU suralimenté : tarification sur demande
En résumé
GMI Cloud offre un équilibre entre performances et coût pour les applications IA standard qui privilégient la fiabilité et la simplicité plutôt que les fonctionnalités premium ou l’optimisation maximale.
Choisir le bon fournisseur pour vos besoins
Lors de la sélection d’un fournisseur d’inférence IA, tenez compte de ces facteurs clés :
1. Pour les applications sensibles aux coûts
- Novita AI : Déploiement multi-régions pour des charges de travail économiques et conscientes de la latence
- Inference.net : Tarification simple avec accès direct aux modèles
- DeepInfra : Prix compétitifs avec optimisation des performances
2. Pour les applications critiques en termes de performances
- Fireworks : Inférence ultra-rapide avec optimisation de la vitesse
- Baseten : Fiabilité de niveau entreprise avec garanties SLA
- DeepInfra : Optimisation des performances sur tous les modèles
3. Pour les besoins spécialisés
- Nebius : Conformité européenne et souveraineté des données
- Together AI : Écosystème complet de modèles open source
- Novita AI : Distribution mondiale avec mise à l’échelle intelligente
4. Pour les fonctionnalités d’entreprise
- Baseten : Garanties SLA d’entreprise et support dédié
- Lambda : Contexte étendu avec fiabilité d’entreprise
- Parasail : Analyses avancées et surveillance complète
**Utilisez les meilleurs fournisseurs d’inférence IA GRATUITEMENT !
Essayez maintenant gratuitement
Questions fréquemment posées
Qu’est-ce qu’une plateforme d’inférence IA ?
Une plateforme d’inférence IA est une infrastructure cloud ou en périphérie qui héberge des modèles de machine learning entraînés et renvoie des prédictions via une API, permettant aux développeurs de ne pas avoir à gérer les GPU ou la mise à l’échelle eux-mêmes.
Que sont les fournisseurs d’inférence ?
Les fournisseurs d’inférence sont des entreprises qui gèrent cette infrastructure—gérant le matériel, la mise à l’échelle et le réseau—afin que les utilisateurs puissent appeler un modèle avec une simple requête HTTP et payer uniquement pour le calcul consommé.
Qu’est-ce que le coût d’inférence IA ?
Le coût d’inférence IA est le montant facturé par un fournisseur chaque fois qu’un modèle traite des données—généralement facturé par token d’entrée et de sortie (pour les modèles de langage) ou par seconde/instance (pour les tâches de vision et les charges de travail personnalisées).
À propos de Novita AI
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et faire évoluer.



