

Points clés
Oui ou non : Le modèle Llama 3.2 3B est un modèle de langage léger mais performant qui prend en charge l’appel de fonction.
Ce qu’il peut faire : L’appel de fonction permet au modèle d’interagir avec des outils externes et des API, élargissant ses capacités au-delà de la simple génération de texte.
Comment l’implémenter ? Installez des API via le “LLM Playground” de Novita AI, puis implémentez avec le framework Langchain.
Dans le domaine actuel de l’intelligence artificielle, de nombreuses personnes débattent activement de la capacité du modèle Llama 3.2 3B à implémenter l’appel de fonction. De nombreux utilisateurs et développeurs partagent leurs expériences avec l’appel de fonction de Llama 3.2 3B sur des forums et les réseaux sociaux. Certains font état de bons résultats, avec un taux de réussite d’environ 80 % lors de l’utilisation du modèle pour des appels d’outils. Cependant, d’autres rapports indiquent que dans certains cas, le modèle peut mal comprendre le contexte, entraînant des appels de fonction inexacts ou échoués. Aujourd’hui, nous allons approfondir la fonctionnalité d’appel de fonction de Llama 3.2.
Llama 3.2 prend-il en charge l’appel de fonction ?
Oui !
Les modèles Llama 3.2, y compris la variante 3B, prennent en charge l’appel de fonction. Cette capacité permet au modèle de détecter quand il doit appeler une fonction, puis de générer du JSON avec des arguments pour appeler cette fonction. Cette fonctionnalité est un élément clé de la série Llama 3.2, les modèles étant affinés pour cela. Le modèle Llama 3.2 3B est particulièrement adapté aux applications sur appareils grâce à sa conception légère, tout en prenant en charge des fonctionnalités puissantes comme l’appel de fonction.

Qu’est-ce que l’appel de fonction ?
L’appel de fonction est une méthodologie qui permet aux LLM d’interagir avec des systèmes externes, des API et des outils. En équipant un LLM d’un ensemble de fonctions ou d’outils, ainsi que des détails sur la façon de les utiliser, le modèle peut choisir et exécuter intelligemment la fonction appropriée pour effectuer une tâche spécifique. Cette capacité étend la fonctionnalité des LLM au-delà de la simple génération de texte, leur permettant d’effectuer des actions, de contrôler des appareils et d’accéder à des bases de données.
Modèles pris en charge pour l’appel de fonction
De nombreux LLM et plates-formes prennent désormais en charge l’appel de fonction. Vous pouvez installer l’API via la page “LLM Playground” de Novita AI, et implémenter l’appel de fonction via langchain.
- Llama 3.3 : La version à 70 milliards de paramètres a montré de solides performances dans les tests d’appel de fonction en identifiant avec succès quand et quelles fonctions appeler en fonction des demandes des utilisateurs.
- Mistral : Les modèles comme Mistral-Large-2 démontrent leur succès dans l’appel de fonction au sein d’environnements tels que watsonx.ai.
- Gemini : Les modèles Gemini de Google prennent également en charge l’appel de fonction, avec divers exemples d’utilisation disponibles.
Si vous souhaitez plus d’informations, vous pouvez consulter ce site web !
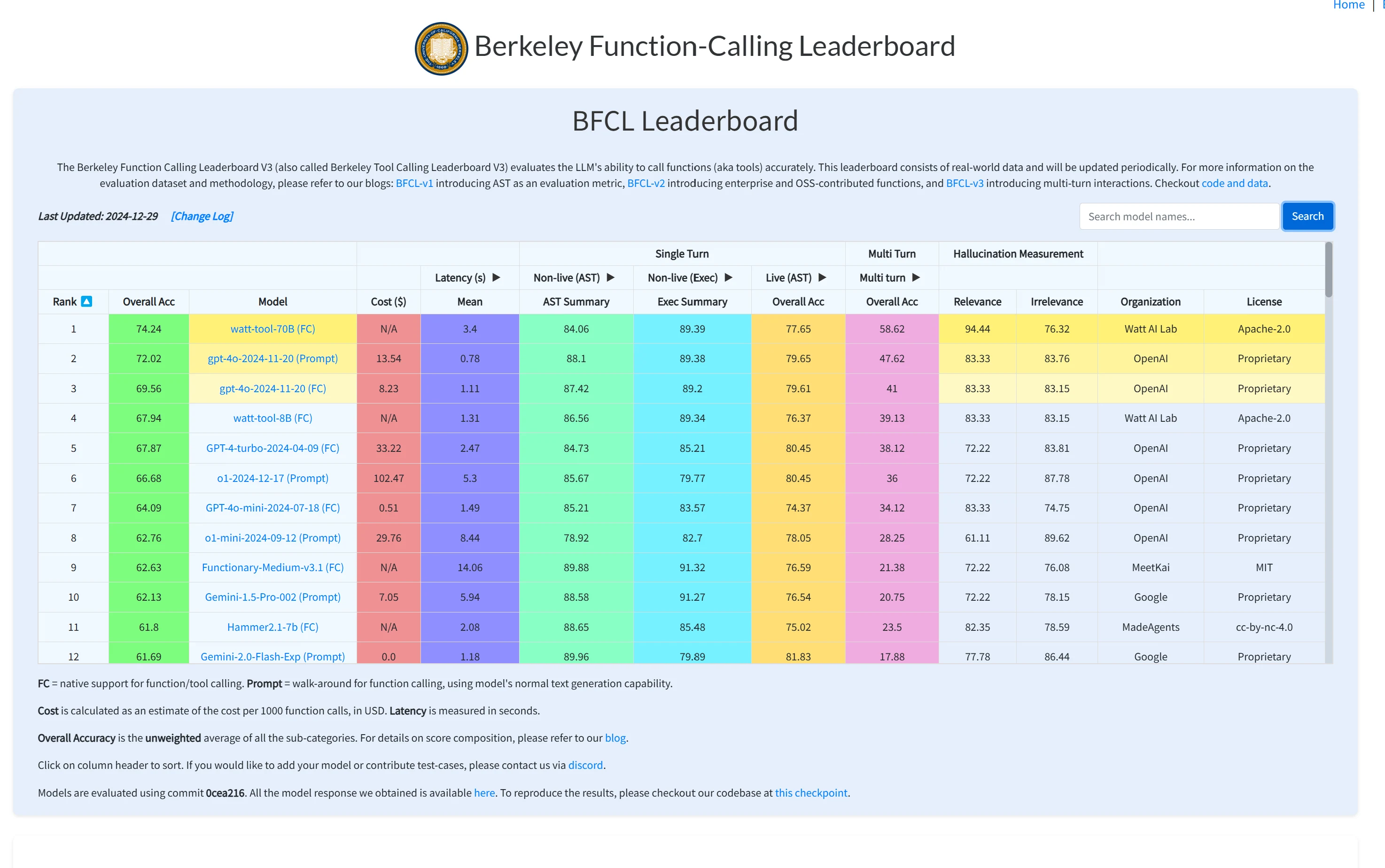
source : Berkeley Function-Calling Leaderboard
Comment fonctionne l’appel de fonction ?
L’appel de fonction implique généralement un processus en deux étapes :
- Mapper la demande utilisateur vers la fonction et les paramètres d’entrée corrects. Le LLM évalue si des outils disponibles sont pertinents pour la requête de l’utilisateur.
- Traiter la sortie de la fonction pour générer une réponse finale cohérente. Si applicable, le LLM construit une requête formatée pour appeler l’outil.
- La sortie de l’outil est ensuite analysée et intégrée dans la réponse finale.
Applications pratiques de l’appel de fonction
L’appel de fonction avec le modèle Llama 3.2 3B a de nombreuses applications concrètes :
- Chatbots de support client : Automatiser les réponses qui nécessitent des calculs ou une recherche d’informations.
- Traitement de données : Interagir avec des systèmes backend pour récupérer ou mettre à jour des données.
- Assistants virtuels : Améliorer les interactions utilisateur en permettant à l’assistant d’effectuer des opérations comme la planification ou les calculs.
- Interactions API : Convertir le langage naturel en appels API.
- Requêtes de base de données : Créer des applications qui traduisent le langage naturel en requêtes de base de données valides.
- Contrôle de la maison intelligente : Contrôler les appareils domestiques intelligents en réglant la température ou en activant/désactivant les lumières à l’aide de commandes en langage naturel.
- Moteurs de recherche de connaissances conversationnelles : Interagir avec des bases de connaissances.
- Plateformes de commerce électronique : Fournir des suggestions de produits en temps réel basées sur les bases de données d’inventaire, suivre les commandes ou gérer les tickets de support client.
- Santé : Planifier des rendez-vous ou récupérer des informations sur les patients.
- Voyage : Récupérer des informations de vol, réserver des réservations ou gérer les réservations.
- Finance : Fournir les soldes de comptes à jour et traiter les transactions.
Comment utiliser l’appel de fonction Llama 3.2 3B via Novita AI
Étape 1 : Obtenir une clé API
Rendez-vous sur la page “Keys”, vous pouvez copier la clé API comme indiqué sur l’image.
Lors de l’inscription, Novita AI offre un crédit de 0,5 $ pour vous permettre de démarrer !
Si le crédit gratuit est épuisé, vous pouvez payer pour continuer à l’utiliser.
Étape 2 : Utiliser Langchain pour implémenter l’appel de fonction
Nous allons créer une application mathématique simple capable d’effectuer des opérations d’addition et de multiplication.
💡 Bien que ce guide utilise LangChain pour plus de commodité, l’implémentation de l’appel de fonction ne nécessite aucun framework spécifique. La clé réside dans la conception des bons prompts pour que le modèle comprenne et invoque correctement les fonctions. LangChain est utilisé ici simplement pour simplifier l’implémentation.
Prérequis
Tout d’abord, installez les packages requis :
pip install langchain-openai python-dotenv
Configuration de l’environnement
Créez un fichier .env à la racine de votre projet et ajoutez votre clé API Novita AI :
NOVITA_API_KEY=your_api_key_here
Étapes d’implémentation
1. Définir les outils
Tout d’abord, créons deux outils mathématiques simples en utilisant le décorateur @tool de LangChain :
from langchain_core.tools import tool
@tool
def multiply(x: float, y: float) -> float:
"""Multiplie deux nombres."""
return x * y
@tool
def add(x: int, y: int) -> int:
"""Additionne deux nombres."""
return x + y
tools = [multiply, add]
2. Créer la fonction d’exécution des outils
Ensuite, implémentez une fonction pour exécuter les outils :
from typing import Any, Dict, Optional, TypedDict
from langchain_core.runnables import RunnableConfig
class ToolCallRequest(TypedDict):
name: str
arguments: Dict[str, Any]
def invoke_tool(
tool_call_request: ToolCallRequest,
config: Optional[RunnableConfig] = None
):
"""Exécute l'outil spécifié avec les arguments donnés."""
tool_name_to_tool = {tool.name: tool for tool in tools}
name = tool_call_request["name"]
requested_tool = tool_name_to_tool[name]
return requested_tool.invoke(tool_call_request["arguments"], config=config)
3. Mettre en place le pipeline LangChain
Créez une chaîne qui utilise le LLM de Novita AI pour sélectionner et préparer les appels d’outils :
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.tools import render_text_description
def create_chain():
"""Crée une chaîne qui utilise le modèle LLM spécifié pour sélectionner et préparer les appels d'outils."""
model = ChatOpenAI(
model="meta-llama/llama-3.3-70b-instruct",
api_key=os.getenv("NOVITA_API_KEY"),
base_url="https://api.novita.ai/v3/openai",
)
rendered_tools = render_text_description(tools)
system_prompt = f"""\
Vous êtes un assistant ayant accès à l'ensemble d'outils suivant.
Voici les noms et descriptions de chaque outil :
{rendered_tools}
À partir de l'entrée utilisateur, renvoyez le nom et les paramètres d'entrée de l'outil à utiliser.
Renvoyez votre réponse sous forme d'objet JSON avec les clés 'name' et 'arguments'.
Les `arguments` doivent être un dictionnaire, dont les clés correspondent
aux noms des arguments et les valeurs aux valeurs demandées.
"""
prompt = ChatPromptTemplate.from_messages(
[("system", system_prompt), ("user", "{input}")]
)
return prompt | model | JsonOutputParser()
4. Créer la fonction principale de traitement
Implémentez la fonction principale qui traite les requêtes mathématiques :
def process_math_query(query: str):
"""Traite une requête mathématique en utilisant un LLM pour sélectionner l'outil approprié et l'exécuter."""
chain = create_chain()
message = chain.invoke({"input": query})
result = invoke_tool(message, config=None)
return message, result
5. Exemple d’utilisation
Voici comment utiliser l’implémentation :
if __name__ == "__main__":
message, result = process_math_query(
"quel est le résultat de 3 plus 1132"
)
print(result) # Sortie : 1135
Problèmes courants et dépannage
Les problèmes courants rencontrés lors de l’appel de fonction incluent :
- Invocation incorrecte de fonction : Le modèle peut mal comprendre le contexte, conduisant à l’invocation de la mauvaise fonction.
- Latence élevée : Des réponses lentes peuvent survenir, affectant potentiellement l’expérience utilisateur.
- Fonctions non reconnues : Le modèle peut ne pas reconnaître les noms ou paramètres de fonctions valides, entraînant des erreurs d’exécution.
- Hallucinations du modèle : Le modèle peut générer des sorties ou des paramètres incorrects, ce qui peut conduire à des comportements inattendus.
- Passage de paramètres incohérent : Les paramètres peuvent être transmis dans des formats inattendus, provoquant des erreurs lors de l’exécution de la fonction.
- Problèmes réseau : Les dépendances API externes peuvent introduire des latences ou des échecs si la connectivité réseau est instable.
- Échecs d’analyse : La sortie du modèle peut ne pas correspondre aux formats attendus (par exemple, JSON invalide), entraînant des erreurs d’analyse.
Bonnes pratiques pour optimiser l’appel de fonction
Pour optimiser l’appel de fonction :
- Pour remédier à l’invocation incorrecte de fonction : Affinez le modèle sur des prompts spécifiques liés à l’appel de fonction pour améliorer la compréhension du contexte et minimiser les erreurs d’invocation de fonction.
- Pour atténuer la latence élevée : Optimisez les temps de réponse en réduisant le nombre de tokens dans les invites ou en implémentant des appels de fonction asynchrones pour de meilleures performances.
- Pour résoudre les fonctions non reconnues : Avant d’invoquer des fonctions, validez les noms et paramètres des fonctions pour garantir qu’ils sont correctement reconnus, évitant ainsi les erreurs d’exécution.
- Pour gérer les hallucinations du modèle : Implémentez des stratégies de gestion des erreurs prudentes pour traiter les sorties ou paramètres incorrects générés par le modèle, en mettant en place des mécanismes de repli pour les résultats inattendus.
- Pour assurer un passage de paramètres cohérent : Établissez des directives claires pour les formats de paramètres et imposez des contrôles de validation stricts pour garantir la cohérence dans la façon dont les paramètres sont transmis lors de l’exécution de la fonction.
- Pour gérer les problèmes réseau : Développez une stratégie robuste de gestion des erreurs pour les problèmes liés au réseau lors des interactions avec des API externes, y compris des mécanismes de nouvelle tentative pour les échecs transitoires.
- Pour prévenir les échecs d’analyse : Utilisez des techniques de validation de sortie pour garantir que les sorties du modèle correspondent aux formats attendus (par exemple, JSON valide), et implémentez une gestion des erreurs pour les erreurs d’analyse afin de maintenir la stabilité du système.
En résumé, la capacité d’appel de fonction représente une avancée significative dans la fonctionnalité des grands modèles de langage, leur permettant d’interagir efficacement avec des outils externes et des API. Bien qu’il existe des défis courants tels que l’invocation incorrecte de fonction, la latence élevée, les fonctions non reconnues et les hallucinations du modèle, l’implémentation de bonnes pratiques et d’une gestion robuste des erreurs peut améliorer sa fiabilité et ses performances. Alors que les développeurs continuent d’explorer et d’affiner cette fonctionnalité, les applications potentielles dans divers domaines devraient s’élargir, faisant de Llama 3.2 un outil polyvalent pour des tâches concrètes.
Foire aux questions
Pourquoi l’appel de fonction est-il crucial pour les agents d’IA ?
Il permet aux agents d’IA d’effectuer de manière autonome des tâches nécessitant des données ou actions externes, améliorant ainsi l’efficacité dans des environnements dynamiques.
Comment l’appel de fonction améliore-t-il les performances du LLM ?
Il améliore la précision en permettant la récupération de données en temps réel, l’exécution de tâches et une prise de décision éclairée via des outils externes.
Novita AI est la plateforme cloud tout-en-un qui propulse vos ambitions en IA. API intégrées, serverless, instance GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



