Everything You Need to Know About OpenAI CLIP

OpenAI’s CLIP (Contrastive Language-Image Pre-training) is a model that learns to associate images and their textual descriptions. By analysing how it works and how to implement CLIP, you will have a full understanding of OpenAI CLIP.
Introduction
In January 2021, OpenAI introduced CLIP (Contrastive Language-Image Pre-Training), a zero-shot classifier that utilizes its understanding of the English language to classify images without needing to be trained on a specific dataset. This model applies recent advancements in large-scale transformers, similar to GPT-3, to the field of vision.
The results are remarkably impressive. We have prepared a CLIP tutorial and a CLIP Colab notebook for you to experiment with the model on your own images.
What is OpenAI CLIP
CLIP, which stands for Contrastive Language-Image Pre-training, is an efficient method for learning from natural language supervision. Introduced in 2021 in the paper “Learning Transferable Visual Models From Natural Language Supervision,” CLIP is a joint image and text embedding model.
CLIP is trained on 400 million image and text pairs in a self-supervised manner, mapping both text and images to the same embedding space. For example, an image of a dog and the sentence “an image of a dog” would have very similar embeddings and be close to each other in the vector space. This capability is significant as it enables the creation of various applications, such as searching an image database with a description or the reverse.
CLIP’s Performance
Training Efficiency: CLIP is one of the most efficient models, achieving an accuracy of 41% with 400 million images. It outperforms other models, such as Bag of Words Prediction (27%) and Transformer Language Model (16%), at the same number of images. This indicates that CLIP trains significantly faster than other models in its domain.
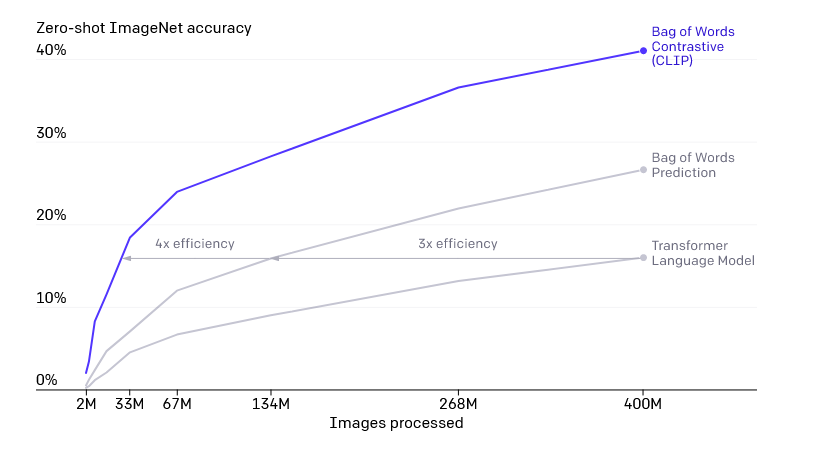
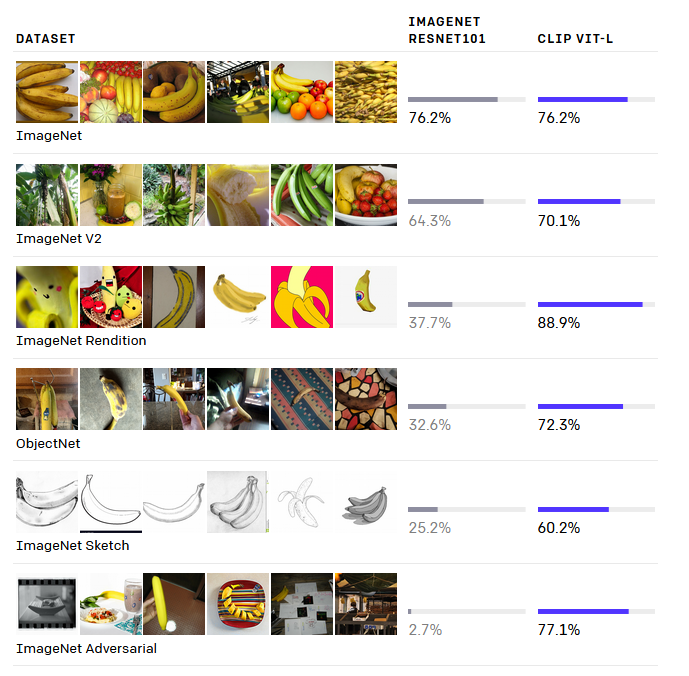
Generalization: CLIP has been trained on a diverse range of image styles, making it far more flexible than models like ImageNet. It is important to note that CLIP generalizes well with images it was trained on, but may not perform as effectively with images outside its training domain. Below are examples of some of the different image styles:
How CLIP works
Architecture
The CLIP model consists of two main components: a text encoder and an image encoder. The text encoder uses a Transformer, an architecture that has revolutionized NLP since 2017, making its inclusion unsurprising. For an excellent visual explanation, refer to the following blog.
For the image encoder, the authors experimented with two different models: ResNet-50 and Vision Transformer (ViT). ResNet-50, based on Convolutional Neural Networks (CNNs), was the original state-of-the-art architecture for image classification. ViT, a more recent adaptation of the Transformer for images, splits each image into a sequence of patches, treating them like a sequence of tokens. The authors found that the ViT trained faster.
The largest ResNet model, RN50x64, took 18 days to train on 592 V100 GPUs while the largest Vision Transformer took 12 days on 256 V100 GPUs.
Both the text and image encoders were trained from scratch.
We train CLIP from scratch without initializing the image encoder with ImageNet weights or the text encoder with pre-trained weights.
Training
The authors initially attempted to train an image captioning model that predicts the exact caption or description for a given image.
Our initial approach, similar to VirTex, jointly trained an image CNN and text transformer from scratch to predict the caption of an image. However, we encountered difficulties efficiently scaling this method.
However, they found that training an image captioning model on the 400 million (image, text) pairs was not scalable. Instead, they opted for a contrastive representation learning approach. The goal of this approach is to learn an embedding space where similar sample pairs are close to each other, while dissimilar ones are far apart.
In a typical contrastive learning setup, the model is given examples in the form of (anchor, positive, negative). Here, the anchor is an image from one class, such as a dog, the positive is another image from the same class (another dog), and the negative is an image from a different class, such as a bird. The images are embedded, and the model is trained to minimize the distance between embeddings of the same class (distance(anchor, positive)) and maximize the distance between embeddings of different classes (distance(anchor, negative)). This encourages the model to produce very similar embeddings for the same objects and distinct embeddings for different objects.
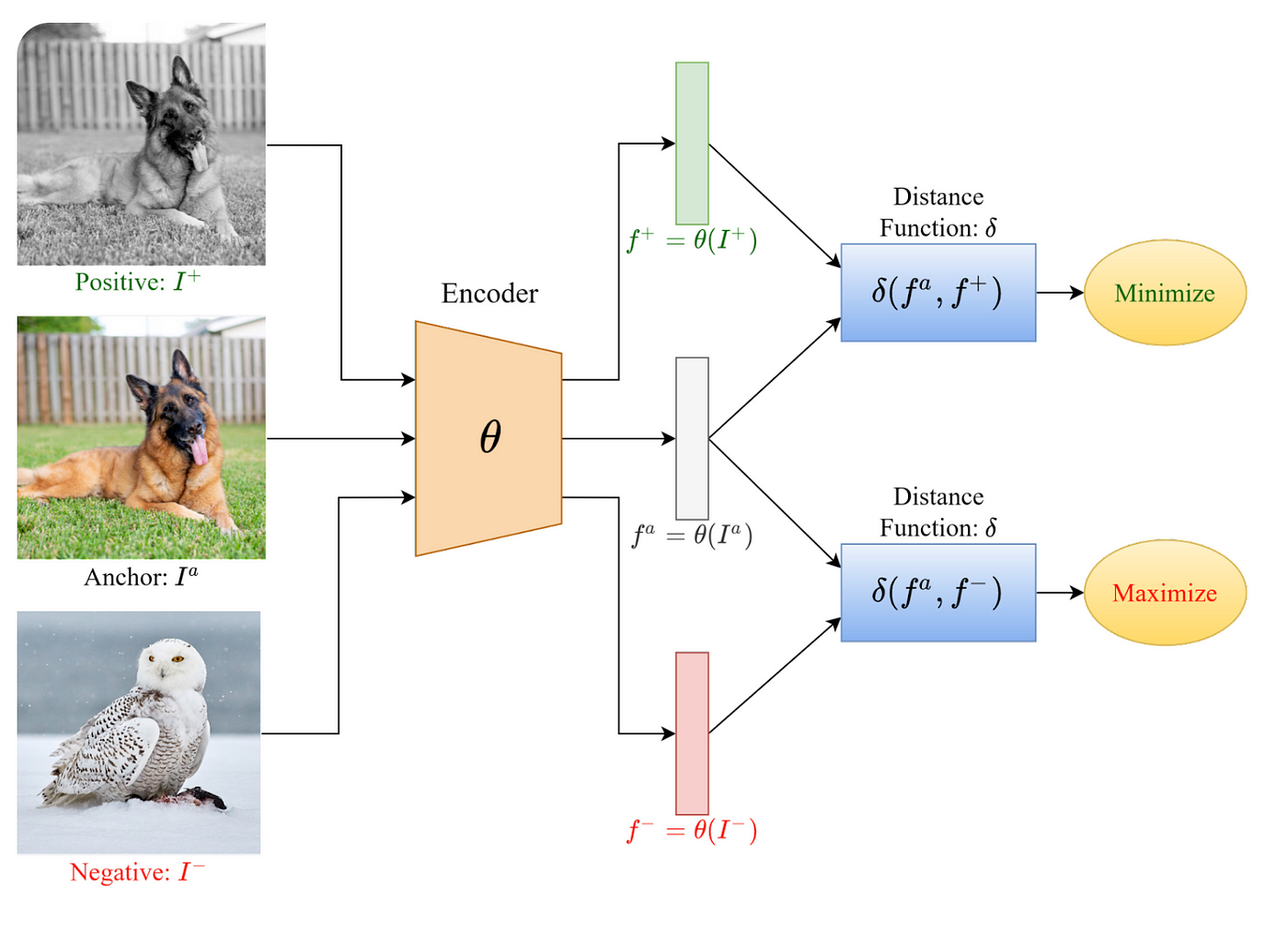
The same approach can be applied to text, as well as to combinations of text and images. For instance, in CLIP, a single training example could consist of an anchor (an image of a dog), a positive (the caption “an image of a dog”), and a negative (the caption “an image of a bird”).
CLIP generalizes this approach even further using a multi-class N-pair loss, an extension of the standard method that involves multiple negatives and positives for each anchor. As described in the paper:
Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N × N possible (image, text) pairings across a batch actually occurred. To do this, CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximise the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimising the cosine similarity of the embeddings of the N² − N incorrect pairings. It optimises a symmetric cross entropy loss over these similarity scores.
Prompt Engineering and Ensembling
With the rise of language models, prompt engineering has become a common practice to achieve good outputs from generative models. Given that the text encoder in CLIP is a transformer model, the authors found prompt engineering crucial for achieving good zero-shot performance. They observed that in their pre-training dataset, it was relatively rare for the text paired with the image to be a single word, such as “dog” representing a class label. More often, the text was a full sentence, like a caption or description of the image. As a result, the authors found that the prompt “a photo of a {object}” was a good default, though more specialized prompts worked better in certain cases. For example, for satellite images, “a satellite photo of a {object}” was more effective.
The authors also experimented with model ensembling, a technique where the predictions of multiple models are combined to produce the final output. This approach is commonly used in machine learning to address issues of high variance and low bias (overfitting) models. For CLIP, the ensemble was constructed by using many different prompts to create classifiers.
Both prompt engineering and ensembling significantly improved performance on ImageNet.
On ImageNet, we ensemble 80 different context prompts and this improves performance by an additional 3.5% over the single default prompt discussed above. When considered together, prompt engineering and ensembling improve ImageNet accuracy by almost 5%.
Applications of OpenAI CLIP
OpenAI CLIP has a wide range of applications and use cases in image-text analysis. Some of the key applications and use cases of CLIP include:
- Image classification: CLIP can classify images into different classes or categories based on their content. It can predict the most relevant class label for a given image.
- Image retrieval: CLIP can retrieve relevant images based on a given text query. It can find images that are semantically similar to the input text.
- Content moderation: CLIP can be used to automatically detect and moderate inappropriate or objectionable content in images and text.
- Image captioning: CLIP can generate captions or descriptions for images based on their content.
- Visual question answering: CLIP can answer questions about images based on their content.
Implementing OpenAI CLIP with Huggingface Transformers
You can utilize CLIP on your local machine with just a few lines of code using the HuggingFace Transformers library! Start by importing the library and loading the pre-trained model.
import transformers
model = transformers.CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = transformers.CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
Next, create two lists: one containing captions or descriptions, and another containing images. Images can be represented either as URLs or PIL images.
import PIL.Image
images = [PIL.Image("for_example_a_dog_image.jpeg")]
possible_classes = ["an image of a bird", "an image of a dog", "an image of a cat"]
Invoke the processor, which tokenizes both the texts and images and prepares them for input into the model. This process resembles calling a tokenizer in the standard text-only use case. Given a batch of descriptions, padding is applied to ensure they are all of the same length for tensor storage, and truncation is used to limit any long sentences to the maximum sequence length (which, as mentioned earlier, is 76). Finally, pass the tokenized inputs to the model, which then feeds them through the text and image encoders.
with torch.no_grad():
inputs = processor(text=descriptions, images=images, return_tensors="pt", padding=True, truncation=True)
outputs = model(**inputs)
Now, we can obtain the matrix of dot products using two different functions. Utilize `logits_per_image` to retrieve a dot product matrix with the shape [num_of_images, num_of_text], and `logits_per_text` to obtain the matrix with the shape [num_of_text, num_of_images].
dot_products_per_image = outputs.logits_per_image
dot_products_per_text = outputs.logits_per_text
Lastly, if desired, we can apply a softmax function to these matrices to obtain a probability distribution for each image.
probabilities = dot_products_per_image.softmax(dim=1)
Limitations of Using OpenAI CLIP
While the paper delves into numerous experiments and results, it’s important to acknowledge that CLIP has several limitations.
Firstly, due to the design decision mentioned earlier, CLIP is not a generative model and cannot perform tasks such as image captioning. However, other generative AI can perform more work than OpenAI CLIP does. For instance:
other generative AI such as novita.ai can make up for the deficiencies of CLIP by applying corresponding APIs.
The authors note that CLIP is still far from being state-of-the-art and is only comparable to a ResNet with a linear layer on top. It generalizes poorly to certain tasks; for instance, it achieves only 88% accuracy on the easy MNIST handwritten digit recognition dataset, likely because there are no similar images in its training data and CLIP does little to address this issue.
CLIP is trained on unfiltered and uncurated image-text pairs from the internet, resulting in the model learning many social biases. These concerns are similar to those of large language models (LLMs) currently, for which techniques like RLFHF (Robust Low-Frequency Hacking Framework) and Direct Preference Optimization attempt to mitigate.
Additionally, in the original implementation, the maximum sequence length for the Transformer text encoder was capped at 76. This limitation arises because the dataset mostly consists of images and short captions. Therefore, using the off-the-shelf pre-training model may not perform well with longer texts, as they would be truncated after 76 tokens, given that the model was trained with short texts.
Future Directions in Image-Text Analysis with CLIP
The success of OpenAI CLIP has opened up new possibilities for the future of image-text analysis. Researchers and developers are continuously exploring innovative applications and advancements in this field.
One future direction is the integration of CLIP with other modalities, such as audio and video, to enable multimodal analysis. This would allow CLIP to understand and analyze complex multimedia data, leading to more comprehensive and accurate results.
Additionally, advancements in self-supervised learning and unsupervised representation learning can further enhance CLIP’s performance and generalization abilities. These advancements can unlock new potential for CLIP in various domains, including healthcare, robotics, and multimedia content analysis.
The future of image-text analysis with CLIP is promising, and ongoing research and development will continue to push the boundaries of this exciting field.
Conclusion
OpenAI’s CLIP marks a significant leap in image-text analysis, utilizing large-scale transformers and contrastive learning to classify images based on natural language descriptions. Its versatility enables numerous innovative applications, although it faces limitations such as struggles with tasks outside its training domain, a capped sequence length for text, and inherited social biases from its unfiltered training data.
Techniques like prompt engineering and ensembling have improved its performance, and future advancements in integrating other modalities, such as audio and video, along with self-supervised and unsupervised learning, hold promise for further enhancing CLIP’s capabilities. The ongoing research and development in this field suggest a bright future for more comprehensive and accurate multimedia analysis.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
What is the difference between LLM and GPT
LLM Leaderboard 2024 Predictions Revealed
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available