

Puntos Clave
Llama 3.3 70B: El avanzado modelo de lenguaje de 70 mil millones de parámetros de Meta, destacado en tareas multilingües y eficiencia.
GPUs en la nube: Recursos escalables y rentables para implementar y ajustar modelos como Llama 3.3 70B.
Novita AI: Una plataforma flexible y asequible que ofrece GPUs potentes y herramientas para utilizar fácilmente Llama 3.3 70B.
Las soluciones basadas en la nube ofrecen una alternativa rentable al costoso hardware local. Puedes usar instancias de GPU de Novita AI — Al registrarte, obtienes 60 GB gratis en el Disco de Contenedor y 1 GB gratis en el Disco de Volumen; si se supera el límite gratuito, se aplicarán cargos adicionales.
El lanzamiento del modelo Llama 3.3 70B de Meta representa un avance importante en modelos de lenguaje accesibles y potentes. Este artículo presenta una visión técnica de Llama 3.3 70B, detallando sus capacidades y cómo aprovecharlo eficazmente utilizando recursos de GPU en la nube, con un enfoque en las soluciones disponibles a través de Novita AI.
¿Qué es Llama 3.3 70B?
Llama 3.3 70B es un modelo de lenguaje grande (LLM) con 70 mil millones de parámetros desarrollado por Meta, optimizado para tareas basadas en texto como chat multilingüe, generación de código y generación de datos sintéticos. Está disponible tanto para fines comerciales como de investigación y destaca en escenarios de diálogo multilingüe, superando a muchos modelos de chat de código abierto y propietarios en puntos de referencia de la industria.
Características Clave
- Arquitectura del modelo: Construido sobre una arquitectura transformer optimizada, Llama 3.3 emplea ajuste fino supervisado (SFT) y aprendizaje por refuerzo con retroalimentación humana (RLHF). Utiliza Atención de Consulta Agrupada (GQA) para una escalabilidad de inferencia mejorada.
- Tamaño de ventana de contexto: Admite una ventana de contexto de 128k tokens, ideal para procesar documentos extensos y conversaciones complejas.
- Idiomas admitidos: Soporta de forma nativa ocho idiomas principales: inglés, francés, alemán, italiano, portugués, español, hindi y tailandés, aunque también está entrenado en una gama más amplia de idiomas.
Benchmark
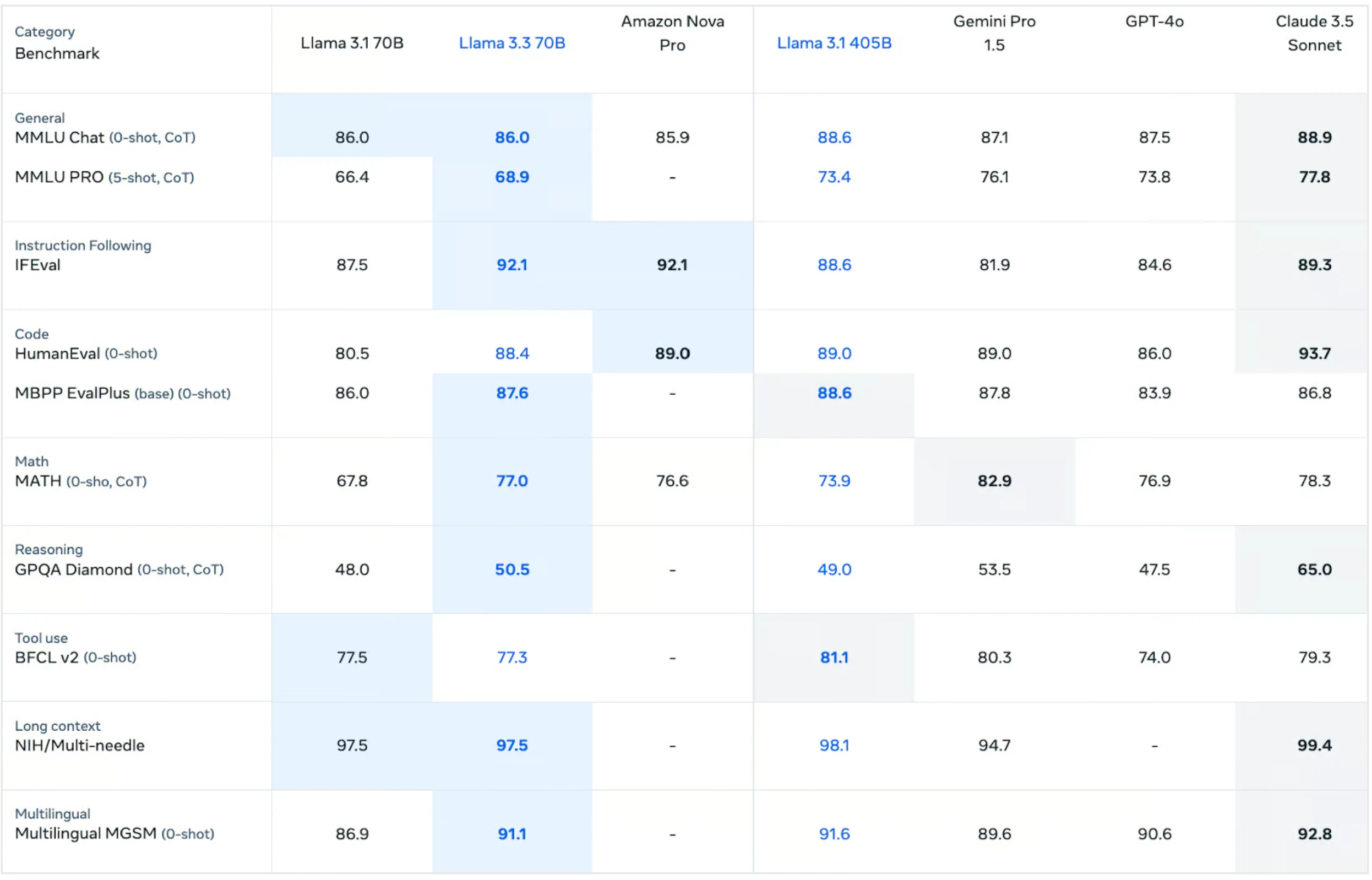
Comparación con otros Modelos
-
Comparación con otros Modelos Llama
- Llama 3.2 3B: Este modelo más pequeño con solo 3 mil millones de parámetros es menos capaz de manejar tareas complejas, pero puede ser más eficiente para aplicaciones simples donde las limitaciones de recursos son un factor.
- Llama 3.1 405B: Llama 3.3 70B proporciona un rendimiento similar al modelo Llama 3.1 405B, siendo más pequeño y con costos computacionales reducidos.
- Llama 3.1 70B: Llama 3.3 70B muestra mejoras de rendimiento en benchmarks como MMLU (CoT), MATH (CoT) y HumanEval en comparación con Llama 3.1 70B.
- Llama 3 70B: Similar en tamaño a Llama 3.3, ofrece alto rendimiento pero carece de algunas optimizaciones presentes en el modelo más nuevo.
-
Comparación con otros Modelos
- Llama 3.3 70B destaca en varias categorías, especialmente en seguimiento de instrucciones (IFEval) y codificación (HumanEval y MBPP EvalPlus). GPT-4o funciona bien en conversación general (MMLU Chat y MMLU PRO) y uso de herramientas (BFCL v2), pero se queda atrás en algunas tareas de razonamiento y codificación. Claude 3.5 Sonnet supera en la mayoría de categorías, especialmente en codificación (HumanEval), razonamiento (GPQA Diamond) y capacidades multilingües (Multilingual MGSM).
Aplicaciones
- Llama 3.3 70B se puede utilizar en diversas aplicaciones:
- Asistentes de IA y chatbots
- Generación de contenido
- Generación de código y asistencia para depuración
- Aplicaciones multilingües, incluyendo herramientas de traducción
- Generación de datos sintéticos
- Aplicaciones industriales: Se puede aplicar en sectores como atención al cliente, salud, finanzas y educación.
- Limitaciones: El modelo puede producir respuestas inexactas o sesgadas; por lo tanto, los desarrolladores deben realizar pruebas de seguridad adaptadas a sus aplicaciones específicas.
Entendiendo las GPUs en la nube

-
¿Qué son las GPUs en la nube?
- Definición: Una GPU en la nube es una unidad de procesamiento gráfico de alto rendimiento proporcionada como servicio por proveedores de nube, que permite acceso remoto a recursos computacionales sustanciales sin inversiones iniciales en hardware.
- Cómo funciona: Las GPUs en la nube ofrecen recursos virtualizados a través de instancias de máquinas virtuales o entornos contenedorizados.
-
Beneficios de usar GPUs en la nube
- Escalabilidad según las necesidades computacionales
- Rentabilidad mediante modelos de pago por uso
- Acceso a recursos potentes para tareas de IA
- Flexibilidad para elegir tipos de GPU
Cómo elegir GPUs en la nube
Criterios de selección clave
-
Tipos de GPU:
- Opta por GPUs de alto rendimiento como NVIDIA A100 o V100, que destacan en el manejo de modelos a gran escala.
-
Capacidad de memoria:
- Asegúrate de que la GPU seleccionada tenga suficiente memoria de video (típicamente 32 GB o más) para cargar y ejecutar modelos de 30B de manera eficiente.
-
*Potencia computacional: *
- Revisa la capacidad computacional (en TFLOPS) ofrecida por el servicio en la nube para asegurarte de que cumple con las demandas de inferencia y entrenamiento del modelo.
-
*Modelos de precios: *
- Compara los métodos de facturación (por hora, basado en uso, etc.) de diferentes servicios en la nube y selecciona el que mejor se alinee con tu presupuesto y frecuencia de uso.
-
*Comunidad y ecosistema: *
- Opta por un servicio en la nube con una comunidad activa y recursos abundantes, lo que facilita encontrar casos de uso y soporte técnico.
Comparación de métodos de acceso
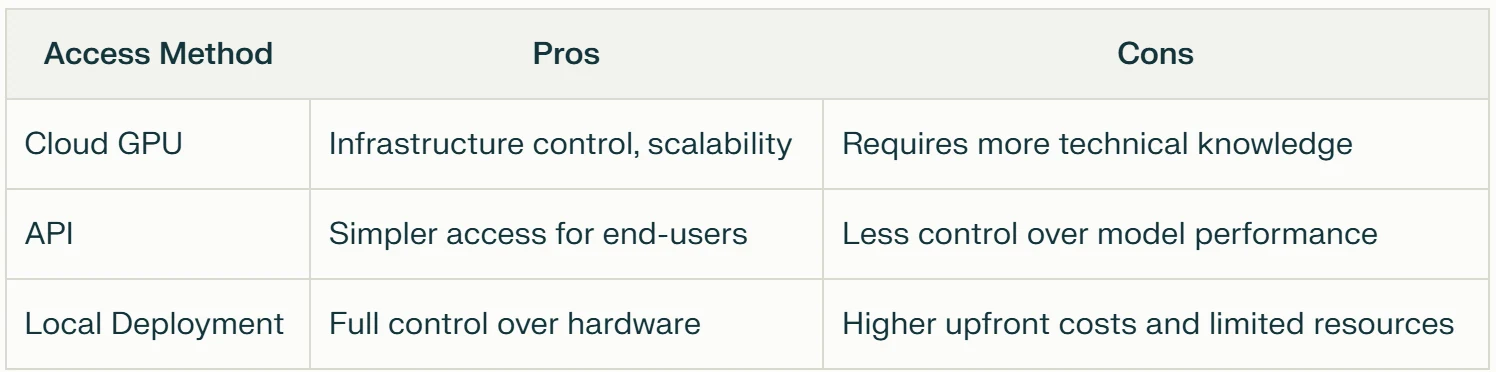
En conclusión, acceder a Llama 3.3 ofrece varias opciones adaptadas a diferentes necesidades del usuario.
- GPU en la nube es mejor para usuarios ocasionales que buscan una interacción rápida y fácil con el modelo sin barreras técnicas.
- Acceso por API es ideal para desarrolladores que buscan integración rentable y flexibilidad para ajustar modelos sin grandes inversiones en hardware.
- Acceso local proporciona a investigadores y desarrolladores control total y personalización, adecuado para quienes priorizan la privacidad y seguridad de los datos.
Cada método tiene sus fortalezas, permitiendo a los usuarios elegir el enfoque más apropiado según sus requisitos y recursos específicos.
GPUs en la nube y proveedores recomendados
GPUs recomendadas
- NVIDIA A100 (80GB):
- Ajuste fino completo (precisión float32): La configuración recomendada es 8x NVIDIA A100.
- La A100 está diseñada para computación de alto rendimiento y ofrece ancho de banda de memoria y potencia computacional excepcionales, lo que la hace ideal para modelos de lenguaje grandes.
- NVIDIA H100:
- Esta GPU es aún más potente que la A100 y es adecuada para cargas de trabajo intensivas de IA, incluido el entrenamiento de modelos grandes como LLaMA 3.3. Cuenta con alta capacidad y ancho de banda de memoria, lo que facilita el procesamiento eficiente de grandes conjuntos de datos.
- NVIDIA RTX 3090:
- Para tareas de ajuste fino más ligeras o escenarios de precisión reducida, se puede usar la RTX 3090, especialmente para modelos que han sido cuantizados. Proporciona 24 GB de memoria GDDR6X, que puede manejar tareas de ajuste fino a menor escala de manera efectiva.
- NVIDIA RTX 4090:
- Esta GPU también ofrece un rendimiento sustancial con 24 GB de VRAM GDDR6X, lo que la hace adecuada para LLM medianos y grandes. Se puede utilizar para ajustar variantes más pequeñas de LLaMA o en escenarios donde la rentabilidad es una prioridad.
Proveedores recomendados
En comparación con otros proveedores de GPU, Novita AI tiene algunas ventajas.
- rentable: reduce los costos de nube hasta en un 50%
- recursos de GPU flexibles a los que se puede acceder bajo demanda
- despliegue instantáneo
- plantillas personalizables
- almacenamiento de gran capacidad
- varios modelos de IA de alta demanda
- obtén 100 GB gratis

Cómo acceder a Llama 3.3 70b en GPUs en la nube
Paso 1: Haz clic en la Instancia de GPU
Si eres un nuevo suscriptor, primero registra tu cuenta. Luego, haz clic en el botón [Instancia de GPU](https://novita.ai/gpus/?utm_source=blogs_gpu&utm_medium=article&utm_campaign= fine-tuning-llama-3-3-70b-with-rtx-4090) en nuestra página web.
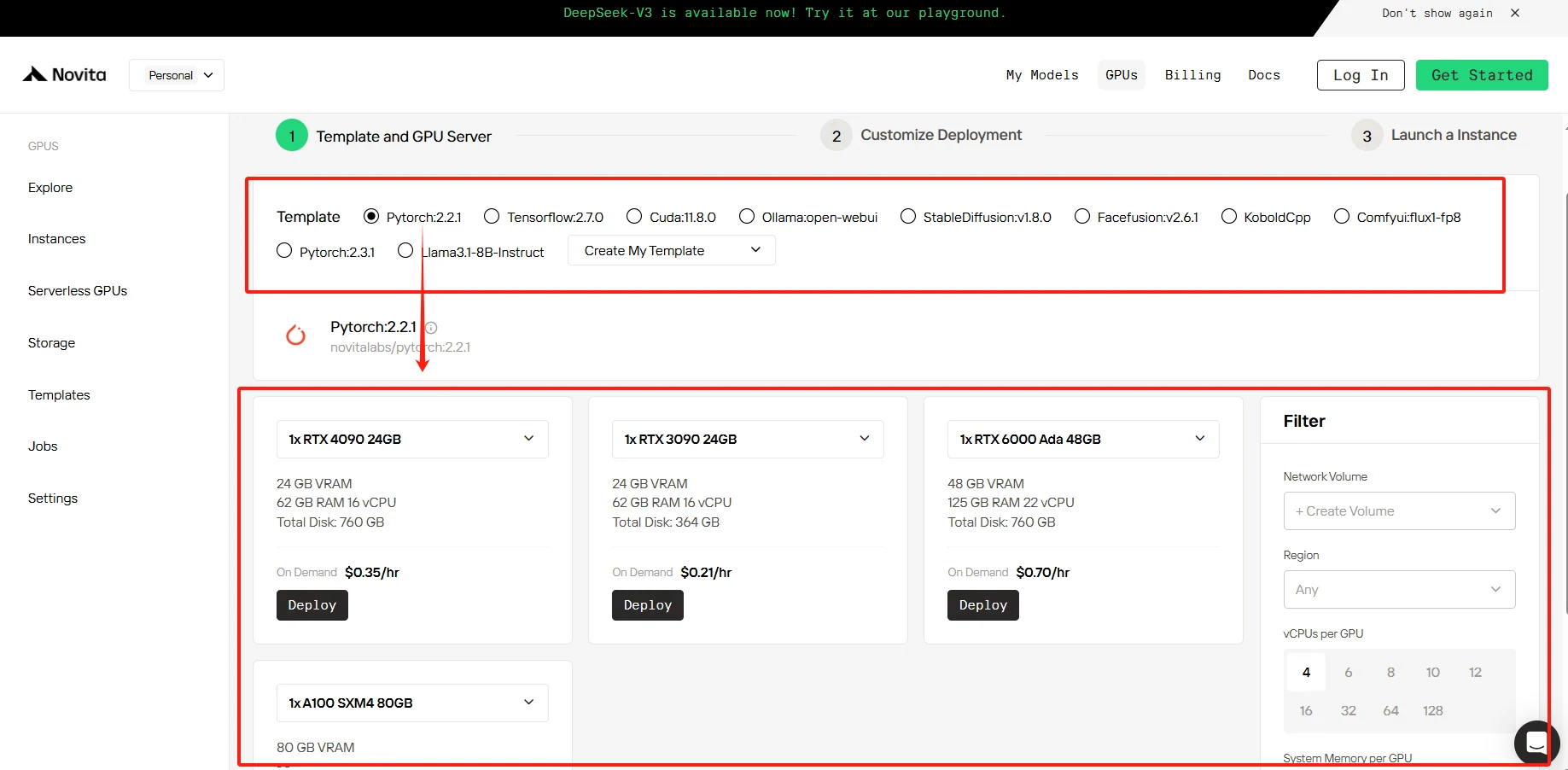
PASO 2: Plantilla y servidor GPU
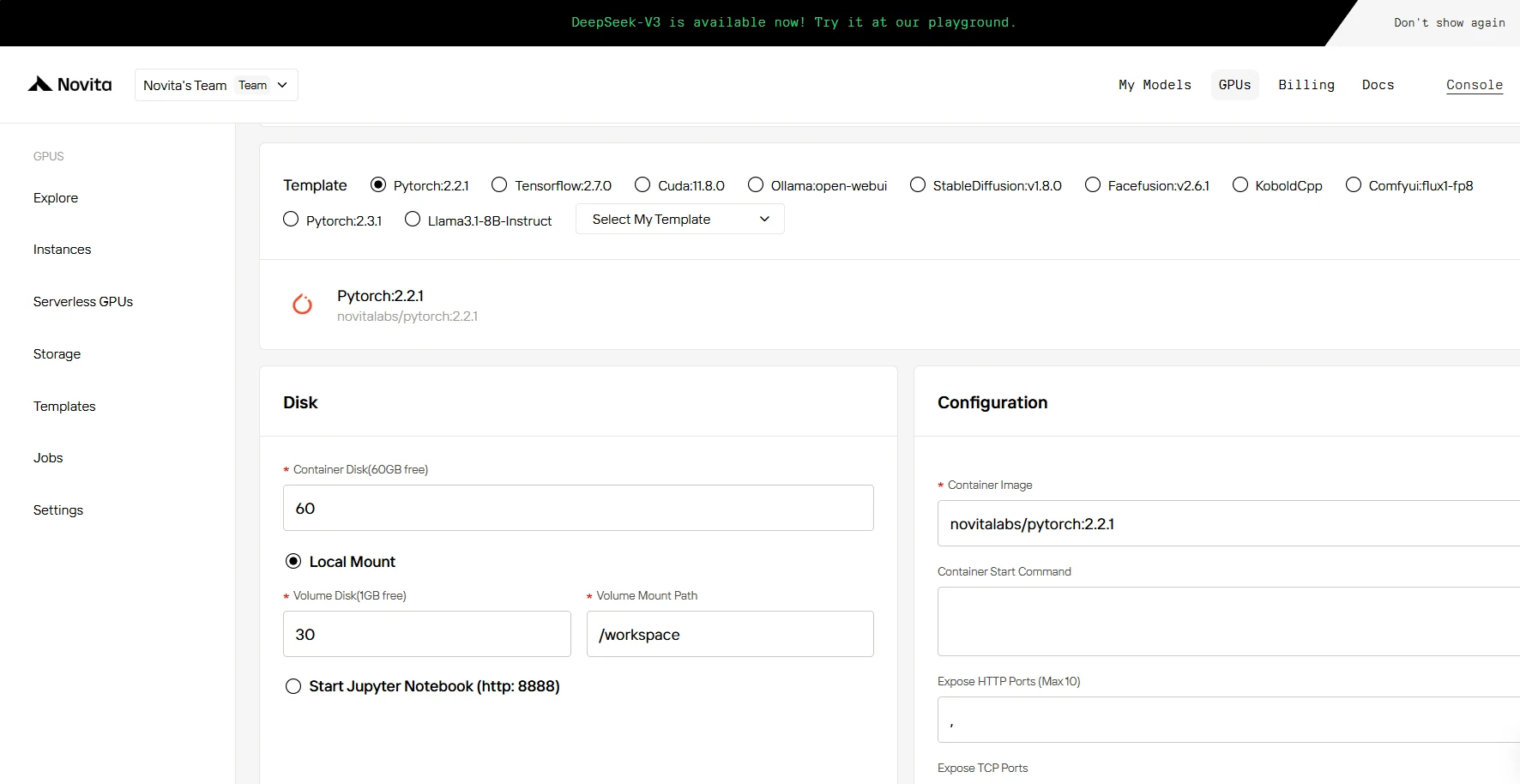
Puedes elegir tu propia plantilla, incluyendo Pytorch, Tensorflow, Cuda, Ollama, según tus necesidades específicas. Además, también puedes crear tus propios datos de plantilla haciendo clic en la última opción.
Luego, nuestro servicio proporciona acceso a GPUs de alto rendimiento como la NVIDIA RTX 4090, cada una con VRAM y RAM sustanciales, asegurando que incluso los modelos de IA más exigentes puedan entrenarse de manera eficiente. Puedes seleccionarla según tus necesidades.
PASO 3: Personalizar el despliegue
En esta sección, puedes personalizar estos datos según tus propias necesidades. Hay 60 GB gratis en el Disco de Contenedor y 1 GB gratis en el Disco de Volumen; si se supera el límite gratuito, se aplicarán cargos adicionales.
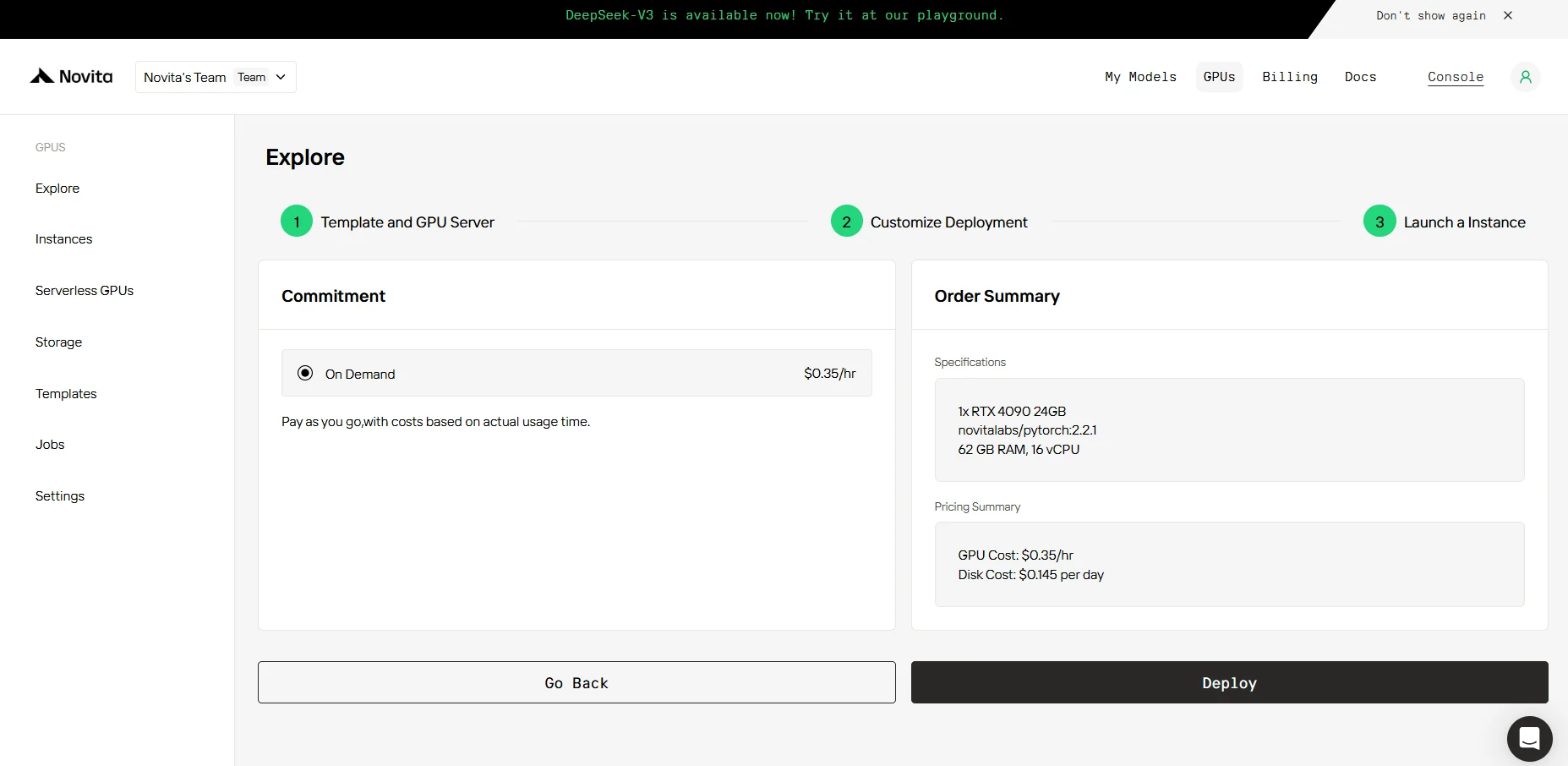
PASO 4: Iniciar una instancia
Ya sea para investigación, desarrollo o implementación de aplicaciones de IA, la Instancia de GPU Novita AI equipada con CUDA 12 ofrece una experiencia de computación GPU potente y eficiente en la nube.
Conclusión
Llama 3.3 70B representa un avance significativo en el modelado de lenguaje, ofreciendo alto rendimiento y eficiencia para tareas como chat multilingüe, generación de código y creación de datos sintéticos. Implementar este modelo a través de GPUs en la nube garantiza escalabilidad, rentabilidad y accesibilidad, lo que lo hace adecuado tanto para fines comerciales como de investigación. Plataformas como Novita AI simplifican el proceso al proporcionar recursos de GPU potentes, plantillas personalizables y soluciones rentables, permitiendo a desarrolladores e investigadores aprovechar todo el potencial de Llama 3.3 70B con facilidad.
Preguntas Frecuentes
¿Por qué debería usar GPUs en la nube para Llama 3.3 70B?
Las GPUs en la nube proporcionan recursos computacionales escalables, rentabilidad mediante modelos de pago por uso y acceso a hardware de alto rendimiento sin necesidad de inversiones iniciales.
¿Qué GPUs se recomiendan para ejecutar Llama 3.3 70B?
Se recomiendan GPUs como NVIDIA A100, H100, RTX 3090 y RTX 4090, dependiendo de la escala de tu tarea y presupuesto.
¿Por qué debería usar GPUs en la nube para Llama 3.3 70B?
Las GPUs en la nube proporcionan recursos computacionales escalables, rentabilidad mediante modelos de pago por uso y acceso a hardware de alto rendimiento sin necesidad de inversiones iniciales.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancia de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



