

تُعد سلسلة MiniMax Speech 2.8 أحدث ترقية لخط إنتاج تحويل النص إلى كلام الرائد من MiniMax، حيث تقدم علامات نبرة عاطفية — علامات مدمجة مثل (laughs) و (sighs) و (gasps) تجعل الكلام المولد بالذكاء الاصطناعي يبدو إنسانياً حقاً. تتوفر السلسلة 2.8 بأربعة إصدارات على Novita AI (HD Sync، HD Async، Turbo Sync، Turbo Async)، مع الحفاظ على نفس أسعار الإصدار السابق مع إضافة مجموعة ميزات لا يقدمها المنافسون بهذا المستوى على الإطلاق. إذا كنت تبني وكلاء صوتية، أو كتباً صوتية، أو أي مسار محتوى صوتي، فهذه سلسلة نماذج تحويل النص إلى كلام التي يجب عليك تقييمها الآن.
ما هي سلسلة MiniMax Speech 2.8؟
تحتل MiniMax باستمرار مركزاً متقدماً في Artificial Analysis Speech Arena و Hugging Face TTS Arena، حيث تفوقت على كبار الصناعة مثل OpenAI في التقييمات العمياء.
تُعد سلسلة Speech 2.8 أحدث تطور في هذا الخط. تم بناؤها على بنية المحول الذاتي الانحداري من MiniMax مع مفكك Flow-VAE، حيث تنتج الكلام في فضاء كامن متعلم بدلاً من الاعتماد على مشفرات الطيف الصوتي الميلية التقليدية — والنتيجة هي صوت يبدو طبيعياً للغاية، مع نبرة صوتية مناسبة، وتنفس، واختلافات عاطفية دقيقة.
الميزة الرئيسية للسلسلة 2.8: علامات النبرة العاطفية. لأول مرة، يمكنك دمج المقاطعات الطبيعية مباشرة في نص الإدخال، ويقوم النموذج بتقديمها كأصوات إنسانية حقيقية داخل تدفق الكلام.
تستضيف Novita AI الآن السلسلة الكاملة لـ Speech 2.8، مما يمنح المطورين وصولاً فورياً لواجهة برمجة التطبيقات (API) دون فترات بدء بارد.
الميزات الرئيسية وما الجديد
علامات النبرة العاطفية
الإضافة المميزة. أدخل العلامات بين قوسين في أي مكان من النص، وسيقوم النموذج بدمجها بسلاسة في الكلام المولد:
| العلامة | التأثير | المثال |
(laughs) |
ضحك | “هذا مضحك (laughs)” |
(chuckle) |
ضحكة خفيفة | “جيد جداً (chuckle)” |
(sighs) |
تنهد | “حسناً (sighs)، لنبدأ” |
(gasps) |
شهقة مفاجئة | “انتظر (gasps)! حقاً؟” |
(clears throat) |
تنظيف الحلق | “(clears throat) لنبدأ” |
(coughs) |
سعال | “عذراً (coughs)” |
(sneezes) |
عطس | “أتشو (sneezes)! آسف” |
هذه ليست مجرد ميزة جديدة — بل تحل مشكلة حقيقية. حتى الآن، كان جعل مخرج تحويل النص إلى كلام يبدو تلقائياً يتطلب تعديلات ما بعد الإنتاج أو إضافة مؤثرات صوتية يدوياً. مع علامات النبرة، يتم دمج التعبيرية مباشرة في مسار التوليد.
وضع الصوت المستمر
يُعدل المعامل الجديد continuous_sound الانتقالات بين الجمل، مما يزيل “الخطوط الدقيقة” الصوتية الخفية التي تجعل الكلام المتركب يبدو ملصقاً معاً. هذا واضح بشكل خاص في المقاطع الأطول.
الميزات الموروثة من سلسلة MiniMax Speech
تحتفظ سلسلة Speech 2.8 بمجموعة الميزات الكاملة للإصدارات السابقة:
- أكثر من 40 لغة مع معامل
language_boostلتعزيز التعرف على اللغات/اللهجات الأقل انتشاراً - 9 إعدادات مسبقة للعاطفة: happy، sad، angry، fearful، disgusted، surprised، calm، fluent، whisper
- استنساخ الصوت: استخدام أصوات النظام، أو الأصوات المستنسخة، أو الأصوات المولدة من النص
- مزج الأصوات: دمج ما يصل إلى 4 أصوات بنسب مرجحة عبر معامل
timber_weights - تعديل الصوت: ضبط المعاملات pitch و timbre و intensity بشكل مستقل (النطاق من -100 إلى 100)
- مؤثرات صوتية: spacious echo، auditorium echo، telephone distortion، robotic
- تنسيقات إخراج الصوت: MP3، PCM، FLAC، WAV
- معدلات العينة: من 8000 إلى 44100 هرتز
- قاموس النطق: قواعد مخصصة لأسماء العلامات التجارية، والاختصارات، والمصطلحات المتخصصة
- إخراج متدفق: للتطبيقات في الوقت الفعلي
- حد النص: ما يصل إلى 10000 حرف لكل طلب (sync)، ما يصل إلى 1000000 حرف (async)
إصدارات النموذج: HD مقابل Turbo، متزامن مقابل غير متزامن
تقدم Novita AI أربع نقاط نهاية في سلسلة Speech 2.8:
| الإصدار | نقطة النهاية | الأفضل لـ |
| Speech 2.8 HD Sync | POST``/v3/minimax-speech-2.8-hd |
جودة عالية، في الوقت الفعلي — كتب صوتية، تعليق صوتي احترافي |
| Speech 2.8 HD Async | POST /v3/async/minimax-speech-2.8-hd |
جودة عالية، محتوى طويل — إنتاج كتب صوتية جماعي، معالجة دفعية |
| Speech 2.8 Turbo Sync | POST /v3/minimax-speech-2.8-turbo |
زمن استجابة منخفض، في الوقت الفعلي — وكلاء صوتية، روبوتات محادثة، دعم عملاء مباشر |
| Speech 2.8 Turbo Async | POST /v3/async/minimax-speech-2.8-turbo |
معالجة سريعة، محتوى طويل — توليد محتوى جماعي، دبلجة على نطاق واسع |
HD مقابل Turbo: يقدم إصدار HD جودة صوتية استوديو — تفاصيل نغمة أغنى، وعرض عاطفي أكثر دقة. يُحسن إصدار Turbo من السرعة مع جودة صوتية أقل قليلاً، مما يجعله مثالياً للسيناريوهات التفاعلية في الوقت الفعلي.
متزامن مقابل غير متزامن: يعيد الإصدار المتزامن الصوت في استجابة واجهة برمجة التطبيقات (API) (ما يصل إلى 10000 حرف). يقبل الإصدار غير المتزامن ما يصل إلى 1000000 حرف ويعيد task_id للاستعلام — مثالي للكتب الصوتية وسير العمل الدفعي.
مقارنة مع Speech 2.6
| الميزة | Speech 2.6 | Speech 2.8 |
| جودة الصوت | ممتازة | ممتازة |
| علامات النبرة العاطفية | ❌ | ✅ (laughs, sighs, gasps, إلخ) |
| وضع الصوت المستمر | ❌ | ✅ |
| أكثر من 40 لغة | ✅ | ✅ |
| استنساخ الصوت | ✅ | ✅ |
| مزج الأصوات (حتى 4) | ✅ | ✅ |
| إعدادات مسبقة للعاطفة (9 أنواع) | ✅ | ✅ |
مسار الترقية واضح: تمنحك سلسلة Speech 2.8 كل ما تقدمه Speech 2.6، بالإضافة إلى علامات النبرة العاطفية ووضع الصوت المستمر، بنفس السعر. لا يوجد سبب لعدم الترحيل.
الأسعار على Novita AI
تتبع سلسلة MiniMax Speech 2.8 على Novita AI نفس هيكل الأسعار الخاص بالسلسلة 2.6:
| النموذج | السعر |
| Speech 2.8 Turbo (متزامن وغير متزامن) | 60 دولاراً / 1 مليون حرف |
| Speech 2.8 HD (متزامن وغير متزامن) | 100 دولار / 1 مليون حرف |
للحصول على أحدث تفاصيل الأسعار، قم بزيارة وحدة أسعار Novita AI.
هل أنت مستعد لتجربة سلسلة MiniMax Speech 2.8؟ سجل في Novita AI واحصل على رصيد مجاني لبدء توليد كلام معبر ومشابه للبشر في دقائق. لا يتطلب إعداد أي بنية تحتية.
من يجب أن يستخدم أي إصدار
تخيل أنك تقرر أي إصدار يناسب مشروعك. إليك دليل سريع بناءً على حالات استخدام حقيقية:
🎙️ “أنا أبني منصة بودكاست أو كتب صوتية”
→ Speech 2.8 HD Async
تحتاج إلى أعلى دقة صوتية، ومحتواك طويل. تتعامل نقطة النهاية غير المتزامنة مع ما يصل إلى 1 مليون حرف لكل طلب — أرسل فصلاً كاملاً واسترجع الصوت عندما يكون جاهزاً. ادمج علامات النبرة مع الإعدادات المسبقة للعاطفة لإحياء الشخصيات: راوٍ يتنهد (sighs) عند منعطف درامي في الحبكة أو يضحك (laughs) عند نكتة يجعل تجربة الاستماع أكثر جاذبية بشكل كبير.
🤖 “أنا أبني وكيل صوتي أو روبوت محادثة في الوقت الفعلي”
→ Speech 2.8 Turbo Sync
زمن الاستجابة هو كل شيء. تم تصميم Turbo Sync للاستجابة في الوقت الفعلي، مما يجعل المحادثات تبدو طبيعية. أضف (chuckle) عندما يروي وكيلك نكتة، أو (clears throat) قبل تقديم معلومات مهمة — لمسات صغيرة تجعل تفاعلات الذكاء الاصطناعي تبدو أقل آلية.
🎮 “أنا أضيف صوتاً لشخصيات اللعبة غير القابلة للعب (NPCs) أو التطبيقات التفاعلية”
→ Speech 2.8 HD Sync
تحتاج شخصيات اللعبة إلى أصوات معربة وعالية الجودة. يمنحك HD Sync صوتاً بجودة استوديو في الوقت الفعلي. استخدم مزج الأصوات لإنشاء أجراس صوتية فريدة للشخصيات، ووزع علامات النبرة في اللحظات الدرامية — شرير يضحك (laughs) بشكل مخيف، أو رفيق يشهق (gasps) عند الاكتشافات.
📹 “أنا أنتج تعليقات صوتية للفيديو على نطاق واسع”
→ Speech 2.8 Turbo Async
تحتاج إلى معالجة دفعية سريعة دون تكاليف باهظة. يوازن Turbo Async بين السرعة والجودة لمحتوى الفيديو عالي الحجم — فيديوهات شرحية، مقاطع وسائل التواصل الاجتماعي، مواد تدريبية. أرسل النصوص بشكل جماعي واسترجع ملفات صوتية مصقولة.
كيف تبدأ على Novita AI
الخطوة 1: جرّبه في مساحة العمل التجريبية (Playground)
قبل كتابة سطر واحد من الأكواد، استكشف سلسلة MiniMax Speech 2.8 مباشرة في مساحة العمل التجريبية لـ Novita AI:
- مساحة عمل تجريبية لـ Speech 2.8 HD Sync
- مساحة عمل تجريبية لـ Speech 2.8 Turbo Sync
- مساحة عمل تجريبية لـ Speech 2.8 HD Async
- مساحة عمل تجريبية لـ Speech 2.8 Turbo Async
مساحة العمل التجريبية لـ Novita
الخطوة 2: احصل على مفتاح واجهة برمجة التطبيقات (API Key) الخاص بك
- سجل في حساب Novita AI (يوجد مستوى مجاني متاح)
- انتقل إلى قسم مفاتيح واجهة برمجة التطبيقات (API Keys) في لوحة التحكم الخاصة بك
- قم بتوليد مفتاح جديد واحفظه
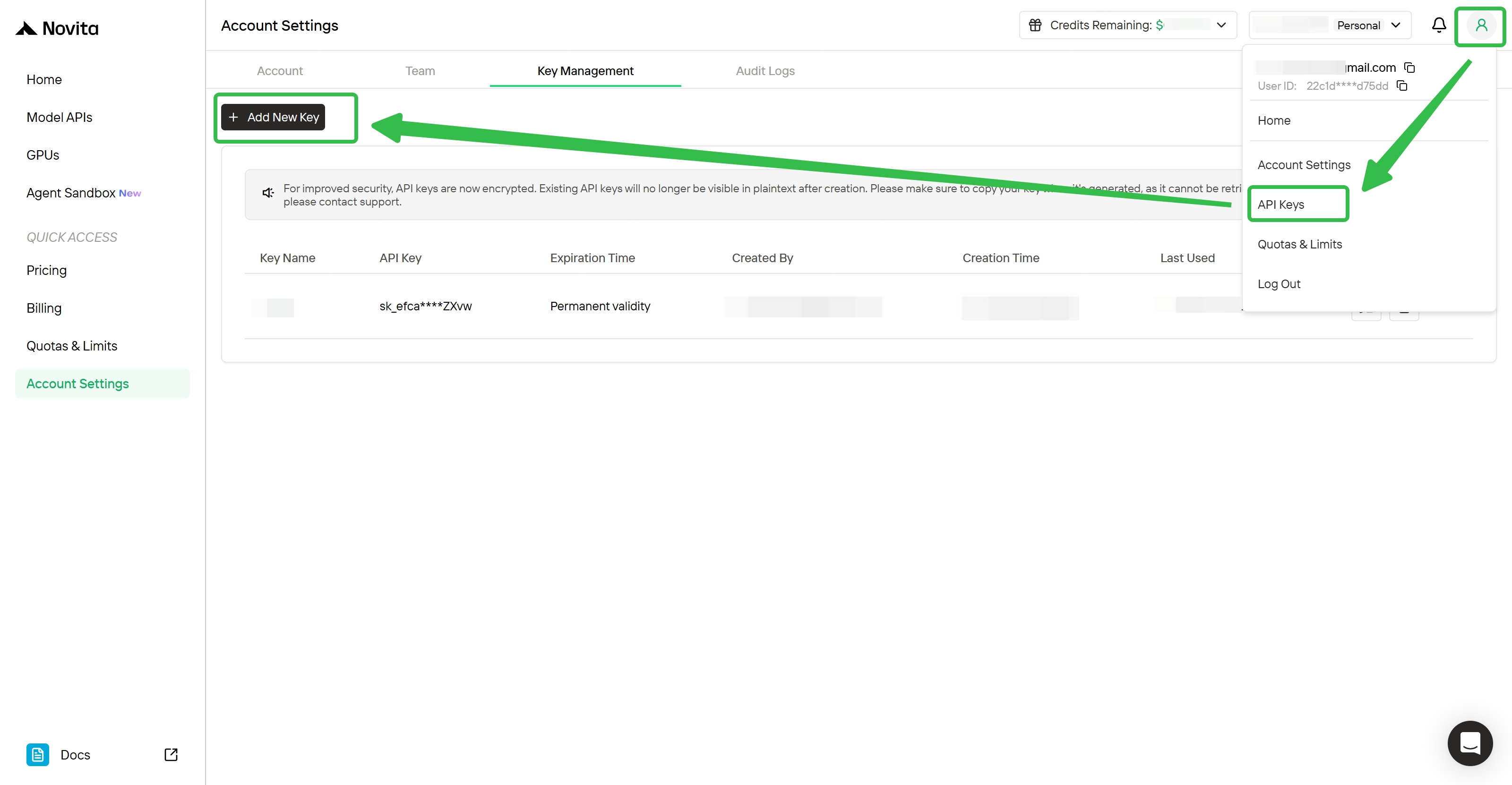
الخطوة 3: قم بأول استدعاء لواجهة برمجة التطبيقات (API) الخاص بك
تدعم سلسلة MiniMax Speech 2.8 وضعين للاستدعاء:
| الوضع | الأفضل لـ | نوع الاستجابة |
| متزامن (Sync) | محادثة في الوقت الفعلي، استجابات فورية | يتم إرجاع الصوت فوراً |
| غير متزامن (Async) | كتب صوتية، محتوى طويل، معالجة دفعية | معرف المهمة (Task ID) → استعلام عن النتيجة |
الخيار أ: استدعاء متزامن (صوت فوري)
استخدم هذا للنصوص القصيرة عندما تحتاج إلى نتائج فورية.
مثال cURL:
curl --request POST \
--url https://api.novita.ai/v3/minimax-speech-2.8-hd \
--header 'Authorization: <authorization>' \
--header 'Content-Type: <content-type>' \
--data '
{
"text": "<string>",
"stream": true,
"voice_modify": {
"pitch": 123,
"timbre": 123,
"intensity": 123,
"sound_effects": "<string>"
},
"audio_setting": {
"format": "<string>",
"bitrate": 123,
"channel": 123,
"force_cbr": true,
"sample_rate": 123
},
"output_format": "<string>",
"voice_setting": {
"vol": 123,
"pitch": 123,
"speed": 123,
"emotion": "<string>",
"voice_id": "<string>",
"latex_read": true,
"text_normalization": true
},
"aigc_watermark": true,
"language_boost": "<string>",
"stream_options": {
"exclude_aggregated_audio": true
},
"timber_weights": [
{
"weight": 123,
"voice_id": "<string>"
}
],
"subtitle_enable": true,
"continuous_sound": true,
"pronunciation_dict": {
"tone": [
{}
]
}
}
'
- مثال Python:
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.8-hd"
payload = {
"text": "<string>",
"stream": True,
"voice_modify": {
"pitch": 123,
"timbre": 123,
"intensity": 123,
"sound_effects": "<string>"
},
"audio_setting": {
"format": "<string>",
"bitrate": 123,
"channel": 123,
"force_cbr": True,
"sample_rate": 123
},
"output_format": "<string>",
"voice_setting": {
"vol": 123,
"pitch": 123,
"speed": 123,
"emotion": "<string>",
"voice_id": "<string>",
"latex_read": True,
"text_normalization": True
},
"aigc_watermark": True,
"language_boost": "<string>",
"stream_options": { "exclude_aggregated_audio": True },
"timber_weights": [
{
"weight": 123,
"voice_id": "<string>"
}
],
"subtitle_enable": True,
"continuous_sound": True,
"pronunciation_dict": { "tone": [{}] }
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
الخيار ب: استدعاء غير متزامن (للنصوص الطويلة)
استخدم هذا للنصوص الطويلة، أو عندما تريد إرسال طلبات متعددة بشكل دفعي.
1. إرسال المهمة
- cURL
curl --request POST \
--url https://api.novita.ai/v3/async/minimax-speech-2.8-hd \
--header 'Authorization: <authorization>' \
--header 'Content-Type: <content-type>' \
--data '
{
"text": "<string>",
"text_file_id": 123,
"voice_modify": {
"pitch": 123,
"timbre": 123,
"intensity": 123,
"sound_effects": "<string>"
},
"audio_setting": {
"format": "<string>",
"bitrate": 123,
"channel": 123,
"audio_sample_rate": 123
},
"voice_setting": {
"vol": 123,
"pitch": 123,
"speed": 123,
"emotion": "<string>",
"voice_id": "<string>",
"english_normalization": true
},
"aigc_watermark": true,
"language_boost": "<string>",
"continuous_sound": true,
"pronunciation_dict": {
"tone": [
{}
]
}
}
'
- Python
import requests
url = "https://api.novita.ai/v3/async/minimax-speech-2.8-hd"
payload = {
"text": "<string>",
"text_file_id": 123,
"voice_modify": {
"pitch": 123,
"timbre": 123,
"intensity": 123,
"sound_effects": "<string>"
},
"audio_setting": {
"format": "<string>",
"bitrate": 123,
"channel": 123,
"audio_sample_rate": 123
},
"voice_setting": {
"vol": 123,
"pitch": 123,
"speed": 123,
"emotion": "<string>",
"voice_id": "<string>",
"english_normalization": True
},
"aigc_watermark": True,
"language_boost": "<string>",
"continuous_sound": True,
"pronunciation_dict": { "tone": [{}] }
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
2. الاستعلام عن الاكتمال
- cURL
curl --request GET \
--url https://api.novita.ai/v3/async/task-result \
--header 'Authorization: <authorization>' \
--header 'Content-Type: <content-type>'
- Python
import requests
url = "https://api.novita.ai/v3/async/task-result"
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.get(url, headers=headers)
print(response.text)
الخطوة 4: استكشف الميزات المتقدمة
بمجرد أن تعمل الأساسيات، جرب هذه الميزات:
- مزج الأصوات: ادمج ما يصل إلى 4 أصوات لإنشاء جرس صوتي فريد باستخدام معامل
timber_weights - مؤثرات صوتية: أضف فلتر
spacious_echoأوroboticعبرvoice_modify.sound_effects - قاموس النطق: عرف قواعد نطق مخصصة لأسماء العلامات التجارية والاختصارات
- وضع التدفق: اضبط
"stream": trueلتسليم الصوت في الوقت الفعلي في التطبيقات التفاعلية - تعديل الصوت: اضبط بدقة المعاملات
pitchوtimbreوintensityفيvoice_modify(نطاق من -100 إلى 100 لكل منها)
الخلاصة
تقدم سلسلة MiniMax Speech 2.8 ترقية ذات معنى لعائلة نماذج تحويل النص إلى كلام (TTS) التي كانت بالفعل من الفئة الأولى. تعالج إضافة علامات النبرة العاطفية ووضع الصوت المستمر اثنين من أكثر نقاط الألم شيوعاً في تركيب الصوت بالذكاء الاصطناعي: جعل الكلام يبدو تلقائياً، والقضاء على الانتقالات غير الطبيعية بين الجمل.
مع توفر أربعة إصدارات على Novita AI — HD و Turbo، كل منهما في وضعي متزامن وغير متزامن — تغطي السلسلة جميع حالات الاستخدام، من الوكلاء الصوتية في الوقت الفعلي إلى إنتاج الكتب الصوتية على نطاق واسع. تظل الأسعار متسقة مع سلسلة 2.6، لذا تحصل على قدرات أكثر بنفس التكلفة تماماً.
إذا كنت تستخدم حالياً Speech 2.6 أو تقيم خيارات تحويل النص إلى كلام (TTS)، فإن سلسلة Speech 2.8 هي ترقية مباشرة. جرّبها في مساحة العمل التجريبية لـ Novita AI أو ابدأ باستخدام واجهة برمجة التطبيقات (API) اليوم.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات (API) البسيطة الخاصة بنا، مع توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.
الأسئلة الشائعة
أي إصدار يجب أن أختار: HD أم Turbo؟
اختر HD عندما تكون جودة الصوت هي الأولوية — كتب صوتية، تعليق صوتي احترافي، محتوى متميز.
اختر Turbo عندما يكون زمن الاستجابة مهماً — وكلاء صوتية، روبوتات محادثة، تطبيقات تفاعلية في الوقت الفعلي. كلا الإصدارين يدعمان مجموعة الميزات الكاملة بما في ذلك علامات النبرة.
متى يجب أن أستخدم الوضع المتزامن مقابل غير المتزامن؟
استخدم المتزامن (Sync) للنصوص القصيرة إلى المتوسطة في الوقت الفعلي (ما يصل إلى 10000 حرف).
استخدم غير المتزامن (Async) للمحتوى الطويل (ما يصل إلى 1000000 حرف) أو سير عمل المعالجة الدفعية.
هل تقدم Novita AI مستوى مجانياً للاختبار؟
نعم. سجل في حساب Novita AI لتحصل على رصيد مجاني، يمكنك استخدامه لاختبار سلسلة Speech 2.8 والنماذج الأخرى في مساحة العمل التجريبية أو عبر واجهة برمجة التطبيقات (API).



