

关键亮点
混元视频 ** 是一款AI文本生成视频工具**,擅长将文本提示转化为电影级画质的视频。
该模型可生成最高 1024x576像素 分辨率、最长 16秒 的视频。
它支持不同级别的GPU,即使是较低显存(最低24GB)也会影响视频质量和生成速度。
混元视频是腾讯开发的一款新颖的开源视频基础模型,旨在根据文本描述生成高质量视频。它整合了数据整理、图像-视频联合模型训练以及高效的基础设施,以促进大规模模型训练与推理。混元视频的目标是弥合闭源与开源视频基础模型之间的差距,让社区能够试验AI驱动的视频创作。
立即在 Novita AI 上开始免费试用。如需集成混元视频 API,请访问我们的开发者文档了解更多详情。
开源可用性
混元视频的与众不同之处在于它是一款 新颖的开源 视频基础模型,这是为了 普及 先进AI视频生成技术的有意之举。腾讯发布该模型的代码和权重,旨在 缩小 专有闭源方案与开源社区之间的差距。
仅限文本生成视频
混元视频作为文本生成视频(T2V)模型发布。图像生成视频模型的发布已被推迟,预计后续可能会发布。
硬件要求
综合考虑,硬件要求对个人用户而言相对较高,但与某些竞品AI视频生成模型相比 更为亲民。
基本要求:
• 显存:最低24GB,推荐45GB,最佳80GB
• GPU:支持CUDA的NVIDIA显卡
• 内存:32GB
• 存储:100GB可用空间
分辨率与显存对应关系:
• 720p(1280x720):60GB显存
• 544p(960x544):45GB显存
模型架构与关键创新
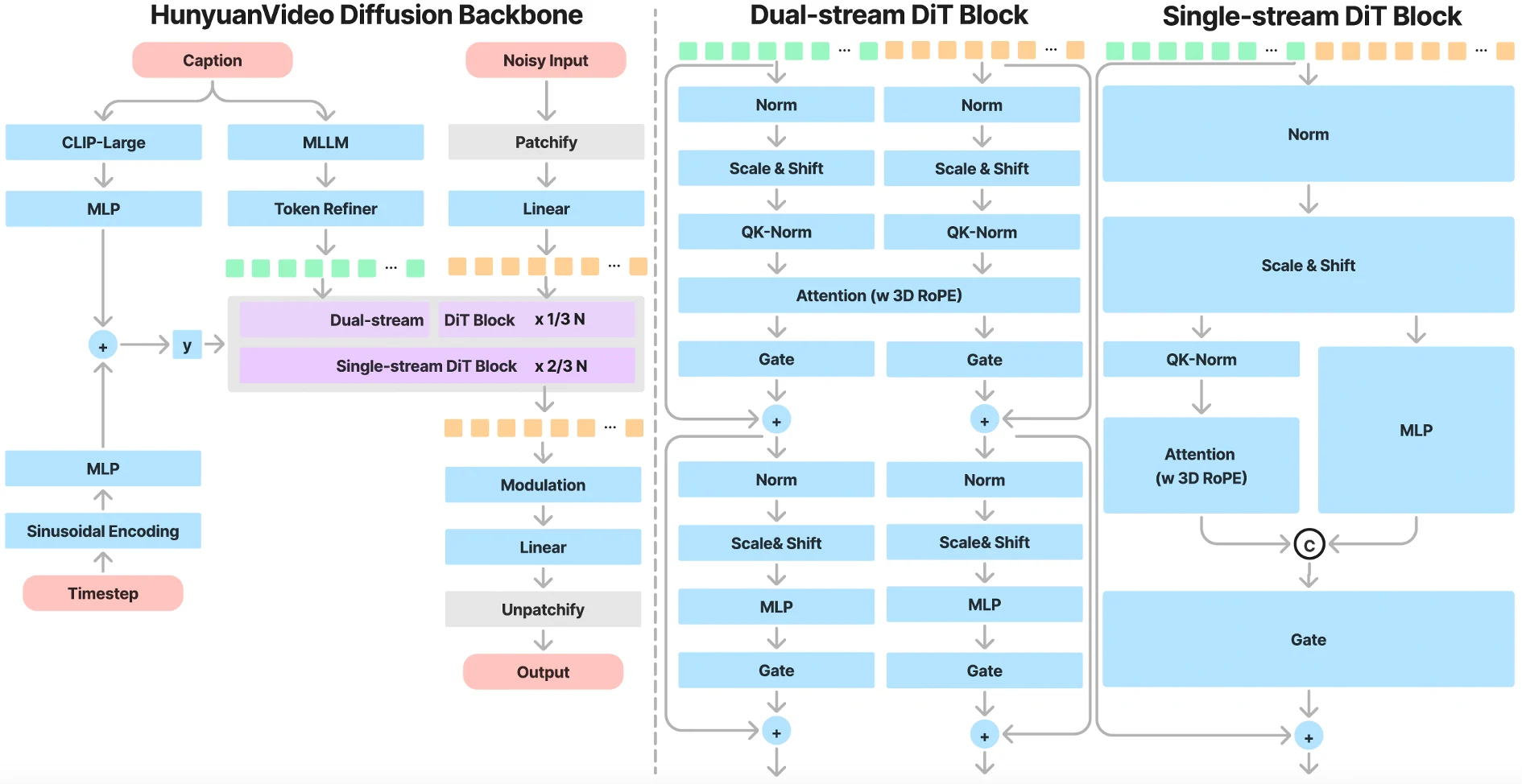
统一生成框架
• 采用先进的Transformer与全注意力机制
• 独特的“双流到单流”设计
• 无缝融合视频与文本处理
来自Hunyuan
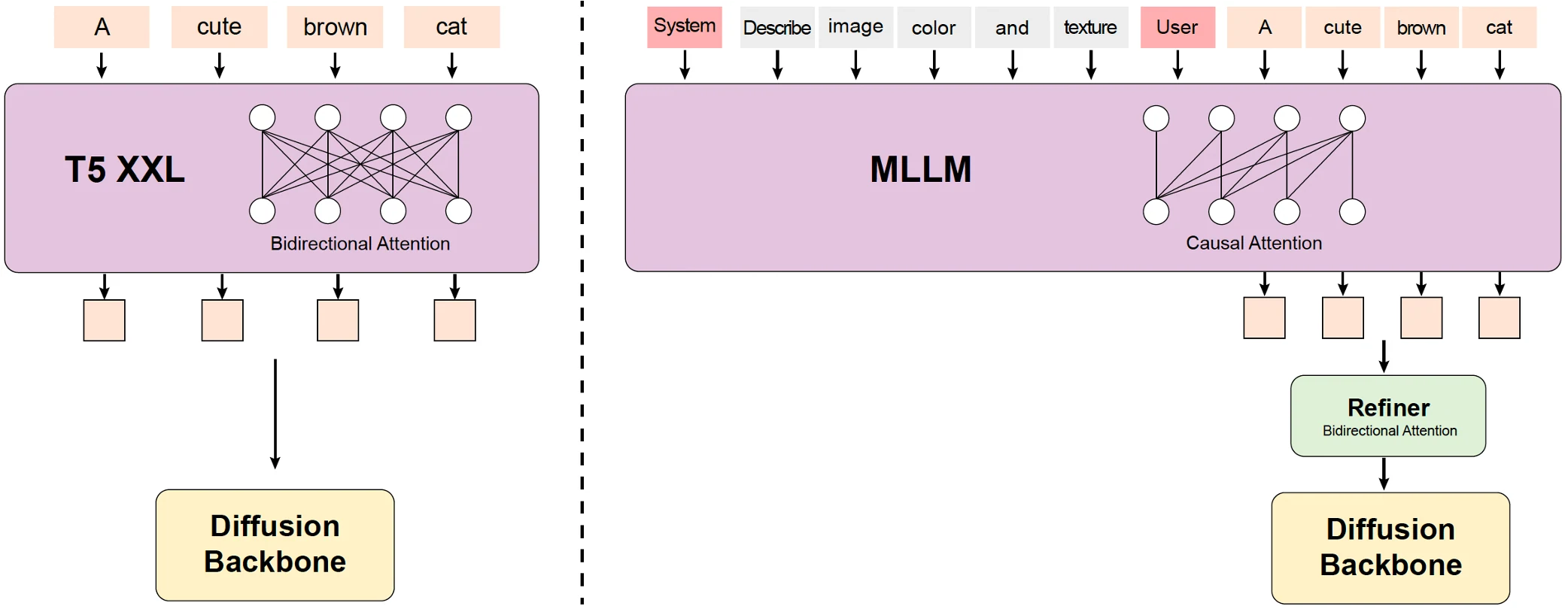
增强的语言理解
• 基于多模态大语言模型(MLLM)
• 仅解码器结构擅长细节理解
• 相比传统CLIP/T5模型具有更优的图像-文本对齐能力
来自Hunyuan
高效的视频处理
• 先进的3D VAE与CausalConv3D
• 优化的潜在空间压缩
• 在原始分辨率/帧率下保持高质量

来自Hunyuan
智能提示系统
• 内置提示优化引擎
• 两种模式:普通(基础)与大师(详细)
• 自动重新格式化用户输入以获得最佳结果
对比评测
VBench 是一套稳健且全面的基准测试套件,专为评估视频生成模型而设计。它将“视频生成质量”分解为层次化、解耦且具体的维度,每个维度都配有量身定制的提示和评估方法。主要评估指标包括:
- 大幅度运动生成
- 人工制品
- 像素级稳定性
- 身份一致性
- 物理合理性
- 平滑度
- 综合图像质量
- 场景生成质量
- 风格化能力
- 单物体准确度
- 多物体准确度
- 空间位置准确度
- 相机控制
- 动作指令跟随
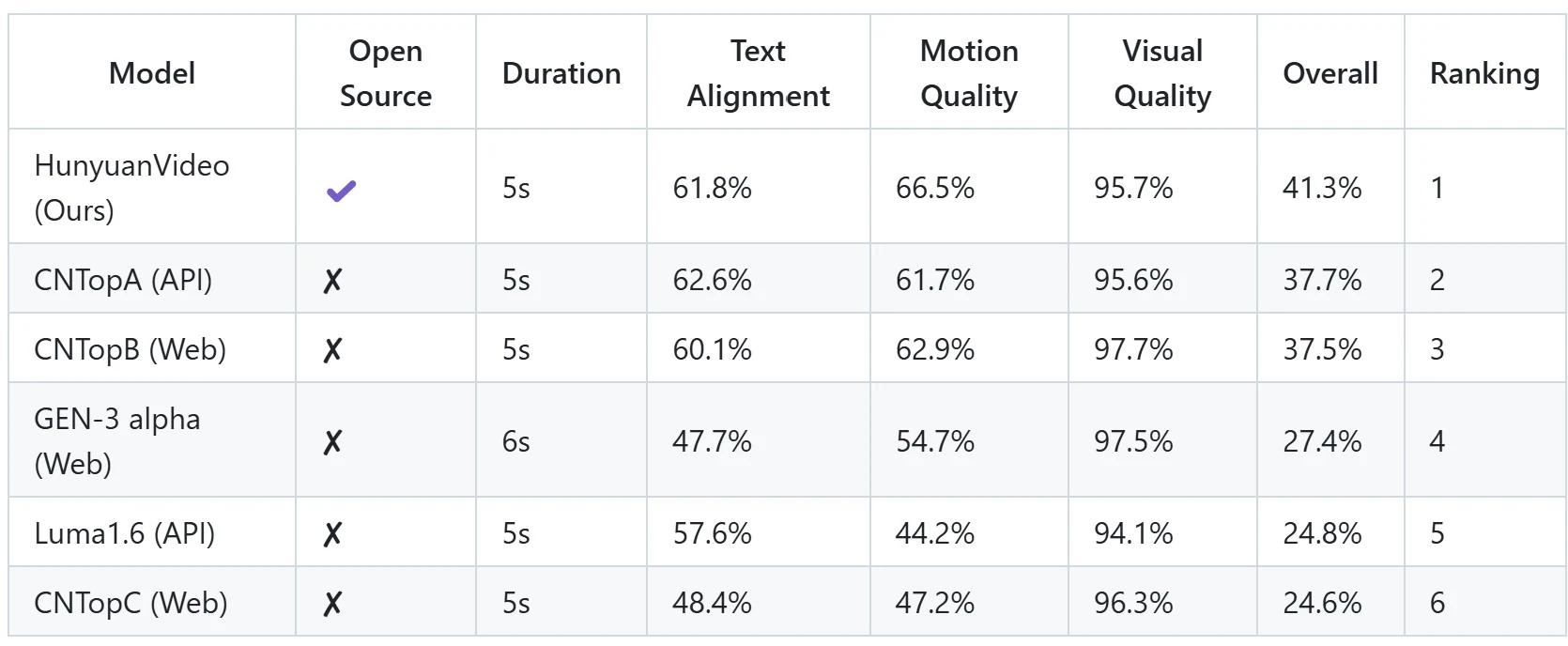
目前尚无权威的 V-Bench 对混元视频的评测,只有混元团队在 GitHub 上自行进行的实验。以下是他们的测试方法:
为了评估混元视频的性能,他们从闭源视频生成模型中选取了五个强基线。他们使用了1533个文本提示,用混元视频单次运行生成了相同数量的视频样本。为保证公正性,他们只运行一次推理,避免筛选结果。在与基线方法对比时,所有选定模型均使用默认设置,以保持视频分辨率一致。视频从三个标准进行评估:文本对齐、运动质量和视觉质量。超过60名专业评估人员参与了评估。混元视频在整体表现上最佳,尤其是在运动质量方面。请注意,此评估使用的是混元视频的高质量版本,与当前发布的快速版本有所不同。
来自Hunyuan
应用场景
- 社交媒体、营销或娱乐的内容创作。
- 想法或概念的可视化。
- 用于教学或说明的教育视频。
- 艺术项目的创意实验。
- 产品演示、创意场景、角色动画以及推广内容。
混元视频站在AI视频生成的前沿,提供了一个强大的开源解决方案,将文本描述转化为逼真、高质量的视频内容。其突破性的架构、高效的训练方法以及对视频质量的专注,使其成为学术研究人员和创意专业人士的宝贵工具。作为一个由社区积极参与支持的开源平台,混元视频已准备好引领AI视频生成技术的下一波创新。
Novita AI 是一站式云平台,助力您的 AI 梦想。集成 API、无服务器、GPU 实例——您需要的经济高效工具。无需操心基础设施,免费开始,将您的 AI 愿景变为现实。



