

核心亮点
重排序模型:重排序模型通过基于精确相关性评分智能重新排序候选文档,优化搜索结果质量,确保用户首先看到最相关的信息。
BAAI/bge-reranker-v2-m3:bge-reranker-v2-m3 模型提供卓越的跨语言重排序能力,支持 18+ 种语言,擅长处理查询-文档对以实现准确的相关性评估。其精确性和多语言支持使其成为高质量搜索体验不可或缺的工具。
强大的 bge-reranker-v2-m3 模型现已在 Novita AI 上线,提供经济高效的重排序解决方案。立即在 Novita AI 开始免费试用!
重排序是现代搜索系统的基石,通过复杂的相关性分析,使应用能够提供高度相关的结果。本指南将深入探讨什么是重排序器(重排序模型)、它们为何对搜索质量至关重要,以及 BAAI/bge-reranker-v2-m3 如何提升搜索能力,从而驱动卓越的用户体验。
理解重排序器
重排序器是一种专门的 AI 模型,通过评估查询与候选文档之间的语义相关性,来优化和重新排序搜索结果。与传统检索系统注重速度和召回率不同,重排序器通过计算查询-文档对的详细相关性评分,优先保证精确性。
在现代 AI 应用中,重排序器在 RAG(检索增强生成) 系统中扮演着尤为关键的角色,其中检索文档的质量直接影响最终生成的回答。重排序阶段充当精确过滤器,确保只有最相关的文档进入内容生成阶段。
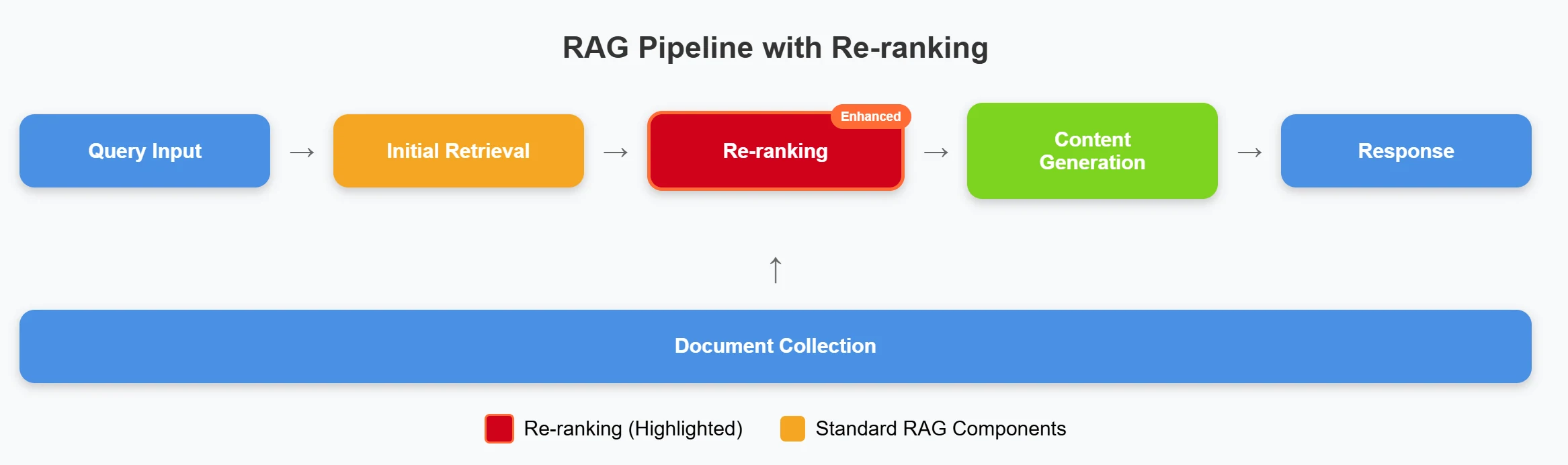
现代信息检索系统通常采用两阶段架构,如上图所示。第一阶段使用初始快速检索方法(如双塔模型、BM25 或向量数据库)从海量集合中快速筛选候选文档。第二阶段则利用重排序器对这些候选结果进行细粒度排序,专注于精确的相关性判断。
重排序器采用交叉编码器架构,将查询和文档联合处理,相比传统检索方法能够实现更深层次的交互建模。这种架构使重排序器能够识别出关键词匹配可能遗漏的复杂语义关联、同义词和层级关系。
重排序器的应用场景
重排序器在多种应用场景中表现出色,这些场景中语义理解和精确排序至关重要:
关键领域应用
• 医疗信息系统:检索相关医学文献,准确性关乎生命安全
• 法律文档检索:为法律专业人士查找精确的判例和法规
• 科学研究:从数千篇论文中找出最相关的研究
AI 驱动系统
• 问答系统:在 RAG 系统中,重排序器确保选择语义最相关的文档作为答案生成的上下文,直接影响回答质量和准确性
• 推荐系统:根据用户偏好对候选项目进行相关性排序,提升参与度和个性化
企业解决方案
• 企业搜索:大型组织使用重排序器优化海量知识库中的文档检索,使信息发现更高效、更准确
• 搜索引擎:对搜索结果进行二次排序,提升超越传统关键词匹配的相关性和用户满意度
跨平台应用
• 多语言平台:有效处理跨语言检索场景,在不同语言间提供一致的搜索质量
了解 BAAI/bge-reranker-v2-m3
BAAI/bge-reranker-v2-m3 是由北京智源人工智能研究院(BAAI)开发的轻量级多语言重排序模型。作为 BGE(Beijing General Embedding)系列的一部分,该模型专门针对多语言重排序任务进行了优化。
主要特性:
- 轻量设计:5.68 亿参数,部署高效
- 多语言支持:18+ 种语言,具备跨语言能力
- 快速推理:毫秒级响应时间
- 易于集成:提供多种 API 和库
技术规格:
- 架构:交叉编码器序列分类
- 输入格式:[查询文本,文档文本]
- 最大长度:512 个 token
- 输出:直接相关性分数,支持可选归一化
- 加速:支持 fp16/bf16 的 GPU 推理
支持的语言:英语、中文、日语、韩语、西班牙语、法语、德语、俄语、阿拉伯语、印地语、孟加拉语、波斯语、芬兰语、印度尼西亚语、泰语、泰卢固语、斯瓦希里语、约鲁巴语
该模型在包括 bge-m3-data(多语言检索)、Quora 训练数据(问答对)和 FEVER 训练数据(事实核查)在内的多样化数据集上进行了训练,确保在各类领域和用例中均有稳健表现。
llama-index.
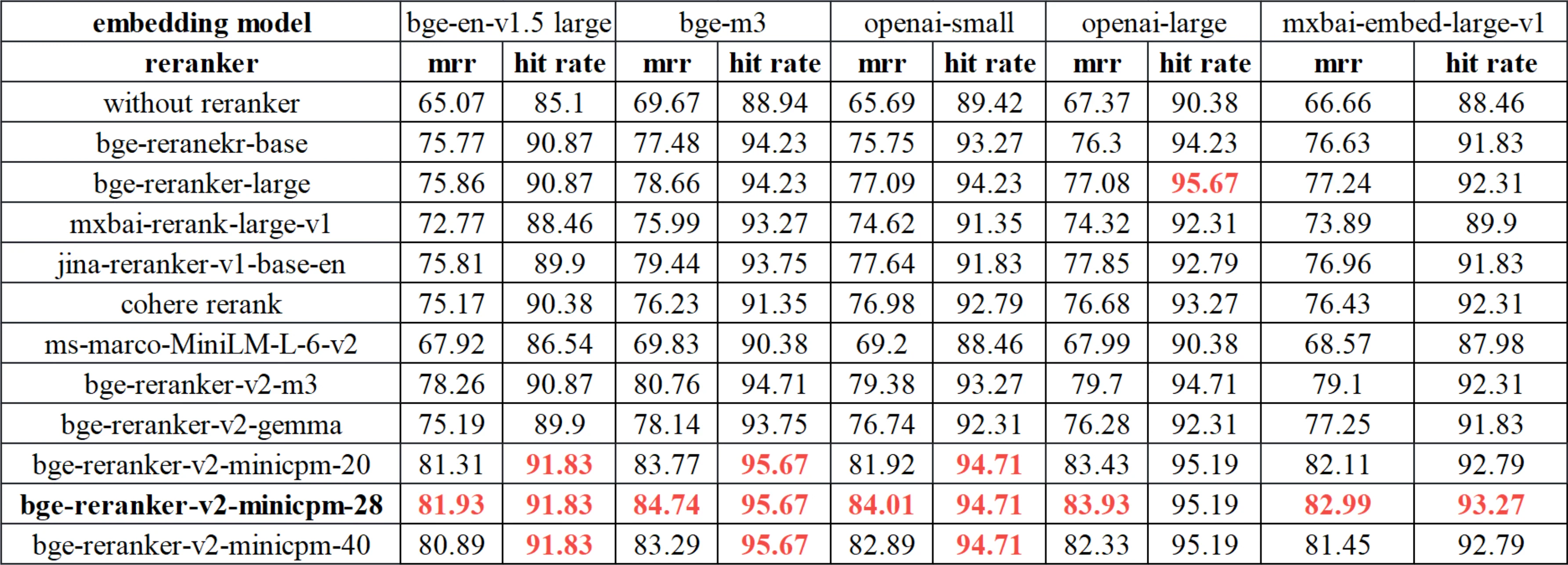
BEIR.

对来自 bge-en-v1.5 large 的前 100 个结果进行重排序。

对来自 e5 mistral 7b instruct 的前 100 个结果进行重排序。
CMTEB-retrieval.

对来自 bge-zh-v1.5 large 的前 100 个结果进行重排序。
miracl(多语言).

对来自 bge-m3 的前 100 个结果进行重排序。
如何在 Novita AI 上访问 BAAI/bge-reranker-v2-m3
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。
第 1 步:登录并访问模型控制台
登录您的账户并访问 模型控制台。
第 2 步:选择您的模型并开始免费试用
浏览可用选项,搜索适合您需求的模型。
第 3 步:获取您的 API 密钥
为了进行 API 身份验证,我们将为您提供一个新的 API 密钥。进入“设置”页面,您可以按照图中所示复制 API 密钥。
第 4 步:安装 API
使用适合您编程语言的包管理器安装 API。
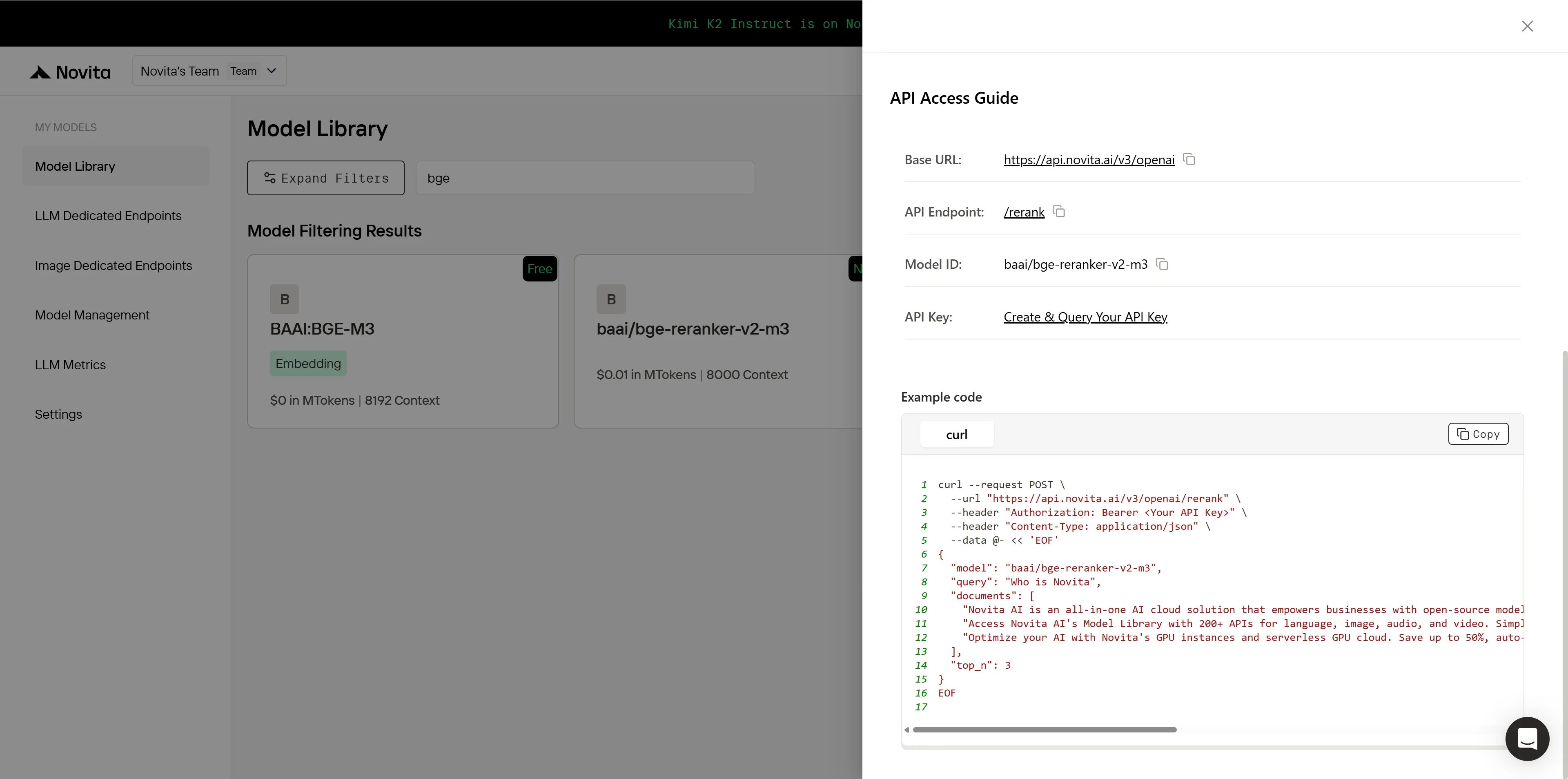
安装完成后,将必要的库导入到您的开发环境中。使用您的 API 密钥初始化 API 以开始与 Novita AI 的重排序服务交互。以下示例演示了如何使用重排序 API。
curl --request POST \
--url "https://api.novita.ai/v3/openai/rerank" \
--header "Authorization: Bearer <Your API Key>" \
--header "Content-Type: application/json" \
--data @- << 'EOF'
{
"model": "baai/bge-reranker-v2-m3",
"query": "Who is Novita",
"documents": [
"Novita AI is an all-in-one AI cloud solution that empowers businesses with open-source model APIs, serverless GPUs, and on-demand GPU instances. Drive innovation and gain a competitive edge with the power of Novita AI.",
"Access Novita AI's Model Library with 200+ APIs for language, image, audio, and video. Simplify AI deployment with powerful, scalable solutions.",
"Optimize your AI with Novita's GPU instances and serverless GPU cloud. Save up to 50%, auto-scale, and access high-capacity storage for global deployment."
],
"top_n": 3
}
EOF
注册后,Novita AI 将提供 0.5 美元信用额度,助您快速上手!
如果免费信用额度用尽,您可以付费继续使用。
重排序器在信息检索和 AI 应用中扮演着关键角色,使系统能够有效理解语义相关性并提高搜索准确性。像 BAAI/bge-reranker-v2-m3 这样的先进模型通过卓越的性能和广泛的语言支持,进一步提升了这些能力,使其成为驱动现代 AI 应用不可或缺的工具。
常见问题解答
BGE Reranker Large 和 BGE Reranker v2 m3 有什么区别?
BGE Reranker Large 基于 xlm-roberta-large,支持中文和英文;而 BGE Reranker v2 m3 基于 bge-m3,具备强大的多语言能力,支持除中文和英文之外的多种语言。
BGE-m3 表现好吗?
是的,BGE-m3 被认为是性能最佳的多语言嵌入模型之一,在多项基准测试中取得了优异结果。它在跨语言检索方面表现出色,并在多种语言上提供了强劲的性能。
什么是 BGE-m3?
BGE-m3(BAAI General Embedding Multilingual-3)是由 BAAI 开发的多语言嵌入模型,支持超过 100 种语言。它被设计用于各种任务,包括文本检索、语义相似度和跨语言应用。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。



