What Are Large Language Model Settings: Temperature, Top P And Max Tokens

This article provides an overview of the configuration settings of large language models (LLMs), delving into the advantages and disadvantages of large context windows. It also offers practical examples illustrating how adjusting these settings affects LLM output across various tasks.
Introduction
Large language models rely on probabilities to determine the most probable subsequent token or word based on their training data, prompts, and settings. Previous discussions have highlighted how prompting techniques can instill human-like reasoning in LLMs, while techniques like Retrieval Augmented Generation enhance their capabilities by granting access to external knowledge sources.
Nevertheless, tweaking LLM settings or parameters can significantly impact the final output regardless of the provided context and prompts. Mastering these settings is crucial for effectively leveraging large language models and guiding them towards desired behaviors. In this article, we explore fundamental LLM parameters such as temperature, top P, max tokens, and context window, elucidating how they influence model output.
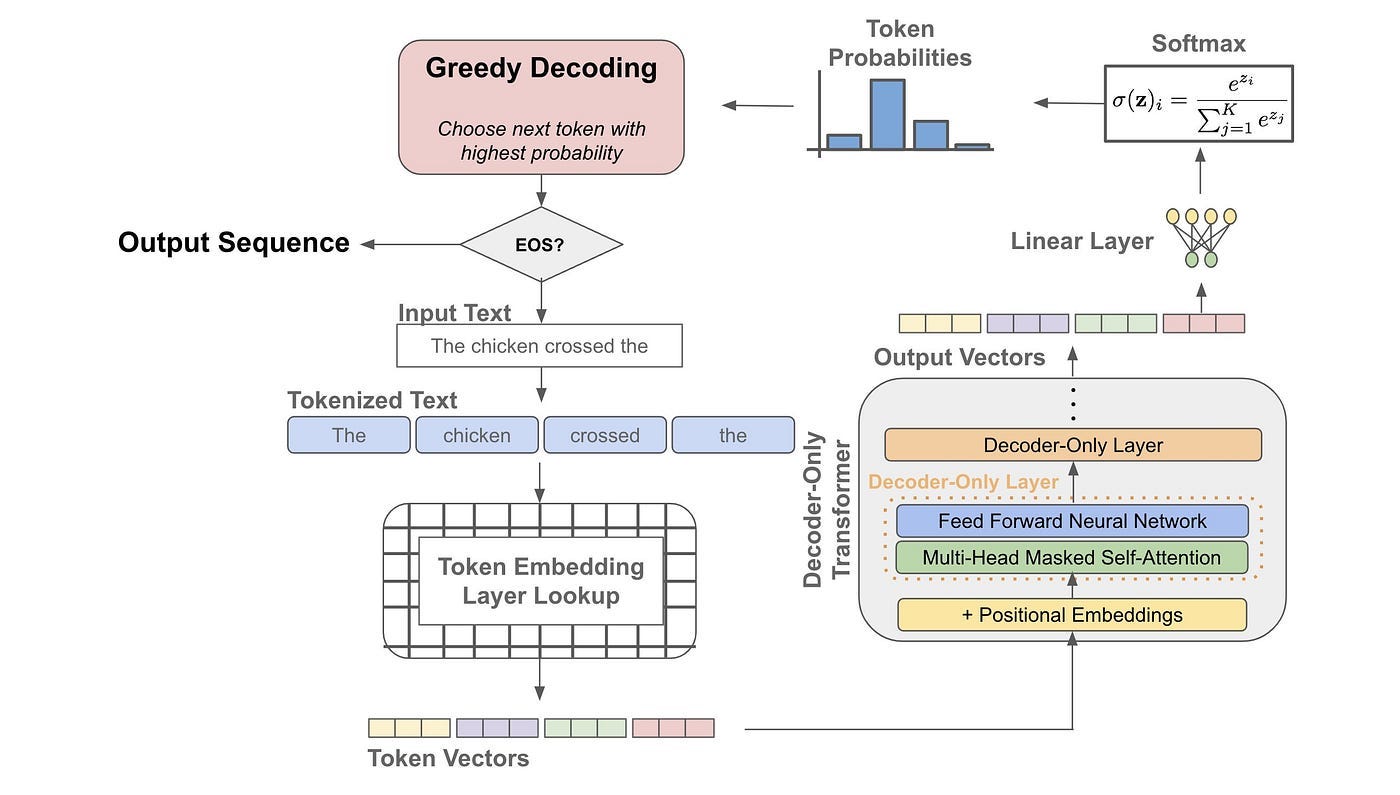
What is LLM Temperature?

In simple terms, temperature is a parameter that ranges from 0 to 1, determining the level of randomness in the responses generated by a large language model (LLM). Higher temperatures lead to more diverse and creative outputs, while lower temperatures result in more conservative and predictable responses.
When the temperature is set to zero, an LLM will consistently produce the same output given the same prompt. Increasing the temperature enhances the model’s creativity, providing a broader range of outputs. However, excessively high temperatures can lead to outputs that lack coherence or meaning.
Default temperature settings vary across different LLMs, depending on factors such as the type of model and whether it’s accessed via API or a web interface. For instance, discussions about ChatGPT-3.5 and 4 commonly mention default temperature settings around 0.7 to 0.8, although precise values are often not disclosed.
Temperature Settings
The temperature parameter is a numerical value typically ranging between 0 and 1, although it can sometimes exceed this range, that influences the degree of risk-taking or conservatism in the model’s word choices. It adjusts the probability distribution of the next word.
Here’s a breakdown of the different temperature parameters for large language models:
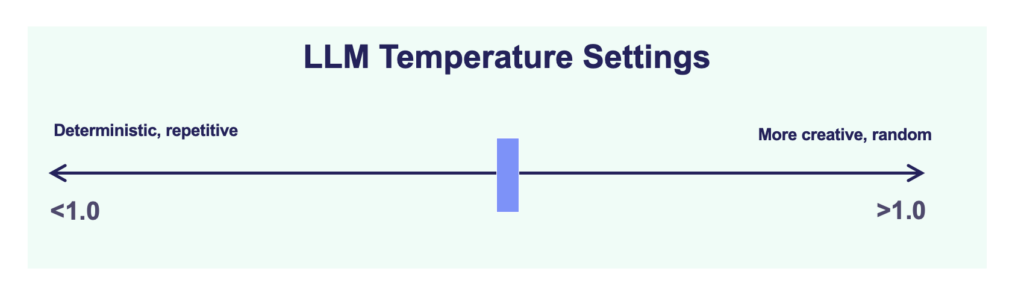
Low Temperature (<1.0) — When set to a value below 1, the model’s output tends to be more deterministic and repetitive. Lower temperatures prioritize the selection of the most likely next word, reducing output variability. This can be advantageous for obtaining predictable and conservative responses, but it may also yield less creative or diverse text, giving the model a more robotic tone.
High Temperature (>1.0) — Setting the temperature above 1 increases randomness in the generated text. The model is more inclined to choose less probable words as the next word in the sequence, resulting in more varied and sometimes more creative outputs. However, this heightened randomness may lead to errors or nonsensical responses, as the model is less bound by the probability distribution of its training data.
Temperature of 1.0 — This is often the default setting, aiming to strike a balance between randomness and determinism. The model generates text that is neither excessively predictable nor too random, drawing on the probability distribution learned during its training.
Use Cases for LLM Temperature Modeling
Fine-tuning the temperature parameter in modeling involves striking the right balance between randomness and determinism, a critical aspect in applications where the quality of generated text profoundly impacts user experience or decision-making processes.
In practical scenarios, the choice of temperature setting depends on the desired outcome. Tasks demanding creativity or diverse responses may benefit from higher temperatures, while those requiring accuracy or factual correctness typically favor lower temperatures.
Here are some common use cases and recommended temperature settings for LLM models:
Creative Writing — Employing higher temperatures can stimulate creativity and yield a variety of outputs, making it beneficial for overcoming writer’s block or generating innovative content ideas.
Technical Documentation — Lower temperatures are preferred to ensure the precision and reliability of content, crucial in technical documentation where accuracy and consistency are paramount.
Customer Interaction — Adjusting the temperature allows for tailoring responses in chatbots or virtual assistants to align with the organization’s brand and tone, as well as meeting the preferences of the target audience.
What is Top P
Top P, also known as nucleus sampling, is another parameter that influences the randomness of LLM output. This parameter determines the threshold probability for including tokens in a candidate set used by the LLM to generate output. Lower values of this parameter result in more precise and fact-based responses from the LLM, while higher values increase randomness and diversity in the generated output.
For instance, setting the top P parameter to 0.1 leads to deterministic and focused output from the LLM. On the other hand, increasing the top P to 0.8 allows for less constrained and more creative responses.
What is Max Tokens
While temperature and top P regulate the randomness of LLM responses, they don’t establish any constraints on the size of the input accepted or the output generated by the model. In contrast, two other parameters, the context window and max tokens, directly affect LLM performance and data processing capabilities.
The context window, measured in tokens (which can be whole words, subwords, or characters), determines the number of words an LLM can process at once. On the other hand, the max tokens parameter sets the upper limit for the total number of tokens, encompassing both the input provided to the LLM as a prompt and the output tokens generated by the LLM in response to that prompt.
Understanding Context Window
In general, the size of the context window in large language models (LLMs) determines the amount of information the model can retain and utilize when generating output. A larger context window enables the LLM to remember more context, leading to more coherent and accurate responses. However, if the input exceeds the context window, the model starts to “forget” earlier information, potentially resulting in less relevant and lower-quality output.
Additionally, the size of the context window places constraints on prompt engineering techniques. Methods like Tree-of-Thoughts or Retrieval Augmented Generation (RAG) require large context windows to be effective, as they rely on feeding the model with sufficient information to generate high-quality responses.
As LLMs evolve, their context windows also expand, allowing them to process more tokens at once. For example, while GPT-4 has a context limit of 8,192 tokens, newer models like GPT-4 Turbo support a context window of up to 128K tokens. Similarly, Anthropic has increased the context limit in the Claude tool from 9,000 tokens to 200K tokens in the Claude 2.1 version.
When does a large context window not result in better output?
While a larger context window enables LLMs to process longer inputs, leading to potentially more relevant responses, expanding context limits isn’t universally advantageous. There are several drawbacks to consider.
Firstly, larger input datasets require more time for LLMs to generate responses. The increased computational complexity of processing larger context windows further exacerbates this issue.
Secondly, the computational costs associated with larger context windows escalate proportionally.
Moreover, research by Liu et al. (2023) highlights another challenge: large language models often struggle to effectively access information within long input contexts. Their study revealed that LLMs achieve optimal performance when relevant information is situated either at the beginning or the end of the input. Conversely, utilizing information from the middle of a lengthy context leads to decreased model performance.
Other LLM Settings
Several other settings can influence the output of language models, including stop sequences, frequency penalties, and presence penalties.
Stop sequences
Stop sequences dictate when the model should halt output generation, enabling control over content length and structure. For instance, when prompting the AI to compose an email, setting “Best regards,” or “Sincerely,” as the stop sequence ensures that the model stops before the closing salutation, resulting in a concise and focused email. Stop sequences prove valuable for generating output expected to follow a structured format, such as emails, numbered lists, or dialogue.
Frequency Penalty
Frequency penalty is a setting that discourages repetition in generated text by penalizing tokens based on their frequency of appearance. Tokens that occur more frequently in the text are less likely to be used again by the AI.
Presence Penalty
The presence penalty operates similarly to the frequency penalty but applies a flat penalty to tokens based on whether they have appeared in the text or not, rather than penalizing them proportionally.
Import Character(optional)
some LLMs have their special settings, for example, import character. By importing character cards, you can chat with your favorite characters, no matter who they are.
How to Adjust LLM Settings?
As demonstrated earlier, adjusting parameters like temperature, top P, and max tokens can help fine-tune LLMs to produce more relevant and accurate results. Lowering the temperature or top P to values like 0.1 or 0.2 reduces randomness, yielding more focused answers suitable for tasks such as code generation or data analysis scripting. Conversely, increasing the temperature or top P parameters to around 0.7 or 0.8 encourages more creative and diverse output, ideal for creative writing or storytelling. It’s generally advised to modify either the temperature or top P parameters but not both simultaneously.
Meanwhile, altering the max tokens parameter allows customization of the length of LLM output. This flexibility proves beneficial when tailoring LLMs to generate either short-form responses for chatbots or longer-form content for articles. Additionally, adjusting the max tokens parameter can be useful in scenarios like code generation for software development or summarizing longer documents.
Conclusion
In summary, gaining proficiency in settings such as temperature, top P, maximum length, and others is crucial when utilizing language models. These parameters enable precise management of the model’s output, tailoring it to suit particular tasks or applications. They govern factors such as response randomness, length, and repetition frequency, all of which contribute to enhancing interactions with AI.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
What is the difference between LLM and GPT
LLM Leaderboard 2024 Predictions Revealed
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available