Mastering vLLM Mixtral: Expert Tips for Success

Unlock the secrets of vLLM Mixtral mastery with expert tips for success. Elevate your expertise with our helpful advice.
Key Highlights
- With Python code and the inference engine called vLLM, vLLM Mixtral works well, ensuring things run smoothly without hiccups.
- The newest update of vLLM Mixtral brings in some fresh models and cool features that make it even more effective and efficient than before.
- When put to the test alongside other models, its ability to handle lots of data while keeping quality high is impressive.
- By picking up some smart tips from experts on using vLLM Mixtral best, developers can get great at generating text for whatever they need.
Introduction
vLLM is a quick and easy-to-use library for LLM inference. Mixtral models is a top language tool from Mistral AI specialises in natural language processing. It generates high-quality text for tasks such as coding. vLLM Mixtral is known for accuracy and is favoured for delivering sensible and precise results. In this blog, we’ll delve into what makes vLLM Mixtral unique and provide insider tips for maximizing its potential. Whether you’re exploring its features or setting it up smoothly, we’re here for you every step of the way.
Understanding vLLM Mixtral: An Overview
vLLM Mixtral combines vLLM’s system with Mistral’s Mixtral tech to enhance computer language understanding. Ideal for various writing tasks, from answering questions naturally to crafting code or stories, vLLM Mixtral stands out for its contextual adaptability and top-tier performance across diverse language processing needs.
What are vLLM and Mixtral?
Large language models (LLMs) have transformed different fields today. Yet, the complexity lies in implementing these models in practical scenarios due to intensive computational requirements. vLLM, short for Virtual Large Language Model, is a dynamic open-source platform that effectively assists LLMs in inference and model deployment.
Mixtral developed by Mistral is an example of such a model. Mixtral produces accurate and natural-sounding answers, which is valuable for enhancing chatbot interactions and content creation.
How does vLLM Work?
It utilizes a unique attention algorithm called PagedAttention, which efficiently handles attention keys and values by segmenting them into smaller, more manageable portions. This method decreases the memory usage of vLLM and enables it to achieve higher throughput than conventional LLM serving techniques.
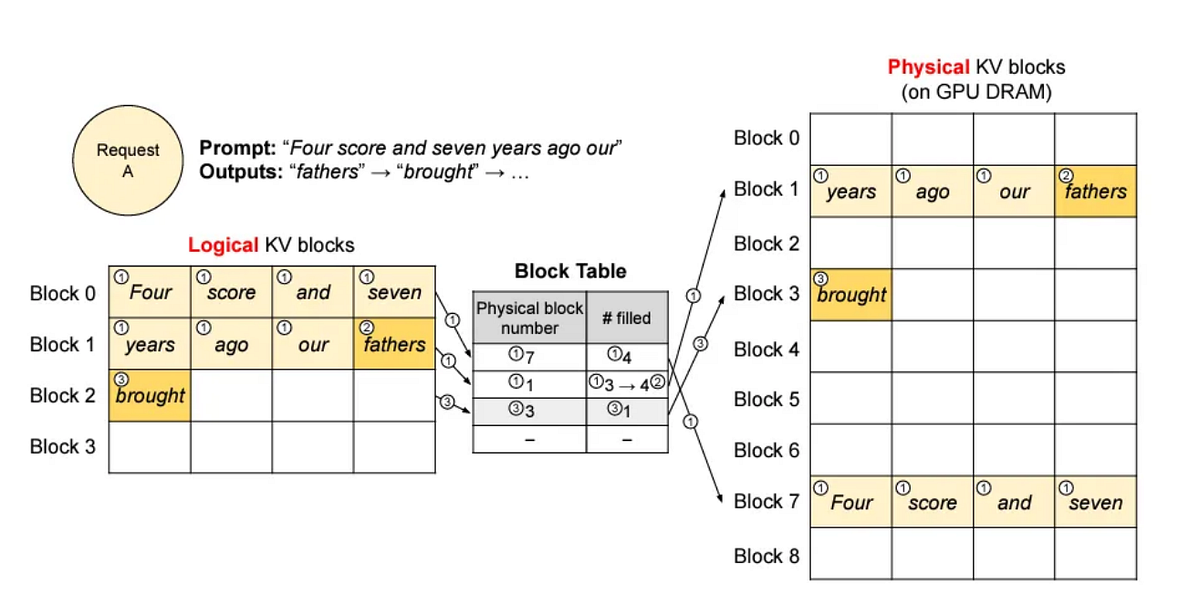
Key Features and Capabilities
Comparison with Other Models
The model has excellent features that make it outperform GPT3.5 and Llama 2. Let’s dive into what makes it stand out:

- Python code can be used when generating through flexible API.
- vLLM Mixtral has billions of parameters to produce high-quality text.
- With an active community and ample documentation, users can easily access support and share experiences.
- The tool excels in memory management, reducing memory usage when handling large models.
- Easily integrate with various machine learning frameworks and tools, supporting multiple programming languages and environments.
Performance Benchmark
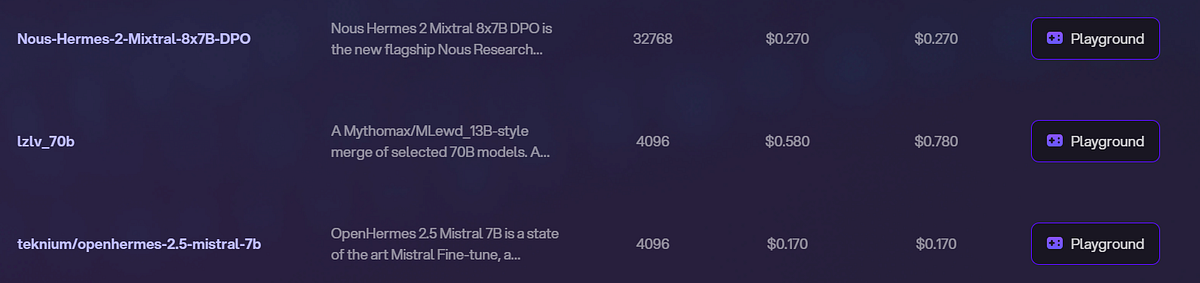
In the following figure, quality is measured versus inference budget tradeoff. Mistral 7B and Mixtral 8x7B belong to a family of highly efficient models.

Mixtral 8x7B is provided by Novita AI, an AI API platform possessing various models. You can view different featured models for reference.

How to Deploy vLLM Mixtral
1. Environment Setup
- Ensure you have Python 3.8 or higher installed.
- Install necessary libraries like vLLM, torch, and transformers.
2. Install Dependencies
pip install torch transformers vllm
3. Clone the Repository (if applicable)
git clone https://github.com/vllm-project/vllm.git
cd vllm
4. Load the Model
Use the following code snippet to load the Mixtral 8x7B model in your Python script.
from vllm import VLLM
model = VLLM.from_pretrained("mixtral-8x7b")
5. Set Up the Inference
Create a function to handle the inference requests:
def generate_response(prompt):
return model.generate(prompt)
6. Run the Server
You can set up a simple server to handle requests.
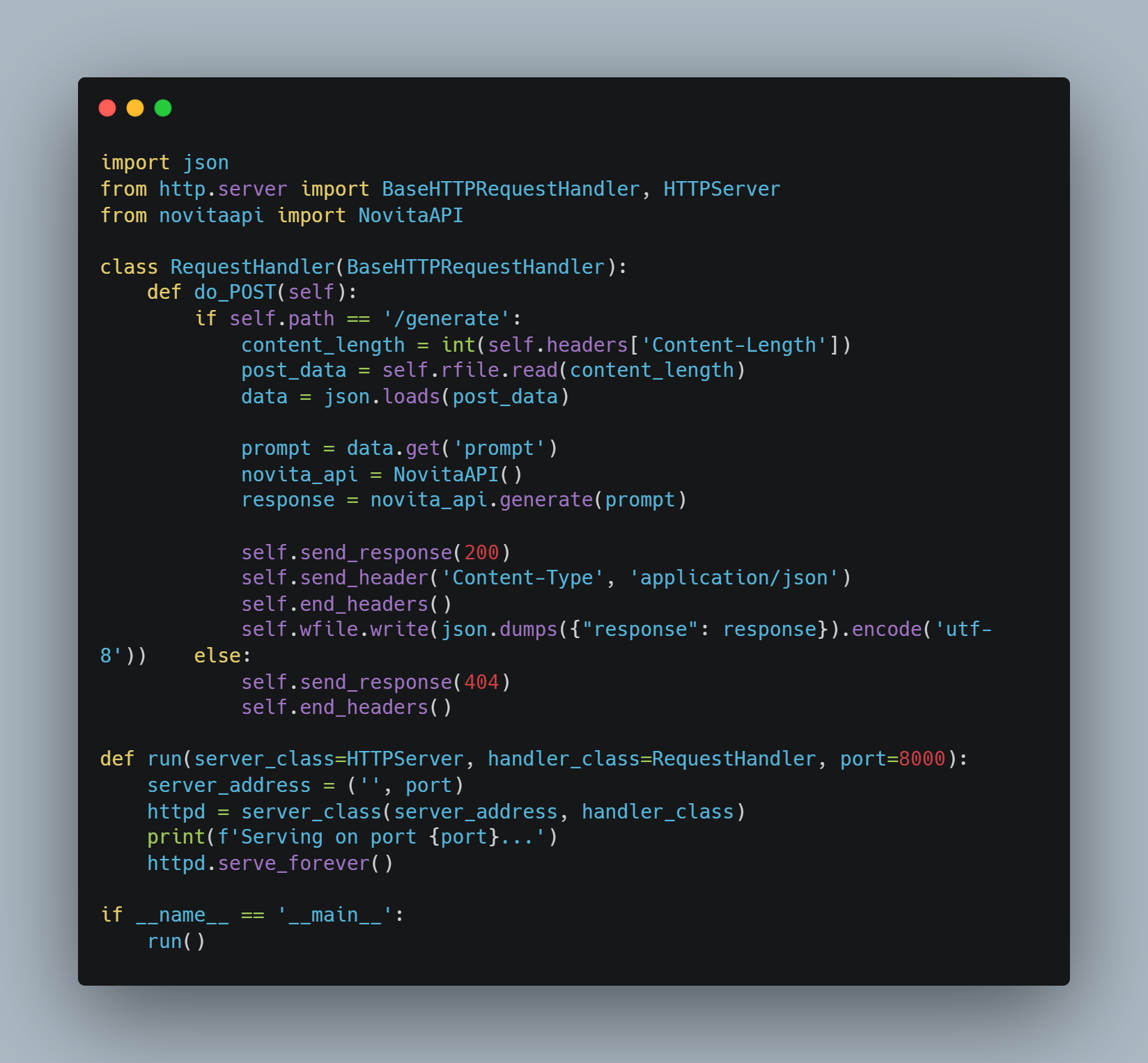
7. Launch the Application
uvicorn your_script_name:app --reload
Optimization for vLLM Mixtral
- Customizing Mixtral: Use Python code to set specific instructions, adjust settings, and train the model for your projects in the right directory.
- Integrating with Other Tools: Combine vLLM Mixtral with tools like Docker to enhance its capabilities and seamlessly integrate it into your workflow.
Getting Started with Novita AI
Deploying a model is challenging. If you don’t want to be bothered. As mentioned before, Novita AI is a user-friendly and affordable platform ready to offer LLM API services for AI needs.
Simple Guide to Using Novita AI LLM API
- Step 1: Visit Novita AI and create an account.

- Step 2: Go to “LLM API Key” to get an API key from Novita AI.

- Step 3: Click on Model API under the “Products” tab. Look for the LLM service in the LLM column or the Hot Column under “Featured AI APIs”.

- Step 4: Enter the LLM service page, and click API Reference.
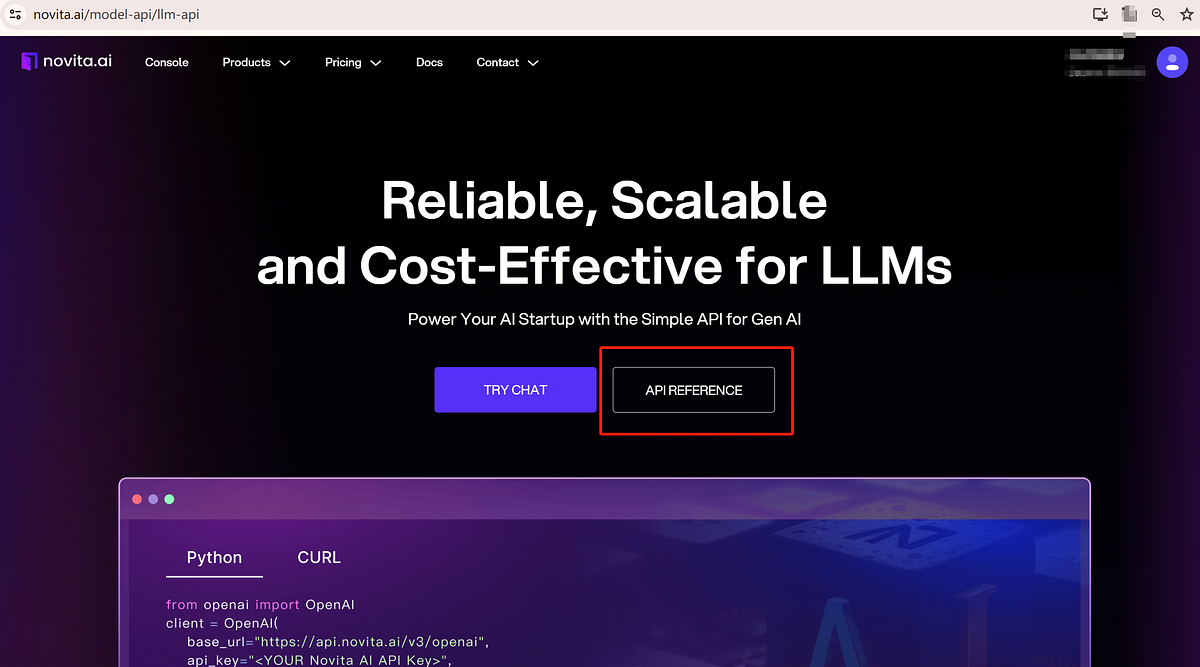
- Step 5: Find the “LLM” in the “LLMs” section. Install the Novita AI API using the programming language’s package manager, then initialize it with your API key to start using the LLM.

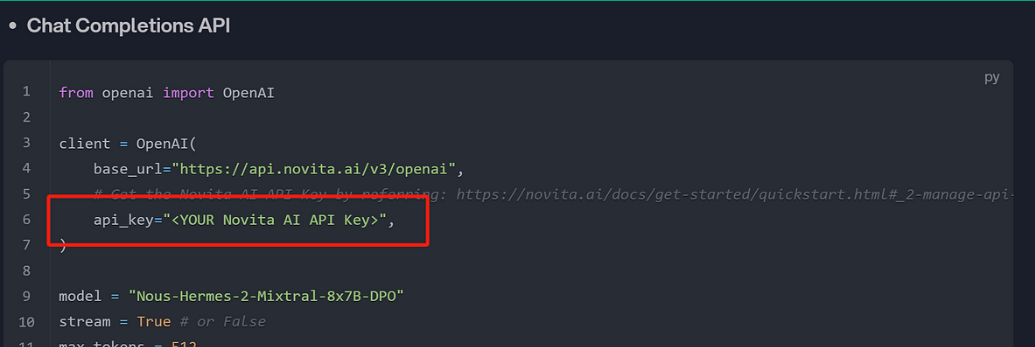
- Step 6: Adjust parameters like in the following image to train models.

- Step 7: Thoroughly test the new LLM API before fully implementing it.
Sample Chat Completions API

Troubleshooting Common vLLM Mixtral Issues
When you’re using the latest version of vLLM Mixtral, sometimes things might not go as planned. Here’s how to fix some of the usual problems:
- For installation hiccups: Check out the guide that came with it. Make sure everything is set up right.
- Running into issues while it’s working: If your experience is laggy or slow, try tweaking a few settings (parameters) and maybe use batch processing to speed things up in the hub.
Installation Errors
When setting up the new model vLLM Mixtral, you may face challenges. Here’s what they are and how to fix them:
- Repository Cloning Error: If cloning the vLLM Mixtral repo from Mistral AI’s GitHub page gives you trouble, make sure you are authorised to do it and double-check that URL.
- Dependency Installation Error: Review the install guide again to ensure everything needed is in place.
- CUDA Configuration Error: Check your system matches what’s required and that all drivers and libraries.
Runtime
When working with vLLM Mixtral, optimize performance by:
- Ensure proper GPU utilization for faster processing.
- Experiment with settings like temperature, and top-p to find the ideal balance of speed and accuracy.
- Use batch processing for multiple tasks to increase efficiency.
Conclusion
Mastering vLLM Mixtral provides an advantage through its advanced technology and features. Thorough understanding, proper configuration, effective issue resolution, task adaptation, technology integration, community engagement, and following proven methods are essential for personal and professional success. Stay updated with expert advice to use vLLM Mixtral.
Frequently Asked Questions
What are common challenges when trying to master vLLM Mixtral?
Customizing the model for specific tasks requires knowledge of transfer learning and fine-tuning techniques. Debugging issues related to model performance or deployment can be challenging.
How to speed up Mixtral inference?
Reduce the model size and increase inference speed by converting weights to lower precision (e.g., from float32 to int8). Process multiple inputs simultaneously to take advantage of parallelism.
What is the throughput of vLLM Mixtral?
Throughput can range from 10 to 30 tokens per second for typical inference tasks. For smaller batch sizes, the throughput might be lower.
Does vLLM support quantization?
Yes, vLLM supports quantization. Quantization can be used to reduce the model size and improve inference speed by representing weights and activations with lower precision (e.g., using int8 instead of float32).
Why is vLLM so fast?
vLLM is designed for high performance in LLM inference and its speed can be attributed to asynchronous execution, quantization support, pipeline parallelism, optimized data loading and more.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading
1.What is vLLM: Unveiling the Mystery
2.Introducing Mistral's Mixtral 8x7B Model: Everything You Need to Know