LLM Foundation: Tokenization&Trianing

Discover the key differences between tokenization and embeddings in Large Language Models (LLMs) like GPT. Learn how tokenization breaks down text into manageable units, while embeddings provide rich vector representations of these tokens. Understanding these processes is crucial for unlocking the potential of LLMs in natural language processing tasks.
Introduction
Tokenization and embeddings are fundamental components of Large Language Models (LLMs) like GPT, crucial for understanding and generating text. Tokenization involves breaking down raw text into manageable units called tokens, while embeddings provide rich vector representations of these tokens. Understanding the differences between tokenization and embeddings is essential for grasping the intricacies of how LLMs process language data.
What is Tokenization
Tokens are frequently discussed in AI research, such as in the Llama 2 paper, where the authors note training on 2 trillion tokens of data. Tokens serve as the fundamental unit, akin to the “atom,” for Large Language Models (LLMs). Tokenization involves translating strings (i.e., text) into sequences of tokens and vice versa.
In the realm of machine learning, a token typically doesn’t equate to a single word. Instead, it could represent a smaller unit, like a character or a portion of a word, or a larger one, such as an entire phrase. The size of tokens varies depending on the tokenization approach used.
Tokenization is typically handled by a component known as a “Tokenizer.” This module operates independently from the Large Language Model and has its own training dataset of text, which may differ entirely from the LLM training data.
Why Does Tokenization Matter?
Tokenization often underlies many peculiarities observed in Large Language Models (LLMs). While some issues might initially appear to stem from the neural network architecture or the LLM itself, they can actually be attributed to tokenization. Here’s a non-exhaustive list of problems that can be traced back to tokenization:
- Inaccuracies in spelling
- Difficulty with simple string processing tasks, like reversing a string
- Lower performance in non-English languages, such as Japanese
- Subpar performance in basic arithmetic operations
- Challenges with coding tasks, like Python, faced by GPT-2
- Issues like trailing whitespace
- Instances where earlier versions of GPT exhibited erratic behavior when prompted about “SolidGoldMagikarp”
- Preference for YAML over JSON in handling structured data
We’ll delve deeper into how tokenization contributes to these issues in this post.
Tokenization Details
Here’s an overview of the steps involved in tokenization. While some of these steps may not be immediately clear, we’ll delve into them in more detail as we proceed through this post.
Pre-Training: Establishing the Vocabulary
- Gather Training Data: Assemble a large corpus of text data that the model will learn from.
- Initial Tokenization: Employ initial tokenization methods to divide the text into fundamental units, such as words, subwords, or characters.
- Vocabulary Creation: Select a tokenization algorithm, like Byte Pair Encoding (BPE), WordPiece, or SentencePiece, to generate a manageable and efficient set of tokens.
- Algorithm Application: Implement the chosen algorithm on the initial tokens to produce a set of subword tokens or characters that capture the linguistic nuances present in the training data.
- ID Assignment: Assign a unique integer ID to each token in the resulting vocabulary.
Real-Time Tokenization Process
- Transform the incoming text into tokens based on the established vocabulary, ensuring comprehensive coverage of all text.
- Associate each token with its respective integer ID as defined in the pre-established vocabulary.
- Incorporate any essential special tokens into the sequence to fulfill model processing requirements.
Understanding Tokenization Challenges
Feel free to type sentences, and observe how tokens are generated (and note the corresponding increase in token count and price per prompt).
Hover over the text on the right-hand side after enabling the “Show whitespace” checkbox, and you’ll observe the highlighted tokens. These tokens typically consist of “chunks” that often include the space character at the beginning.

Here’s another example:

Observe how the token chunks and their numeric representations vary based on:
- The presence of a space before the word
- The existence of punctuation
- The letter case
The Large Language Model (LLM) must learn from raw data that despite these differences in tokens, the words represent the same concept or are at least extremely similar. This variability can decrease performance.
Other Human Languages
Comparing the chunk size for English with other languages, you’ll often notice a significantly larger number of tokens used for languages other than English. This difference stems from the fact that chunks for other languages tend to be more fragmented, leading to an inflated sequence length in documents.
In the attention mechanism of machine learning transformers, there’s a higher likelihood of running out of context for non-English languages. Even when conveying the same message, more tokens are consumed because the chunks are smaller. This discrepancy is influenced by both the training set used for the tokenizer and the tokenizer itself.
Ultimately, this inefficient utilization of the context window for non-English languages results in poorer performance by the Large Language Model (LLM) when handling non-English queries.
Tokenization and Code — Python
In the case of Python, the GPT-2 encoder by OpenAI often expended numerous tokens on individual whitespace characters utilized in the indentation of Python code segments. This behavior, akin to the challenges faced with non-English languages, leads to considerable bloating of the Limited Language Model’s (LLM) context window and consequently, a drop in performance.
Config: YAML vs. JSON
It’s discovered that YAML exhibits higher density compared to JSON, requiring fewer tokens to accomplish the same task.
Here’s a straightforward illustration:


JSON: 46 tokens
The augmented bloating for JSON results in:
- Increased difficulty for the LLM to comprehend (less density, more prone to exceeding the context window).
- Higher expenditure for users (as they essentially pay per token during API calls to OpenAI).
Tokenization issues
Tokenization lies at the core of many anomalies observed in Large Language Models (LLMs). Several issues that may initially seem related to the neural network architecture or the LLM itself can actually be traced back to tokenization. For instance:
- LLMs struggle with spelling words or executing basic string processing tasks like string reversal.
- Performance tends to deteriorate for non-English languages.
- LLMs exhibit subpar performance in handling simple arithmetic.
- GPT-2 encountered significant challenges when tasked with coding in Python.
- Peculiar warnings may arise regarding trailing whitespace.
- The phrase “Solid Gold Magikarp” often leads LLMs to veer off into unrelated tangents.
- YAML is preferred over JSON when working with LLMs.
Tokenization in Large Language Models
In the training of large language models (LLMs), the process involves taking strings and converting them into integers from a predefined vocabulary. These integers are then utilized to retrieve vectors from an embedding table, which are subsequently input into the Transformer model. This process becomes intricate because it necessitates not only supporting the basic English alphabet but also accommodating various languages and special characters like emojis.
Strings in Python and Unicode Code Points
In Python, strings are immutable sequences comprising Unicode code points. These code points are defined by the Unicode Consortium within the Unicode standard, which presently encompasses approximately 150,000 characters spanning 161 scripts. The Unicode standard remains actively maintained, with the latest version, 15.1, being released in September 2023.
To retrieve the Unicode code point for a single character in Python, we can utilize the ord() function. For instance:

Yet, employing these raw code point integers for tokenization isn’t feasible, as it would result in an excessively large vocabulary (150,000+) that is also unstable due to the continuous evolution of the Unicode standard.
Unicode Byte Encodings
In pursuit of a more effective tokenization solution, we look towards Unicode byte encodings such as ASCII, UTF-8, UTF-16, and UTF-32. These encodings dictate the methods for translating abstract Unicode code points into tangible bytes that are suitable for storage and transmission.
Unicode Byte Encodings, ASCII, UTF-8, UTF-16, UTF-32
The Unicode Consortium delineates three types of encodings: UTF-8, UTF-16, and UTF-32. These encodings serve as the means to convert Unicode text into binary data or byte streams.
Among these encodings, UTF-8 is the most prevalent. It translates each Unicode code point into a byte stream ranging from one to four bytes, contingent upon the code point. The initial 128 code points (ASCII) necessitate only one byte. The subsequent 1,920 code points necessitate two bytes for encoding, encompassing the majority of Latin-script alphabets. Three bytes are required for the remaining 61,440 code points within the Basic Multilingual Plane (BMP). Four bytes encompass other Unicode planes, encompassing less common CJK characters, various historical scripts, and mathematical symbols.

Using the raw UTF-8 bytes directly would prove highly inefficient for language models, resulting in excessively lengthy sequences with a restricted vocabulary size of only 256 possible byte values. Such a constraint hampers the model’s ability to attend to sufficiently long contexts.
The solution lies in employing a byte pair encoding (BPE) algorithm to compress these byte sequences variably. This approach enables the efficient representation of text with a larger but adjustable vocabulary size.
What’s the Difference Between Tokenization and Embeddings?
Tokenization and embeddings are separate yet interrelated processes within Large Language Models (LLMs) like GPT, contributing to how these models comprehend and generate text. Here’s a brief overview of each and their distinctions:
LLM Tokenization
Objective: Tokenization aims to transform raw text into a sequence of tokens, which can encompass words, subwords, or characters, depending on the chosen tokenization approach.
Procedure: It entails dissecting the text into manageable segments that the model can interpret. This may entail initially segmenting the text based on spaces and punctuation, followed by further segmentation into subwords or characters if they are absent from the model’s predefined vocabulary.
Result: The outcome is a token sequence that represents the original text in a format conducive to model processing. Each token is assigned a unique integer ID corresponding to the model’s vocabulary.
Embeddings
Objective: Embeddings are compact, low-dimensional, continuous vector representations of tokens. They encode semantic and syntactic meanings, facilitating the model’s comprehension of language nuances.
Procedure: Following tokenization, each token (represented by its integer ID) is associated with an embedding vector. These vectors are acquired through the model’s training phase and are stored in an embedding matrix or table.
Result: The embeddings function as input to the neural network layers of the LLM, enabling the model to conduct computations on the tokens and discern relationships and patterns within the dataset.
Find more detailed information about LLM Embedding in our blog: What is LLM Embeddings: All You Need To Know
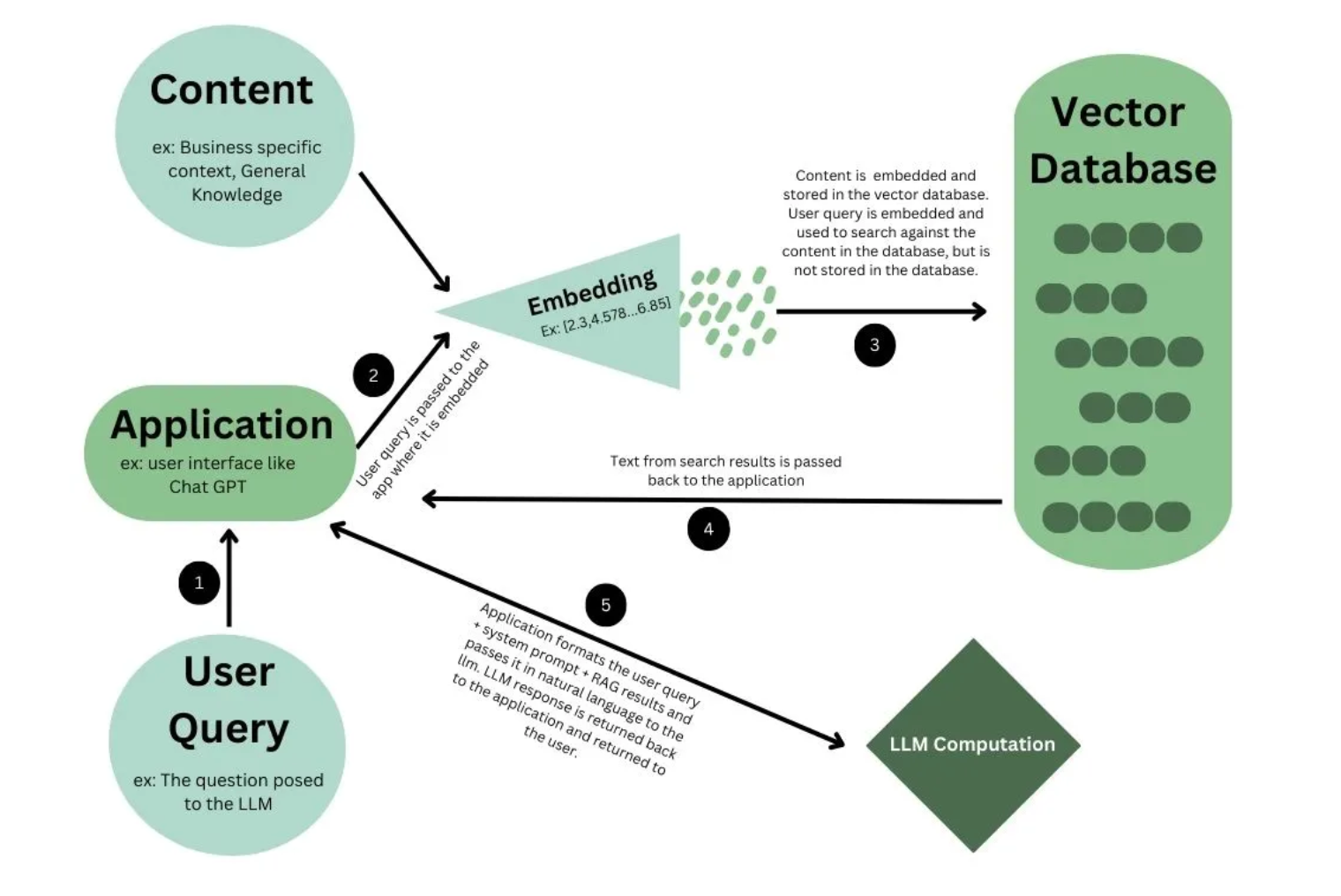
Distinguishing Features
Processing Stage: Tokenization serves as an initial preprocessing step, converting text into a format understandable to the model (tokens), while embeddings occur subsequent to tokenization, translating tokens into detailed vector representations.
Function: Tokenization primarily involves structurally deconstructing and representing text, whereas embeddings focus on capturing and leveraging the semantic and syntactic meanings embedded within tokens.
Representation: Tokenization yields discrete, integer-based representations of text components, while embeddings transform these integers into continuous vectors that encode linguistic information.
Conclusion
In conclusion, tokenization and embeddings play pivotal roles in the functioning of Large Language Models. While tokenization structures text into tokens, embeddings provide semantic and syntactic meanings to these tokens through vector representations. By comprehending these processes, we gain insight into how LLMs interpret and generate text, contributing to advancements in natural language processing.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
What is the difference between LLM and GPT
LLM Leaderboard 2024 Predictions Revealed
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available