Llama Weights: An Ultimate Guide 2024

Introduction
Often heard of Llama weights but have little idea about it? Don’t worry! In this ultimate guide, we will explore the concept of weight, discuss the content and the importance of Llama weights, ways of downloading llama weights and the most efficient method of adopting LLMs — — API. So, if you want to keep up with the Llama weight trend, keep reading!
Understanding the Concept of Weight
Weight is a fundamental concept in neural networks, including the transformer-based language models like Llama. Weights are the adjustable parameters that the model learns during training, enabling it to capture patterns in the data and perform well on natural language processing (NLP) tasks. The transformer architecture, which has become the prevalent design for state-of-the-art language models, organizes these weights into a specific structure named “multi-head self-attention”.

In transformer models, the weights are distributed across hundreds of layers, each consisting of numerous neurons or units. The number of parameters varies among models depending on the architectural design choices, such as the number of layers, the dimensionality of the input and output representations, and the complexity of the attention mechanisms.
Substantial parameter count allows the model to capture intricate patterns and nuances in natural language, facilitating its strong performance on a wide range of NLP tasks, from text generation to question answering and beyond. It’s important to note that while a higher number of parameters generally correlates with increased model capacity, efficient utilization of these parameters through architectural innovations, training strategies, and regularization techniques is crucial for optimal performance and generalization.
What are Llama Weights?
Llama weights refer to the parameters utilized in models within the Llama family. The current discussions around Llama weights are a result of Meta AI’s decision to share the Llama 2 and 3 models with the public. This means that anyone can now freely access and download these models, along with their tokenizers (tools that break text into smaller parts called “tokens”, similar to a word) and weights for personal use and even commercial use.
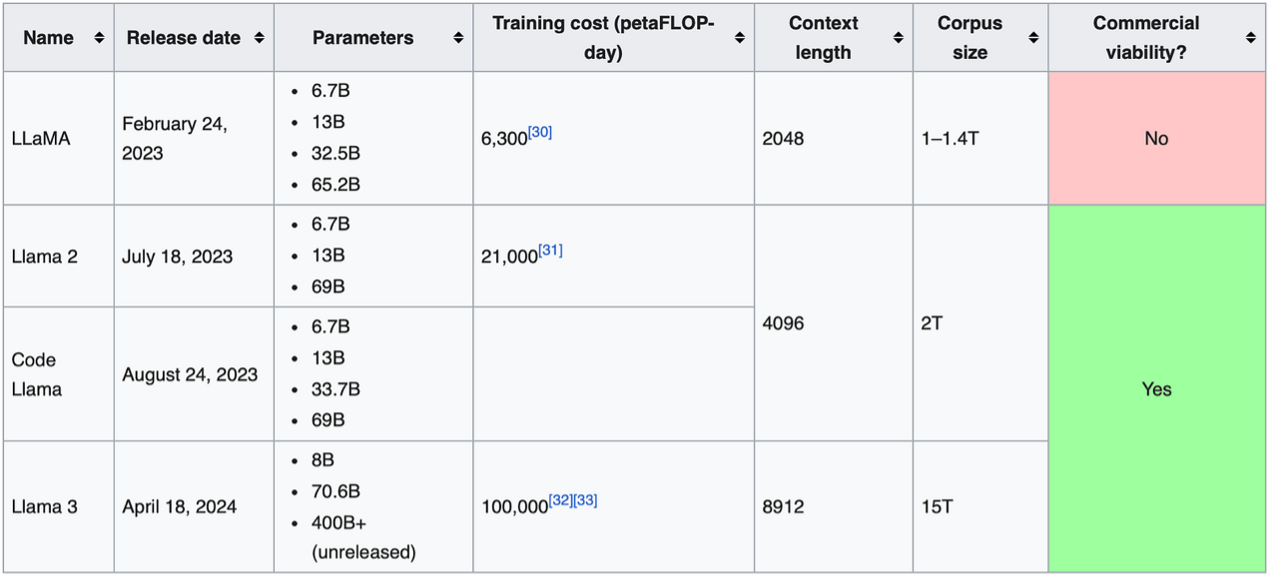
Difference between Llama 2 and 3
Naturally, with the innovation of models, different Llama generations have different weight numbers. To elaborate further, Llama 2 offers models in three different sizes, with approximately 7 billion, 13 billion, and 70 billion parameters respectively. Similarly, the Llama 3 model is available in versions with 8 billion and 70 billion parameters. Although Meta AI’s largest models have over 400 billion parameters, they are still undergoing training and have not yet been released.
Comprehending Llama Weights in Codes
Writing vocab...
[ 1/291] Writing tensor tok_embeddings.weight | size 32000 x 4096 | type UnquantizedDataType(name='F16')
[ 2/291] Writing tensor norm.weight | size 4096 | type UnquantizedDataType(name='F32')
[ 3/291] Writing tensor output.weight | size 32000 x 4096 | type UnquantizedDataType(name='F16')
[ 4/291] Writing tensor layers.0.attention.wq.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[ 5/291] Writing tensor layers.0.attention.wk.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[ 6/291] Writing tensor layers.0.attention.wv.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[ 7/291] Writing tensor layers.0.attention.wo.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[ 8/291] Writing tensor layers.0.attention_norm.weight | size 4096 | type UnquantizedDataType(name='F32')
[ 9/291] Writing tensor layers.0.feed_forward.w1.weight | size 11008 x 4096 | type UnquantizedDataType(name='F16')
[ 10/291] Writing tensor layers.0.feed_forward.w2.weight | size 4096 x 11008 | type UnquantizedDataType(name='F16')
[ 11/291] Writing tensor layers.0.feed_forward.w3.weight | size 11008 x 4096 | type UnquantizedDataType(name='F16')
[ 12/291] Writing tensor layers.0.ffn_norm.weight | size 4096 | type UnquantizedDataType(name='F32')
[ 13/291] Writing tensor layers.1.attention.wq.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[ 14/291] Writing tensor layers.1.attention.wk.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[ 15/291] Writing tensor layers.1.attention.wv.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[ 16/291] Writing tensor layers.1.attention.wo.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[ 17/291] Writing tensor layers.1.attention_norm.weight | size 4096 | type UnquantizedDataType(name='F32')
[ 18/291] Writing tensor layers.1.feed_forward.w1.weight | size 11008 x 4096 | type UnquantizedDataType(name='F16')
[ 19/291] Writing tensor layers.1.feed_forward.w2.weight | size 4096 x 11008 | type UnquantizedDataType(name='F16')
[ 20/291] Writing tensor layers.1.feed_forward.w3.weight | size 11008 x 4096 | type UnquantizedDataType(name='F16')
[ 21/291] Writing tensor layers.1.ffn_norm.weight | size 4096 | type UnquantizedDataType(name='F32')
...
[283/291] Writing tensor layers.31.attention.wq.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[284/291] Writing tensor layers.31.attention.wk.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[285/291] Writing tensor layers.31.attention.wv.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[286/291] Writing tensor layers.31.attention.wo.weight | size 4096 x 4096 | type UnquantizedDataType(name='F16')
[287/291] Writing tensor layers.31.attention_norm.weight | size 4096 | type UnquantizedDataType(name='F32')
[288/291] Writing tensor layers.31.feed_forward.w1.weight | size 11008 x 4096 | type UnquantizedDataType(name='F16')
[289/291] Writing tensor layers.31.feed_forward.w2.weight | size 4096 x 11008 | type UnquantizedDataType(name='F16')
[290/291] Writing tensor layers.31.feed_forward.w3.weight | size 11008 x 4096 | type UnquantizedDataType(name='F16')
[291/291] Writing tensor layers.31.ffn_norm.weight | size 4096 | type UnquantizedDataType(name='F32')
Writing vocab...: This line indicates that it is writing the vocabulary (all the words/tokens) used by the model.tok_embeddings.weight: This refers to the embedding matrix, which maps each word/token in the vocabulary to a dense vector representation.norm.weight: This is a weight matrix used for normalization layer after the output of a neural network layer.output.weight: This is a weight matrix responsible for converting the output of a neural network’s last hidden layer into the network’s final output.- The lines with
layers.#.attention.wq/wk/wv/wo.weight: These are the weight matrices used in the multi-head attention mechanism inside each of the 32 transformer layers. For example,wqare the weights to create the query vectors,wkfor keys,wvfor values, etc. Query vectors enable the network to generate the output sequence while focusing on various segments of the input sequence. layers.#.attention_norm.weight: Weight vectors for normalization inside the attention sub-layers.layers.#.feed_forward.w1/w2/w3.weight: Weight matrices for the feed-forward sub-layers inside each transformer layer. These apply non-linear transformations.layers.#.ffn_norm.weight: Normalization weights for the feed-forward sub-layers.
The sizes show the dimensions of these weight matrices/vectors. For example, 4096 x 4096 means a square matrix of 4096 rows/columns, representing the model dimension.
The UnquantizedDataType refers to the data type/precision used to store the weights, like F16 (half-precision floating point) or F32 (regular floating point).
So in summary, this is listing out all the different trainable parameters of the large Llama language model across its embedding layers, attention layers, feed-forward layers, normalization components, etc. The sizes correspond to the model’s vocabulary size and dimensionality. If you have further questions related to installing Llama 3, feel free to explore this guideline “llama3 implemented from scratch”.
Why Do Llama Weights Matter?
In the world of AI, weights are the invisible gears that keep the machine running smoothly. Think of them as the muscles of a bodybuilder: properly tuned and developed, they make the difference between a flabby novice and a competition-ready champion. Weights determine how the model processes input data, learns from it, and makes predictions. In Llama 3, managing these weights effectively is crucial for several reasons. First, they ensure it can handle complex tasks efficiently without unnecessary computational bloat. Second, well-managed weights lead to better generalization, enabling the model to perform well on unseen data. Third, they contribute to the model’s ability to scale, meaning larger models can be trained and utilized without a proportional increase in computational resources.
It is important to note that Llama weights and other aspects of the model work together to present state-of-the-art performance. Let’s dig deeper into this.
Model Architecture: The Brainy Beast
- Bigger and Better Vocabulary: 128K token vocabulary for efficient language encoding.
- Grouped Query Attention (GQA): Improves inference efficiency in both 8B and 70B models.
- Longer Sequences, Better Focus: Trained on 8,192-token sequences with careful attention span management.
Training Data: The Mighty Mountain of Words
- A Data Feast: Over 15 trillion tokens, seven times more than Llama 2, with four times more code data.
- Multilingual Magic: 5% high-quality non-English data across 30+ languages.
- Data Filters Galore: Heuristic filters, NSFW filters, semantic deduplication, and Llama 2-assisted classifiers ensure top-notch data quality.
Scaling Up Pretraining: The Bigger, the Better
- Scaling Laws: Guide optimal data mix and training compute use, predicting performance.
- Continuous Improvement: 8B and 70B models show log-linear gains with up to 15T tokens.
- Three-Tiered Parallelization: Data, model, and pipeline parallelization achieve over 400 TFLOPS per GPU on 24K GPU clusters.
Instruction Fine-Tuning: The Masterclass in Coaching
- Supervised Fine-Tuning (SFT): Enhances responses with curated prompts and human QA.
- Rejection Sampling, proximal policy optimization (PPO), and direct preference optimization (DPO): Improve reasoning and coding skills through preference learning.
- Human Touch: Ensures high-quality annotations for accurate, nuanced answers.
In Llama 3, every component from architecture to training data to fine-tuning is optimized, with a focus on weight management, ensuring top-tier performance, efficiency, and scalability.
How to download LLaMA weights?
To get the Llama model weights onto your computer, you’ll need to follow these steps:
- First, visit the Meta Llama website and agree to their license terms and conditions. This is required before they’ll allow you to download the model.
- After you accept the license, submit a request on their website. They will then review your request.
- If your request is approved, Meta will send you a personalized download link via email. This link will be valid for 24 hours only.
- Once you receive that email with the download link, you’ll need to run the script
./download.shon your computer. This script will automatically download the model weights file from the personalized link they provided. - When running the download script, it will prompt you to enter or paste in the special download link from the email.
- The script will then use that link to download the large model weights file to your computer.

A couple of important notes:
- You need to have certain programs/utilities like
wgetandmd5suminstalled for the script to work properly. - The download links expire after 24 hours, so you’ll need to request a new one if it expires before you could download.
- There’s a limit on how many times a link can be used, so you may need to re-request if you get an error
403: Forbidden.
How to integrate LLaMA model API
Downloading and setting up large language models like Llama can be quite complicated, especially for those without technical expertise. Between accepting licenses, requesting access, running scripts, and handling downloads — it can get messy very quickly.
Fortunately, there’s an easier way to use cutting-edge models like Llama for your projects, whether you’re building software or websites. Novita AI offers powerful Language Model APIs that provide seamless access to state-of-the-art models, including Llama 3 and Mixtral.
With Novita AI’s APIs, you can simply integrate these advanced language capabilities into your applications without the hassle of downloading, setting up, and maintaining the models yourself. The process is straightforward: sign up for an account, obtain your API credentials, and integrate the APIs into your applications.
Check out your preferred LLM models and tap into the potential of LLMs for your own works with professional help.
Conclusion
In conclusion, Llama weights are the parameters Llama models learned through the processes of training which allow it to solve NLP tasks. Importantly, the state-of-the-art performance of a model, e.g. Llama 3, also depends on its architecture, training data and other innovative moves. Apart from downloading Llama’s open-source models, the most efficient way to combine the capacity of different LLMs is to integrate APIs.
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
Meta Llama 3: Newest of the Llama Model family is Crashing the Party
Introducing Llama 2: All Worthwhile After Llama 3 Released
Introducing Meta-Llama Models: What Are They and How to Set Up