How to Evaluate Large Language Models

Discover the importance of a comprehensive evaluation framework for Large Language Models (LLMs) in advancing AI technologies. Learn how meticulous evaluation methods ensure effectiveness, ethical adherence, and practical applicability across industries. Explore the emergence of Enterprise LLMs and schedule a custom AI demo to experience their transformative impact firsthand
Introduction
Artificial intelligence technology has produced remarkable tools, with few as impactful as Large Language Models (LLMs). These models have garnered substantial attention for their capacity to comprehend and process human-like natural language.
LLMs serve as the cornerstone of AI systems equipped with Natural Language Processing (NLP) capabilities. These models drive various tools, including AI chatbots, content generators, machine translation systems, and speech recognition technologies. Nevertheless, alongside their remarkable capabilities come considerable challenges in objective assessment, underscoring the critical necessity for rigorous LLM evaluation.
Hence, the evaluation of LLMs holds greater significance than ever to ensure their accurate operation. A thorough assessment of model capabilities is pivotal in determining their effectiveness, guaranteeing that these sophisticated systems meet the rigorous standards required for their diverse applications. Therefore, precise LLM evaluation metrics are essential.
Developers, researchers, and businesses increasingly rely on synthetic benchmarks and other evaluation tools to assess a model’s proficiency in understanding and processing language intricacies. From crafting coherent narratives to providing relevant information, various benchmarks such as HellaSwag and TruthfulQA datasets highlight a model’s versatility. It is these evaluations that validate the readiness of LLMs to fulfill their intended purposes, potentially reshaping industries through their deployment.
What is LLM Evaluation?
The notion of evaluating Large Language Models (LLMs) entails a detailed and intricate process essential for appraising the functionalities and capabilities of these advanced language models. Within this evaluative framework, the strengths and limitations of a specific model become evident, offering guidance to developers for refinement and aiding in the selection of models that best suit the project’s needs. To begin, let’s delve into a concise yet comprehensive overview of LLMs.
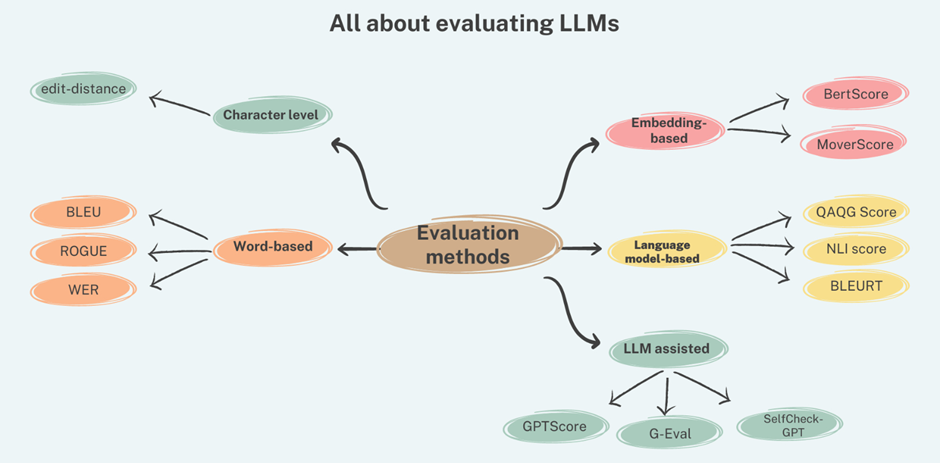
LLM Overview
In the current landscape, the widespread adoption of Large Language Models (LLMs) is profoundly reshaping various sectors. This includes their integration into healthcare, a pivotal development revolutionizing the industry. Additionally, LLMs are finding applications in banking and AI customer service, enhancing efficiency and effectiveness. Therefore, regular assessment of these models is crucial to ensure their accuracy and reliability in delivering valid responses.
At the core of LLM performance evaluation lies the imperative to understand the effectiveness of foundational models. This is achieved through rigorous testing against benchmark datasets tailored to push the boundaries of an LLM’s performance in terms of accuracy, fluency, and relevance. This critical analysis illuminates how a model processes and generates language, essential for applications ranging from question answering to content creation.
Transitioning to system evaluations, we delve into specific components within the LLM framework, such as prompts and contexts, which play a fundamental role in real-world applications of these models. Tools like OpenAI’s Eval library and Hugging Face’s platforms provide invaluable resources for evaluating foundational model performances. These tools not only facilitate comparative analysis but also equip developers with empirical evidence needed to optimize LLMs for bespoke uses.
Determining how to evaluate LLMs is as much about refining the algorithms that underpin them as it is about ensuring seamless and productive integration within a specific context. Choosing the right model is critical, as it forms the foundation upon which businesses and developers can build innovative and reliable solutions that meet user requirements in this ever-evolving tech landscape.
Why is an LLM Evaluation Framework Needed?
As we venture deeper into the realms of artificial intelligence, the proficiency of generative AI systems, particularly Large Language Models (LLMs), is exerting increasingly significant influence across various industries.
To grasp why evaluating LLMs is pivotal, we must acknowledge the rapidly expanding scope of their applications, often surpassing the capability of traditional feedback mechanisms to monitor their performance adequately. Thus, the LLM evaluation process is indispensable for several reasons.
First and foremost, it offers a glimpse into the model’s reliability and efficiency — critical factors determining an AI’s functionality in real-world scenarios. Without robust and up-to-date evaluation methods, inaccuracies and inefficiencies may go unchecked, potentially resulting in unsatisfactory user experiences.
Through the evaluation of LLMs, businesses and practitioners gain invaluable insights to fine-tune these models, ensuring they are accurately calibrated to meet the specific needs of AI deployments and the broader context of their applications.
How to Evaluate Large Language Model
A robust evaluation framework is vital for detecting and mitigating biases within AI outputs. Given the societal and legal ramifications involved, systematically identifying and implementing strategies to address these biases is crucial for fostering ethically responsible AI solutions.
Through the examination of critical parameters such as relevance, potential for hallucination, and toxicity, evaluation endeavors aim to strengthen user trust and ensure that generated content adheres to ethical standards and societal expectations.
The importance of evaluating large language models cannot be overstated. It not only highlights the capability of AI in today’s technology-driven environment but also ensures that the development path of LLMs aligns with the ethical guidelines and efficiency standards required by their evolving roles.
LLM system evaluation strategies: Online and offline
Given the novelty and inherent uncertainties surrounding many LLM-based functionalities, a prudent release strategy is essential to maintain privacy and uphold social responsibility standards. While offline evaluation proves valuable in the initial stages of feature development, it lacks in assessing how model adjustments affect user experience in a live production setting. Thus, a balanced combination of online and offline evaluations forms a sturdy framework for comprehensively grasping and improving LLM quality across the development and deployment lifecycle. This approach enables developers to glean insights from real-world usage while ensuring the reliability and effectiveness of the LLM through controlled, automated assessments.
Offline evaluation
Offline evaluation involves assessing LLMs using specific datasets to ensure they meet performance standards prior to deployment. This method is particularly effective for evaluating aspects like entailment and factuality and can be seamlessly automated within development pipelines, facilitating faster iterations without relying on live data. It’s cost-effective and suitable for pre-deployment checks and regression testing.
Golden datasets, supervised learning, and human annotation
Golden datasets, supervised learning, and human annotation play pivotal roles in the initial stages of constructing an LLM application. The process begins with a preliminary assessment, often referred to as “eyeballing,” which entails experimenting with inputs and expected responses to tune and build the system. While this provides a proof of concept, it’s just the beginning of a more intricate journey.
Creating an evaluation dataset, also known as ground truth or golden dataset, for each component becomes crucial for thorough LLM system evaluation. However, this approach presents challenges, notably in terms of cost and time. Designing the evaluation dataset requires meticulous curation of diverse inputs spanning various scenarios, topics, and complexities to ensure effective generalization by the LLM. Simultaneously, gathering corresponding high-quality outputs establishes the ground truth against which the LLM’s performance will be measured. Building the golden dataset involves annotating and verifying each input-output pair meticulously. This process not only refines the dataset but also deepens understanding of potential challenges and intricacies within the LLM application, typically requiring human annotation.
To enhance the scalability of the evaluation process, leveraging the LLM’s capabilities to generate evaluation datasets proves beneficial. While this approach helps save human effort, human involvement is still crucial to ensure the quality of datasets produced by the LLM. For instance, utilizing QAGenerateChain and QAEvalChain from LangChain for both example generation and model evaluation, as demonstrated in Harrison Chase and Andrew Ng’s online courses, provides an example.


AI evaluating AI
Beyond the conventional AI-generated golden datasets, let’s delve into the innovative domain of AI assessing AI. This approach not only offers the potential for speed and cost-effectiveness surpassing human evaluation but also, when finely tuned, can yield significant value. Particularly within the realm of Large Language Models (LLMs), there exists a distinct opportunity for these models to act as evaluators.
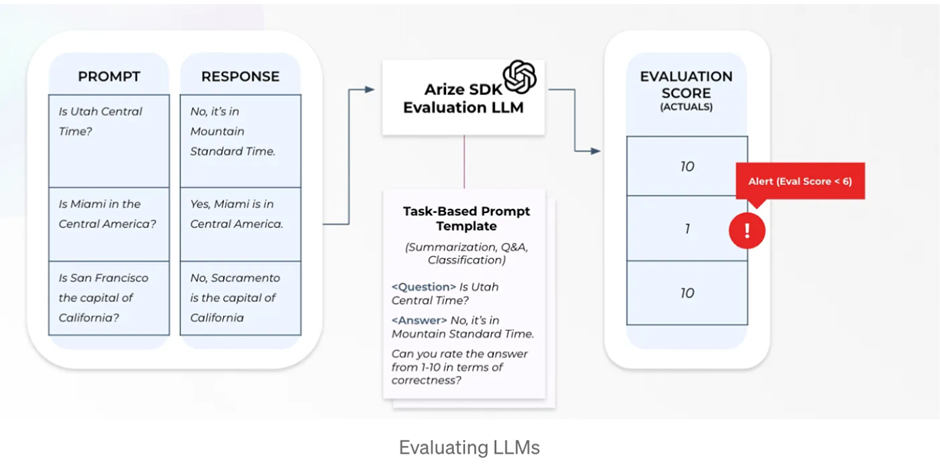
In the design phase, exercising caution is crucial. As it’s impossible to conclusively prove the correctness of the algorithm, adopting a meticulous approach to experimental design becomes essential. It’s vital to maintain a healthy skepticism and acknowledge that even advanced LLMs like GPT-4 are not infallible oracles. They lack an inherent grasp of context and can potentially offer misleading information. Therefore, any inclination to embrace simplistic solutions should be balanced with a critical and discerning assessment.
Online evaluation and metrics
Online evaluation occurs within real-world production environments, utilizing genuine user data to evaluate live performance and user satisfaction via direct and indirect feedback. This method employs automatic evaluators activated by new log entries extracted from live production. Online evaluation effectively mirrors the intricacies of real-world usage and incorporates valuable user input, rendering it optimal for ongoing performance monitoring.
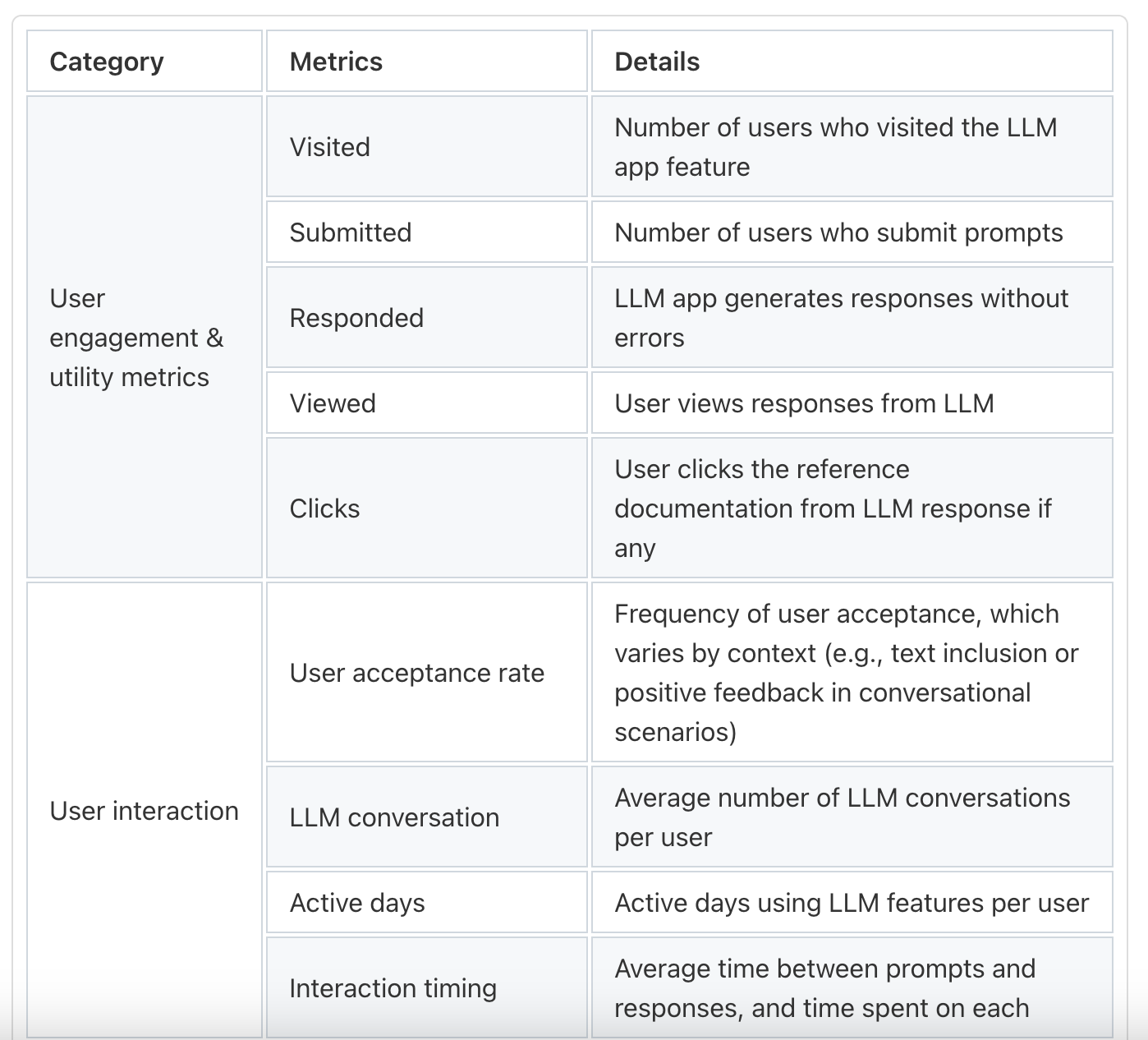
Applications of LLM Performance Evaluation
Thoroughly evaluating Large Language Models (LLMs) goes beyond academic exercise; it’s a business imperative in today’s data-driven world. Employing precise LLM evaluation metrics allows us to unlock their full potential, optimize their application across diverse fields, and ensure they effectively serve our objectives.
Performance Assessment
Various metrics are used to assess how effectively LLMs interpret human language and provide accurate responses, covering comprehension tests, information extraction, and text quality under different input conditions.
Model Comparison
Businesses and researchers rely on comprehensive data for comparing LLM performance. Utilizing LLM performance evaluation techniques provides insights into fluency, coherence, and the handling of domain-specific content.
Bias Detection and Mitigation
Bias detection is crucial in current model evaluation techniques, identifying situations where models may produce prejudiced outcomes. Effective LLM evaluation metrics help strategize improvements, ensuring fair and ethical outputs.
Comparative Analysis
Alongside tracking model evolution and user feedback, evaluating the integration and impact of LLM embeddings is essential. Comparative analysis identifies strengths and weaknesses, fostering enhanced user trust and better-aligned AI solutions.
Striving for excellence in artificial intelligence through comprehensive LLM performance evaluation not only advances the field but also ensures that the AI systems we develop reflect our values and efficiently serve our needs.
If you are looking for evaluated LLMs, dive into our blog to see: TOP LLMs for 2024: How to Evaluate and Improve An Open Source LLM

How to overcome problems of large language models evaluation methods
In the domain of large language model evaluation, precision in methodology is crucial. Improving the integrity and effectiveness of evaluations entails adhering to established best practices. Equipped with these strategies, developers and researchers can adeptly navigate the intricacies of LLM evaluation and advancement.
Harnessing LLMOps
Central to refining LLM evaluation processes is the strategic application of LLMOps. This involves orchestrating and automating LLM workflows to prevent data contamination and biases.
Collaborative tools and operational frameworks, often provided by reputable institutions, play a crucial role in achieving consistent and transparent outcomes. These systems enable practitioners to rigorously assess and deploy language models while ensuring accountability for the data sources they utilize.
Utilizing Multiple LLM Evaluation Metrics
In the pursuit of LLM evaluation best practices, employing a variety of metrics is imperative. It’s essential that evaluations are diverse, covering a wide spectrum including fluency, coherence, relevance, and context understanding.
Evaluating large language models with multifaceted metrics not only showcases the nuanced capabilities of these systems but also ensures their suitability across various communication domains. Such rigorous examination reinforces the reliability and adaptability of the models under scrutiny.
Real-world Evaluation
Beyond controlled laboratory conditions lies the realm of real-world applications — a domain where theory meets practicality. Validating LLMs through practical usage scenarios verifies their effectiveness, user satisfaction, and ability to adapt to unforeseen variables.
This approach shifts large language model evaluation from the abstract to the tangible, user-centric world where utility is truly tested. Additionally, integrating known training data into evaluations ensures that datasets reflect a wide range of acceptable responses, making evaluations as comprehensive as possible.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
What is the difference between LLM and GPT
LLM Leaderboard 2024 Predictions Revealed
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available