

Seedance V1 I2V de ByteDance es uno de los modelos de imagen a vídeo más potentes disponibles hoy en día, capaz de transformar una sola imagen fija en secuencias cinematográficas fluidas. Con funciones como narración multi‑toma nativa, consistencia de personajes y visuales profesionales en 1080p, está especialmente diseñado para creadores que necesitan generación de vídeo coherente y de alta calidad.
Sin embargo, aunque la plataforma oficial de ByteDance aún no permite el acceso directo a las capacidades de vídeo de Seedance V1, Novita AI proporciona una API estable y asequible que hace que esta tecnología de vanguardia sea inmediatamente accesible. Por solo $0.13 por corte de vídeo, desarrolladores y artistas pueden experimentar con las versiones Lite y Pro, integrando Seedance V1 sin problemas en sus flujos de trabajo creativos.
¿Por qué Seedance V1 I2V es superior?
Narración multi‑toma nativa
- Admite vídeos narrativos multi‑toma por diseño.
- Mantiene la consistencia del sujeto, el estilo visual y la atmósfera a través de transiciones de toma y cambios espacio‑temporales.
- Ideal para generar contenido cinematográfico coherente y basado en historias.
Dado que el sitio web de ByteDance no admite el uso directo de Seedance V1, ¡puedes usar la API estable y rentable de Novita AI para probar la capacidad multi‑toma de Seedance V1!
Creado por Novita AI
Movimiento y estabilidad de alta calidad
- Cuenta con un amplio rango dinámico, capaz de producir tanto movimientos a gran escala como expresiones sutiles.
- Garantiza un movimiento suave y natural con una fuerte estabilidad y realismo físico.
Expresión estilística diversa
- Interpreta con precisión las indicaciones en un amplio espectro de estilos:
- Ofrece a los creadores opciones artísticas y creativas versátiles.
Resolución y estética
- Genera directamente vídeos HD en 1080p.
- Produce resultados con estética de nivel cinematográfico, adecuados para casos de uso profesional.
¿Cómo funciona Seedance V1 I2V?
Transformer de difusión latente: Seedance V1 emplea esta arquitectura avanzada para garantizar la coherencia espacio‑temporal, lo que significa que el vídeo mantiene la consistencia y la plausibilidad del movimiento a lo largo del tiempo.
Capas espaciales y temporales desacopladas: La arquitectura del modelo separa el aprendizaje de los detalles espaciales (cómo se ven las cosas) de la dinámica temporal (cómo se mueven las cosas). Esto le permite manejar tareas de texto a vídeo (T2V) e imagen a vídeo (I2V) dentro de un solo modelo.
Aprendizaje basado en retroalimentación: El rendimiento de Seedance V1 se mejora significativamente mediante algoritmos de aprendizaje basados en retroalimentación que utilizan múltiples modelos de recompensa. Estos modelos se centran en mejorar la naturalidad del movimiento, la coherencia estructural y la fidelidad visual.
Seedance V1 Lite vs Seedance V1 Pro
| Característica | Seedance V1 Lite | Seedance V1 Pro |
|---|---|---|
| Resolución | Hasta 720p, suave y cinematográfico | Hasta 1080p, visuales de grado profesional con mayor detalle y consistencia temporal |
| Asequibilidad | Rentable, ideal para vistas previas rápidas y casos de uso de baja resolución | Diseñado para uso profesional, priorizando la calidad sobre el costo |
| Velocidad | Generación rápida, optimizada para tiempos de respuesta cortos | Equilibrado con funciones avanzadas, menos enfocado en la velocidad |
| Funciones avanzadas | Generación básica de vídeo, menos controles | Admite precisión, estabilidad y narrativas multi‑toma complejas |
| Control | Salida cinematográfica estándar | Generación matizada con control refinado sobre el movimiento y la dinámica de la escena |
| Más adecuado para | Borradores rápidos, vistas previas asequibles, casos de uso casual | Creación de contenido profesional, narración de historias, proyectos cinematográficos complejos |
¡Gracias al sólido soporte de API de Novita AI, los precios de Lite y Pro son casi iguales, solo $0.13 por corte de vídeo!
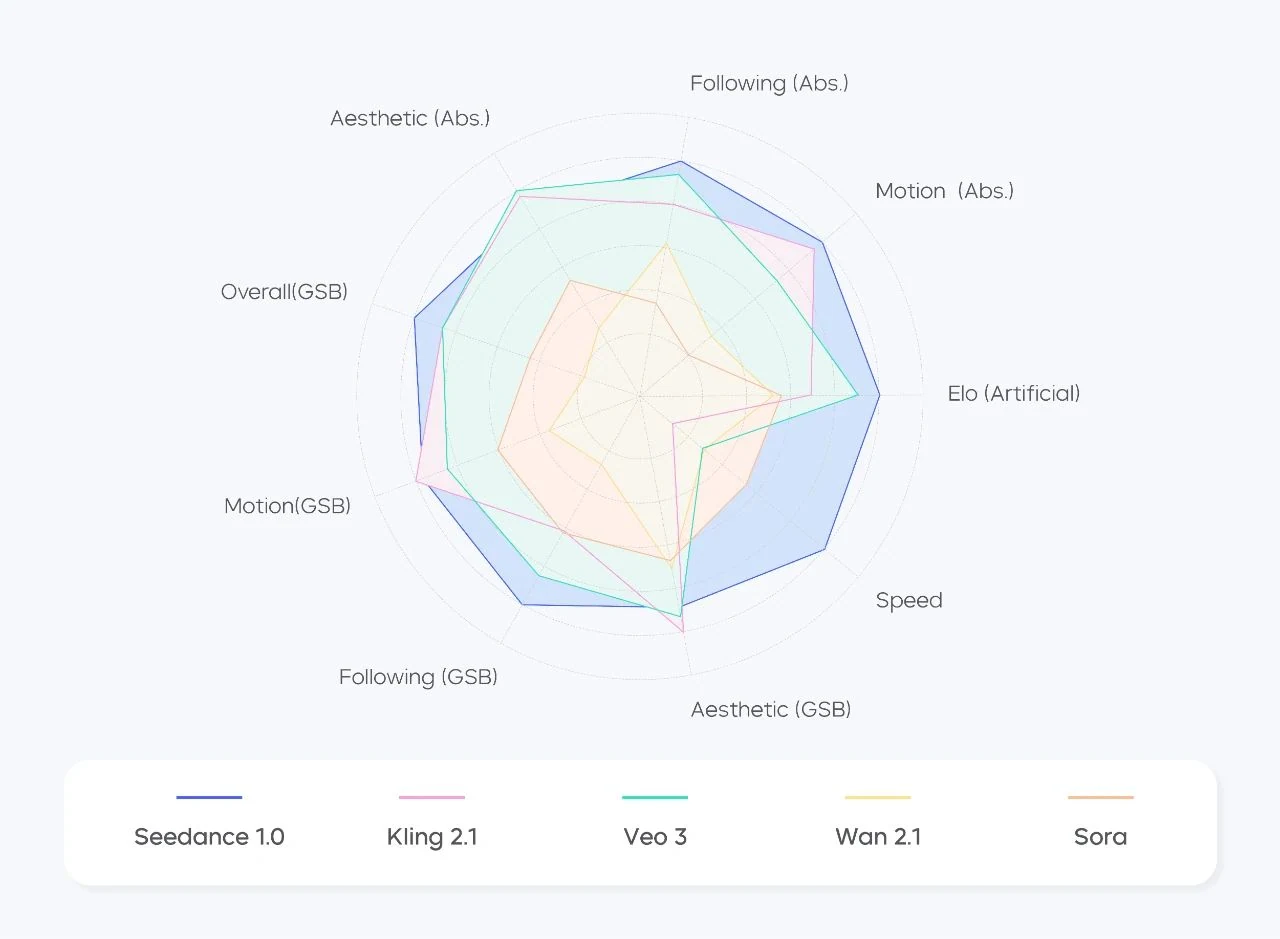
Seedance V1 I2V vs otros I2V
En general, Seedance 1.0 ha alcanzado los primeros puestos en los rankings tanto para tareas T2V como I2V. Sus puntos fuertes residen en su movimiento fluido, estructuras estables y fiel adherencia a indicaciones complejas.
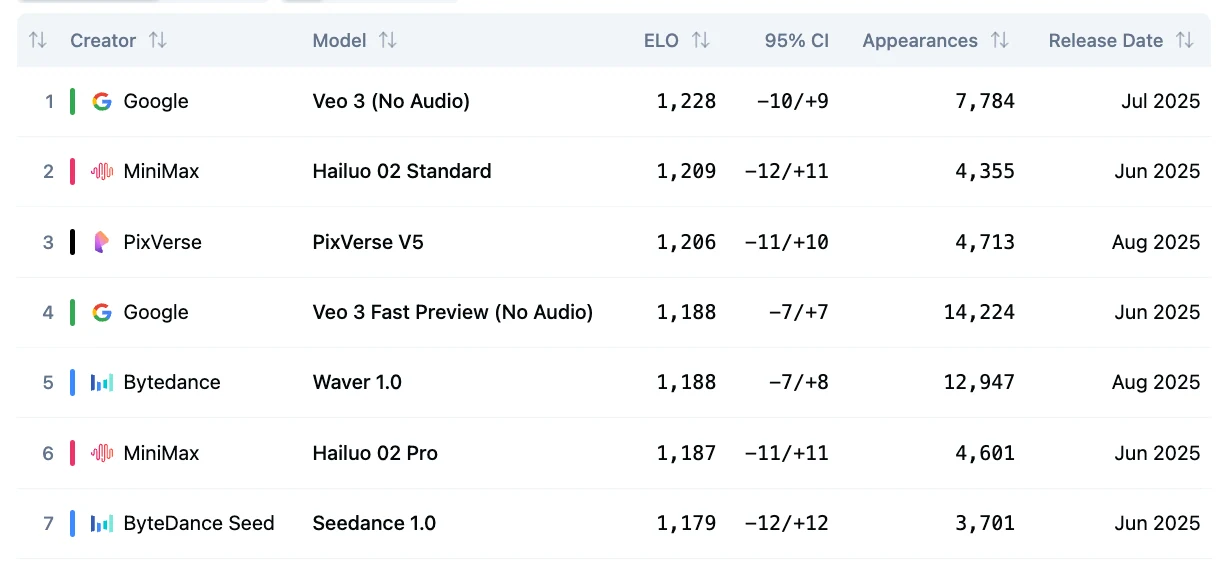
Benchmark de Seedance V1 I2V
| Modelo | Arquitectura y fuente | Resolución y duración | Fortalezas principales | Limitaciones clave |
|---|---|---|---|---|
| Seedance V1 I2V | Transformer de difusión (DiT) con capas espaciales/temporales desacopladas; RLHF; modelo unificado T2V/I2V. | Hasta 1080p, 5-10 s | Narración multi‑toma nativa con consistencia de personajes. Fuerte adherencia a indicaciones para control de cámara cinematográfico. |
Dominar las indicaciones multi‑toma puede ser complejo. |
| PixVerse V4.5 I2V | Difusión propietaria; 20+ plantillas de lentes cinematográficos; fusión multi‑imagen | 720p/1080p, hasta 8 s (5 s nativos) | Movimientos de cámara precisos (dolly, paneo, zoom); fusión narrativa multi‑imagen; generación rápida de 5 s |
Inestable en escenas complejas con múltiples sujetos; duración máxima del clip ~8 s |
| Wan 2.2 I2V | 27 B MoE + TI2V-5B VAE de alta compresión; T2V/I2V unificado | 720p@24 fps, 5 s | Inferencia rápida de 5 s; uso académico y comercial |
Limitado a clips de 5 s; el tiempo de inferencia sigue siendo de minutos a pesar de la compresión |
| Hailuo 02 | Síntesis de movimiento basada en difusión; indicaciones guiadas por tokens | 768p@25 fps 1080p (Pro ≈8 min) |
Movimiento natural y fluido; consistencia de grado profesional; versión Pro para salida 1080p |
La versión estándar tarda minutos por clip |
| Kling 1.6 I2V | Difusión propietaria con prioridades de movimiento basadas en esqueleto | 480p–720p, 3–6 s (≈10–15 min en RTX 3080) | Optimizado para anime y escenas de un solo personaje; se ejecuta en GPUs de consumo; experimentación rápida | Menor fidelidad para escenas complejas; tiempos de inferencia más largos en GPUs antiguas |
| Vidu 2.0 | Difusión + backbone U-ViT | 4s: 360p, opciones: 360p, 720p,1080p 8s: 720p |
Alta coherencia y dinamismo; generación de secuencias largas; técnicas de estilo fotográfico |
Las indicaciones complejas pueden degradar la calidad o dar resultados inesperados |
Seedance V1
Wan 2.2
kling 2.1
Hailuo 02
Vido 2.0
PixVerse V4.5
Novita AI ofrece estas API de vídeo mencionadas. ¡Puedes hacer clic directamente en el sitio web para encontrar y probar el vídeo que te interesa!
Tutorial de Seedance V1 I2V para principiantes
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Configuración” y copia la clave API como se indica en la imagen.

Paso 4: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
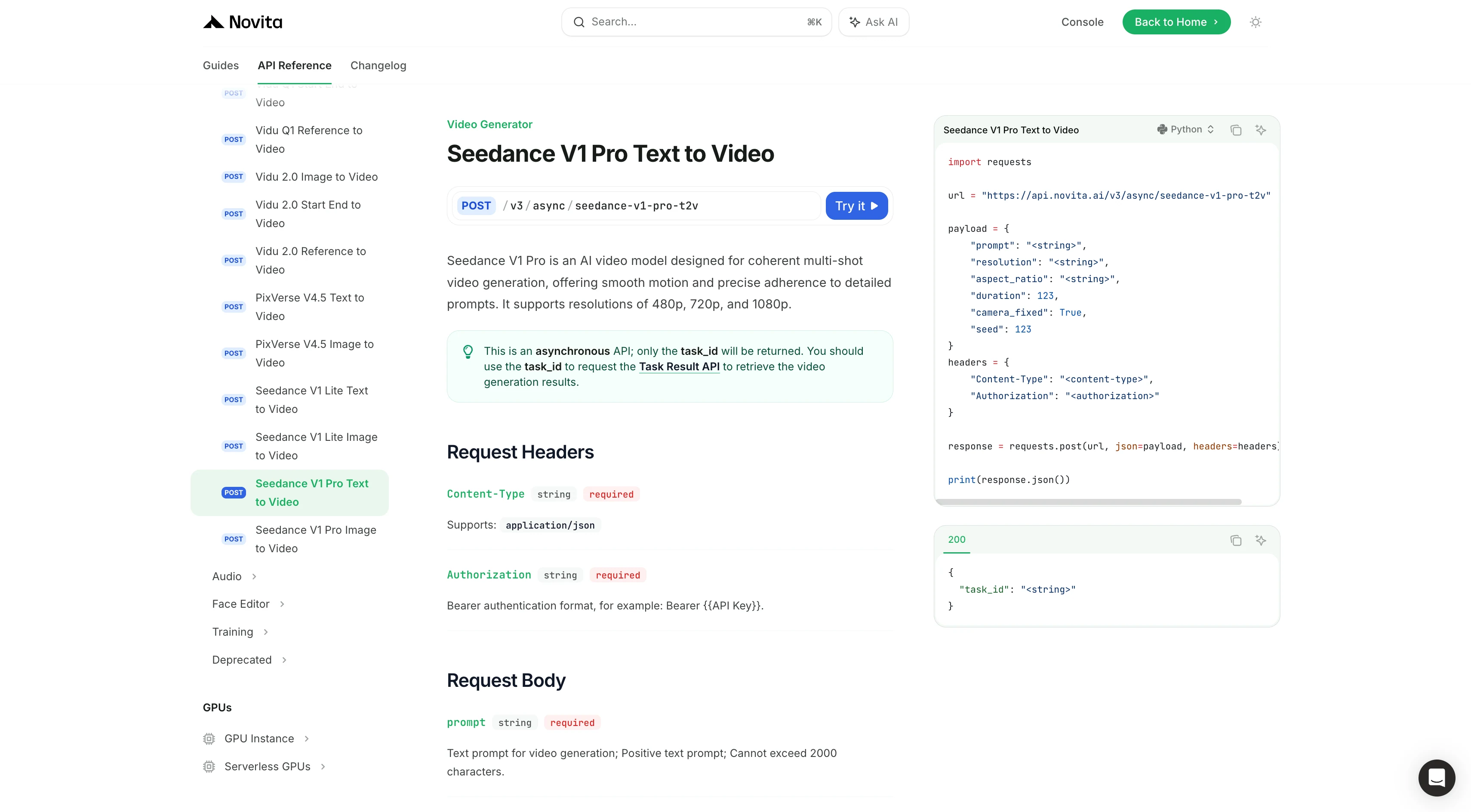
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completaciones de chat para usuarios de Python.
¡Haz clic en “¡Pruébalo!” — luego sigue la plantilla para ingresar tu contenido y crear tu propio prompt de Python!
import requests
url = "https://api.novita.ai/v3/async/seedance-v1-pro-t2v"
payload = {
"prompt": "<string>",
"resolution": "<string>",
"aspect_ratio": "<string>",
"duration": 123,
"camera_fixed": True,
"seed": 123
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
Paso 5: Usa el ID de tarea para obtener la URL del vídeo
import requests
url = "https://api.novita.ai/v3/async/task-result"
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.get(url, headers=headers)
print(response.json())
Seedance V1 I2V se ha consolidado como uno de los modelos más avanzados en generación de vídeo con IA, ofreciendo verdadera narración multi‑toma, consistencia cinematográfica y movimiento fluido en resoluciones de hasta 1080p. Si bien la plataforma oficial de ByteDance aún no permite el uso directo de Seedance V1 para vídeo, los creadores pueden confiar en la API estable y rentable de Novita AI para acceder tanto a la versión Lite como a la Pro por solo $0.13 por corte de vídeo. Con alto rendimiento, asequibilidad e integración flexible de API, Novita AI hace que Seedance V1 sea ampliamente accesible para desarrolladores, artistas y usuarios comerciales.
Preguntas frecuentes
¿Cómo puedo probar los vídeos de Seedance V1 hoy?
Puedes usar la API de Seedance V1 de Novita AI, que ofrece versiones Lite y Pro para generación de vídeo I2V confiable.
¿Hay diferencia de precio entre Lite y Pro?
No significativamente. Gracias a Novita AI, el costo es casi el mismo: solo $0.13 por corte de vídeo.
¿Qué hace único a Seedance V1?
Narración multi‑toma nativa con consistencia de personajes
Movimiento cinematográfico de alta calidad y estabilidad
Admite estilos versátiles y salida HD en 1080p
Novita AI es la plataforma integral en la nube que impulsa tus ambiciones de IA. API integradas, sin servidor, instancias GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



