

Puntos clave
✅ Métodos de entrenamiento:
DeepSeek V3: Preentrenamiento → SFT → RL para adaptabilidad dinámica.
Qwen 2.5: Preentrenamiento específico por dominio (ej., código, matemáticas).
✅ Rendimiento:
DeepSeek lidera en codificación (36% vs. 28%), matemáticas (89% vs. 86%) y benchmarks de razonamiento.
Qwen destaca en tareas multilingües (29 idiomas vs. 3).
✅ Costo y velocidad:
Qwen: Menor costo ($0.38/M tokens de entrada) y salida más rápida.
DeepSeek Turbo: 3× de rendimiento + 20% de descuento para necesidades de alto volumen en Novita AI.
Si buscas evaluar DeepSeek V3 y Qwen 2.5 72B en tus propios casos de uso — Al registrarte, Novita AI te proporciona un crédito de $0.5 para empezar.
La batalla entre los modelos de lenguaje MoE (Mixture of Experts) se intensifica con DeepSeek V3 (dic 2024) y Qwen 2.5 72B (sep 2024). Mientras que DeepSeek apunta a la precisión técnica y la interacción dinámica, Qwen prioriza la eficiencia multilingüe y el ahorro de costos. Esta comparación explora sus fortalezas, debilidades y casos de uso ideales.
Comparación completa: DeepSeek V3 vs. Qwen 2.5 72B
| Categoría | DeepSeek V3 | Qwen 2.5 72B |
|---|---|---|
| Fecha de publicación | 27 dic 2024 | 19 sep 2024 |
| Tamaño del modelo | 671B parámetros (37B activos/token, MoE) | 72B parámetros (MoE) |
| Método de entrenamiento | Preentrenamiento → SFT → RL | Preentrenamiento específico por dominio (ej., datos de código/matemáticas) |
| Datos de entrenamiento | 14.8B tokens | 18B tokens |
| Benchmarks clave | - LiveCodeBench: 36% - GPQA: 56% - MATH-500: 89% - MMLU-Pro: 76% |
- LiveCodeBench: 28% - GPQA: 49% - MATH-500: 86% - MMLU-Pro: 72% |
| Soporte multilingüe | ✅ Chino, Inglés | ✅ 29 idiomas |
| Costo ($/M de tokens) | Entrada: $0.89 Salida: $0.89 Turbo: 3× rendimiento + 20% descuento |
Entrada: $0.38 Salida: $0.40 |
| Requisitos de hardware | VRAM: 171.8GB GPU: 8~16GB (optimizado para MoE) |
VRAM: 145.5GB GPU: Mínimo 32GB |
| Fortalezas | - Razonamiento de alta precisión - Adaptación dinámica a tareas - Alto rendimiento |
- Bajo costo - Cobertura multilingüe - Optimizaciones específicas por dominio |
| Ideal para | I+D técnico, asistentes de IA en tiempo real, procesamiento a escala en la nube | Proyectos con presupuesto ajustado, tareas multilingües estáticas, flujos de trabajo especializados en código/matemáticas |
Mejor para ti
| Requisito | Recomendación |
|---|---|
| Tareas de codificación/matemáticas/QA | ✅ DeepSeek V3 (Mayor precisión) |
| Contenido multilingüe | ✅ Qwen 2.5 (29 idiomas + menor costo) |
| Interacción en tiempo real | ✅ DeepSeek V3 Turbo (optimizado con RL) |
| Presupuesto limitado | ✅ Qwen 2.5 (Rentable) |
| GPU <32GB | ✅ DeepSeek V3 (soporte 8~16GB) |
Introducción básica de los modelos
Para comenzar nuestra comparación, primero comprendamos las características fundamentales de cada modelo.
DeepSeek V3
- Fecha de publicación: 27 de diciembre de 2024
- Escala del modelo:
- Características clave:
- Tamaño del modelo: 671B parámetros (37B activos/token)
- Tokenizador: Tokenizador multilingüe basado en SentencePiece
- Idiomas compatibles: Enfocado en chino e inglés
- Multimodal: Solo texto
- Ventana de contexto: 128K tokens
- Formatos de almacenamiento: Inferencia FP8/BF16
- Arquitectura: Mixture of Experts (MoE) + Multi-Head Latent Attention
- Datos de entrenamiento: 14.8B tokens para preentrenamiento
- Método de entrenamiento: Preentrenamiento → Supervised Fine-Tuning (SFT) → Reinforcement Learning (RL)
Qwen 2.5 72B
- Fecha de publicación: 19 de septiembre de 2024 (serie Qwen 2.5)
- Escala del modelo:
- Características clave:
- Tamaño del modelo: 72B parámetros
- Idiomas compatibles: sólido soporte multilingüe para más de 29 idiomas
- Multimodal: Solo texto
- Ventana de contexto: soporta hasta 128K tokens y puede generar hasta 8K tokens
- Arquitectura: Mixture of Experts (MoE) + Multi-Head Latent Attention
- Datos de entrenamiento: Entrenamiento en un conjunto de datos extenso de 18 billones de tokens
- Método de entrenamiento: preentrenamiento según diferentes datos
DeepSeek V3 aprovecha el entrenamiento en múltiples etapas con Supervised Fine-Tuning (SFT) y Reinforcement Learning (RL), permitiendo una optimización continua a partir de la retroalimentación humana (ej., seguimiento de instrucciones, alineación de seguridad). Su arquitectura MoE ajusta dinámicamente los pesos de los expertos, permitiendo que un solo modelo se adapte de manera flexible a tareas de múltiples dominios (ej., generación de código, razonamiento matemático) sin necesidad de reentrenamiento específico para cada tarea.
En contraste, Qwen 2.5 72B depende únicamente del preentrenamiento y requiere reentrenar modelos especializados para diferentes dominios (ej., Qwen2.5-Coder para código y Qwen2.5-Math para matemáticas). Aunque estos modelos especializados logran mejoras significativas de rendimiento gracias a grandes cantidades de datos específicos por dominio (ej., 5.5B tokens de código para Qwen2.5-Coder) y métodos de razonamiento multimodales (CoT, PoT, TIR), su generalización está limitada por distribuciones de datos estáticas, lo que los hace más adecuados para tareas especializadas (ej., evaluación de programación, razonamiento matemático bilingüe) que para escenarios interactivos dinámicos.
Comparación de velocidad
Si deseas probarlo tú mismo, puedes iniciar una prueba gratuita en el sitio web de Novita AI.
¡Prueba ahora DeepSeek V3 Turbo, rentable pero de tamaño completo!
Comparación de velocidad
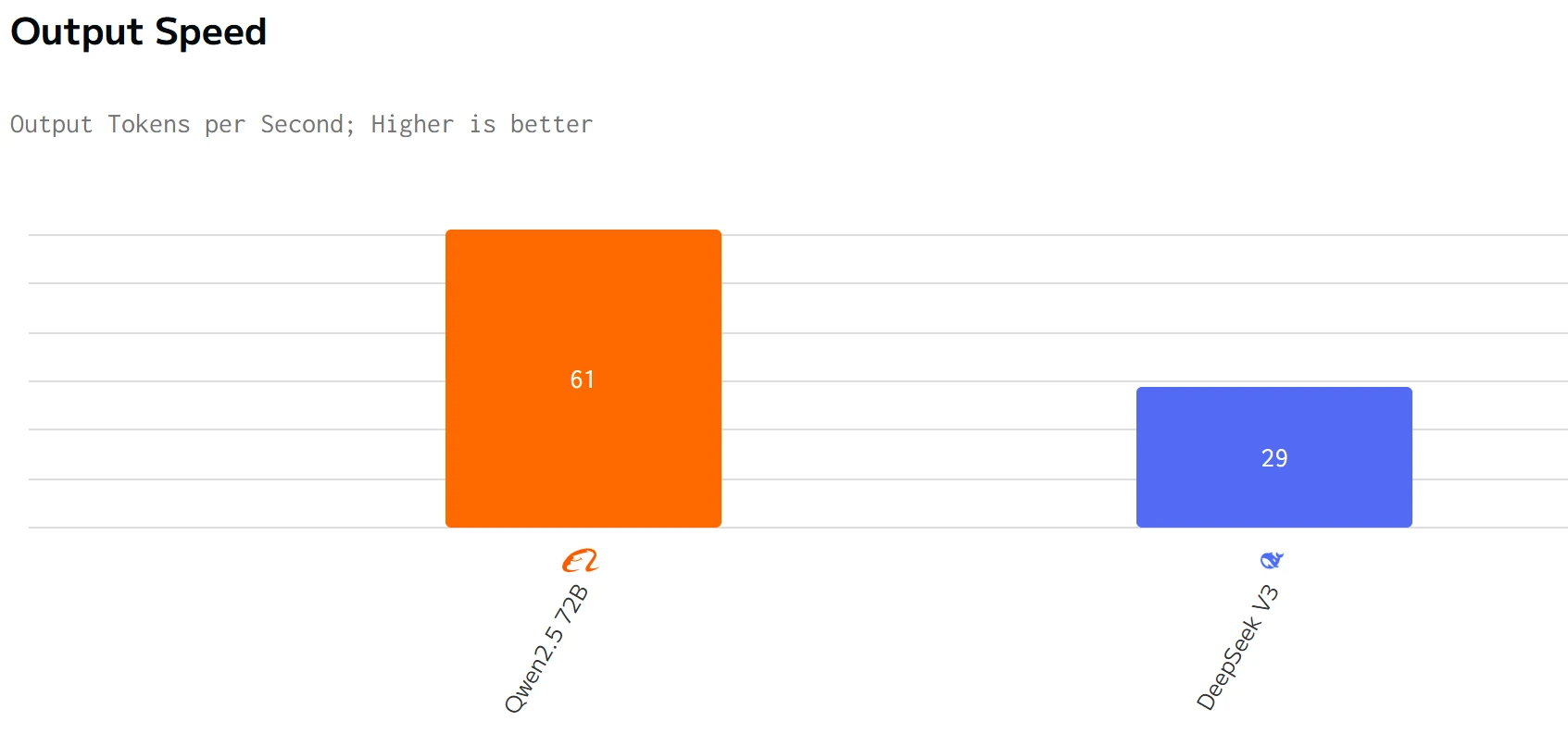
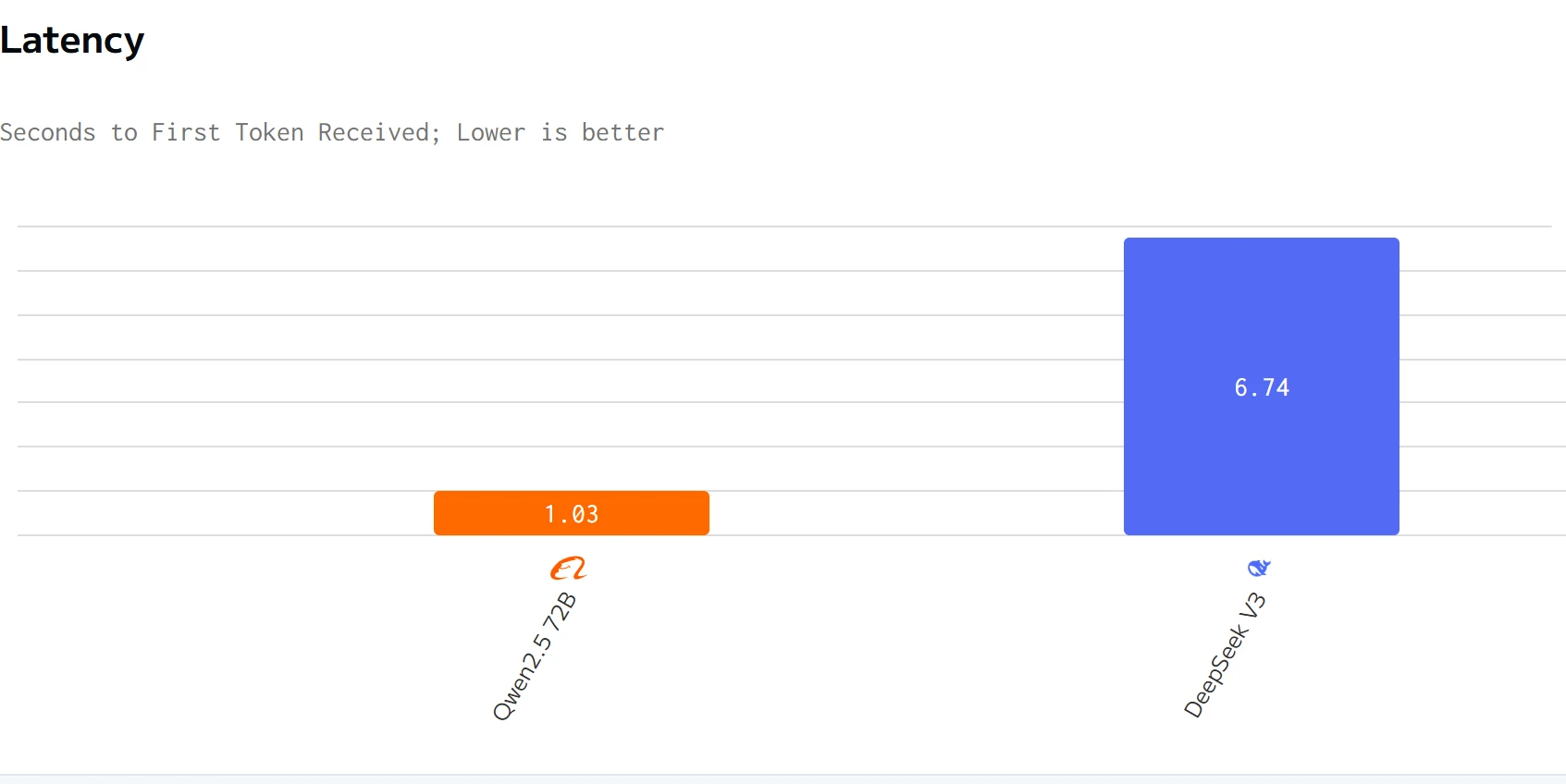
fuente: artificialanalysis
Comparación de costos en Novita AI
| Modelo | Contexto | Precio de entrada ($/M de tokens) | Precio de salida ($/M de tokens) |
|---|---|---|---|
| deepseek/deepseek-v3-turbo | 64000 | $0.4 | $1.3 |
| deepseek/deepseek_v3 | 64000 | $0.89 | $0.89 |
| qwen/qwen-2.5-72b-instruct | 32000 | $0.38 | $0.4 |
Qwen 2.5 72B supera a DeepSeek V3 en velocidad de salida y latencia. Los precios de entrada y salida de DeepSeek V3 son significativamente más altos que los de Qwen 2.5 72B.
Vale la pena señalar que Novita AI lanza una versión Turbo con 3x de rendimiento y un descuento por tiempo limitado del 20%. ¡Pruébalo ahora!

Comparación de benchmarks
Ahora que hemos establecido las características básicas de cada modelo, profundicemos en su rendimiento en varios benchmarks. Esta comparación ayudará a ilustrar sus fortalezas en diferentes áreas.
| Benchmark | DeepSeek V3 (%) | Qwen 2.5 72B (%) |
|---|---|---|
| LiveCodeBench (Codificación) | 36 | 28 |
| GPQA Diamond | 56 | 49 |
| MATH-500 | 89 | 86 |
| MMLU-Pro | 76 | 72 |
Estos resultados sugieren que el enfoque de aprendizaje por refuerzo iterativo impulsado por máquina de DeepSeek V3 puede ser particularmente efectivo para desarrollar capacidades más sólidas en dominios técnicos especializados que requieren razonamiento preciso y habilidades de resolución de problemas estructurados.
Si deseas ver más comparaciones, puedes consultar estos artículos:
- Deepseek v3 vs Llama 3.3 70b: Tareas de lenguaje vs. Código y matemáticas
- Llama 3.2 3B vs DeepSeek V3: Comparando eficiencia y rendimiento.
Requisitos de hardware
| Modelo | VRAM | GPU recomendada |
| DeepSeek V3 | 171.8GB | 8x RTX4090 o 4 x A100 o 2 x H100 |
| Qwen 2.5 72B | 145.5GB | 8x RTX4090 o 4 x A100 o 2 x H100 |
Aplicaciones y casos de uso
DeepSeek V3
Casos de uso:
- Tareas técnicas de alta precisión: Generación de código, razonamiento matemático y QA complejo (ej., herramientas de programación, análisis de I+D).
- Interacción dinámica: Asistentes de IA en tiempo real que requieren cumplimiento de instrucciones y alineación de seguridad (ej., finanzas, asesoría legal).
- Alto rendimiento: La versión Turbo es adecuada para procesamiento por lotes a gran escala (ej., manejo de documentos multilingües, servicios en la nube).
Fortalezas:
- Rendimiento superior en codificación (LiveCodeBench: 36%), matemáticas (MATH-500: 89%) y razonamiento (GPQA: 56%).
- La arquitectura MoE reduce los parámetros activos (37B/671B), equilibrando eficiencia y precisión.
Qwen 2.5 72B
Casos de uso:
- Tareas multilingües estáticas: Generación/traducción de contenido en 29 idiomas (ej., marketing global, documentación localizada).
- Flujos de trabajo específicos por dominio: Modelos especializados reentrenados (ej., Qwen2.5-Coder para evaluación de código, Qwen2.5-Math para resolución de problemas bilingüe).
- Proyectos con presupuesto limitado: Menor costo ($0.38/M tokens de entrada) para necesidades multilingües básicas (ej., startups, investigación académica).
Fortalezas:
- Grandes volúmenes de datos específicos por dominio (5.5B tokens de código para modelos de codificación).
- Soporta diversos métodos de razonamiento (CoT, PoT, TIR) para tareas estructuradas.
Acceso e implementación a través de Novita AI
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona una GPU en la nube asequible y confiable para construir y escalar.
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

¡Prueba la demo de DeepSeek V3 ahora!
Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Settings” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Al registrarte, Novita AI proporciona un crédito de $0.5 para que empieces.
Si se agotan los créditos gratuitos, puedes pagar para continuar usándolo.
Elige DeepSeek V3 para precisión técnica y adaptabilidad, o Qwen 2.5 72B para tareas multilingües rentables. Para empresas, el aumento de rendimiento de DeepSeek Turbo y la prueba gratuita de Novita AI lo convierten en una opción atractiva.
Preguntas frecuentes
¿Comparación de costos entre Qwen 2.5 72B y Deepseek V3?
Qwen cuesta $0.38/M tokens de entrada frente a $0.89/M de DeepSeek.
¿Por qué elegir Qwen 2.5?
Por su soporte multilingüe (29 idiomas) o presupuestos ajustados.
¿Cómo probar Qwen 2.5 72B y Deepseek V3?
Prueba DeepSeek V3 Turbo en Novita AI con un 20% de descuento.
Novita AI es la plataforma integral en la nube que impulsa tus ambiciones de IA. API integradas, sin servidor, instancias de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



