Diving Into the Academic Frontier: An Introduction of Large Language Models Differential Privacy

Introduction
As machine learning technologies become increasingly prevalent, the need to ensure the privacy and security of the data used to train these LLMs has become a critical concern. One key approach to addressing this challenge is the use of differential privacy (DP) techniques.
In this article, we will delve into the concept of Large Language Models differential privacy, exploring how it works, the challenges involved, and the potential solutions being explored by researchers. By understanding the intricacies of DP for LLMs, we can gain insights into the broader implications of privacy-preserving machine learning.
What Is Large Language Models Differential Privacy?
Differential privacy (DP) is a rigorous mathematical framework for training machine learning models, including large language models like GPT-3 and BERT, in a way that provably protects the privacy of the training data. The core principle is to ensure the model’s outputs do not reveal too much information about any individual data point used during the training process. This is achieved through a combination of techniques applied throughout the model training pipeline.
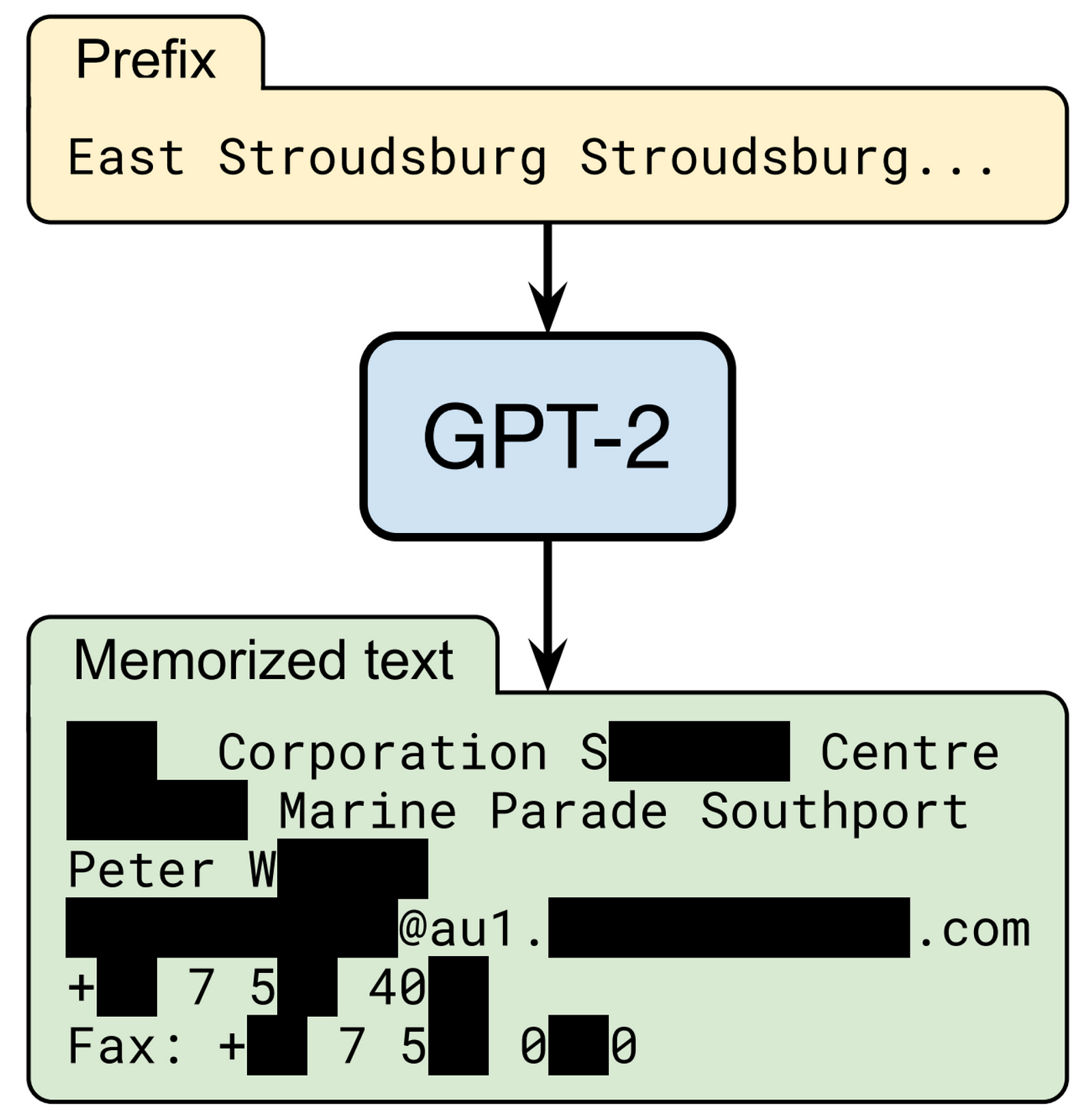
How Does Large Language Models Differential Privacy Work?
1 Gradient Clipping
Gradient clipping is a key technique for enforcing differential privacy during language model training.
Imagine the training data as a mountain range, and the gradients (updates to model parameters) as ropes attached to different peaks. Without clipping, some ropes would be very thick, corresponding to training examples with outsized influence. This allows the model to “memorize” specific data, compromising privacy.
Gradient clipping puts a strict limit on the thickness of these ropes. No single rope can be thicker than the limit. This ensures the model updates draw equally from all training data, preventing any one example from dominating.
It’s like capping the ropes to make the mountain peaks more even. This makes it much harder to identify and extract information about specific training data.

2 Adding Noise
After clipping the gradients (ropes) to a fixed thickness, we add random noise to them. Imagine spraying each rope with a fine mist — the mountains are now obscured by a hazy cloud. This further prevents any single training example from standing out and being identified, reinforcing the differential privacy guarantees.
3 Tracking Privacy Loss
We carefully keep tabs on the “privacy budget” being spent as the model is trained. Each update to the model parameters, each batch of training data processed, incurs a small amount of privacy loss. It’s like we’re keeping a running tally, making sure the total amount of “privacy spent” doesn’t exceed a safe limit, even after seeing millions of training examples. This rigorous accounting ensures the final model respects the desired level of differential privacy.
The end result is a language model that has been trained in a privacy-preserving way. It can then be used without revealing sensitive information about the individuals whose data was used to create it. Of course, there is usually some tradeoff in terms of the model’s overall performance, but researchers are working to minimize this.
What Are the Problems of Large Language Models Differential Privacy?
Disparate Impact on Model Accuracy
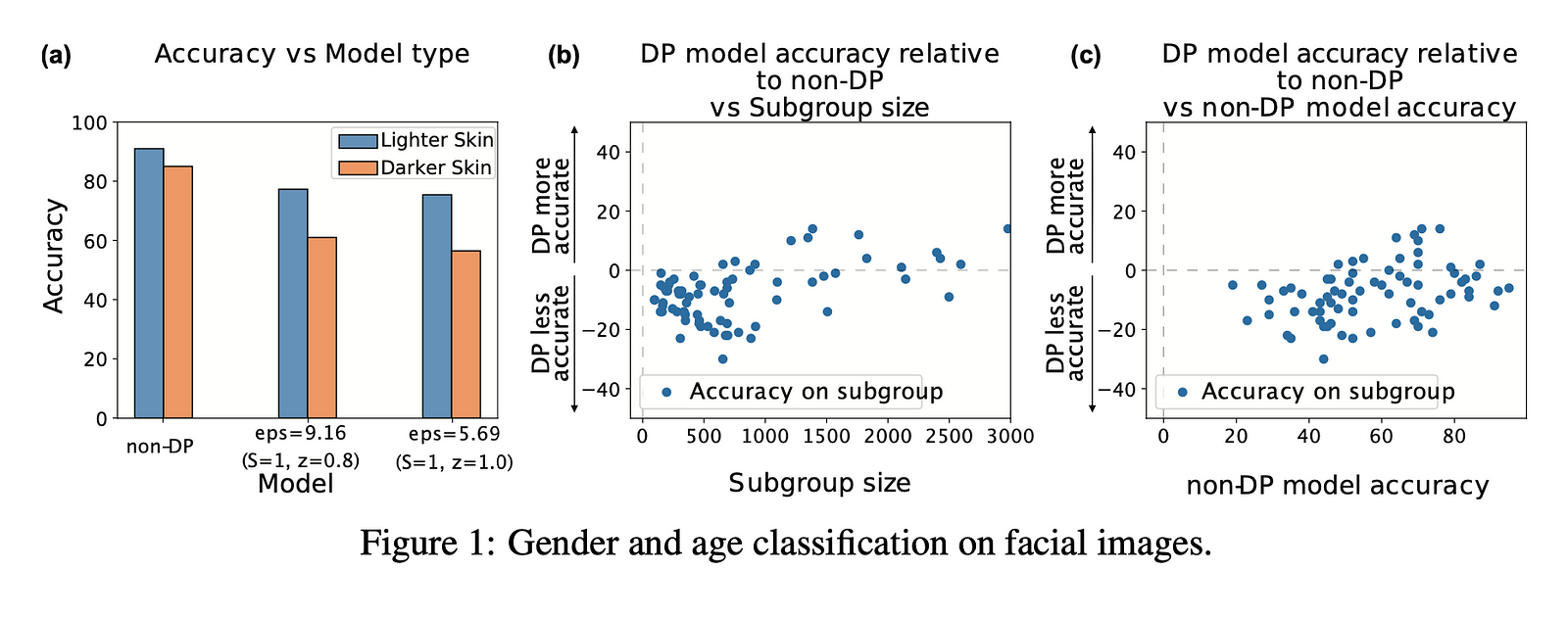
- Applying differential privacy (DP) techniques like gradient clipping and adding noise to the training process has a disproportionately negative impact on the accuracy of large language models (LLMs) for underrepresented or minority subgroups in the data.
- For example, in the gender and age classification tasks, the DP-trained models exhibited much lower accuracy on faces with darker skin tones compared to lighter skin tones. This was not the case for the non-DP models.
- The “the poor get poorer” effect means the DP training hurts accuracy the most for the classes or subgroups that already had lower accuracy in the original, non-DP model. So it amplifies the unfairness of the model.
- This happens because the DP mechanisms like gradient clipping and noise addition have an outsized effect on the gradients and training signal coming from the underrepresented or harder-to-learn parts of the data. The model ends up biased even more towards the majority, simpler subgroups.
Challenges with Large/Complex Models
- Modern large language models like GPT-3 or BERT have billions of parameters and immense complexity. Applying DP techniques to these models is computationally very expensive and challenging.
- The gradients in these complex models may be too sensitive to the random noise required for DP. This sensitivity limits the accuracy that can be achieved with DP training, even after extensive hyperparameter tuning. The DP model’s performance simply plateaued far below the non-DP version.
Privacy-Utility Tradeoff
- To maintain a reasonable privacy budget, as measured by the DP parameter ε being less than 10, the DP-trained LLMs often suffer substantial drops in accuracy compared to their non-DP counterparts.
- Increasing the privacy budget could improve the model’s accuracy, but this comes at the cost of much higher privacy leakage, which may be unacceptable in many real-world applications.
- There is a fundamental tension between preserving privacy and maintaining high utility (accuracy) of the language model. Achieving both simultaneously is extremely challenging.
Difficulty Combining DP with Other Fairness Techniques
- Standard techniques used to improve the fairness of machine learning models, like oversampling or reweighting underrepresented groups, are incompatible with the sensitivity constraints required for differential privacy.
- The documents note that the DP mechanisms, such as gradient clipping and noise addition, essentially override or negate the effects of these fairness-promoting techniques.
Is There a Way to Ensure Both Privacy and Model Performance?
Typically, when you apply the standard differential privacy (DP) optimization techniques like DP-SGD to train large language models, the performance ends up much worse than non-private models. This is because the noise added for privacy protection tends to scale with the model size, and large models have high-dimensional gradients.
Interestingly, in the paper titled Large Language Models Can Be Strong Differentially Private Learners by Xuechen Li, Florian Trame, Percy Liang and Tatsunori Hashimoto from Stanford University and Google Research presented a way to balance both privacy and model performance. To obtain this balance, the authors take a few smart approaches. Same as before, if research details do not interest you, just skip to the next section about an efficient solution for your own project.
1 Leveraging Pretrained Language Models
The authors found that using large, pretrained language models like BERT and GPT-2 as the starting point for fine-tuning was much more effective than training a new model from scratch. These pretrained models have already learned rich linguistic knowledge, so fine-tuning them with differential privacy is easier than trying to learn everything from the limited private training data.
2 Tuning Differentially Private Stochastic Gradient Descent (DP-SGD) Hyperparameters
The authors discovered that DP-SGD is highly sensitive to the choice of hyperparameters. Contrary to the typical small batch sizes and learning rates used in non-private fine-tuning, they found that using much larger batch sizes (e.g. 2048) and learning rates (e.g. 2^-5) led to significantly better performance under the same privacy budget. This suggests the standard hyperparameter settings for non-private learning are not well-suited for DP optimization.
3 Aligning Fine-tuning Objective with Pretraining
The authors observed that fine-tuning objectives more closely aligned with the original pretraining objective of the language model tended to work better under differential privacy. For example, instead of just predicting the sentence classification label, they had the model also predict missing words in the sentence — a task more similar to the language modeling pretraining. This allowed the model to better leverage the language understanding abilities learned during pretraining.
4 Introducing “Ghost Clipping”
A key challenge with DP-SGD is the high memory requirement of storing per-example gradients for the clipping step. The authors developed a new memory-efficient technique called “ghost clipping” that allows running DP-SGD on large Transformer models without this high memory cost. This technique generalizes the Goodfellow (2015) trick to handle sequential inputs, enabling DP fine-tuning with roughly the same memory as non-private training.
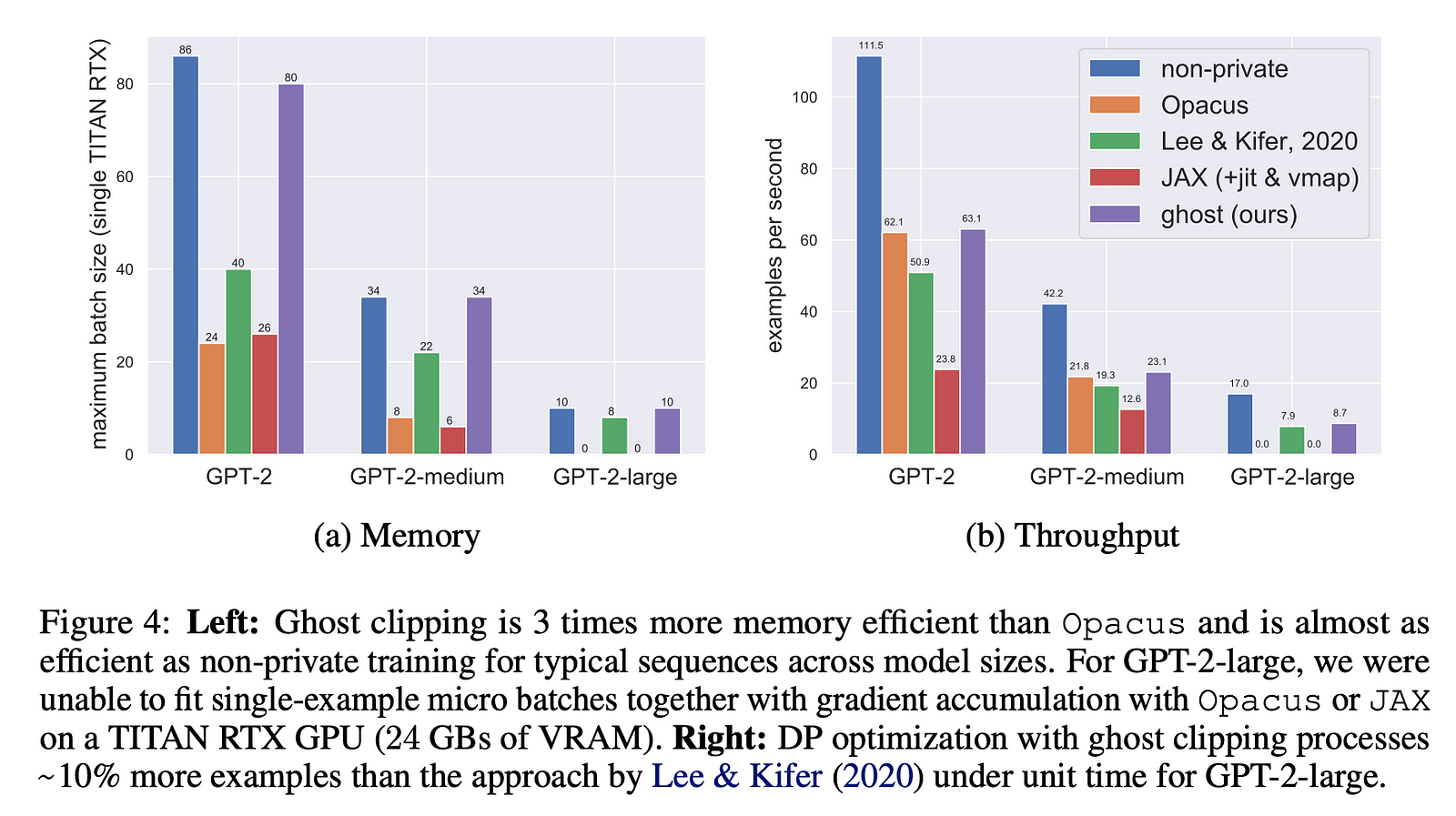
With these innovations, the authors are able to fine-tune large pretrained language models under differential privacy, and obtain models that match or even outperform strong non-private baselines. This shows it is possible to build practical private language models without sacrificing too much performance.
Future Directions of Large Language Models Differential Privacy
Developing Targeted DP Training Techniques
- The standard DP training approaches can sometimes have a disparate impact on underrepresented groups in the data.
- The idea is to explore adjusting the DP mechanisms, like clipping and noise addition, in a more targeted manner to better protect the privacy of underrepresented groups without unduly impacting their model performance.
- This could involve new DP training algorithms or modifications that are more sensitive to the needs of different data subgroups.
Combining DP with Other Fairness Approaches
- Fairness and privacy can sometimes be at odds in machine learning.
- This direction aims to investigate how DP can be combined with other fairness-enhancing techniques, such as adversarial debiasing or causal modeling, while preserving the privacy-preserving properties of DP.
- The goal is to develop hybrid approaches that achieve strong privacy guarantees and improved fairness outcomes, especially for underrepresented groups.
Understanding the Interaction Between DP and Fairness Notions
- Fairness can be defined in multiple ways, like equal opportunity or demographic parity.
- This direction focuses on understanding how DP interacts with these different fairness criteria, particularly in the context of large language models.
- Exploring this interaction can help researchers and practitioners navigate the trade-offs and synergies between DP and various fairness notions.
Analyzing DP’s Impact on Model Generalization
- DP training can introduce noise and constraints that may impact a model’s ability to generalize, especially for underrepresented and complex data subgroups.
- This direction aims to deepen the understanding of how DP affects the model’s overall and subgroup-specific generalization performance.
- Gaining this understanding can inform the design of DP techniques that balance privacy, fairness, and generalization, particularly for challenging data subsets.
Conclusion
As the use of large language models continues to grow, the need to balance their impressive capabilities with robust privacy protections has become increasingly important. The research efforts outlined in this article highlight the ongoing work to develop more effective and efficient differential privacy techniques for LLMs, with a focus on mitigating the disparate impact on underrepresented groups and finding ways to combine DP with other fairness-enhancing approaches.
By addressing the key challenges around computational complexity, sensitivity, and the privacy-utility tradeoff, researchers have shown it is possible to build practical private language models without sacrificing too much performance. As these advancements continue, we can expect to see the emergence of LLMs that not only deliver state-of-the-art performance but also uphold rigorous privacy standards, paving the way for a future where AI systems can be trusted to handle sensitive data with the utmost care and responsibility.
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.