Decoding Mixtral of Experts: Complete Guide

Mixtral of Experts means Mixtral 8x7B and Mixtral 8x22B using SMoE. Explore features and applications about Mixtral of Experts on our blog.
Key Highlights
- Mixtral 8x7B and Mixtral 8x22B are leading open-source language models developed by Mistral AI.
- These models utilize a Sparse Mixture of Experts (SMoE) architecture, with Mixtral 8x22B employing only 39B active parameters out of 141B.
- Mixtral excels in various tasks, including code generation, multilingual understanding, and long-range context handling, surpassing larger language models in performance.
- Its exceptional performance, coupled with its open-source nature, positions Mixtral as a powerful tool for developers seeking to integrate advanced AI capabilities into their applications.
Introduction
The field of Natural Language Processing (NLP) is always changing. New advancements continue to enhance our capabilities, with the Mixtral model standing out as a prime illustration. Operating on a blend of expert approaches within a transformer framework, Mixtral will be examined in detail in this guide. The blog will encompass its features, functionalities, and potential applications in language processing-dependent sectors.
What is a Mixtral of Experts?
What are Mixtral 7B and Mixtral 8x22B?
Mixtral 8x7B and Mixtral 8x22B developed by Mistral AI are advanced large language models. Mixtral 8x7B and Mixtral 8x22B are open-source weight models known for their high efficiency. These models are accessible under an Apache 2.0 license, ensuring improved accessibility. They are particularly valuable for tasks that need customization and fine-tuning, offering faster performance, increased portability, and better control as key features.
What is a Sparse Mixture of Experts?
Mixtral utilizes a sparse mixture of experts (SMoE) approach for efficiency. Instead of using all parameters simultaneously, it employs a router network to select a small group of experts for each input token. This targeted selection enhances performance by focusing on relevant model components and is done by a gating network in the moe layer. By activating only essential parameters, Mixtral achieves higher throughput and processes information faster, making it ideal for complex NLP tasks with large datasets.
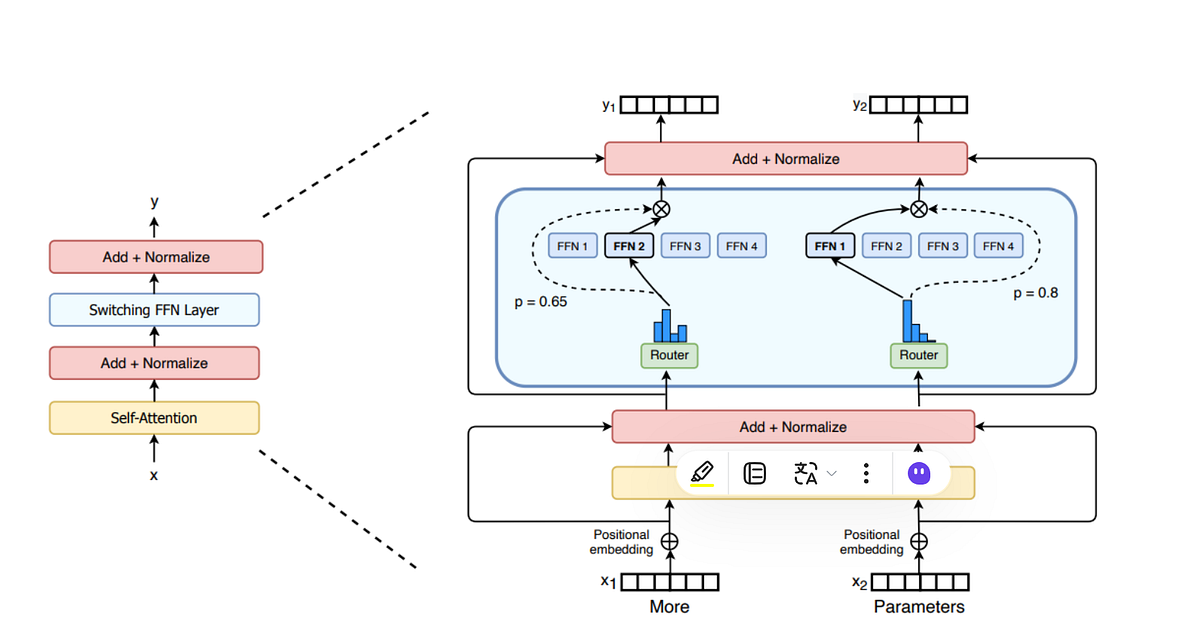
Capabilities of Mixtral
Leveraging innovations like Grouped-Query Attention (GQA) and Sliding Window Attention (SWA), Mixtral excels in swiftly managing intricate tasks by leveraging model parallelism. Mixtral can divide complex problems into simpler ones with advanced training strategies. The weighted sum of outputs from diverse experts in the MoE layer enhances its performance by capturing complexities that single-structured models may miss.
Technical Features of Mixtral of Experts
Mixtral 8x7B
- Multilingual abilities in English, French, Italian, German and Spanish
- Strong coding performance
- Finetuned into an instruction-following model
- 32k tokens context window
Mixtral 8x22B
- 64K tokens context window
- Fluent in English, French, Italian, German, and Spanish
- Strong mathematics and coding capabilities
- Natively supports function calling
Performance Benchmark of Mixtral
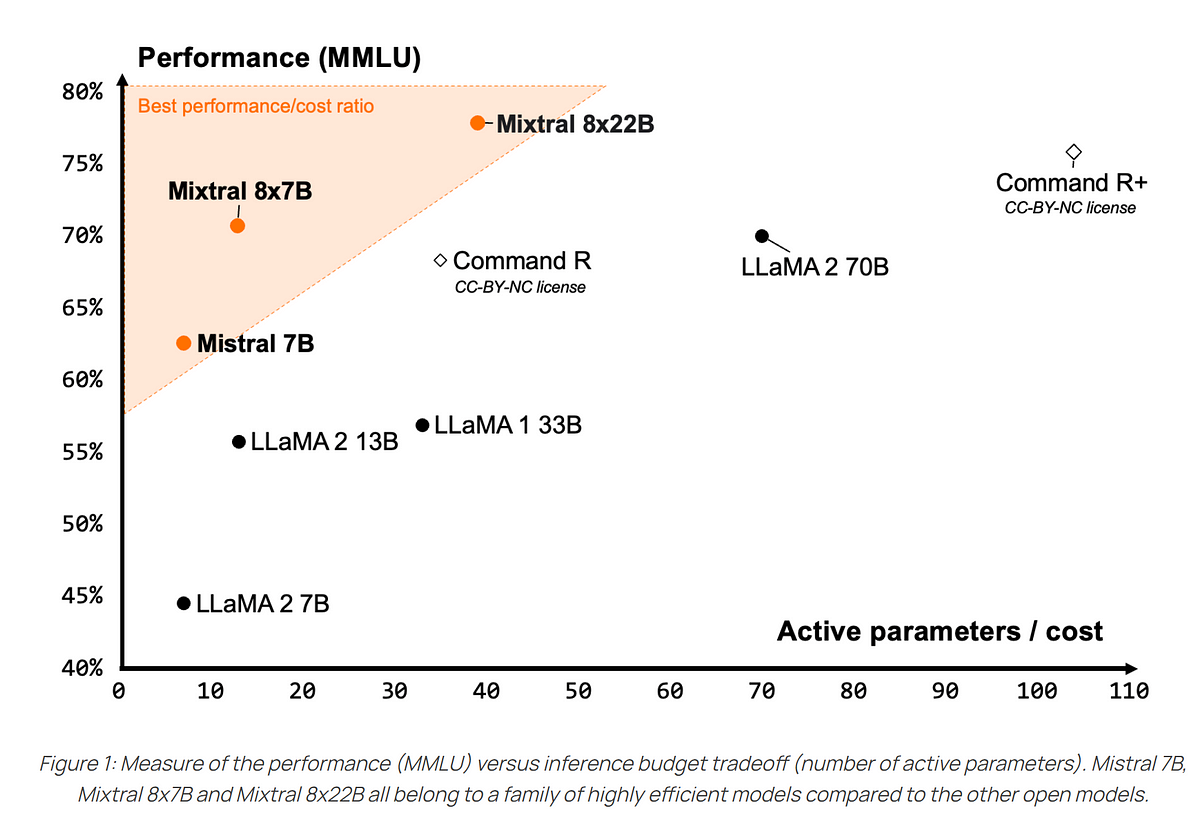
The following is a graph of the performance of Mixtral 8x22B and Mixtral 8x7B. This is derived from models provided by the community. Mixtral 8x22B is the latest model in Mistral’s open model family. With sparse activation patterns, it is a much more powerful alternative to the 70B model and surpasses other open-weight models. Its availability as a base model makes it ideal for fine-tuning various use cases.
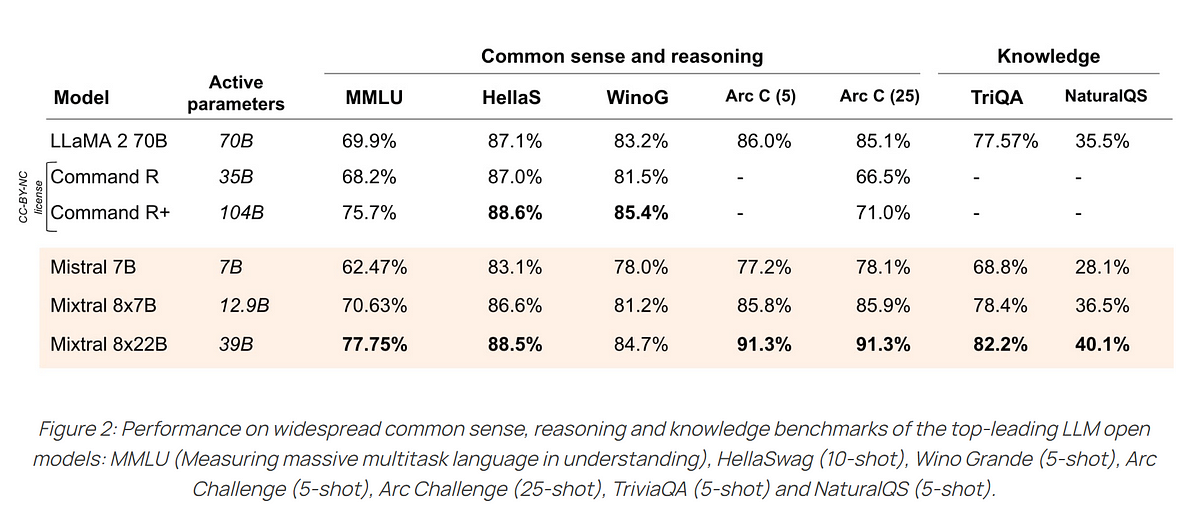
In reasoning capabilities, Mixtral 8x7B and Mixtral 8x22B also outperform Llama 2 70B, the current foundational model for expanding large language models to languages that are widely spoken but underrepresented in the training data of these language models.
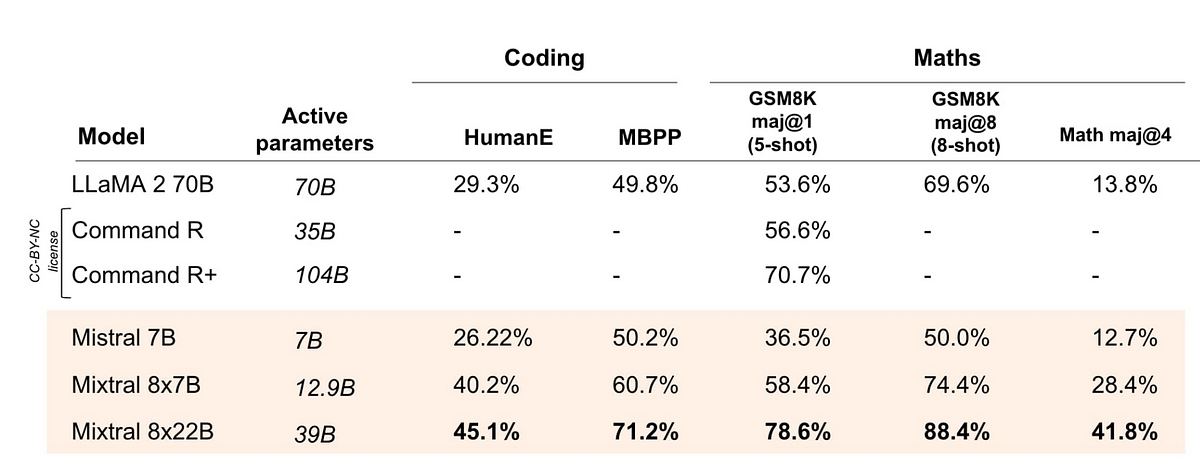
These Mixtral models of experts show great coding and maths capabilities. Mixtral outperforms its predecessor, Llama 2 70B, using only 13 billion active parameters per token, a significant reduction from 70 billion to save computational cost.
Novita AI provides these two models, you can check for detailed info on our LLM Model API.


Practical Applications of Mixtral
Mixtral’s technical prowess extends beyond its capabilities. Its ability to generate human-like text makes it ideal for coding, language translation, and content creation. Being open source, Mixtral is accessible to a wide range of industries. Developers can tailor the model to suit specific requirements for it facilitates the development of new methods and applications.
Content Generation
One of the primary applications of Mistral of Experts and any LLM is to generate text based on your initial prompts. At the core of this functionality is extensive training of the model on diverse datasets containing a vast amount of text from various domains. Through this extensive training, the model can master different writing styles, topics, and language structures, enabling it to excel in producing text that meets specific tone or content requirements.
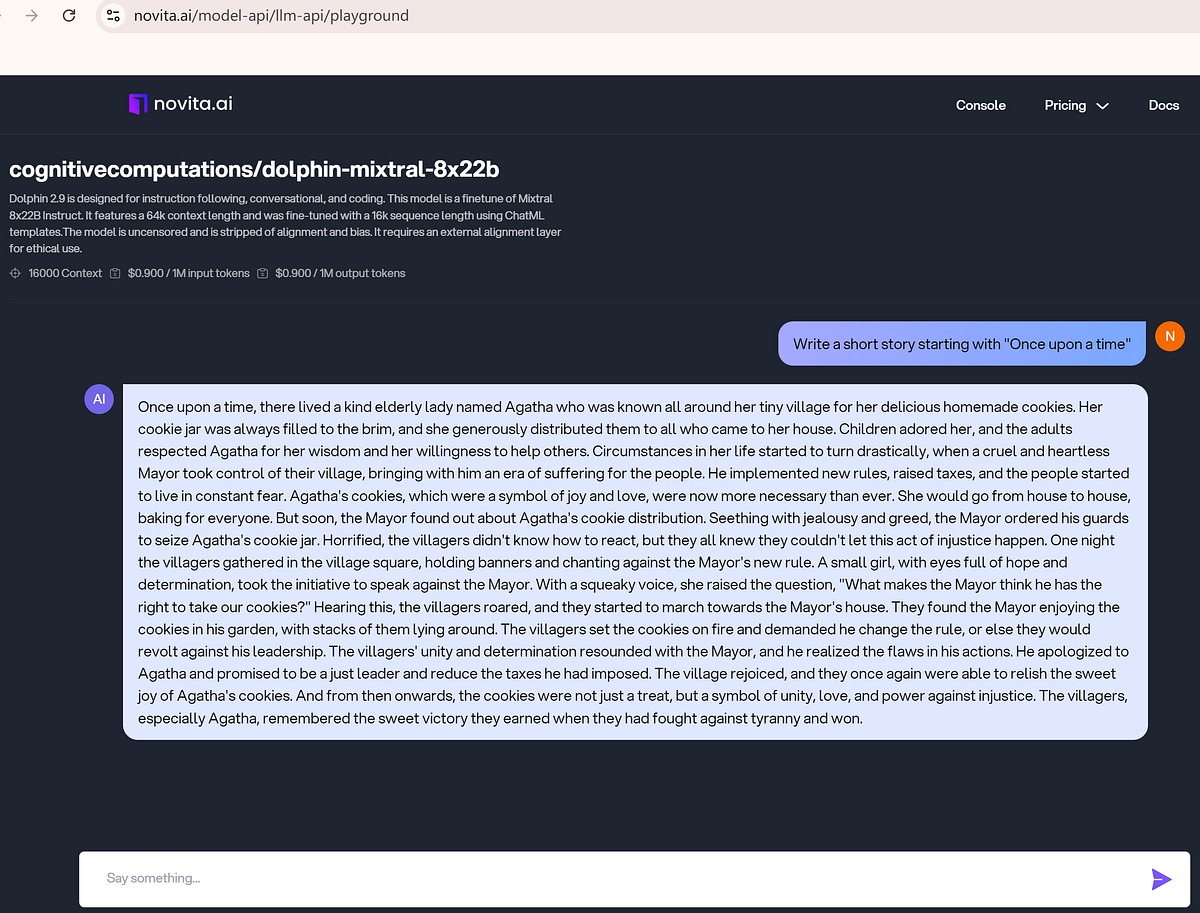
Emotion Analysis
Mistral’s emotion analysis, powered by deep learning, accurately detects positive, negative, and neutral emotions in the text during the chat. It leverages extensive training on diverse datasets to infer emotional tones and differentiate emotions in various content types. You can request Mistral to analyze the emotions in a specific text.
Mixtral 8x22B Sample Code
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring: /docs/get-started/quickstart.htmll#_3-create-an-api-key
api_key="<YOUR Novita AI API Key>",
)
model = "cognitivecomputations/dolphin-mixtral-8x22b"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)Text Translation and Multilingual Tasks
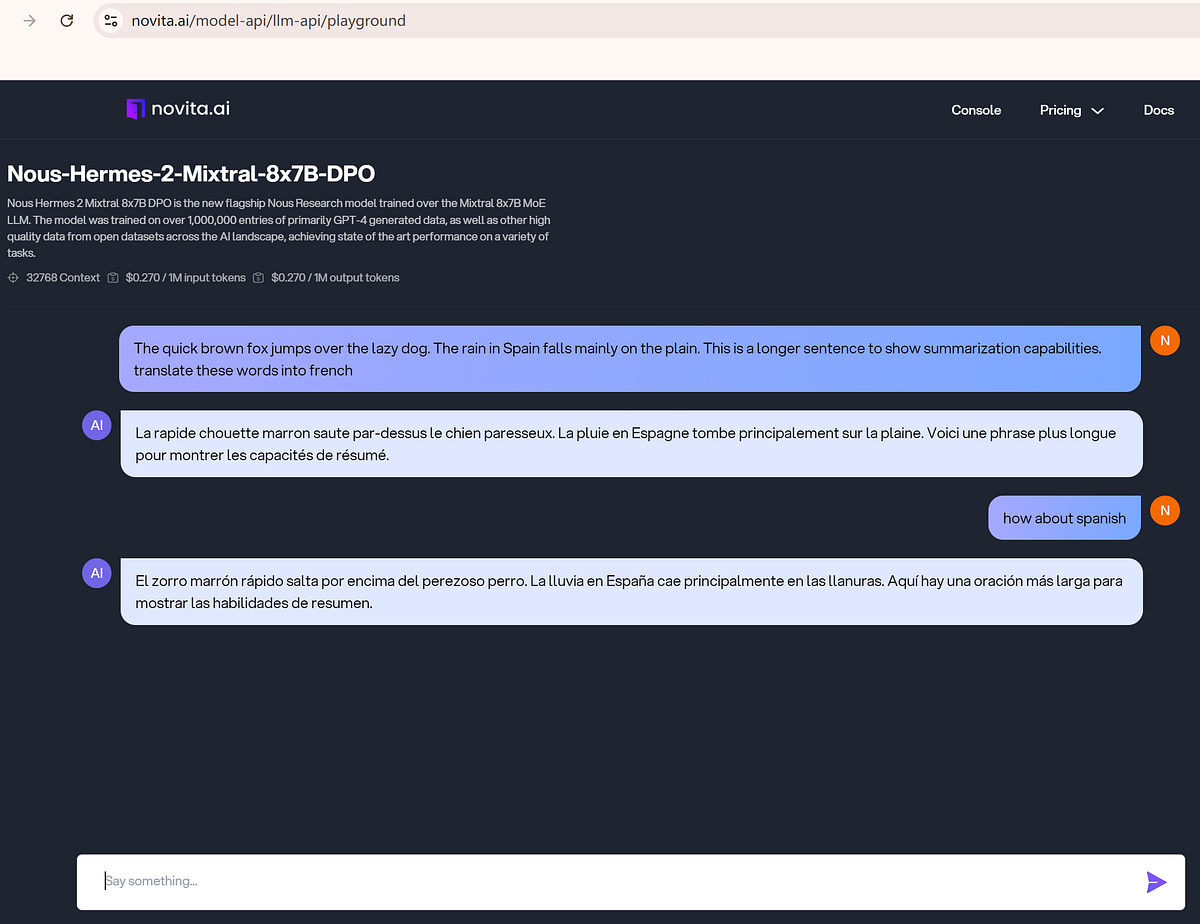
Mistral also demonstrates excellent capabilities in handling multilingual tasks. Specifically trained, Mistral can understand and generate text in various languages, particularly French, German, Spanish, and Italian. Mistral is particularly valuable for businesses and users who need to communicate in multiple languages.
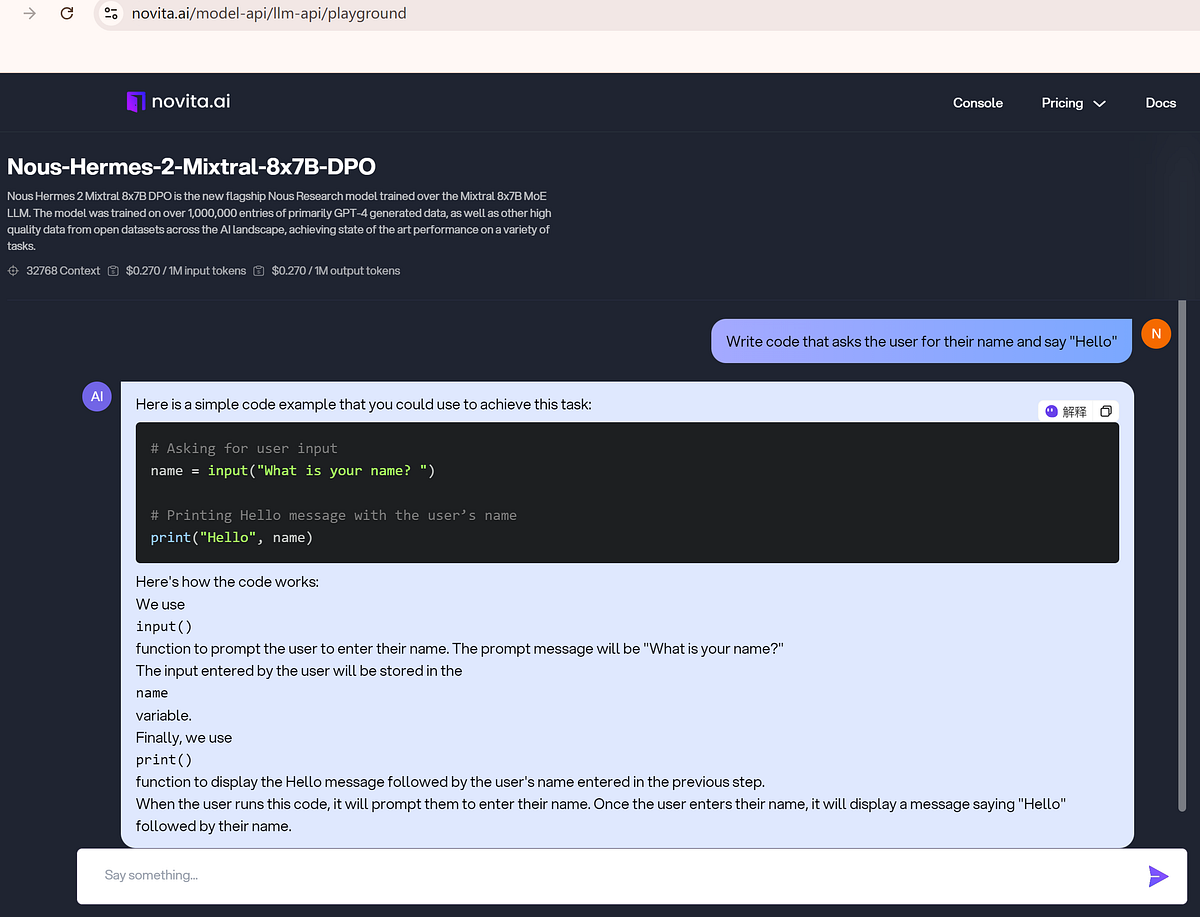
Code Generation
With the given input, the Mistral of Experts model excels in code generation, converting high-level descriptions into efficient code in multiple programming languages. It uses training from code repositories, technical documentation, and developer forums to meet requirements and ensure functionality and optimization.
Mixtral 8x7B Sample Code
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring: /docs/get-started/quickstart.htmll#_3-create-an-api-key
api_key="<YOUR Novita AI API Key>",
)
model = "Nous-Hermes-2-Mixtral-8x7B-DPO"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)Developer’s Guide to Leveraging Mixtral: LLM API
Adding the Mixtral model to apps is an exciting opportunity for developers. It’s open-source and customizable to specific needs. To utilize Mixtral effectively, developers must understand its functionality and APIs. We recommend Novita AI for cost-effective LLM API integration, as this AI API platform is equipped with featured models and affordable LLM solutions.
Get started with Novita AI API
- Step 1: Enter Novita AI and Create an account. You can log in with Google or GitHub. Your first login will create a new account. It’s okay to sign up for things using your email address.
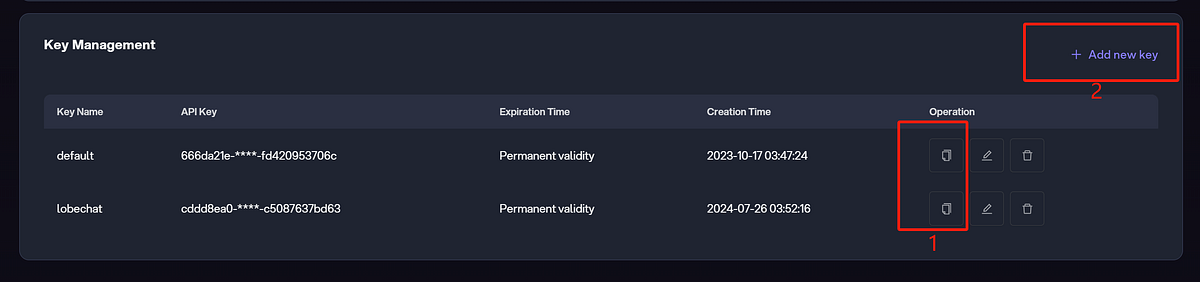
- Step 2: Manage API Key. Novita AI authenticates API access using Bearer authentication with an API Key in the request header. Go to “Key Management” to manage your keys. Once you log in first, a default key is automatically created. You can also click “+ Add new key”.
- Step 3: Make an API call. Go to Model API Reference, and enter your API key to continue the following tasks.
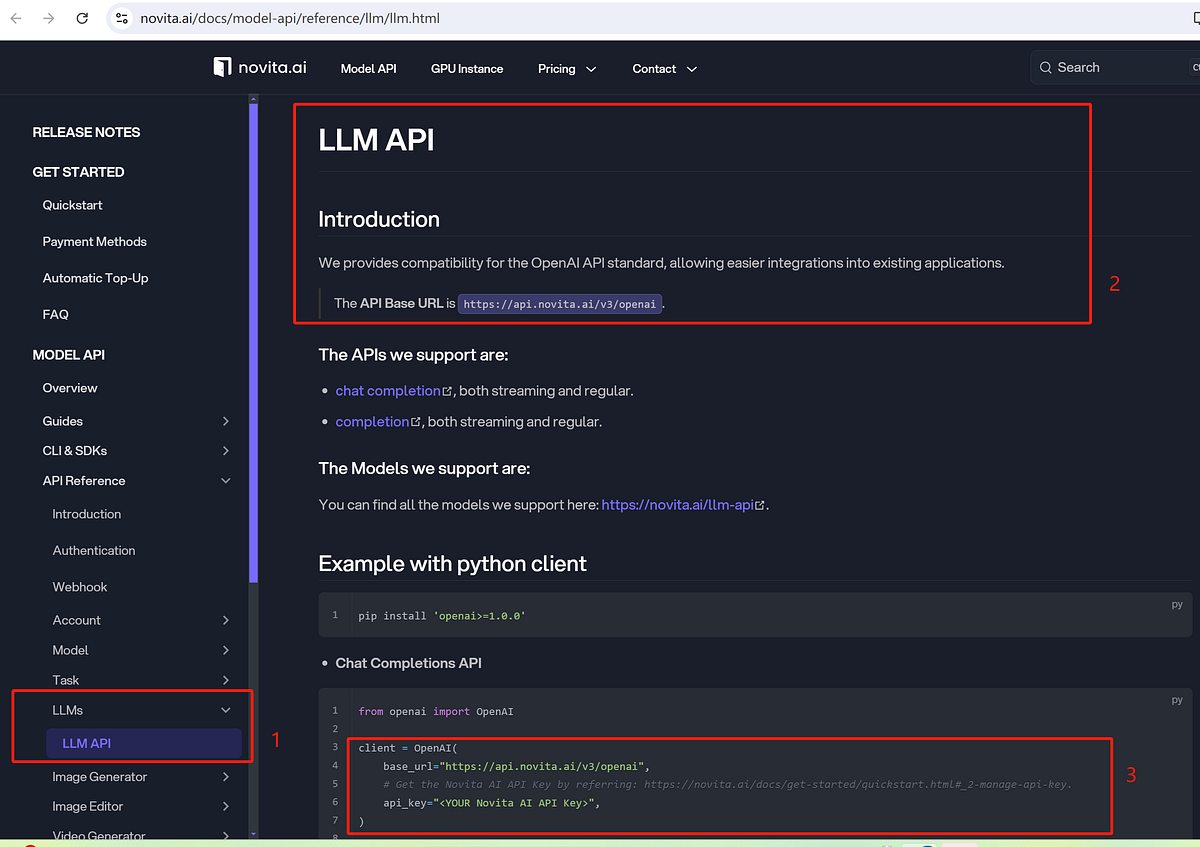
Here’s an example with a Python client using Novita AI Chat Completions API.
pip install 'openai>=1.0.0'
from openai import OpenAIclient = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)model = "Nous-Hermes-2-Mixtral-8x7B-DPO"
stream = True # or False
max_tokens = 512chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)- Step 4. Top up credit. As mentioned in the first step, you have a voucher with credits to try our products, but it’s limited. To add more credit, please visit Billing and Payments and follow the guide on Payment Methods.
Conclusion
In conclusion, Mixtral of Experts with MoE at its core architecture is a new technology that combines smart AI features with real-life use in different industries. It works better in specific tasks like generating code, stories, and translation. This makes it a special tool in today’s digital world of machine learning. Businesses can leverage their full power by using Mixtral with current systems and following good practices. This will help them be more creative and stay ahead of the competition. Embrace the strength of Mixtral to succeed in the fast-moving world of AI.
FAQs
What is the difference between Mistral and Mixtral?
Mixtral with Sparse Mixture of Experts architecture, has enhanced capabilities compared to Mistral. It excels in tackling intricate language tasks with speed and efficiency, requiring less computing power.
What is Mixtral trained on?
Mixtral underwent training with an extensive context size of 32,000 tokens and demonstrates comparable performance compared to Llama 2 70B and GPT-3.5 across different benchmarks.
Does Mixtral need a GPU?
To perform inference using Mixtral 8X22B, a GPU with a minimum of 300GB memory is necessary. For Mixtral 8x7B, typically about 94GB of VRAM would be needed based on standard guidelines.
Can Mixtral be used for commercial use?
Both Mixtral 8x7B and Mixtral 8x7B — Instruct are available under the Apache 2.0 license, allowing for both academic and commercial utilization.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading
1.Introducing Mixtral-8x22B: The Latest and Largest Mixture of Expert Large Language Model
2.Mixtral 8x22b Secrets Revealed: A Comprehensive Guide
3.Introducing Mistral's Mixtral 8x7B Model: Everything You Need to Know