Boost LLMs 30B by Renting GPU in GPU Cloud
Boost LLMs 30B with GPU cloud rentals. Rent GPU to accelerate your LLMs 30B tasks efficiently. Upgrade your performance now!

Introduction
In the rapidly evolving landscape of artificial intelligence and large language models (LLMs), computational power has become a pivotal factor in driving innovation and pushing the boundaries of what is possible. With the advent of advanced models like GPT-3 and its derivatives, the demand for high-performance GPUs has skyrocketed. However, the cost of acquiring and maintaining a fleet of top-tier GPUs can be prohibitively expensive for many organizations and researchers. This is where renting GPUs in GPU clouds emerges as a game-changing solution. By leveraging the vast computational resources available in the cloud, users can access state-of-the-art GPUs like the NVIDIA A100, which boasts an impressive 80GB of memory and is optimized for demanding AI workloads, without the upfront costs and management overhead associated with owning physical hardware.
A brief Introduction of LLM 30B
What is LLMs 30B?
Large Language Models (LLMs) are an important class of models in the field of Natural Language Processing (NLP). By pre-training on vast amounts of textual data, they are capable of understanding and generating natural language text, demonstrating robust capabilities across various NLP tasks. LLMs 30B, as a model with 30 billion parameters, boasts a considerable scale and complexity, enabling it to handle more complex and diverse natural language tasks.

Some Key features of LLMs 30B
- High Parameter Count: With 30 billion parameters, these models can capture complex patterns and relationships in data, leading to improved performance in various tasks.
- Multimodal Capabilities: Many 30B models support multimodal inputs, allowing them to process and understand text, images, and potentially audio, enhancing their versatility.
- Fine-tuning Flexibility: They can be fine-tuned on specific datasets, making them adaptable for various applications such as chatbots, content generation, and more.
- Improved Contextual Understanding: The larger parameter size enables better contextual understanding, allowing the model to generate more coherent and contextually relevant responses.
- Enhanced Language Generation: These models excel in generating human-like text, making them suitable for creative writing, summarization, and translation tasks.
- Scalability: They can be deployed on powerful cloud infrastructures, allowing for scalability to handle increased workloads and user demands.
- Robust Performance on Benchmarks: 30B models typically perform well on various NLP benchmarks, often surpassing smaller models in tasks like question answering, sentiment analysis, and more.
Comparison between LLMs 30B and Smaller Language Models
A comparison between LLMs 30B and smaller language models can be made in several key aspects. And here's a summary of the key differences and similarities:
Capabilities and Performance
- Generalization and Emergent Abilities:
- LLMs 30B: Larger models like LLMs 30B often exhibit emergent abilities, which are capabilities that emerge only when the model reaches a certain size threshold. These include better context understanding, in-context learning, and the ability to solve complex tasks without additional fine-tuning.
- Smaller Language Models: While smaller models can perform well on specific tasks they are trained for, they may lack the generalization power and emergent abilities seen in larger models.
- Task Performance:
- LLMs 30B: LLMs 30B can perform well on a wide range of NLP tasks, including machine translation, text summarization, question answering, and more. Its large size enables it to capture nuanced language patterns and generate more coherent and relevant responses.
- Smaller Language Models: Smaller models may excel at specific tasks they are tailored for but may struggle with more complex or general tasks.
Training and Deployment
- Training Data:
Both LLMs 30B and smaller language models are trained on large corpora of textual data. However, LLMs 30B typically requires even larger and more diverse datasets to fully utilize its capacity.
- Training Time:
- LLMs 30B: Training a model with 30 billion parameters is a computationally intensive and time-consuming process, often taking weeks or even months.
- Smaller Language Models: Smaller models can be trained in a more manageable timeframe, making them suitable for rapid prototyping and experimentation.
- Deployment:
- LLMs 30B: Deployment of LLMs 30B often requires specialized hardware and software infrastructure to handle the computational demands.
- Smaller Language Models: Smaller models can be easily deployed on a wide range of hardware platforms, making them more accessible for real-world applications.

Enhance LLMs by renting GPU in GPU Cloud
The 30B models typically require substantial computational resources for both training and inference, making renting GPU cloud services a common solution when utilizing these models.
What are the relationships between LLMs and GPU cloud?
Computational Demands: Due to their vast number of parameters, 30B models place high demands on computational power, often necessitating high-performance GPUs for efficient inference and training.
Cloud Services Offer Flexibility: By renting GPU cloud services, users can access computational resources on an as-needed basis, eliminating the need for costly hardware investments. This is particularly crucial for developers and enterprises that require intermittent access to 30B models.
What benefits can you get from renting GPU in GPU cloud?
- Cost-Effectiveness: Utilizing cloud services reduces initial investment costs, as users can select instance types tailored to their workloads, optimizing costs accordingly.
- Scalability: Cloud services allow users to rapidly scale up or down resources based on demand, crucial for applications that need to process large-scale data or handle high concurrency requests.
- Ease of Management: Cloud service providers typically handle hardware maintenance, software updates, and security issues, enabling users to focus solely on model development and application.

Factors affect you to choose a GPU
- GPU Types:
Opt for high-performance GPUs such as NVIDIA A100 or V100, which excel in handling large-scale model.
- Memory Capacity:
Ensure that the selected GPU has sufficient video memory (typically 32GB or more) to load and run 30B models efficiently.
- Computational Power:
Review the GPU's computational capability (in TFLOPS) offered by the cloud service to ensure it meets the demands of model inference and training.
- Pricing Models:
Compare the billing methods (hourly, usage-based, etc.) of different cloud services and select the one that best aligns with your budget and usage frequency.
- Community and Ecosystem:
Opt for a cloud service with an active community and abundant resources, making it easier to find use cases and technical support.
Rent GPU in Novita AI GPU Instance!
Just like what we have mentioned above, 30B LLM requires significant computational resources for both training and fine-tuning due to their size and complexity, often necessitating distributed training across multiple GPUs or TPUs, whereas GPU cloud provides a good choice for users to enhance their workflow with LLMs 30B. Try Novita AI GPU Instance!
Novita AI GPU Instance, a cloud-based solution, stands out as an exemplary service in this domain. This cloud is equipped with high-performance GPUs like NVIDIA A100 SXM and RTX 4090. This is particularly beneficial for PyTorch users who require the additional computational power that GPUs provide without the need to invest in local hardware.
The cloud infrastructure is designed to be flexible and scalable, allowing users to choose from a variety of GPU configurations to match their specific project needs. When facing a variety of software, Novita AI GPU Instance can provide users with multiple choices. And users just pay what you want, reducing costs greatly.
Rent NVIDIA A100 in Novita AI GPU Instance
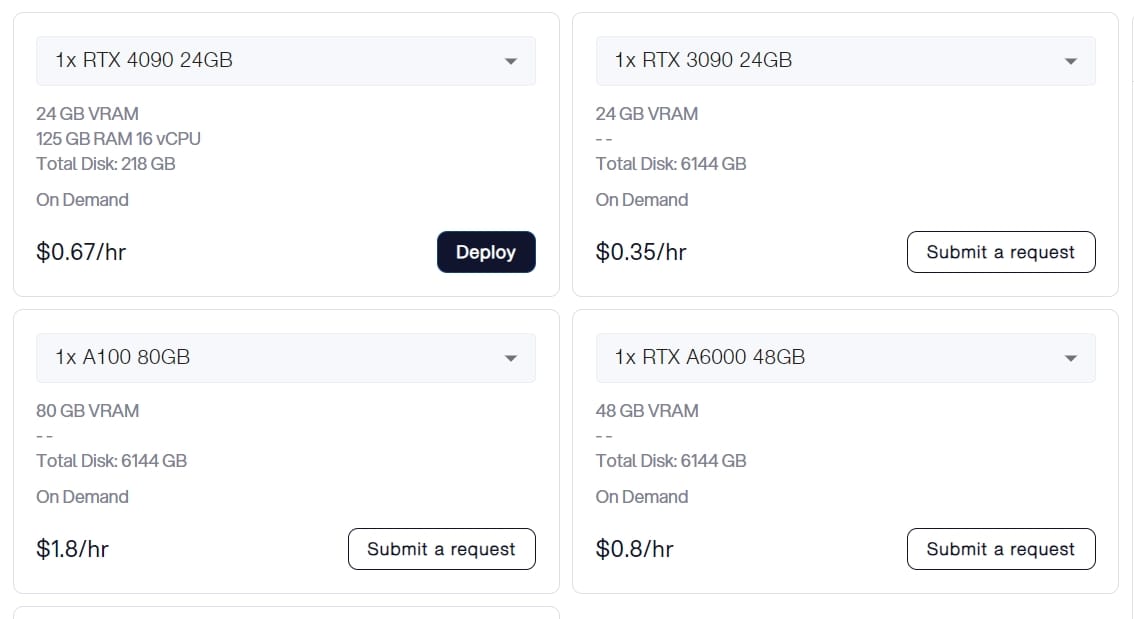
As we mentioned above, NVIDIA A100 is one of the best choices for users to optimize the using of LLMs 30B. And in Novita AI GPU Instance, we also offer NVIDIA A100 80GB, charging based on the time you use.
Benefits you can get:
- Cost-Efficiency:
Users can expect significant cost savings, with the potential to reduce cloud costs by up to 50%. This is particularly beneficial for startups and research institutions with budget constraints.
Now NVIDIA A100 80GB costs about 10,000 dollars in the marketing price. However, by renting it in Novita AI GPU Instance can you save a lot for it charging according to your using time and it cost only $1.8/hr.
- Instant Deployment:
You can quickly deploy a Pod, which is a containerized environment tailored for AI workloads. This streamlined deployment process ensures developers can start training their models without any significant setup time.
- Function:
In addition, you can also get the same function as you buy the whole hardware:
- 80GB VRAM
- Total Disk: 6144GB
Conclusion
In summary, Throughout this article, we have discussed the numerous benefits of renting GPUs in a GPU cloud, like Novita AI GPU Instance, including cost savings, scalability, and flexibility. We have also highlighted the importance of selecting the right GPU cloud provider, optimizing model training for the cloud environment, and managing costs to ensure maximum return on investment. The potential of renting GPUs in a GPU cloud to boost LLMs 30B and beyond is truly immense. It offers a powerful and cost-effective way to harness the transformative power of AI, enabling users to push the boundaries of what is possible and create solutions that will shape the future of technology.
Frequently Asked Questions
What is 3B+7B in LLM?
Stable Code 3B is a 3 billion parameter Large Language Model (LLM), allowing accurate and responsive code completion at a level on par with models such as Code LLaMA 7b that are 2.5x larger.
How are LLMs trained?
Training of LLMs is a multi-faceted process that involves self-supervised learning, supervised learning, and reinforcement learning.
What is a context length?
In AI, context length refers to the amount of text that an AI model can process and remember at any given time.
Novita AI, is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance - the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading: