

Sparse Techniques for 100X Speedup in Large Language ModeI Inference . Explore how sparse compilers revolutionize LLM inference, unlocking unprecedented efficiency and speed. In the previous discussion on “How LLMs Accelerate Inference through Sparsity,” we explored the second part, “Accelerating Inference with Activation Sparsity.” Click here to review the first part, “How LLMs Perform Pruning.” In this installment, we will delve into the third part, “The Impact of Sparse Compilers on LLM Inference.”
The Need for Compilers
Recent developments indicate that deep learning computations are becoming increasingly sparse, i.e., operations are performed on tensors with multiple zeros. In addition to sparse model weights (typically static and prior-known), more sparse patterns dependent on input and only known at runtime, namely dynamic sparsity, have been discovered. For instance, large language models (LLMs) such as GPT and OPT exhibit various types of dynamic sparsity. Firstly, Transformer models (and other types of models) demonstrate inherent dynamic sparsity in their inputs, activations, and gradients. In activation graphs, only a very few elements are nonzero (e.g., 3.0% for T5-Base, 6.3% for ViT-B/16). Secondly, leveraging dynamic sparsity to further scale up DNN models. Most existing models with over a trillion parameters adopt an expert mixture-of-experts (MoE) architecture, which activates experts dynamically based on sparse inputs. Additionally, dynamic sparsity training dynamically prunes less important connections in the model during training, garnering increasing attention for its superior computational efficiency. Dynamic sparsity, where sparse patterns are unknown before runtime, poses significant challenges to deep learning. Advanced sparse-aware deep learning solutions are limited to predefined static sparse patterns due to significant overhead associated with preprocessing. Efficient execution of dynamically sparse computations often faces inconsistency between GPU-friendly tensor block configurations for efficient execution and minimizing wasted coverage (nonzero values in tensors) in sparse-aware block shapes. LLM sparsity necessitates the use of sparse operators, and traditional libraries like cuSPARSE or Sputnik, due to their generic designs rather than optimality, involve either supporting only statically compiled sparse-aware kernels or necessitating dynamic conversion of sparse matrices to dense format, resulting in significant performance overhead in scenarios of dynamic sparsity.
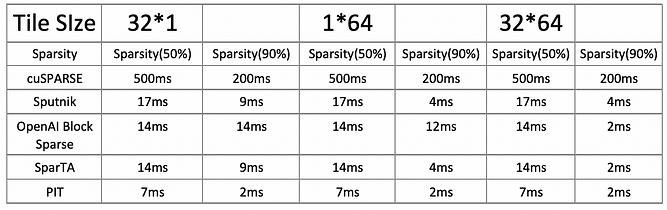
Comparison of Mainstream Compilers
The current mainstream sparse computation compilers mainly include cuSPARSE, Sputnik, OpenAI Block Sparse, SparTA, and PIT, as referenced in [11]. Below is a comparison table of acceleration data: Scenario: Matrix multiplication of size 4096 × 4096 × 4096 Metric: Latency (ms)
The impact of compilers on LLM inference
OPT
Experiment [11] evaluates PIT using the Alpaca dataset on two versions of the OPT model: OPT13B and 30B, across eight V100–32GB GPUs. PIT applies two dynamic sparsity optimizations on OPT: (1) eliminating padding overhead for sentences of different lengths in the same batch; (2) leveraging fine-grained sparsity (up to 99%) created by ReLU activations in the FFN layers. The batch size is set to 32, and PyTorch-S utilizes Triton as the backend.
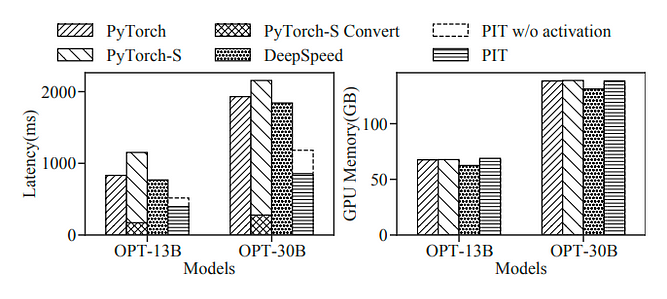
End-to-end latency per batch and memory footprints of OPT PIT’s performance surpasses PyTorch, PyTorchS, and DeepSpeed by 2.1x ∼ 2.3x, 2.5x ∼ 3.0x, and 2.0x ∼ 2.2x, respectively. Avoiding padding in dynamic sequences contributes to PIT achieving a 1.6x ∼ 1.7x speedup relative to the baseline. By further leveraging the dynamic sparsity in ReLU activations of FFN layers, PIT further boosts performance by 1.3x ∼ 1.4x. Compared to PyTorch-S using Triton block-sparse kernels with a block size of 32x32, PIT employs smaller micro-blocks (i.e., 1x32) and efficient computations with SRead and SWrite, avoiding computational waste. Additionally, PyTorch-S is also affected by the overhead of sparse format conversion, hence exhibiting the highest latency. In terms of memory consumption, DeepSpeed has the lowest memory usage as it fuses the entire encoder layer into one operator, saving activation memory.
MOE
In experiments [11] on SwinMoE, a large vision model with an encoder and MoE structure, PIT’s performance was evaluated on A100 using float16 precision. For visual transformers, input images within the same batch were rescaled to the same resolution to ensure consistent sequence length. In our experiments, we compared the end-to-end inference latency and memory usage of Swin-MoE with different batch sizes and expert counts. MegaBlocks outperforms other baselines by executing all experts simultaneously, effectively utilizing sparse kernels to avoid computation waste. PIT further improves performance by supporting data reshuffling in data movement across memory hierarchies compared to MegaBlocks.
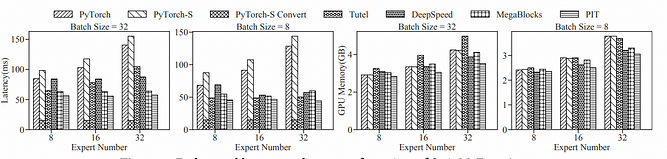
End-to-end latency and memory footprints of SwinMoE on A100 Compared to PyTorch, PyTorchS, Tutel, DeepSpeed, and MegaBlocks, PIT achieved speed ups of 1.5x ∼ 6.3x, 1.5x ∼ 2.9x, 1.1x ∼ 1.8x, 1.2x ∼ 1.6x, and 1.1x ∼ 1.4x, respectively. PIT’s performance improvement on Swin-MoE is less than that of Switch Transformer, as Swin-MoE has significantly fewer experts than Switch Transformer. Therefore, when the number of experts increases from 8 to 32, the MoE layer contributes only 23.6% to 61.2% of the end-to-end latency. When comparing the latency of the MoE layer alone, PIT is approximately 1.2x ∼ 1.7x faster than MegaBlocks. Here’s the compiled comparison data for PIT:
 Finally, let’s discuss the hardware support required for acceleration.
Finally, let’s discuss the hardware support required for acceleration.
GPU
NVIDIA A100
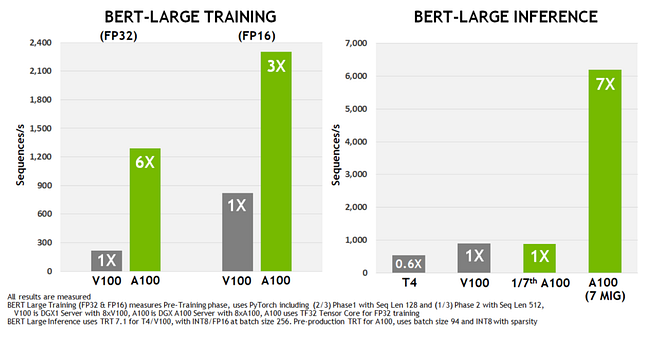
The A100 utilizes the new Ampere architecture, featuring up to 6912 CUDA cores and 40GB of high-speed HBM2 memory. It also supports second-generation NVLink technology, enabling fast GPU-to-GPU communication and boosting training speeds for large models. The A100 introduces powerful new third-generation Tensor Cores, along with comprehensive support for DL and HPC data types, as well as new sparse capabilities to further double throughput. The TF32 Tensor Core operations in the A100 provide a straightforward path to accelerate FP32 input/output data in DL frameworks and HPC, running 10 times faster than V100 FP32 FMA operations, or 20 times faster in the case of sparsity. For FP16/FP32 mixed precision DL, the A100’s performance is 2.5 times that of V100, increasing to 5 times with sparsity. When running AI models with the PyTorch framework, compared to the previous generation V100 chip, the A100 demonstrates a 6x performance improvement in BERT model training and a 7x improvement in BERT inference.
Intel Max Series GPU
According to reference [18], recent implementations of two sparse matrix operations on the NVIDIA V100 GPU have shown performance gains of up to 10 times compared to the reference implementation on V100.
Conclusion
In summary, here are three conclusions regarding the acceleration of LLM inference through sparsity:
- Weight sparsity (50%), activation sparsity (90%), and MOE sparsity (e.g., Mistral 8x7B with 75% dynamic sparsity) are orthogonal factors (effects can be cumulative, but model performance may be affected). Combined with the 2–3x acceleration effect of the PIT compiler on sparse models, compared to current mainstream inference frameworks (TGI/vLLM, etc.), there is a theoretical acceleration limit of 5–30 times.
- Latency is the primary focus of current sparsity techniques (sparsity has certain effectiveness; the larger the batch size, the poorer the sparsity effect). Throughput direction will be a new optimization direction because activation sparsity exhibits a certain power-law distribution, offering significant engineering optimization potential.
- Converting non-ReLU activations to ReLU activations in LLM incurs relatively low costs (around 3% fine-tuning cost; data quality is relatively important). Additionally, training predictors in DejaVu incurs lower costs (fast training and independent of data). Combined with the cost reduction brought about by the increase in inference speed, this is a high ROI initiative and is commercially viable.
Reference Paper
[11]Pit: Optimization of dynamic sparse deep learning models via permutation invariant transformation [18]Performance Optimization of Deep Learning Sparse Matrix Kernels on Intel Max Series GPU
novita.ai provides Stable Diffusion API and hundreds of fast and cheapest AI image generation APIs for 10,000 models.🎯 Fastest generation in just 2s, Pay-As-You-Go, a minimum of $0.0015 for each standard image, you can add your own models and avoid GPU maintenance. Free to share open-source extensions.
Recommended reading Unveiling LLM-Pruner Techniques: Doubling Inference Speed



