Will Speculative Decoding Harm LLM Inference Accuracy?

Mitchell Stern et al. 2018 introduced the prototype concept of speculative decoding. This method has since been further developed and refined by various approaches, including Lookahead Decoding, REST, Medusa and EAGLE, significantly accelerating the inference process of large language models (LLMs).
One might wonder: will speculative decoding in LLMs harm the accuracy of the original model? The simple answer is no.
The orthodox speculative decoding algorithm is lossless, and we will prove this through both mathematical analysis and experiments.
Mathematical Proof
The speculative sampling formula can be defined as follows:
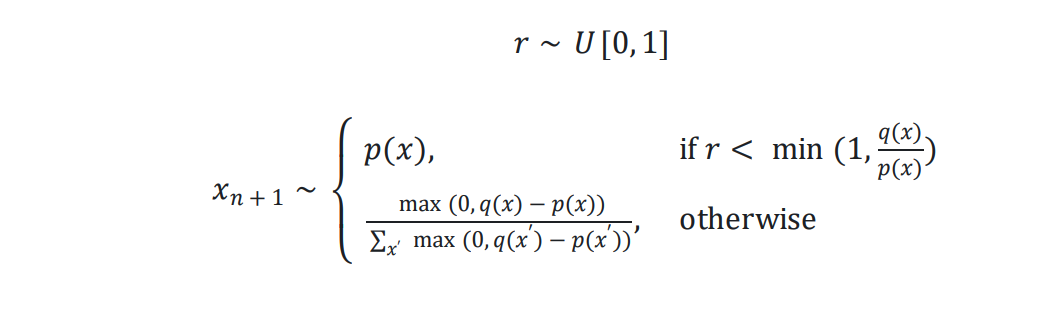
While:


Below is a proof of the lossless nature of this formula from the DeepMind paper:

If you feel too dull to read math equations, next I will illustrate the proof with some intuitional diagrams.v√
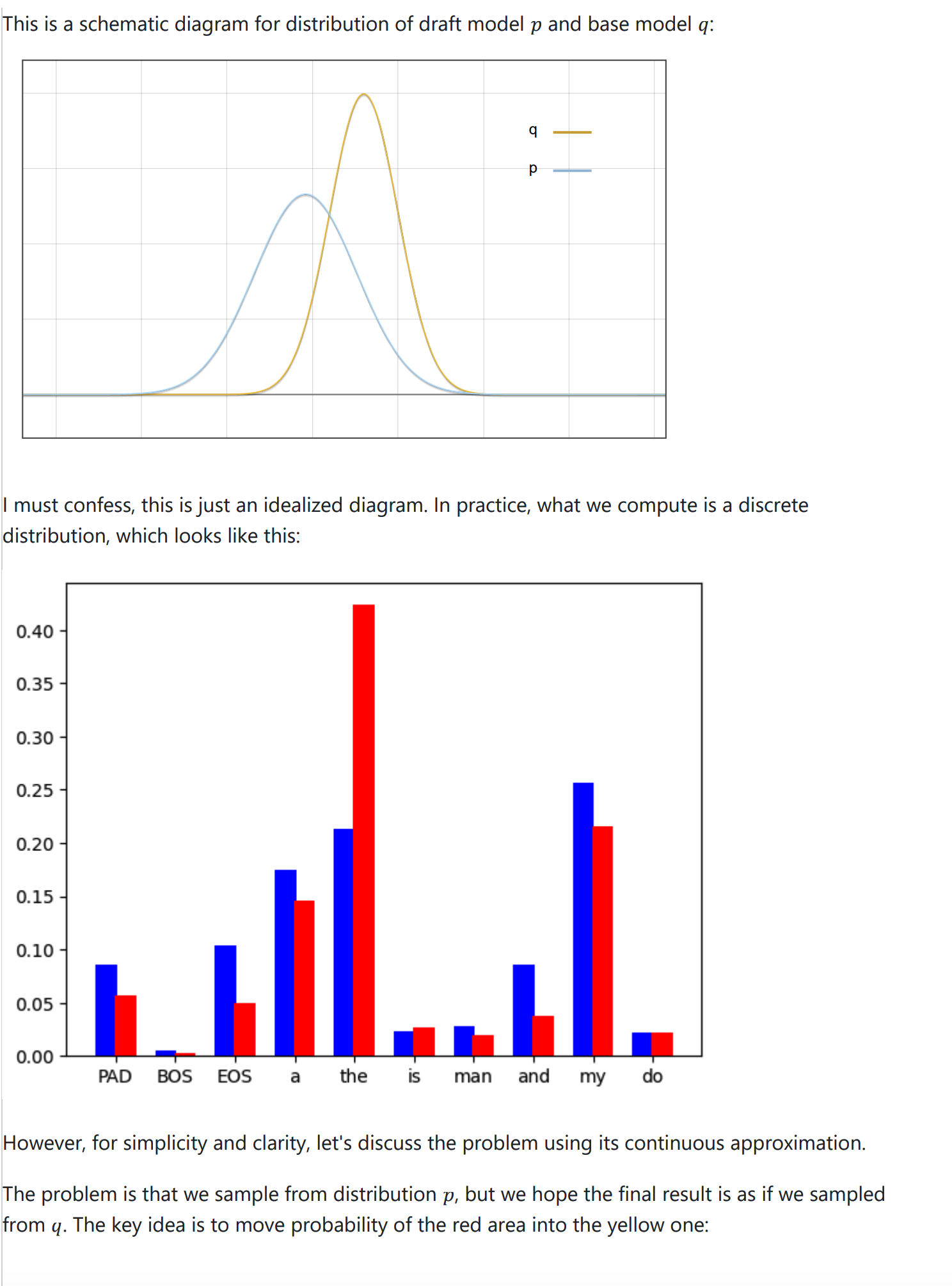
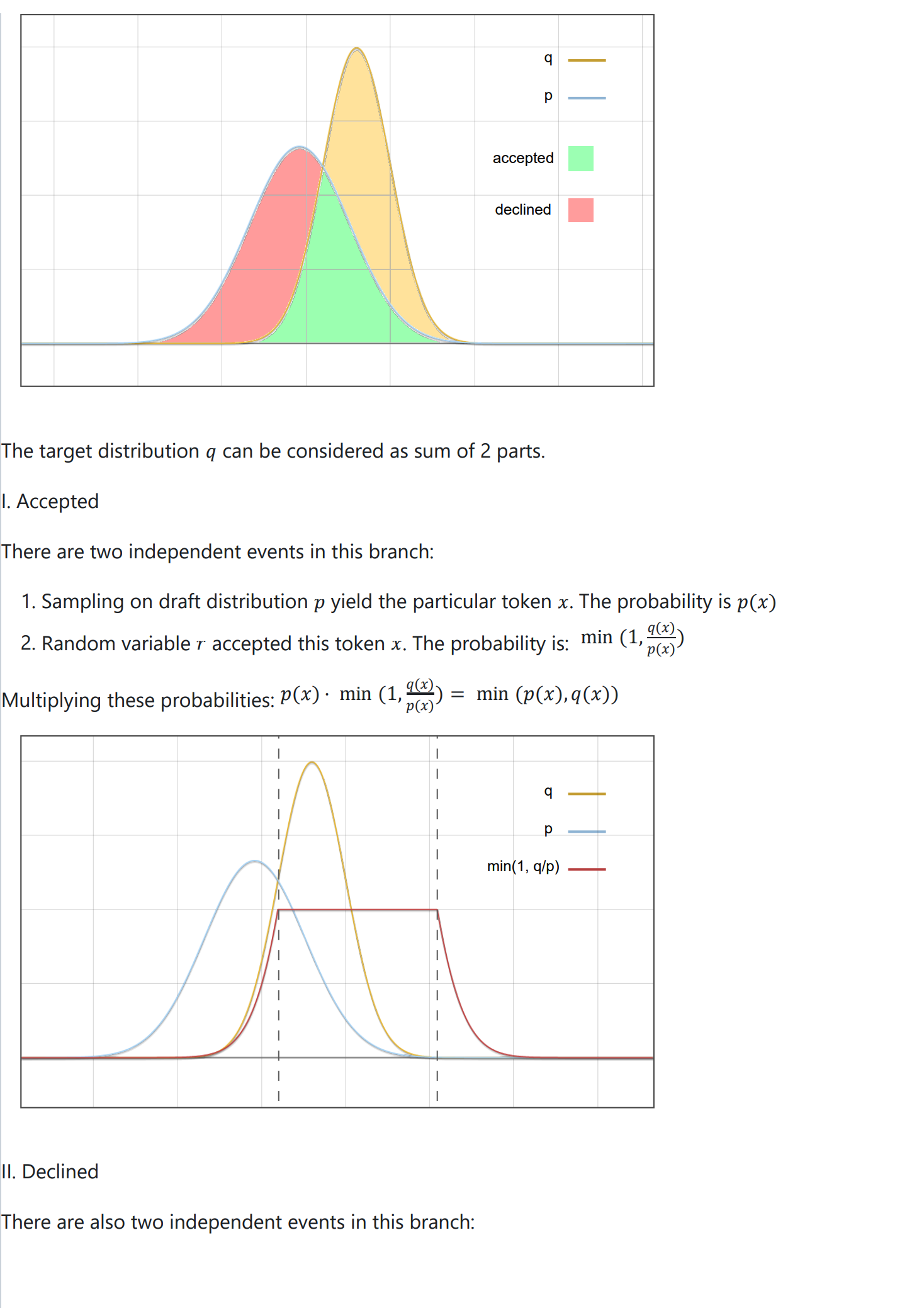
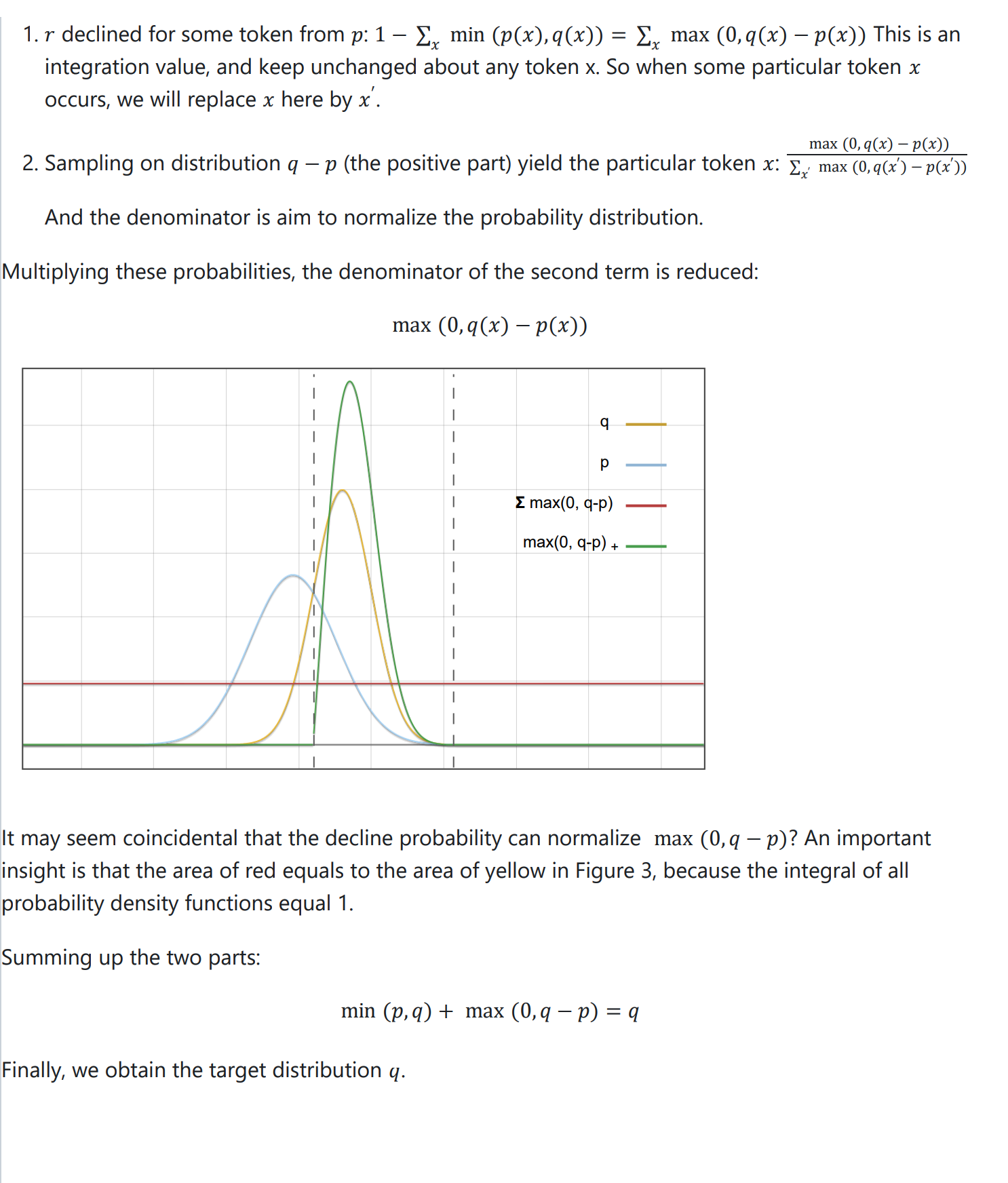
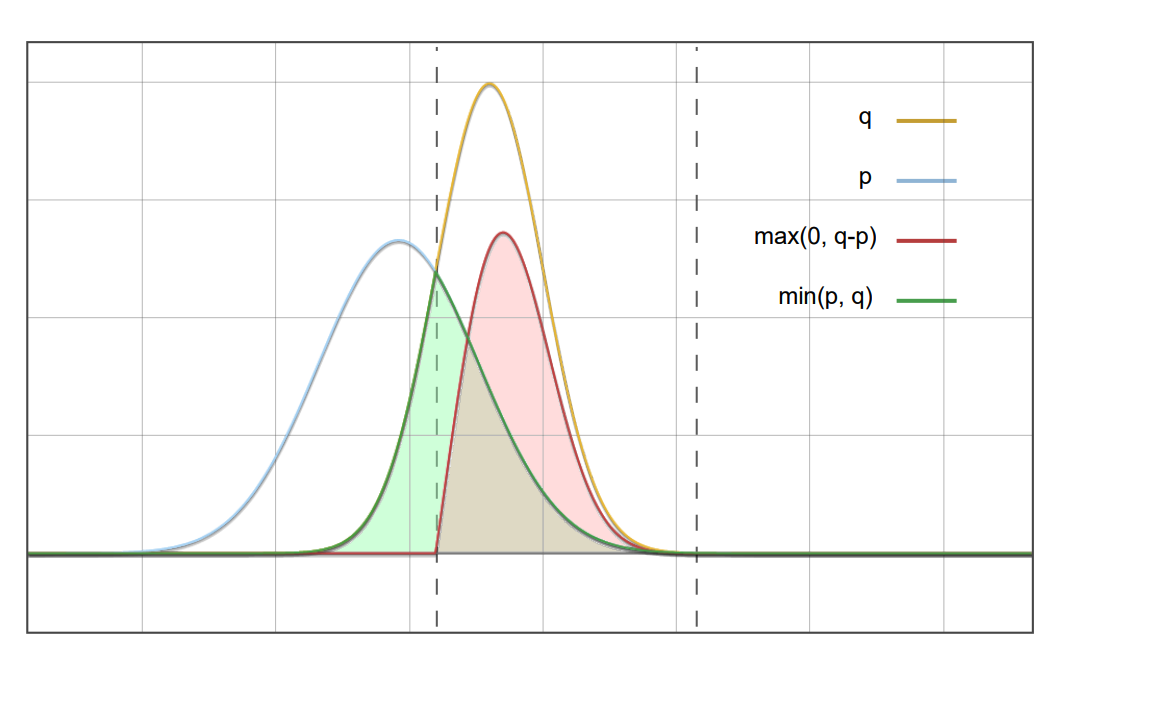
Experiments
Although we have mathematically proven that speculative decoding is lossless in principle, implementation errors can still occur. Therefore, experimental validation is also necessary. We conducted experiments on two cases: the deterministic method of greedy decoding and the random method of multinomial sampling.
Greedy Decoding
We asked the LLM to generate a short story twice, first using vanilla inference and then using speculative decoding. We utilized the speculative decoding implementation from Medusa. The model weight is medusa-1.0-vicuna-7b-v1.5 and its base model vicuna-7b-v1.5. After test running, we obtained two identical results. The generated text is as follows:

Multinomial Sampling
In the case of random sampling, the situation is more complex. Most methods for reproducing results in random programs use a fixed random seed to leverage the determinism of pseudo-random generators. However, this approach does not fit our scenario. Our experiment relies on the law of large numbers: with enough samples, the error between the practical and theoretical distributions will converge to zero.
We conducted 1,000,000 sampling iterations for the first token generated for each of four prompts. The model weights used were Llama3 8B Instruct and EAGLE-LLaMA3-Instruct-8B. The statistical results are shown below:
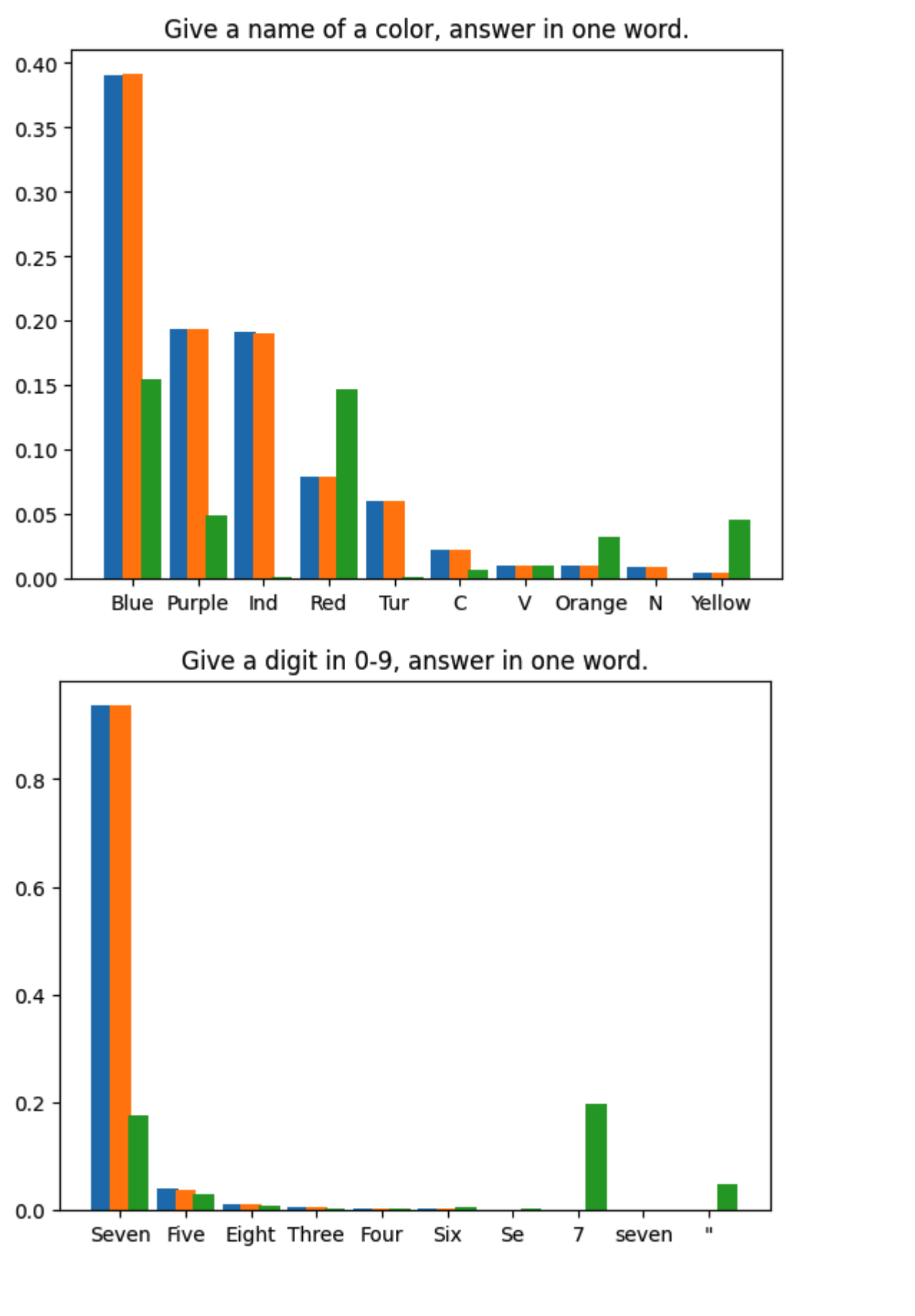
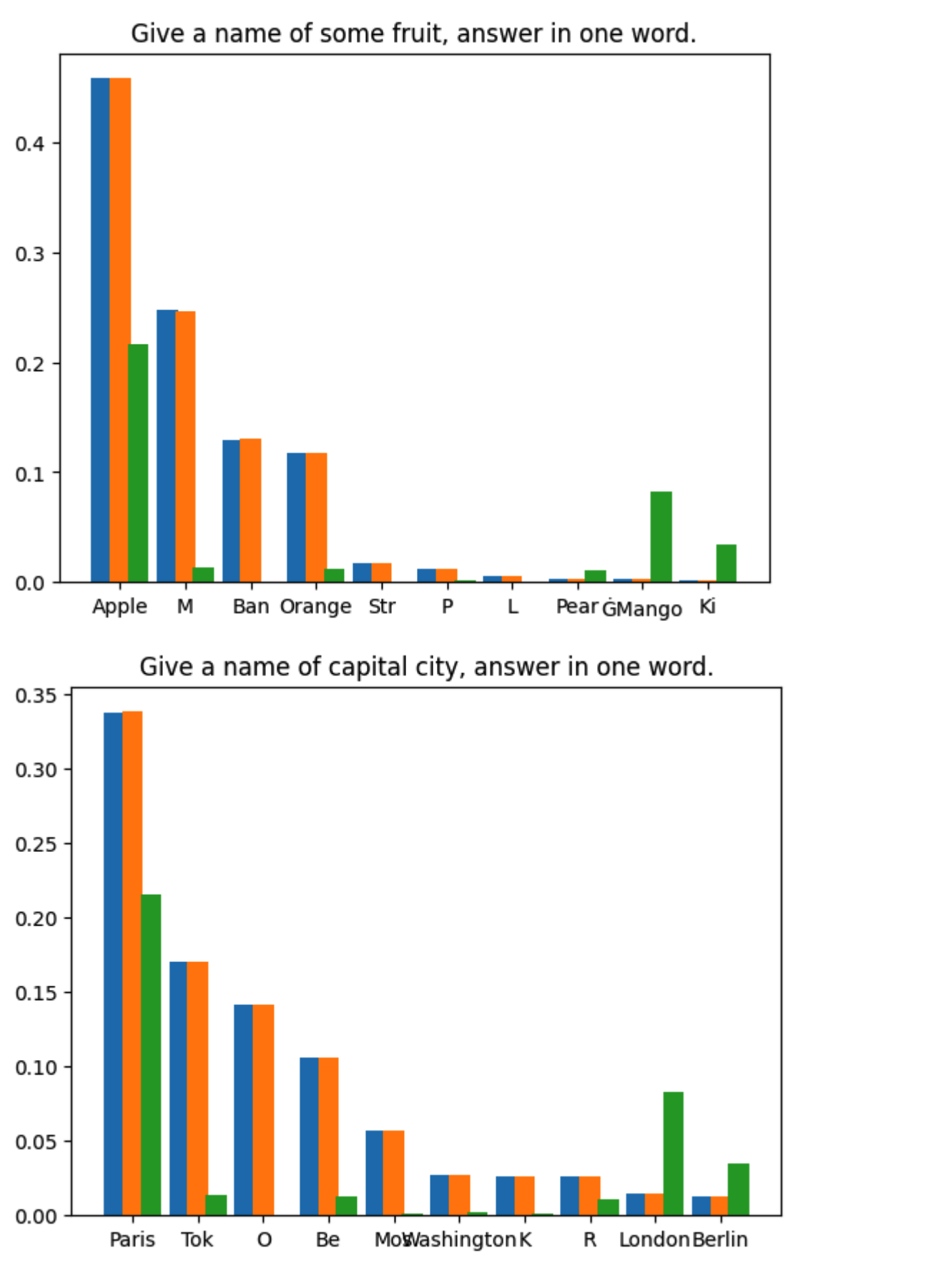
- Blue: softmax of logits from base model
- Green: softmax of logits from draft model
- Orange: token frequency from speculative sampling (1,000,000 times)
The standard deviation of sampling distribution from base model is 9.694e-5. That's in line with expectations.
Conclusion
Speculative decoding does not compromise the inference accuracy of large language models. Through rigorous mathematical analysis and practical experiments, we have demonstrated the lossless nature of standard speculative decoding algorithms. The mathematical proof illustrates how the speculative sampling formula preserves the original distribution of the base model. Our experiments, including both deterministic greedy decoding and probabilistic multinomial sampling, further validate these theoretical findings. The greedy decoding experiment produced identical results with and without speculative decoding, while the multinomial sampling experiment showed negligible differences in token distribution over a large number of samples.
These results collectively affirm that speculative decoding can significantly accelerate LLM inference without sacrificing accuracy, paving the way for more efficient and accessible AI systems in the future.
You can visit Novita AI for more details!