What is vLLM: Unveiling the Mystery
Discover vLLM, a cutting-edge technology transforming language models. Unveil its features, benefits and relationship with GPU cloud.

Key Highlights
- VLLM is an open-source LLM serving and inference engine known for its memory efficiency and speed.
- It outperforms models like Hugging Face Transformers, handling tasks up to 24 times faster and surpassing Hugging Face Text Generation Inference by over three times in speed.
- The key to vLLM’s performance is PagedAttention, a memory management algorithm that minimizes unused memory and allows for handling more data simultaneously
- With support for various LLM models, vLLM has gained popularity among developers, evidenced by its 20,000+ GitHub stars and active community.
- Rent GPU in Novita AI GPU Instance: A Better Way to Enhance Your vLLM Running Efficiency.
Introduction
VLLM, or Very Large Language Model, is a popular tool among developers for efficiently running large language models. It optimizes performance and manages memory effectively, making it ideal for businesses handling extensive text processing without draining resources.
Traditional methods often waste memory and slow down processes. VLLM tackles these issues using PagedAttention, enhancing speed and minimizing waste.
In this guide, we explore what sets vLLM apart, its innovative technology, memory management efficiency, performance compared to older methods, real-world success stories, and how to integrate vLLM into your projects.
Why is serving LLM so challenging?
- High Memory Footprint: LLMs need large amounts of memory to store their parameters and intermediate activations(mainly the key and value parameters from the attention layers), making them challenging to deploy in resource-constrained environments.
- Limited Throughput: Traditional implementations struggle to handle high volumes of concurrent Inference Requests, hindering scalability and responsiveness. This affects when the Large Language Model runs in the Production server and cannot work with the GPUs effectively.
- Computational Cost: The intense load of matrix calculations involved in LLM inference can be expensive, especially on large models. With the High Memory and Low Throughout, this will further add in more costs.
Understanding vLLM and Its Importance
what is VLLM
vLLM stands for Virtual Large Language Model and is an active open-source library that supports LLMs in inferencing and model serving efficiently.
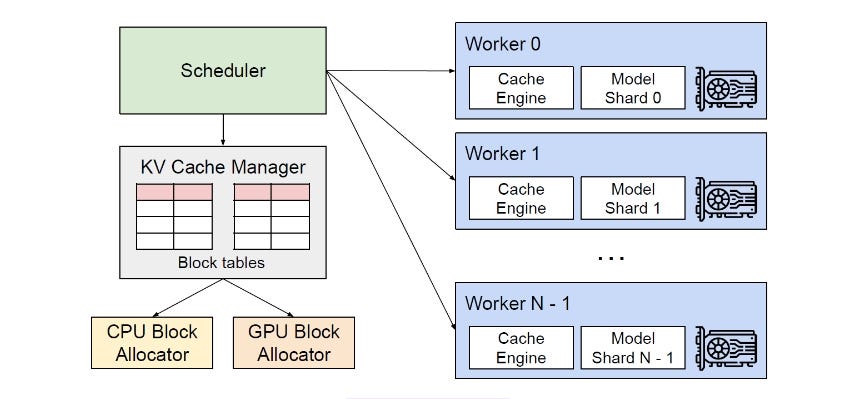
Importance of vLLM
It optimizes memory usage, which could improve LLM serving performance around 24 times while using half the memory of the GPU compared with the traditional method. VLLM’s PagedAttention feature ensures efficient memory utilization, with less than 4% wastage. This smart approach allows for increased productivity without requiring additional expensive GPUs.

For example, LMSYS used vLLM in their Chatbot Arena project and reduced GPU usage by half while doubling task completion rates. Choosing vLLM can lead to cost savings and improved performance metrics in natural language processing tasks.
Core Technologies Behind VLLM
VLLM excels in memory management and data handling due to its key technologies:

LLM Serving: Efficiently generates text and completes prompts using large language models without excessive memory or processing power.
LLM Inference: Enhances text generation by optimizing attention and memory use for faster, smoother operations.
KV Cache Management: Keeps track of essential data for text creation, ensuring efficient cache use.
Attention Algorithm: Improves efficiency by minimizing memory usage and speeding up responses during model serving and inference.
PagedAttention: Optimizes memory usage, ensuring no space is wasted and boosting overall performance.
If you want to get more information about how K V cache is managed, you can click on this link to have a deeper understanding of it:
Key Features of VLLM
VLLM stands out with its unique approach:
Memory Efficiency: Uses PagedAttention to prevent memory waste, ensuring smooth project execution.
Task Handling: Manages memory and attention algorithms to handle more tasks simultaneously than standard LLMs, ideal for quick-response projects.
PagedAttention Mechanism: Maximizes available space for storing essential data, enhancing speed and efficiency.
Attention Key Management: Efficiently stores and accesses attention keys, improving performance in complex language tasks.
Developer-Friendly Integration: The serving engine class allows easy integration for generating text or performing other operations effortlessly.
Comparing VLLM with Traditional LLMs
VLLM really stands out from the usual LLM setups in a few important ways. When we look at VLLM compared to old-school LLMs, here’s what we find:
- Memory Waste: Old-style LLMs often end up wasting a lot of memory because they don’t manage it well, leading to issues like breaking it into useless pieces and holding onto more than they need. On the flip side, VLLM uses cool tricks like PagedAttention to keep memory waste super low and use almost exactly as much memory as needed.
- GPU Utilization: Thanks to its smart way of handling memory, VLLM makes sure GPUs (the powerful computers that do all the heavy lifting) are used as efficiently as possible. This means these machines can do their job better and faster than with traditional LLM methods.
- Throughput: Because of how cleverly Vllm manages both GPU power and how little space is wasted on unnecessary stuff; It can handle way more tasks at once without slowing down. If you’re looking for something that gets language processing jobs done quickly and smoothly, vllm is likely your best bet.
Performance Benchmarks: VLLM vs. Others
VLLM’s performance benchmarks demonstrate its superiority over other inference engines in terms of throughput and memory usage. Let’s compare VLLM with other options:
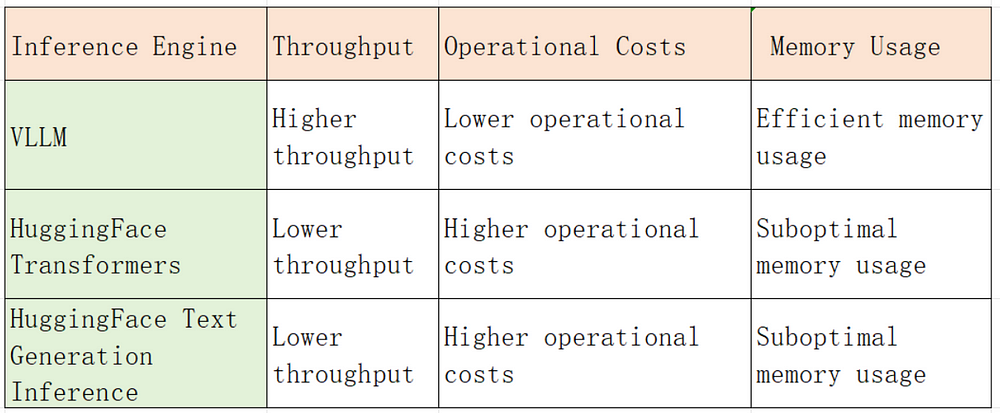
VLLM achieves up to 24x higher throughput compared to HuggingFace Transformers and up to 3.5x higher throughput compared to HuggingFace Text Generation Inference. This significant improvement in throughput translates into lower operational costs and improved performance for organizations using VLLM.
Implementing VLLM in Your Projects
Boost the efficiency of your language models by integrating VLLM. Here’s how:
Step-by-Step Guide to Setting Up a VLLM Environment
Getting a vLLM environment up and running is pretty easy and there’s plenty of guidance out there. Here’s how you can do it, step by step:
- Step 1: Install VLLM: First off, get the vLLM package on your computer using pip.
# (Recommended) Create a new conda environment.
conda create -n myenv python=3.9 -y
conda activate myenv# Install vLLM with CUDA 12.1.
pip install vllm
- Step 2: Review Documentation: After installing, take some time to go through the vLLM documentation for detailed steps on how to set everything up properly. This documentation is packed with info on how to use vLLM effectively and make it work with other software.
- Step 3: Explore Hugging Face Models: With support for numerous pre-trained language models from Hugging Face, head over to their site next. Look around for a model that fits what you need for your project.
- Step 4: Use the GitHub Repository of vLLM: For more help like examples or guides on making the most out of vLLM check its GitHub page often as they keep adding new stuff which could be very useful.
A Better Way to Enhance Your vLLM Running Efficiency
As you can see, the very first step of install and run vLLM is to deploy a high-speed environment. You may consider how to get GPUs with better performance, here is an excellent way — — try Novita AI GPU Instance!
Novita AI GPU Instance, a cloud-based solution, stands out as an exemplary service in this domain. This cloud is equipped with high-performance GPUs like NVIDIA A100 SXM and RTX 4090. This is particularly beneficial for PyTorch users who require the additional computational power that GPUs provide without the need to invest in local hardware.
How to start your journey in Novita AI GPU Instance
1. Create a Novita AI GPU Instance account
To create a Novita AI GPU Pod account, visit the Novita AI GPU Pods website and click the “Log in” button. You will need to provide an email address and password.
2. Select a GPU-enabled server
ou can choose you own template, including Pytorch, Tensorflow, Cuda, Ollama, according to your specific needs. Furthermore, you can also create your own template data by clicking the final bottom.
Then, our service provides access to high-performance GPUs such as the NVIDIA RTX 4090, and RTX 3090, each with substantial VRAM and RAM, ensuring that even the most demanding AI models can be trained efficiently. You can pick it based on your needs.

3. Launch an instance
Whether it’s for research, development, or deployment of AI applications, Novita AI GPU Instance equipped with CUDA 12 delivers a powerful and efficient GPU computing experience in the cloud.
Conclusion
VLLM is a real game-changer because of its top-notch tech and amazing efficiency. When you use vLLM in your projects, you’re setting yourself up for some incredible results and making things better for everyone who uses it. With the attention mechanism and improvements in memory, we’re seeing a whole new way to handle big language models. Looking at how well it performs through tests and examples from real life, it’s clear that vLLM beats the old-school LLMs by a long shot.
To get vLLM working its magic, there’s some setup needed to make sure everything runs smoothly. By choosing vLLLm ,you’re really pushing your projects forward and keeping up with the latest in technology.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended reading