Stable Diffusion Checkpoints for AI art

Introduction
AI art has come a long way, with advancements in stable diffusion models revolutionizing image generation. These models, powered by neural networks, can create realistic and high-resolution images, opening up new possibilities in the world of art. In this blog, we will explore stable diffusion checkpoints for AI art and delve into the science behind them, their evolution, the significance of fine-tuning, popular models, how to choose the right model, merging models, different model types, and how stable diffusion is shaping the future of AI art.
Understanding Stable Diffusion in AI Art
Stable diffusion models lie at the heart of AI art generation, utilizing neural networks and diffusion models to create images. But what exactly is stable diffusion? Stable diffusion refers to the control of image generation stability through weights. Model checkpoints, known as stable diffusion checkpoint models, play a crucial role in managing stable diffusion weights. With specific needs for further training, stable diffusion models rely on checkpoint directories to ensure stability throughout the training process.
Stable Diffusion Online: No GPU, Only pay for request. Try for free.
The Science Behind Stable Diffusion
At the core of stable diffusion lies the diffusion model, a powerful framework used in generating images. Neural networks, which are machine learning models inspired by the structure of the human brain, are employed to control stable diffusion weights. These weights determine the stability of image generation throughout the training process. Within stable diffusion models, a neural network is trained using a dataset specific to the desired art style. By adjusting network parameters, stable diffusion models can generate images that adhere to specific art styles.
The model card, a file that accompanies stable diffusion models, provides essential information about the model, including relevant NLP terms, such as checkpoint model, checkpoint directory, stable diffusion weights, and training data. This card acts as a guide for further training and understanding of the stable diffusion model. By leveraging stable diffusion weights and neural network training, realistic images can be generated, bringing a new level of artistry to AI creations.
Github: https://github.com/CompVis/stable-diffusion/tree/main

Evolution of Stable Diffusion Models
Stable diffusion models have undergone significant evolution since their inception, evolving from different platforms and models. The advancement of stable diffusion checkpoint models, particularly in generating higher-resolution versions of images, has been a driving force in their evolution. These checkpoint models, developed with specific training data, have become foundational models for AI art generation.
One example of the evolution of stable diffusion checkpoint models is the introduction of v1.4 and v1.5 models. These versions of stable diffusion checkpoint models have brought about an enhanced capability to produce realistic images, further expanding the possibilities of AI art generation. Another notable development is the transition to v2 models, which offer higher-resolution versions and improved stability. The stability of AI partnerships has played a crucial role in developing and advancing stable diffusion models, shaping the future of AI art. Fine-tuning in Stable Diffusion Models
While stable diffusion models provide a base for image generation, fine-tuning plays a pivotal role in customizing and adapting these models to specific art styles. Fine-tuning involves further training of stable diffusion models, allowing for adjustments in stability, art style, and image generation. By fine-tuning a stable diffusion model, artists can control the stability of generated images, ensuring they meet their specific needs and preferences.
- Realistic Vision: Realistic style.
- Anything: Anime style.
- Dreamshaper: Realistic painting style.

What is Fine-tuning?
Fine-tuning is a popular technique used in machine learning to further enhance the performance of a pre-trained model. It involves taking a model that has already been trained on a large and diverse dataset and then continuing the training process on a more specific or specialized dataset.
Fine-tuning refers to the process of adjusting the stable diffusion model to generate images that align with specific art styles. It involves further training the model using a dataset or specific art-style examples, such as those provided by the Dreambooth training dataset. By fine-tuning a stable diffusion model, artists can achieve more control over the stability and style of the generated images.
One example of fine-tuning is the Dreambooth model, which allows users to input text and generate images based on that text input. By fine-tuning the model with specific training data, the generated images can be tailored to match a desired art style or concept. Fine-tuning provides artists with the ability to shape the output of stable diffusion models and create art that aligns with their vision.
Significance of Fine-tuning in Stable Diffusion
Fine-tuning plays a significant role in the image-generation process of stable diffusion models. Adjusting stable diffusion weights during fine-tuning can result in more realistic images, as well as images that adhere to specific art styles. The main change in stable diffusion models often comes from the fine-tuning process, which allows for the customization of image generation.
The benefit of fine-tuning is that it combines the general knowledge and versatility of the original pre-trained model with the ability to generate outputs that are more aligned with the specific task or dataset it is being fine-tuned on. This approach can lead to improved performance and more accurate results in various machine-learning applications.
One of the main benefits of fine-tuning stable diffusion models is the generation of images in their original size. Without fine-tuning, stable diffusion models may produce images that are scaled down, leading to a loss of detail and resolution. By fine-tuning, artists can ensure that their generated images retain their original size, capturing the intricacies and nuances of their art style.
The model card, which accompanies stable diffusion models, describes the specific details of the model, such as the dataset used, the stable diffusion weights, and the training method employed. This card serves as a reference guide for artists, providing valuable insights into the model’s capabilities and opportunities for further fine-tuning.
However, before proceeding with the fine-tuning of the model, two important issues need to be addressed:
The first issue we need to address is overfitting: Fine-tuning these large generative models on a small set of images, no matter how diverse, can lead to overfitting. This means the model will primarily learn to reproduce the subject in the poses and contexts present in the training images, limiting its ability to generate diverse outputs.

Prior-preservation loss acts as a regularizer that alleviates overfitting, allowing pose variability and appearance diversity in a given context. Image and caption from DreamBooth’s paper.
The second issue is language drift: Fine-tuning with specific prompts can cause the model to forget how to generate diverse instances of a class. Instead, it tends to produce images resembling the subject used for fine-tuning. This narrows the model’s output space and may lead to biased results, as not all instances of a class should resemble the fine-tuning subject.
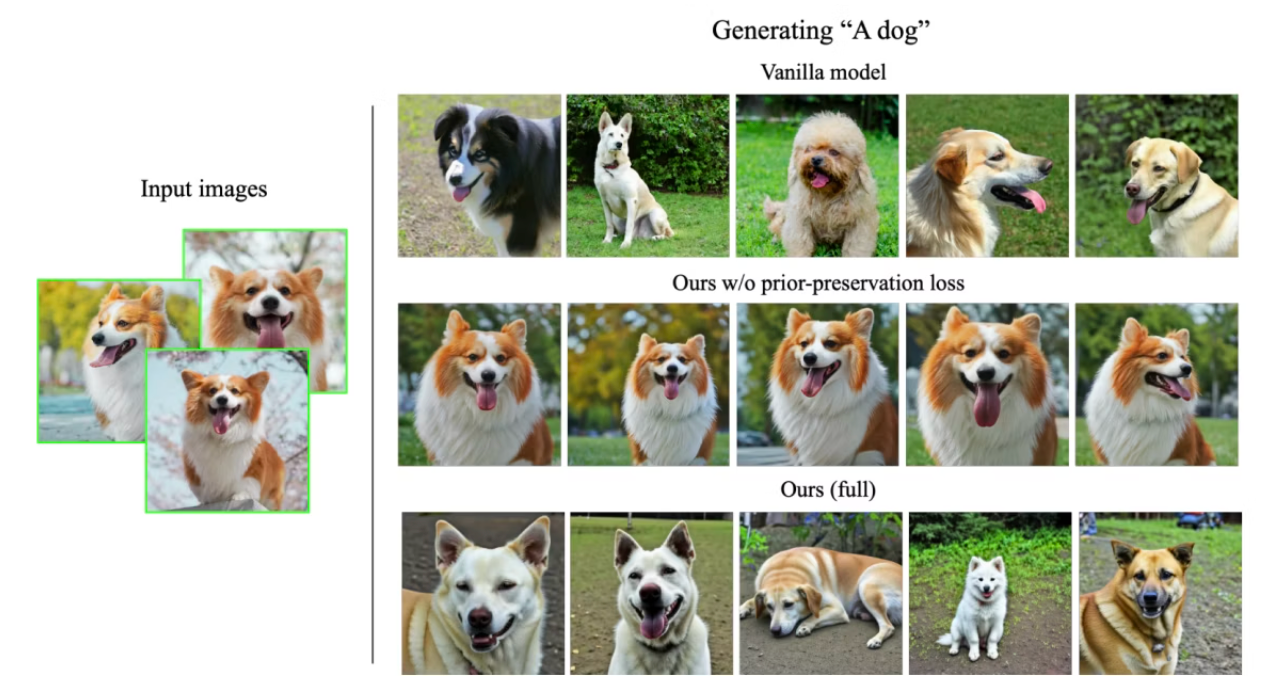
Language drift. Without prior-preservation loss, the fine-tuned model cannot generate dogs other than the fine-tuned one. Image taken from DreamBooth’s paper.
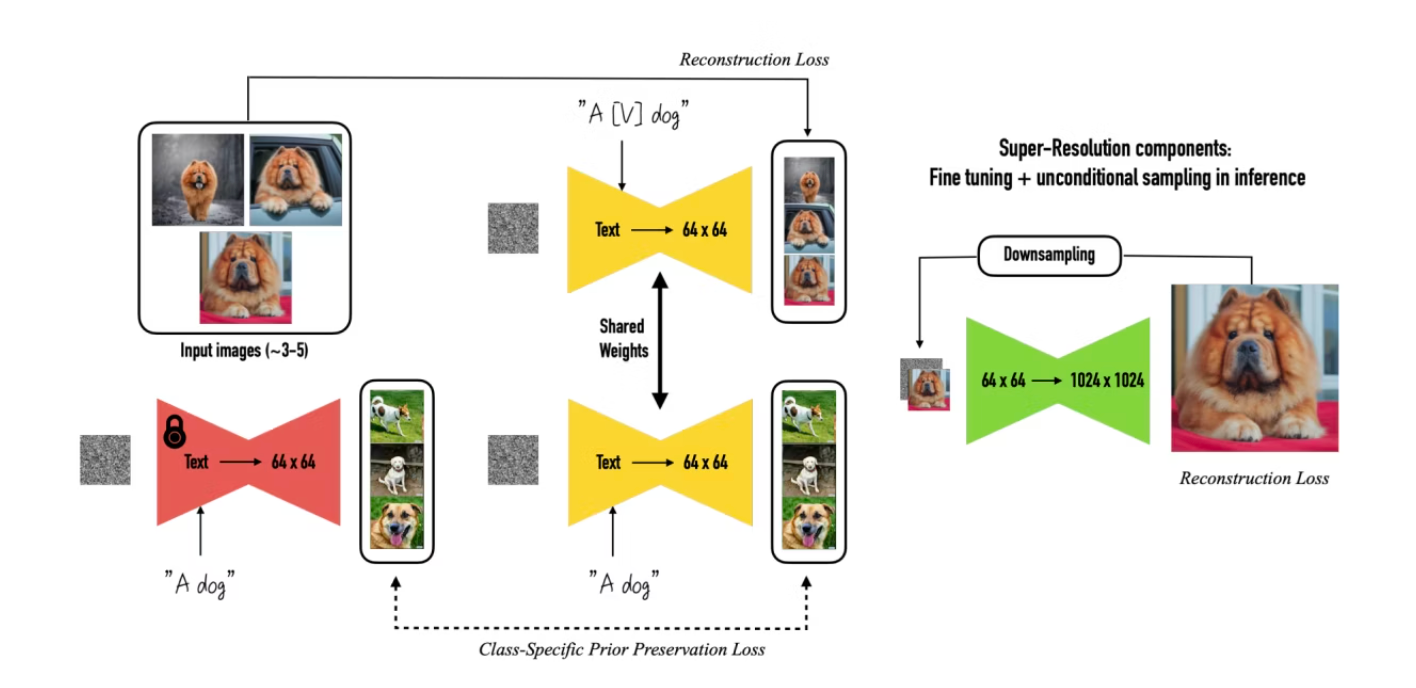
The training approach involves fitting the subject’s images together with generated images from the subject’s class using the Stable Diffusion model. Additionally, the super-resolution component of the model, which upsamples the output images from 64 x 64 to 1024 x 1024 resolution, is fine-tuned using only the subject’s images. This approach was described in DreamBooth’s paper.
Exploring Popular Stable Diffusion Models
Stable diffusion models have gained popularity due to their ability to generate realistic images and their impact on AI art. Let’s explore some of the widely-used stable diffusion models, such as Stable Diffusion v1.4, v1.5, and the introduction of v2 models.
An Overview of Stable Diffusion v1.4 and v1.5
Stable Diffusion v1.4 and v1.5 models, which are stable diffusion checkpoint models, have garnered attention in the AI art community for their ability to produce realistic images. These models utilize diffusion and stable diffusion weights to generate art that simulates real-world images. With advancements in stable diffusion training, these models have become base models for further image generation and training in AI art.
Each checkpoint can be used.
Stable diffusion v1.4: Model Detail Page
Stable diffusion v1.5: Model Detail Page

Introduction to v2 Models
Building on the success of v1.4 and v1.5 models, stable diffusion v2 models have emerged, bringing improved stability and control to image generation. These models offer higher-resolution versions of images, allowing for greater detail and fidelity in generated art. Developed through partnerships, such as Stability AI, stable diffusion v2 models are shaping the future of AI art, driving innovation, and expanding the possibilities of realistic vision art generation.
Here’s a list of websites you can run Stable Diffusion 2.0
Install Stable Diffusion 2.0 according to installation instructions on your respective environment. Launch AUTOMATIC1111 GUI. Input parameters, follow prompts, and monitor results.
After installation, you will need to download two files to use Stable Diffusion 2.0.
- Download the model file (768-v-ema.ckpt)
- Download the config file, and rename it to
768-v-ema.yaml - Put both of them in the model directory:
stable-diffusion-webui/models/Stable-diffusion - Using Stable Diffusion 2.0

A photo of a Russian forrest cat wearing sunglasses relaxing on a beach

How to Choose the Right Stable Diffusion Model?
With various stable diffusion models available, it is essential to choose the right model for your specific needs and art style. Factors such as training data, art style, and illustration style play critical roles in determining the optimal model for image generation.
Factors to Consider When Choosing a Model
When choosing a stable diffusion model, several factors should be considered:
- Specific needs: Determine the specific requirements of your art style and the desired output.
- Art style: Assess whether the model aligns with the art style you wish to achieve in your generated images.
- Illustration style: Consider whether the model is well-suited for generating images with the desired illustration style.
- Alongside these factors, artistry, training data quality, and stability of the checkpoint directory are critical considerations. By carefully evaluating these factors, artists can select the stable diffusion model that best suits their artistic vision.
Ready to see what’s out there? Here are our top 10 models!
Anime style.
Realistic photo style.
2.5D Styles

Common Mistakes to Avoid
When working with stable diffusion models, it is important to avoid common mistakes that can impact the quality of generated images. Some common mistakes to avoid include:
- Neglecting stability: Failing to control for stability during model training can lead to issues in generated images.
- Overlooking checkpoint directory: Ignoring the stability of the checkpoint directory can result in model inefficiency and hiccups during image generation.
- Neglecting original size: Disregarding the importance of generating images in their original size can compromise the detail and fidelity of the artwork.
- By being mindful of these potential pitfalls, artists can optimize their use of stable diffusion models, ensuring the highest quality of generated art.
Merging Models in Stable Diffusion
Merging models in stable diffusion introduces new opportunities for image generation, allowing artists to combine the strengths of different models for enhanced stability and image quality.
Benefits of Merging Two Models
Merging two stable diffusion models offers several benefits, including:
- Enhanced stability: Merging models can improve the stability of image generation, resulting in higher quality and more realistic output.
- Higher resolution images: By merging models, artists can generate images with higher resolution, capturing finer details and nuances.
- Expanded art style possibilities: Combining models allows for the exploration of different art styles, expanding the range of artistic expression.
- Powerful keywords: Merged models can yield powerful keywords, enabling artists to generate images specific to their desired art style.
- Diverse illustration styles: Merging models opens up the possibility of creating art with diverse illustration styles, further enhancing creativity and artistic impact.
Step-by-step Guide to Merging Models
To merge stable diffusion models, you go to the checkpoint merger tab up here and there are some settings.
follow these steps:
- Ensure stability of the primary model checkpoint directory. Loading up to three different models.
- Understand the specific needs and characteristics of each model before merging them. the merging process is figuring out the difference and then again with the slider here, you’re deciding how much of the percentage difference should go into Model A.
- Verify compatibility of stable diffusion checkpoint models, particularly with stability AI partner models.
- Combine stable diffusion checkpoint models using the appropriate techniques and tools.
- Verify the stability and compatibility of the merged models by generating test images.
- By following this step-by-step guide, artists can successfully merge stable diffusion models, unlocking new possibilities in image generation.

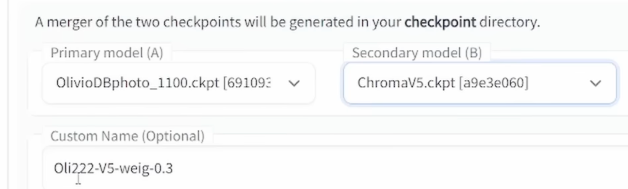
Here you can load up to three different models, model A, model B, and model C. The primary model is called Model A which is what you want to refine, so if you have trained your model with Dreambooth, and you want to mix it with other models, you load your model here into this case.
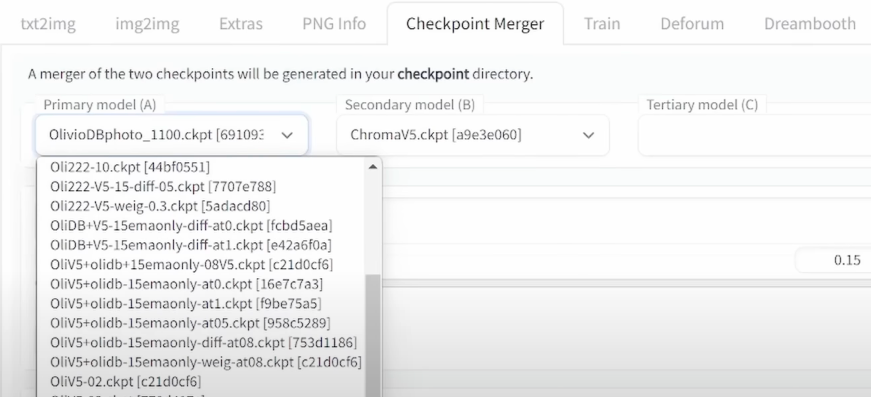
In the secondary model, you load whatever you want to mix with that, so in this case I have selected from my list for the ChromaV5 model.
Now below you see some other settings, first of all, regarding the Custom name I want highly suggest to that you write names that include all of the settings you did here so afterward when you do testing on these merged models, you can still understand what is going on so you can see here for example in this case, I’m using Oli222-V5-weig-0.3 so that means I have my Olivio model and I have already mixed it with the chroma V5 with a weighted sum of 0.3 so when I look at the file name I know exactly what’s going on, even when I come back days later or weeks later.
Multiplier is super easy to understand this defines, how much of Model B you want to mix into Model A and you can read these values as percentages so if you put this on zero that means zero percentage of B is going into A, If you put it into one, it’s one hundred percent right so that’s easy and if you put it anywhere in between for example to 0.25 that is going to be 25%, I would suggest to you that you generate multiple mergers. let’s say five different merges and then try out if they give you the result.

If you select the Add Difference method you always need three models it’s really important.

Different Model Types in Stable Diffusion
Understanding the different types of stable diffusion models is crucial in optimizing image generation and realizing specific artistic visions.
Understanding Pruned, Full, and EMA-only Models
Stable diffusion models are available in various types, including pruned, full, and EMA-only models:
- Pruned models: Pruned models offer higher resolution version generation, ensuring image stability and realistic vision in art generation.
- Full models: Full models provide a broad range of art style generation capabilities, allowing for diverse and unique image creations.
- EMA-only models: EMA-only models focus on generating stable diffusion weights for images, contributing to stability in the art generation process.
- Each model type caters to different needs and preferences, offering artists a wide range of options to explore and experiment with.
Differences between Fp16 and fp32 Models
Different stable diffusion model types, such as fp16 and fp32 models, offer unique advantages and characteristics that impact image stability and resolution:
- Fp16 models: Fp16 models specialize in generating images with specific art styles, offering stability and control over image generation within those specific styles.
- Fp32 models: Fp32 models ensure higher resolution, realistic vision art generation, providing enhanced clarity, detail, and fidelity in images.
- Understanding the differences between these model types is essential for selecting the model that best aligns with artistic goals and image generation requirements.
How is Stable Diffusion Shaping the Future of AI Art?
The advancements in stable diffusion models are shaping the future of AI art, paving the way for remarkable innovations and realistic vision art generation. Stable diffusion provides artists with powerful tools to create images that surpass traditional art methodologies, opening doors to new artistic expressions and possibilities. With stable diffusion, artists can generate images with higher resolution, enhanced stability, and a range of art style options, revolutionizing the art industry.
Conclusion
In conclusion, stable diffusion has revolutionized the field of AI art by providing artists with powerful tools to create stunning and realistic images. The science behind stable diffusion models is complex but essential to understand for anyone looking to explore this technology. Fine-tuning plays a crucial role in achieving optimal results and should not be overlooked. When choosing a stable diffusion model, it is important to consider factors such as computational requirements and the specific needs of your project. Merging models can bring unique benefits and expand the creative possibilities even further. Different model types, such as pruned, full, and EMA-only, offer different trade-offs and should be chosen accordingly. Overall, stable diffusion is shaping the future of AI art and opening up a world of possibilities for artists and enthusiasts alike.
novita.ai provides Stable Diffusion API and hundreds of fast and cheapest AI image generation APIs for 10,000 models.🎯 Fastest generation in just 2s, Pay-As-You-Go, a minimum of $0.0015 for each standard image, you can add your own models and avoid GPU maintenance. Free to share open-source extensions.
Recommended Reading


