Unlocking the Power of Llama 3.2: Multimodal Use Cases and Applications
Explore Llama 3.2's multimodal capabilities and use cases. Learn how to leverage this advanced AI model for image reasoning and edge applications with Novita AI.

Llama 3.2, Meta's latest advancement in large language models, introduces groundbreaking multimodal capabilities and lightweight versions optimized for edge devices. This new generation of AI models opens up a world of possibilities for developers and businesses alike. In this comprehensive guide, we'll explore the key features of Llama 3.2, its multimodal use cases, and how you can leverage its power to create innovative AI solutions. Whether you're building advanced chatbots, image analysis tools, or on-device AI applications, Llama 3.2 offers the versatility and performance to take your projects to the next level.
Table of Contents
- Key Features of Llama 3.2: A New Era of Multimodal AI
- Exploring Multimodal Capabilities: Vision and Language Integration
- Real-World Use Cases with Llama 3.2
- Accessing Llama 3.2 Vision Model on Novita AI
Key Features of Llama 3.2: A New Era of Multimodal AI
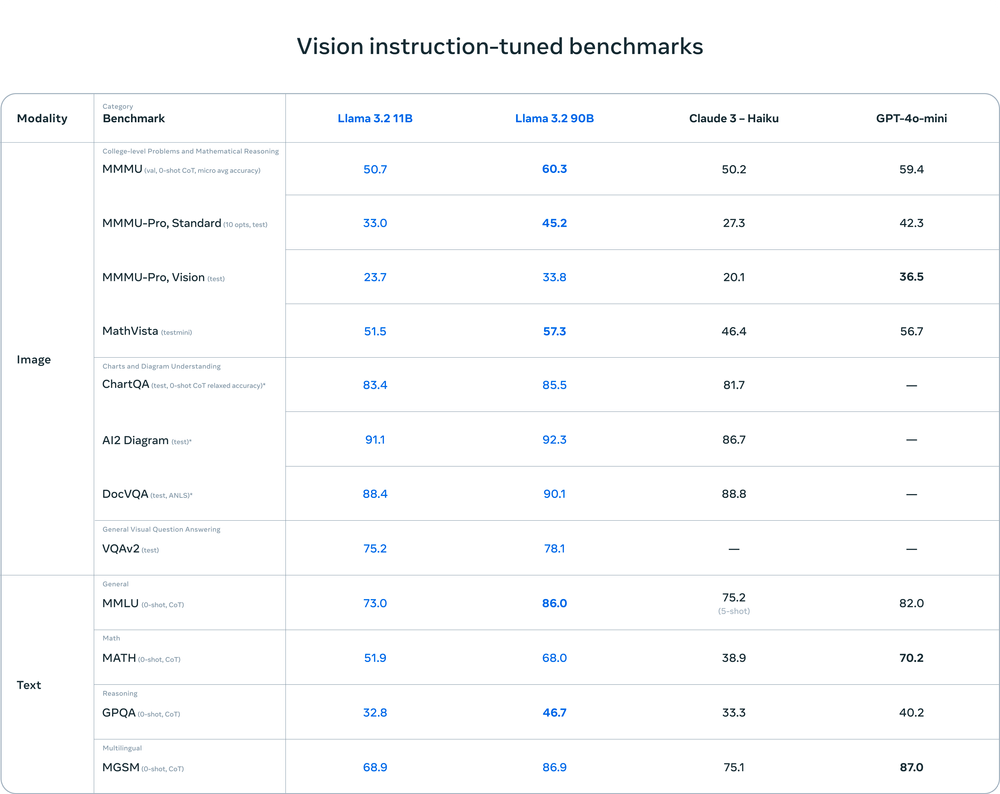
Llama 3.2 represents a significant leap forward in the field of artificial intelligence, offering a suite of models that cater to a wide range of applications and computational environments. At its core, Llama 3.2 is designed to be more versatile, efficient, and accessible than its predecessors, making it an attractive option for developers looking to implement cutting-edge AI solutions.
- Multimodal Capabilities: The 11B and 90B parameter models support both text and image inputs, enabling sophisticated reasoning tasks that combine visual and textual information.
- Lightweight Models: The 1B and 3B parameter models are optimized for edge devices, allowing for on-device AI processing with minimal latency.
- Improved Efficiency: All models in the Llama 3.2 family are designed for reduced latency and improved performance across various tasks.
- Llama Stack Integration: Built on top of the Llama Stack, these models offer a standardized interface for easier development and deployment of AI applications.
- Multilingual Support: Llama 3.2 demonstrates strong performance across multiple languages, making it suitable for global applications.
The architecture of Llama 3.2 builds upon the success of previous iterations, incorporating advanced techniques such as grouped-query attention (GQA) for optimized inference, especially beneficial for the larger 90B model. The instruction-tuned versions employ supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to enhance their ability to follow specific instructions and align with human preferences[3].For developers looking to explore the capabilities of Llama 3.2 and other advanced language models, Novita AI's LLM playground offers a free environment to experiment with these powerful tools.
Exploring Multimodal Capabilities: Vision and Language Integration
One of the most exciting aspects of Llama 3.2 is its multimodal functionality, which allows the model to process and reason about both text and images simultaneously. This integration of vision and language opens up a plethora of new use cases and applications that were previously challenging or impossible with text-only models.
Image Reasoning and Analysis
The 11B and 90B parameter models of Llama 3.2 are equipped with sophisticated image reasoning capabilities. These models can:
- Analyze charts and graphs to extract meaningful insights
- Provide detailed descriptions of complex visual scenes
- Answer questions about specific elements within an image
- Perform visual grounding tasks, such as identifying objects based on textual descriptions
For example, a business analyst could use Llama 3.2 to quickly interpret financial charts, extracting key trends and data points without manual analysis. Similarly, e-commerce platforms could implement visual search functionalities, allowing users to find products by uploading images rather than typing text descriptions[2].
Enhanced Document Understanding
Llama 3.2's multimodal capabilities extend to document analysis, where it can process both the textual and visual elements of a document simultaneously. This is particularly useful for:
- Analyzing scanned documents that contain both text and images
- Interpreting complex layouts in reports, presentations, or scientific papers
- Extracting information from infographics and data visualizations
Legal firms, for instance, could use Llama 3.2 to analyze contracts that include charts or diagrams, ensuring a comprehensive understanding of all document elements[1].
Image Captioning and Content Generation
The ability to generate text based on visual inputs makes Llama 3.2 a powerful tool for content creation and management:
- Automatically generating captions for images in social media posts
- Creating alt text for web accessibility
- Assisting in the production of visual content by suggesting complementary text
Marketing teams can leverage this capability to streamline their content creation process, generating engaging captions and descriptions for visual marketing materials[1].To start integrating these multimodal capabilities into your projects, check out Novita AI's Quick Start guide for using the LLM API.
Learn more about the vision ability of Llama 3.2.
Real-World Use Cases with Llama 3.2
Llama 3.2's multimodal capabilities shine in real-world scenarios, especially when combining image reasoning with text-based insights. Here are key applications demonstrating its versatility:
- Restaurant Receipt Analysis
Use Case: Facilitates financial management by analyzing multiple receipt images to calculate total expenses.
Process: Supports both individual image processing and a holistic analysis of merged receipts for comprehensive tracking.
Benefit: Streamlines expense tracking for businesses and individuals.
Example: A user uploads images of dining receipts, and the model identifies line items, calculates totals, and generates an expense summary.
- Drink Selection for Diet
Use Case: Aids in comparing the nutritional facts of two beverages captured in an image.
Output: Converts visual data into structured JSON for easy analysis and decision-making.
Benefit: Helps users make informed, health-conscious drink choices.
Example: Two drink labels are analyzed, and the system highlights calorie, sugar, and ingredient differences.
- Architecture Diagram Interpretation
Use Case: Simplifies complex diagrams, such as Llama 3 paper illustrations, by summarizing key elements and suggesting actionable implementation steps.
Benefit: Assists developers and researchers in understanding intricate designs.
Example: Upload an architecture diagram to get a step-by-step implementation guide and related recommendations.
- Chart to HTML Table Conversion
Use Case: Extracts data from visual charts like LLM speed comparisons and generates HTML table representations.
Benefit: Makes data more accessible and usable for presentations or further analysis.
Example: A user uploads a chart, and the tool outputs an organized HTML table summarizing the data.
- Fridge Contents Analysis
Use Case: Recognizes ingredients in fridge images and suggests recipes based on available items.
Benefit: Supports meal planning and minimizes food waste.
Advanced Feature: Includes follow-up questioning to refine recipe suggestions.
Example: Upload a photo of your fridge, and the system lists ingredients and suggests dishes like pasta with available vegetables.
- Interior Design Assistant
Use Case: Analyzes images of interiors to describe design elements, styles, colors, and materials.
Output: Provides detailed object lists and spatial relationships, enabling users to plan home decor effectively.
Benefit: Assists homeowners and designers in conceptualizing and refining interior projects.
Example: An image of a living room is analyzed, and the tool provides design suggestions, including complementary color schemes.
- Math Homework Grading
Use Case: Processes images of handwritten math assignments to evaluate answers and provide feedback.
Output: Calculates scores and offers guidance for incorrect responses.
Benefit: Revolutionizes educational technology with automated grading.
Example: Upload a child's math homework, and the model grades it, explaining areas for improvement.
- Tool Calling with Image Analysis
Use Case: Demonstrates advanced AI by combining image understanding with external tool integration.
Process:
Identifies the subject (e.g., Golden Gate Bridge) from an image.
Uses the information to perform related tasks like weather queries.
Benefit: Highlights potential for multi-step workflows.
The applications of Llama 3.2's multimodal capabilities discussed earlier are just the tip of the iceberg. These use cases serve as a springboard for developers and businesses to imagine and create even more groundbreaking solutions. The true potential of this powerful AI tool is yet to be fully realized, with countless unexplored possibilities waiting to be discovered.
Accessing Llama 3.2 Vision Model on Novita AI
To get started with Llama 3.2 vision model on Novita AI, follow these steps:
Step 1: Explore the Llama 3.2 Vision Model Demo
Step 2:Go to Novita AI and log in using your Google, GitHub account, or email address
Step 3:Manage your API Key:
- Navigate to "Key Management" in the settings
- A default key is created upon first login
- Generate additional keys by clicking "+ Add New Key"
Explore the LLM API reference to discover available APIs and models
Step 4:Set up your development environment and configure options such as content, role, name, and prompt
Step 5:Run multiple tests to verify API performance and consistency
API Integration
Novita AI provides client libraries for Curl, Python and JavaScript, making it easy to integrate Llama 3.3 70B Instruct into your projects:
For Python users:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="Your API Key",
)
model = "meta-llama/llama-3.2-11b-vision-instruct"
stream = True # or False
max_tokens = 16384
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
For JavaScript users:
import OpenAI from "openai";
const openai = new OpenAI({
baseURL: "https://api.novita.ai/v3/openai",
apiKey: "Your API Key",
});
const stream = true; // or false
async function run() {
const completion = await openai.chat.completions.create({
messages: [
{
role: "system",
content: "Be a helpful assistant",
},
{
role: "user",
content: "Hi there!",
},
],
model: "meta-llama/llama-3.2-11b-vision-instruct",
stream,
response_format: { type: "text" },
max_tokens: 16384,
temperature: 1,
top_p: 1,
min_p: 0,
top_k: 50,
presence_penalty: 0,
frequency_penalty: 0,
repetition_penalty: 1
});
if (stream) {
for await (const chunk of completion) {
if (chunk.choices[0].finish_reason) {
console.log(chunk.choices[0].finish_reason);
} else {
console.log(chunk.choices[0].delta.content);
}
}
} else {
console.log(JSON.stringify(completion));
}
}
run();
For Curl users:
curl "https://api.novita.ai/v3/openai/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer Your API Key" \
-d @- << 'EOF'
{
"model": "meta-llama/llama-3.2-11b-vision-instruct",
"messages": [
{
"role": "system",
"content": "Be a helpful assistant"
},
{
"role": "user",
"content": "Hi there!"
}
],
"response_format": { "type": "text" },
"max_tokens": 16384,
"temperature": 1,
"top_p": 1,
"min_p": 0,
"top_k": 50,
"presence_penalty": 0,
"frequency_penalty": 0,
"repetition_penalty": 1
}
EOF
Conclusion
Llama 3.2 represents a significant leap forward in multimodal AI capabilities, offering developers powerful tools to create innovative applications across various domains. From sophisticated image reasoning to efficient edge computing, Llama 3.2 opens up new possibilities for AI-driven solutions. By leveraging its advanced features and following best practices for implementation, developers can build cutting-edge applications that combine visual and textual understanding in ways previously unattainable.
If you're a startup looking to harness this technology, check out Novita AI's Startup Program. It's designed to boost your AI-driven innovation and give your business a competitive edge. Plus, you can get up to $10,000 in free credits to kickstart your AI projects.
Frequently Asked Questions about Llama Models
Is Llama 3.2 1B multimodal?
No, Llama 3.2 1B is a text-only model and does not have multimodal capabilities.
Is Llama 3.1 8B multimodal?
No, Llama 3.2 8B is also a text-only model and does not support multimodal functionality.
Is Llama 3.2 11B multimodal?
Yes, Llama 3.2 offers multimodal capabilities in its larger models (11B and 90B).
Can Llama 3.2 generate an image?
No, while Llama 3.2 can process and analyze images, it does not have the capability to generate images.
Can I use Llama 3 for commercial use?
Yes, you can use Llama 3 (specifically Llama 3.1) for commercial purposes under specific conditions outlined in the Meta community license agreement, including proper attribution and compliance with legal requirements.
Originally published at Novita AI
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading