Stable Diffusion Accelerated Up to 211.2%: Aitemplate, TensorRT, OneFlow, and Xformers Acceleration Test

1. Introduction
Stable Diffusion is an image generation technology based on the diffusion model, capable of producing high-quality images from text, suitable for CG, illustrations, and high-resolution wallpapers, among other fields.
However, due to its complex computation process, Stable Diffusion’s image generation speed can often become a bottleneck. To address this issue, novita.ai conducted a series of comparative tests on acceleration methods, including Xformers, Aitemplate, TensorRT, and OneFlow.
In this article, we will introduce the principles and performance test results of these acceleration methods, providing considerations on cost-effectiveness for different graphics cards to assist in making informed choices during deployment.
The test results indicate that OneFlow achieves a speedup of 211.2% compared to Xformers on RTX 3090 and a speedup of 205.6% on RTX 4090. Therefore, when deploying Stable Diffusion, the preferred GPU choice is RTX 3090.

2.Acceleration Scheme Principles and Characteristics Comparison
Firstly, we have organized various schemes that can be used to accelerate stable diffusion.
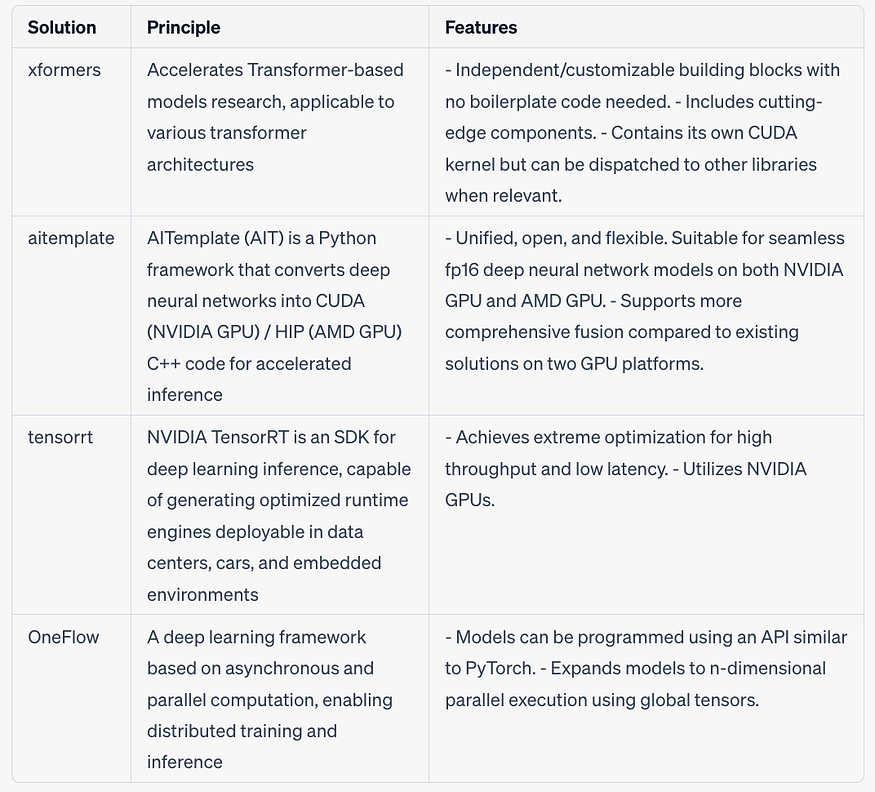
We have selected Xformers, Aitemplate, TensorRT, and OneFlow as our acceleration schemes. NvFuser is similar in principle to Xformers, both using FlashAttention technology. DeepSpeed and colossal are primarily designed for training acceleration, while OpenAI Triton serves as a model deployment engine, suitable for batch size acceleration but not for model optimization latency scenarios. Thus, these are excluded from our comparison.
Currently, we are testing the performance of the WebUI basic scheme and the four acceleration schemes (Xformers, Aitemplate, TensorRT, and OneFlow) on different GPUs.
We use VoltaML to evaluate Aitemplate’s acceleration effect, Stable Diffusion WebUI to assess Xformers’ acceleration, the official TensorRT example for TensorRT’s performance, and integrate OneFlow into Diffusions to test its acceleration.

3. Acceleration Scheme Testing
Next, we will present the relevant testing configurations and share the actual test results with you.
3.1 Testing Setup
For this round of testing, our performance metric is iterations per second (its/s).
Image Settings: 512*512, steps 100
Prompts: A beautiful girl, best quality, ultra-detailed, extremely detailed CG unity 8k wallpaper, best illustration, an extremely delicate and beautiful, floating, high resolution.
Negative: Low resolution, bad anatomy, bad hands, text error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet, fused body.
Sampler: Euler a
Model: Stable Diffusion 1.5
3.2 Test Results
After a series of tests, we obtained performance test results on various GPUs, as shown below:

From the table above, we can observe that the acceleration comparison is as follows: OneFlow > TensorRT > Aitemplate > Xformers.
OneFlow achieves a relative speedup of 211.2% compared to Xformers on RTX 3090, and a speedup of 205.6% on RTX 4090.

4. GPU Performance and Cost-effectiveness Comparison
We conducted a cost-effectiveness analysis for different GPUs. Here are the conclusions:
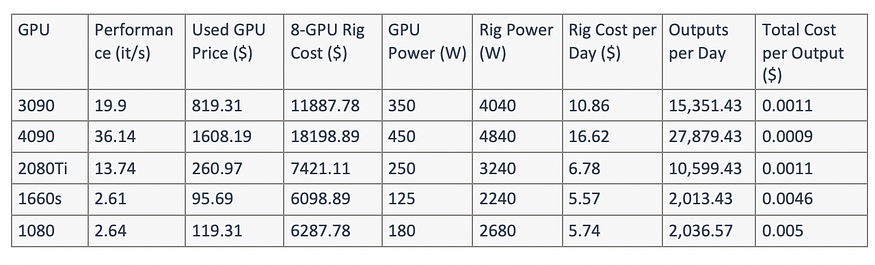
Conclusion 1: From a cost-effectiveness perspective, the RTX040 GPU offers the highest value.
Conclusion 2: Extremely low-end GPUs can increase overall costs. The RTX 2080Ti might strike a balance between initial heavy investments and overall costs.
Conclusion 3: Least performing GPUs
In this test, we selected several low-end GPUs with a memory capacity greater than 6GB, including M60, 1660s, and 1080.
1. GPUs like 1660s and 1080 do not support acceleration schemes such as TensorRT, Aitemplate, and OneFlow, possibly due to insufficient memory or GPU incompatibility.
2. Among these, 1660s (1080) achieved 2.61 it/s (2.64 it/s) when generating 512*512 images with 20 steps taking 7.66s (7.57s), indicating some level of usability.
3. On the other hand, the M60 achieved 1.27 it/s, taking 15.74s to generate 512*512 images with 20 steps, indicating poorer usability.

5. Selection Recommendations
5.1 The RTX 4090 offers the highest cost-effectiveness, but we recommend deploying the RTX 3090.
For example, we can calculate the “iterations per dollar” for each GPU using the runpod test, representing the cost-effectiveness of the GPU.
It’s evident that under similar utilization rates, the RTX 4090 has higher cost-effectiveness compared to the RTX 3090. Furthermore, the RTX 3090 outperforms other GPUs of the same level, such as A5000 and A4000.
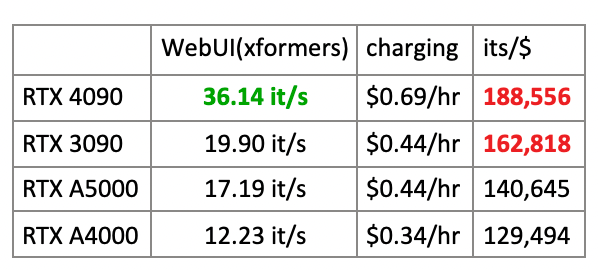
The choice of RTX 4090 for Stable Diffusion models depends on specific circumstances:
- Actual cost-effectiveness is determined by utilization (hours of usage per hour/60min) * its/$. Depending on the service mode and estimated utilization, if the utilization of RTX 4090 is similar to using two times the RTX 3090, then RTX 4090’s cost-effectiveness is higher. However, if deploying two RTX 3090 instances results in higher utilization due to increased concurrent support and request handling, the RTX 3090 might be preferred. Utilization needs to be analyzed based on the specific scenario.
- its/$ represents inference performance, while larger VRAM allows caching more models, reducing model loading time, and accelerating the image generation process significantly. Both RTX 3090 and RTX 4090 have 24GB VRAM, but if Stable Diffusion WebUI is optimized based on VRAM usage, RTX 3090 might have an advantage in VRAM cost.
- If prioritizing inference speed, RTX 4090 is the best choice as its inference time is approximately half that of RTX 3090.
This is consistent with the findings in https://timdettmers.com/2023/01/30/which-gpu-for-deep-learning/. For more GPU data, refer to the graph below.
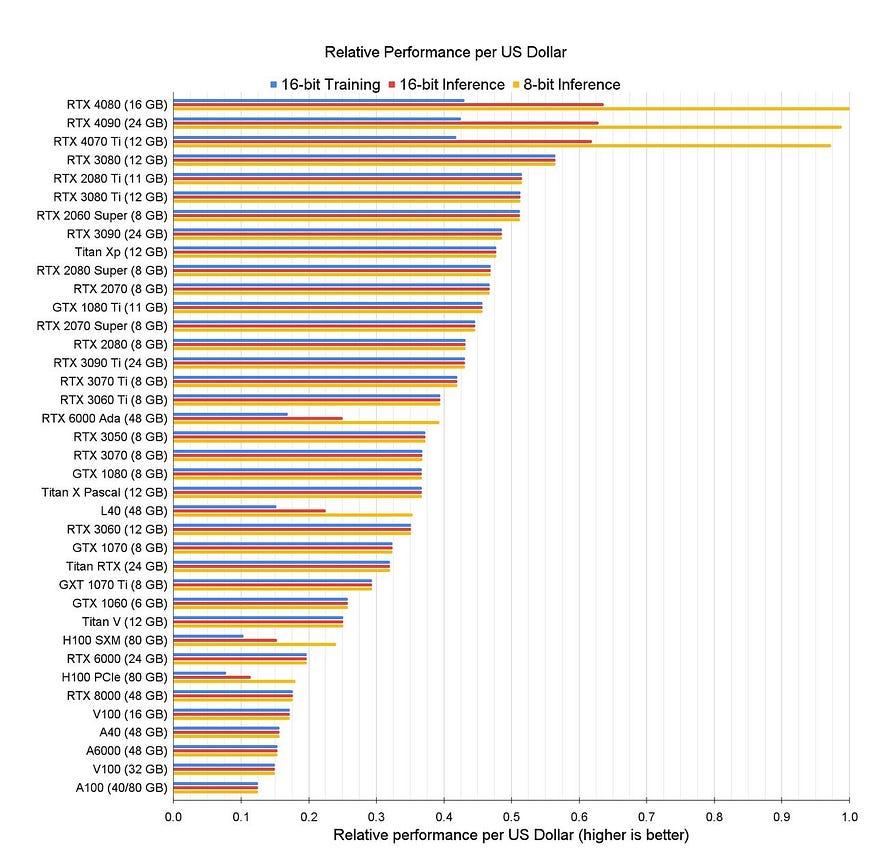
When the GPU time is a small proportion of the overall time in the processing chain, it is possible to choose GPUs with slightly lower performance to replace the RTX 3090. This includes options such as A5000, A10G, RTX 3080, RTX 3080Ti, and RTX 2080Ti.
If you have any questions or would like to explore more acceleration options for Stable Diffusion, feel free to reach out to us on our Discord.
Welcome to join and explore the capabilities of Stable Diffusion with novita.ai!
novita.ai provides Stable Diffusion API and hundreds of fast and cheapest AI image generation APIs for 10,000 models.🎯 Fastest generation in just 2s, Pay-As-You-Go, a minimum of $0.0015 for each standard image, you can add your own models and avoid GPU maintenance. Free to share open-source extensions.
Recommended reading