PyTorch Weight Initialization Demystified

Introduction
Setting up initial weights in a neural network is crucial for training. These starting weights are adjusted during training to improve the model’s performance by reducing errors and enhancing accuracy. Proper weight initialization is essential in deep learning as it impacts the efficiency of learning. This article explores various methods of setting initial weights using PyTorch, a popular framework for deep learning projects, to help your neural network learn faster and perform better.
Understanding the Basics of Weight Initialization
Weight initialization sets the starting values for weights in a neural network. These start points are important because they start the training phase. An activation function makes sure our neural network does more than simple calculations.
We usually pick random numbers to initialize these weights. The numbers we choose affect how well our model learns and performs. You might need to adjust your weight initialization strategy depending on the activation function you’re using.
Why Weight Initialization is Crucial in Deep Learning
It’s important to set up the weights right when training a neural network, especially with deep learning. These weights decide how the brain handles and responds to incoming information. If these starting thoughts aren’t set up well, it can make learning slow or mess things up, leading to poor results.
If we don’t set the weights right, our model will have a hard time learning.

If we don’t get the weights right, the model will take longer to train, won’t be as accurate, or won’t work at all.
But if we get the weights right, the model will learn faster and better.
Common Pitfalls in Weight Initialization
It’s important to get the initial weights right when setting up a neural network. If you don’t, you might have problems with gradients that are too small or too big, which can affect learning.
Your network might take a long time to find the best solution if it got stuck at the start. This happens if the first weights aren’t set right.
To avoid problems, choose a good method for setting initial weights. There are some great techniques for this, like Xavier and He initialization. They help your neural network learn and perform better.
Try different weight initialization methods until you find one that fits your neural network.
Exploring PyTorch Weight Initialization Techniques
PyTorch is a well-liked framework for deep learning that comes with its nn.init module, packed with various weight initialization methods. These options let you choose between setting up the initial weights yourself or letting PyTorch do it automatically.
Manual Weight Initialization in PyTorch
PyTorch gives you the power to set up the starting weights of your neural network on your own. This comes in handy when you already know a bit about what you’re working with or if there’s a special way you need to kick things off because of how your network is built.
Automatic Weight Initialization in PyTorch
PyTorch’s nn.init module makes it super easy to set up the weights in your neural network right off the bat, without you having to do it by hand. It comes packed with some default methods that usually hit the mark for most types of projects.
For starters, here are a few ways PyTorch can automatically get those weights ready:
- With uniform initialization, it picks random numbers from a flat line within certain limits.
- Xavier or Glorot initialization goes for a bell curve approach but keeps things centered around zero and tweaks how spread out the numbers are.
- Kaiming is perfect if you’re into using ReLU because it adjusts weight scale based on how ReLU behaves.
- Zeros does exactly what you think: fills everything up with zeroes.
- Ones isn’t much different; just swap out zeros for ones.
- Normal grabs values from your typical bell curve distribution but doesn’t stick to any specific center or spread.
Diving Deeper into PyTorch’s nn.init Module
The nn.init module in PyTorch is a handy tool that helps you set up the initial weights for your neural network layers using different strategies. With this module, initializing the weights of your network becomes straightforward.
Understanding nn.init’s Role and Functions
In PyTorch, the nn.init module is super important for getting neural network weights set up right. It’s packed with different ways to kick off those weights in your network layers just how you need them.
With the nn.init module, setting up weight initialization is a breeze because it brings together all these handy functions and methods. You can use them on your layer’s weight tensors to get started with some initial values that make sense. Here are a few of the go-to options:
- torch.nninit.uniform_: With this function, you’re filling in the weights using numbers from a uniform distribution that fall within a certain range.
- torch.nninit.xavieruniform: This method also uses a uniform distribution but adds special scaling factors into the mix for initializing those weights.
- torch.nninit.normal_: If you prefer starting with values from a normal (or Gaussian) distribution, this function does exactly that by letting you specify mean and standard deviation parameters.
- torch.nninit.xaviernormal: Similar to its xavier_uniform cousin but for normal distributions; it sets up your initial weight values considering specific scaling factors as well.

Practical Examples of Using nn.init for Different Layers
The nn.init module in PyTorch provides a variety of weight initialization techniques that can be applied to different layers of a neural network. These techniques offer flexibility in initializing the weights based on the specific requirements of each layer.
Here are some practical examples of using nn.init for different layers:
- Linear Layer: The weights of a linear layer can be initialized using techniques like Xavier initialization or He initialization. These techniques ensure proper scaling and variance of the weights.
- Convolutional Layer: The weights of a convolutional layer can be initialized using similar techniques as the linear layer. However, it is important to consider the specific requirements of the convolutional layer, such as the number of input and output channels.
- Recurrent Layer: Recurrent layers, such as LSTM or GRU, have specific weight initialization requirements. Techniques like Xavier initialization or orthogonal initialization can be used to initialize the weights of recurrent layers effectively.
Advanced Techniques in Weight Initialization
While simple methods like Xavier and He initialization work well for many cases, there are other ways to boost how your neural network performs.
Using Xavier/Glorot Initialization for Better Convergence
Xavier initialization is a useful way to set up your neural network. It works well with tanh or sigmoid activation functions. Xavier initialization picks weights from a normal distribution with an average of zero and a variance based on the layer’s inputs and outputs.
Xavier prevents problems like exploding or vanishing gradients when training your neural network. This way, each part of your neural net gets information at the right pace.
Sticking with Xavier for setting up weights in your model’s layers according to this specific pattern ensures everything flows smoothly during learning. This speeds up learning and improves accuracy.
The Importance of He Initialization for ReLU Networks
He initialization is a way to set up the starting weights for neural networks that use ReLU, which stands for Rectified Linear Unit, as their activation function. This method helps solve issues where gradients become too small or too large, making it hard for the network to learn.
With He initialization, the initial weights are picked from a normal distribution with an average of zero and a variance that depends on how many inputs each layer has.
Because ReLU functions in a specific nonlinear way, He initialization adjusts the weight scale so both input and output variances match. This step is crucial because it avoids problems with gradients disappearing and makes training neural networks more effective and faster.
Make Your Way of Weight Initialization More Powerful
Using GPU cloud services to initialize weights in PyTorch can significantly enhance the efficiency and speed of deep learning projects. When you leverage powerful GPU cloud resources, you can quickly initialize and fine-tune the weights of your neural network models, ensuring they are set up optimally for training. This process benefits from the high computational power and parallel processing capabilities of GPUs, which can handle large workloads and complex operations swiftly.
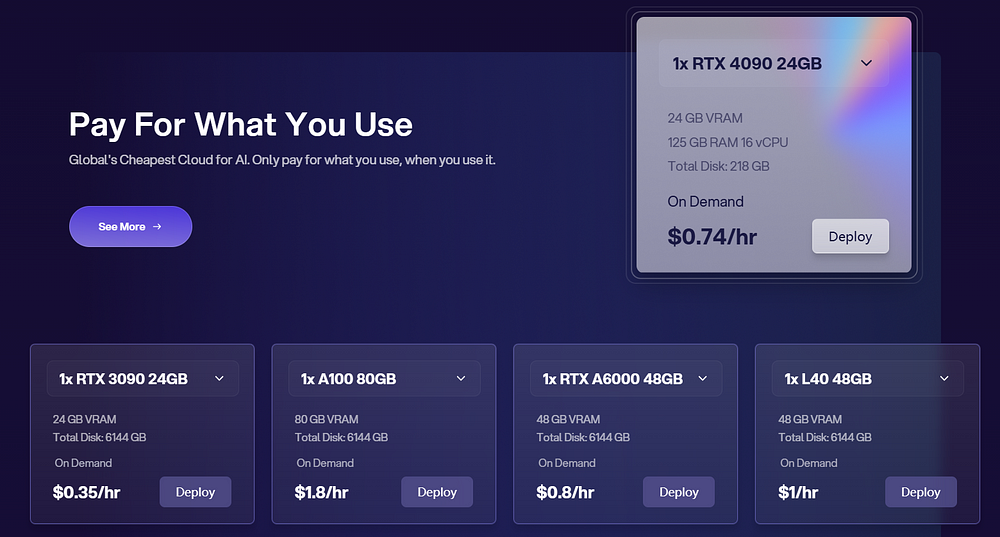
Novita AI GPU Instance offers every developer or lerner high-quality and cost-effective GPU resource in a pay-as-you-go way. Except the multiple choices of GPUs, like RTX 4090 or A100, you can also directly open Pytorch and other framework you want.
Conclusion
In PyTorch, starting weights correctly is important for better models. By learning different ways to set up weights and more complex methods like Xavier/Glorot and He initialization, you can make things run smoother and improve how well your network does its job. The nn.init module is useful for adjusting weight setup for different layers to improve training. Starting with the right weights is important for deep learning success. Mastering these techniques is crucial for top-notch model performance.
Frequently Asked Questions
How to initialize weights in PyTorch?
In PyTorch, you can initialize weights using the torch.nn.init module which provides various initialization methods like torch.nn.init.xavier_uniform_, torch.nn.init.kaiming_normal_, etc.
What is PyTorch default initialization?
The default initialization algorithm used in PyTorch uses a Uniform Distribution with the range depending on the size of the layer with a formula that looks pretty similar to Xavier initialization.
Why not initialize weights to 0?
Initializing all the weights with zeros leads the neurons to learn the same features during training. In fact, any constant initialization scheme will perform very poorly.
Are there any common pitfalls to avoid when initializing weights in PyTorch?
Yes. For example, using the default weight initialization, using the same weight initialization for all layers, using a too large or too small weight initialization, not initializing the biases and not using a seed for weight initialization.
Novita AI, is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance - the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading: