LLM Leaderboard 2024 Predictions Revealed

Key Highlights
- LLM leaderboards play a crucial in evaluating and comparing language models in the field of NLP
- They provide insights into the performance of different language models on various NLP tasks
- Recent research indicates that LLM leaderboards may be misleading due to biases and limitations in benchmark evaluations
- Task-specific benchmarks are suggested as a way to improve the evaluation of LLMs
- The issue of data contamination in LLM training is being addressed through advanced data processing techniques and rigorous testing
- The future of LLM leaderboards lies in technological advancements and open-source contributions
Introduction & Background
Large Language Models (LLMs) have revolutionized the field of Natural Language Processing (NLP) by enabling machines to understand and generate human-like text. To evaluate and compare the performance of different LLMs, LLM leaderboards have become an essential tool in the AI community. These leaderboards provide a standardized framework for assessing the capabilities of language models on various NLP tasks such as text generation, language understanding, translation, sentiment analysis, and question answering.
LLM leaderboards play a crucial role in advancing the field of NLP by fostering competition among researchers and practitioners. They encourage model development and provide a platform for showcasing state-of-the-art models. By benchmarking models based on their performance on multiple-choice tests and crowdsourced A/B preference testing, these leaderboards help identify the best-performing models for different tasks and datasets.
However, there is a growing concern regarding the reliability and accuracy of LLM leaderboards. Recent research has highlighted biases and limitations in benchmark evaluations, which may lead to misleading rankings. It has been found that even small changes in the evaluation format, such as the order of questions or answer options, can significantly impact the leaderboard rankings.
Understanding LLM Leaderboards and Their Importance
LLM leaderboards are important in the AI community as they foster competition and encourage the development of better language models. They also provide a standardized framework for comparing the performance of different models and tracking advancements in the field over time.
What Are LLM Leaderboards
LLM leaderboards are ranking systems that evaluate and compare different language models based on their performance on various NLP tasks. These leaderboards provide a standardized framework for assessing the capabilities of language models and help researchers and practitioners identify state-of-the-art models.
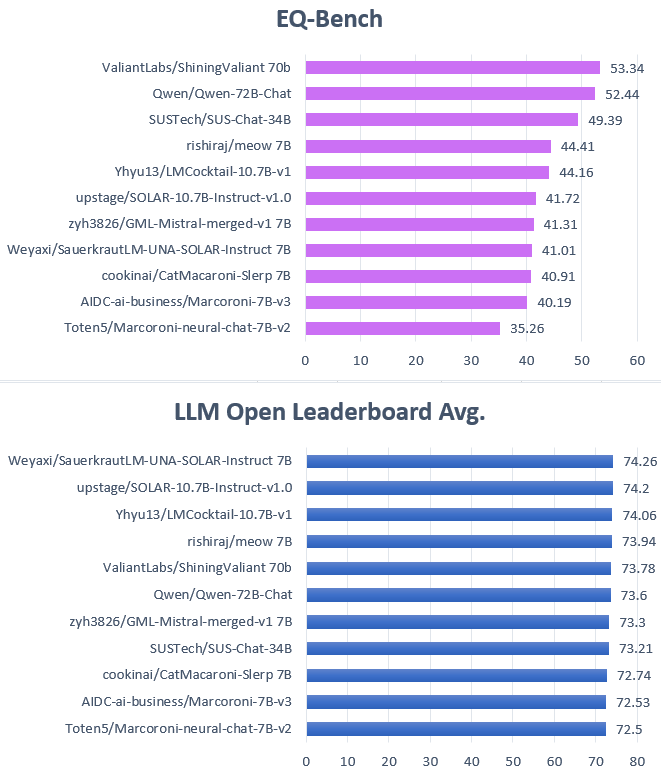
LLM leaderboards typically rank models based on their performance on multiple-choice benchmark tests and crowdsourced A/B preference testing. They evaluate models on tasks such as text generation, language understanding, translation, sentiment analysis, and question answering.
Some of the most popular LLM leaderboards include those on Hugging Face, MMLU, AlpacaEval, MT-Bench, and ChatbotArena. These leaderboards play a crucial role in advancing the field of NLP by fostering competition, encouraging model development, and providing a standardized framework for comparing the performance of different language models.
Significance in the AI Community
LLM leaderboards are of great significance in the AI community as they provide a standardized framework for evaluating and comparing language models. These leaderboards help researchers and practitioners identify state-of-the-art models and track advancements in the field over time.
LLM leaderboards serve as benchmarks for evaluating the performance of language models on various NLP tasks. They provide insights into the capabilities of different models and help guide model selection for specific use cases.
In addition, LLM leaderboards foster competition among researchers and practitioners, driving innovation in the field of NLP. They encourage the development of better language models by showcasing top-performing models and identifying areas for improvement.
Overall, LLM leaderboards play a crucial role in advancing the field of AI by providing a standardized framework for comparing the performance of language models and promoting continuous improvement in the development of AI technologies.
Key Players in LLM Leaderboards for 2024
There are several key players in the LLM leaderboards for 2024. These include emerging LLM technologies and leading organizations and projects.
Emerging LLM Technologies and Their Impact
Emerging LLM technologies are expected to have a significant impact on the LLM leaderboards for 2024. These technologies bring new features and capabilities to language models, pushing the boundaries of what they can achieve. Some of the emerging LLM technologies and their impact on the leaderboards include:
- Open LLMs: Open-source LLMs that can be locally deployed and used for commercial purposes.
- Chatbot Arena: A benchmark platform that features anonymous randomized battles in a crowdsourced manner.
- New Features: Technological advancements that enhance the performance of LLMs in various NLP tasks.
These emerging technologies are expected to shape the future of LLM leaderboards by introducing new models and features that push the boundaries of language understanding and generation.
Predictions on Leading Organizations and Projects
The LLM leaderboards for 2024 are expected to be dominated by leading organizations and projects in the field of AI and NLP. These organizations and projects are at the forefront of developing innovative language models and pushing the boundaries of what LLMs can achieve. Some predictions on leading organizations and projects in the LLM leaderboards for 2024 include:
- OpenAI: Known for its GPT models, OpenAI is expected to continue leading the way in developing advanced language models.

- Meta AI: Meta AI’s llama models have gained recognition for their performance and are likely to be among the top-ranking models.

- Novita.AI: One-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation.

These predictions are based on the current landscape of LLM development and the performance of leading organizations and projects in the field.
Criteria for Ranking on the LLM Leaderboard
Several criteria are considered for ranking LLMs on the leaderboard. These criteria focus on evaluating the performance and capabilities of language models in various NLP tasks.
Evaluation Metrics Explained
Evaluation metrics play a crucial role in assessing the performance of LLMs on the leaderboard. These metrics provide insights into the capabilities of language models and help researchers and practitioners identify top-performing models.
Some commonly used evaluation metrics for LLMs include:
- Accuracy: The percentage of correct responses generated by the language model.
- Fluency: The smoothness and coherence of the generated text.
- Context-awareness: The ability of the model to understand and utilize context in generating responses.
- Benchmark Performance: The performance of the language model on benchmark tests and crowdsourced A/B preference testing.
These metrics help evaluate the depth and breadth of language models’ language abilities and provide a comprehensive assessment of their performance.
The Role of Innovation and Accuracy
Innovation and accuracy are key factors in ranking LLMs on the leaderboard. Language models that demonstrate innovative features and capabilities are more likely to rank higher on the leaderboard. Similarly, models that consistently generate accurate and contextually relevant responses are more likely to be considered top-performing models.
Innovation plays a crucial role in advancing the field of NLP and pushing the boundaries of what language models can achieve. Accuracy, on the other hand, ensures that language models generate reliable and trustworthy responses.
Language models that combine innovation with accuracy are likely to stand out on the leaderboard and gain recognition in the AI community.
Navigating LLM Benchmarks
Navigating LLM benchmarks requires an understanding of the diversity of LLM models and the challenges faced by LLM leaderboards. These benchmarks provide insights into the capabilities and performance of language models and help researchers and practitioners make informed decisions.

Diversity of LLM Models
The domain of Large Language Models (LLMs) is diverse and multifaceted, as every model offers its distinct advantages. Some examples of those are GPT (generative pre-trained transformer) and BERT (bidirectional encoder representations from transformers). The variety becomes even more remarkable with the inclusion of specialized models tailored for specific purposes. The significance of AI leaderboards lies in their role in aiding users and researchers to pinpoint the models that best align with their specific requirements and goals.

The importance of LLM Benchmarks
Benchmarking LLMs is a foundational aspect of gauging the comprehensive abilities of language models, offering a range of standardized tests designed to measure their performance across a spectrum of tasks. These tasks span from understanding natural language to analyzing sentiment, generating text, and more, each crafted to test various aspects of a model’s cognitive ability and adaptability. Establishing a consistent and fair standard for comparison is crucial to ensure that assessments are not only relative but also accurately reflect a model’s real-world effectiveness.
As the landscape of AI evolves with models growing in complexity and new capabilities emerging, benchmarks too must evolve. Incorporating innovative tasks that present fresh challenges is essential. This strategy ensures that benchmarks stay current and stringent, continually expanding the limits of what AI can achieve and fostering progress in the sector.
Challenges Faced by LLM Leaderboards
LLM leaderboards face several challenges that impact the reliability and accuracy of their rankings. These challenges include addressing biases and ensuring data privacy and security.
Addressing Bias and Fairness
Addressing bias and ensuring fairness in LLM leaderboards is a crucial challenge. Biases in benchmark evaluations can lead to misleading rankings and favor certain models over others. To address this challenge, researchers and practitioners are working on developing unbiased evaluation methods that consider a wider range of factors and use diverse datasets.
Fairness is another important aspect to consider in LLM leaderboards. Ensuring that language models are evaluated and ranked based on objective criteria and are not influenced by factors such as gender, race, or ethnicity is essential for fair and unbiased rankings.
The Issue of Data Privacy and Security
The issue of data privacy and security is another challenge faced by LLM leaderboards. Language models are trained on vast amounts of data, some of which may contain sensitive or private information. Ensuring that this data is handled securely and that the privacy of individuals is protected is of utmost importance.

Researchers and organizations working on LLM leaderboards must adhere to strict data privacy and security protocols. This includes anonymizing data, implementing secure data storage and transmission systems, and obtaining appropriate consent from individuals whose data is used for training language models.
Future Directions for LLM Leaderboards
The future of LLM leaderboards lies in technological advancements and open-source contributions. These directions are expected to shape the development and evaluation of language models in the coming years.
Anticipated Technological Advancements
Technological advancements are expected to drive the development of LLM leaderboards. These advancements may include improvements in model architecture, training techniques, and data processing methods. They are likely to result in more accurate and reliable language models that perform better across various NLP tasks.
The Importance of Open-Source Contributions
Open-source contributions are crucial for the advancement of LLM leaderboards. Open-source models and tools enable collaboration and knowledge sharing among researchers and practitioners, leading to the development of better language models. By making their models open-source, organizations and researchers contribute to the growth and improvement of the AI community as a whole.
Conclusion
In conclusion, LLM Leaderboards play a crucial role in the AI community, showcasing the advancements and innovations in language models. With emerging technologies shaping the landscape, it’s essential to focus on innovation, accuracy, and fairness in rankings. Despite challenges like bias and data privacy, the future of LLM Leaderboards looks promising with anticipated technological advancements and open-source contributions driving progress. By understanding the criteria for ranking and navigating diverse LLM models, organizations can stay competitive and contribute to the evolution of language model benchmarks. Stay informed about the key players and projects to watch in 2024 for insights into the dynamic world of LLM Leaderboards.
Frequently Asked Questions
What Makes an LLM Stand Out in the Leaderboard?
An LLM stands out on the leaderboard based on its standout features, use case relevance, and its ability to generate high-quality text. The performance of an LLM on various NLP tasks, such as text generation, language understanding, and translation, contributes to its ranking on the leaderboard.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
Novita.ai vs. Together.ai: A Comprehensive Comparison
Unveiling the Power of Large Language Models: A Deep Dive into Today's Leading LLM APIs
The Ethical Frontier: Analysing the Complexities of NSFW AI