LLM in a Flash: Efficient Inference Techniques With Limited Memory

Efficiently infer with limited memory using LLM in a flash. Explore techniques in our blog for quick and effective results.
Key Highlights
- Efficient large language model inference techniques have been developed to tackle the challenges of running large models on devices with limited memory.
- These techniques leverage innovative strategies such as model pruning, dynamic computation offloading, and memory management to optimize memory usage and improve inference speed.
- The concepts of temporal locality and sparsity are key factors in maximizing efficiency and memory utilization in large language models.
- By implementing innovative memory management techniques and utilizing row-column bundling, LLM inference can be enhanced to achieve higher throughput and faster processing times.
- Frequently asked questions include how LLMs operate efficiently on devices with limited memory and whether LLM inference speed can be improved without compromising accuracy.
- The research paper “LLM in a Flash” offers valuable insights into the efficient inference techniques and memory management innovations in large language models.
Introduction
Large language models (LLMs) have become increasingly central to natural language processing (NLP), enabling advanced AI capabilities like text generation, translation, and sentiment analysis. However, the computational and memory demands of these models pose significant challenges, especially for devices with limited DRAM capacity.
The item “LLM in a Flash” presents innovative techniques to tackle these challenges head-on, offering a path to significantly faster and more efficient LLM inference on resource-constrained devices. By optimizing memory usage, leveraging sparsity, and implementing memory management innovations, these techniques enable the operation of larger models on devices with limited memory, such as edge devices, making them ideal for use in various apps and interfaces across platforms.
In this blog, we will delve into memory constraints in deep learning, understand the significance of sparsity and temporal locality in maximizing efficiency, and examine innovative techniques for efficient LLM inference using GPUs. We will also address frequently asked questions related to LLM efficiency on devices with limited memory.
Understanding Memory Constraints in Deep Learning
Deep learning models, including large language models (LLMs), operate on the principles of neural networks, which are computational models inspired by the human brain. In deep learning, memory plays a crucial role in storing and accessing the model’s parameters, intermediate results, and input data.
Memory bandwidth, the rate at which data can be transferred between memory and the processing unit, is a critical factor in deep learning model inference. It determines the speed at which the model can access the required data for computations.
However, deep learning models, especially LLMs with billions of parameters, can exceed the memory bandwidth capabilities of devices, leading to performance bottlenecks and slower inference times. The size of the model, precision of data storage, input data size, and hardware limitations all contribute to memory bandwidth requirements.
Memory limitations, especially in devices with limited DRAM capacity, present significant challenges in running LLMs efficiently. The computational and memory demands of LLMs pose unique challenges that require innovative techniques to optimize memory usage and improve inference performance.
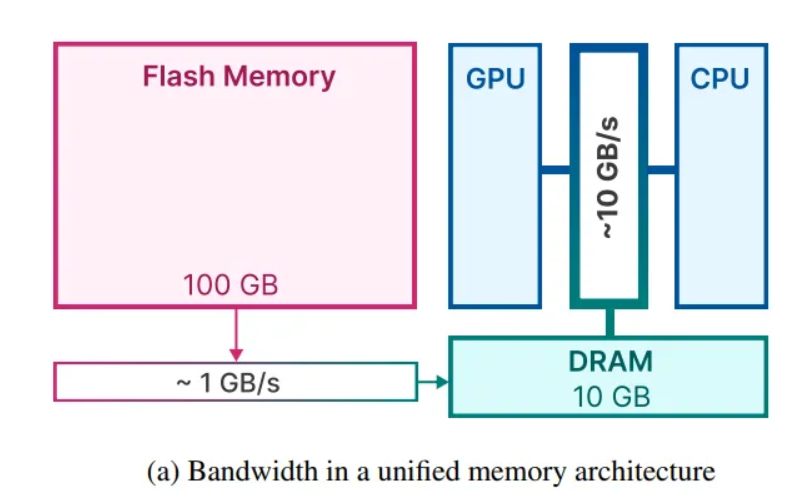
Memory Bandwidth and Its Impact on LLM Performance
Memory bandwidth is a crucial factor in determining the performance of large language models (LLMs) during inference. It refers to the rate at which data can be transferred between memory and the processing unit, influencing the speed and efficiency of computations.
The memory bandwidth requirements of LLMs depend on various factors, including the size of the model, precision of data storage, input data size, and hardware limitations. LLMs with larger model sizes and higher precision data storage typically require higher memory bandwidth to perform computations efficiently.
Limited memory bandwidth can result in performance bottlenecks and slower inference times, impacting the overall efficiency of LLM-based applications. Efficient data transfer between memory and the processing unit is critical for optimizing LLM performance and achieving faster inference times.
Strategies for Overcoming Memory Limitations
To overcome memory limitations and optimize memory usage in deep learning, including large language models (LLMs), several strategies can be employed. These strategies aim to maximize memory efficiency and improve inference performance on devices with limited memory capacity. Some effective strategies include:
- Model Pruning: Removing redundant parameters from the LLM, reducing the memory footprint without compromising performance.
- Quantization: Representing model parameters using fewer bits, reducing memory requirements while maintaining inference accuracy.
- Dynamic Computation Offloading: Offloading computations to external resources or distributing them across multiple devices to reduce memory load.
- Memory Refresh Techniques: Managing memory by deleting outdated or irrelevant data and incorporating new relevant data efficiently.
These strategies, when combined with innovative techniques such as windowing and row-column bundling, offer efficient solutions to overcome memory limitations in LLM inference. By optimizing memory usage, these strategies enable the deployment of larger models on devices with restricted memory, improving inference speed and efficiency.
Innovative Techniques for Efficient LLM Inference
Efficient large language model (LLM) inference techniques have been developed to overcome memory limitations and optimize inference performance on devices with limited memory capacity. These techniques leverage innovative strategies to reduce memory requirements, improve data transfer efficiency, and enhance overall inference speed.
Model Pruning and Quantization for Size Reduction
Model pruning and quantization are effective techniques for reducing the size of large language models (LLMs) and optimizing memory usage during inference. These techniques focus on removing unnecessary parameters and reducing the precision of parameter storage, respectively.
Model pruning involves identifying and removing redundant or unimportant parameters from the LLM. By eliminating these parameters, the model’s memory footprint is reduced, enabling more efficient memory utilization and faster inference times. Pruned models can achieve significant size reduction without sacrificing performance.
Quantization, on the other hand, involves representing model parameters using fewer bits. By reducing the precision of parameter storage, the memory requirements of the LLM are further minimized. Quantized models can achieve substantial size reduction while maintaining inference accuracy.
These techniques, when applied in combination with other memory management strategies, enable the deployment of larger LLMs on devices with limited memory. By reducing the memory footprint and optimizing memory usage, model pruning and quantization contribute to more efficient LLM inference on resource-constrained devices.
Dynamic Computation Offloading to Optimize Memory Usage
Dynamic computation offloading is an innovative technique used to optimize memory usage and improve inference performance in large language models (LLMs) on devices with limited memory. This technique involves offloading computations to external resources or distributing them across multiple devices.
By offloading computations, the memory load on the device is reduced, enabling more efficient memory usage and enhancing inference speed. Computation offloading can be performed in real-time, dynamically adjusting the allocation of computational resources based on the specific requirements of the inference task.
By strategically distributing computations and utilizing dynamic computation offloading, the memory requirements of the LLM can be minimized, and the overall efficiency of the inference process can be improved. This technique enables the deployment of larger models on devices with limited memory, such as a CPU, expanding the capabilities of LLM-based applications and making them more accessible on resource-constrained devices for machine learning.
Temporal Locality and Its Role in Maximizing Efficiency
Temporal locality plays a crucial role in maximizing the efficiency of large language models (LLMs) during inference. Temporal locality refers to the property that recent data is more likely to be accessed again in the near future than older data.
In the context of LLM inference, temporal locality means that recent tokens or words in a sequence are more predictive of what comes next. By leveraging temporal locality, LLMs can optimize memory usage by loading and retaining only the necessary data for inference.
The Concept of Temporal Locality in Data Access
Temporal locality, in the context of large language models (LLMs), refers to the property that recent data is more likely to be accessed again in the near future than older data. This concept is based on the observation that the words or tokens in a sequence of text are often highly correlated with each other.
In LLM inference, the concept of temporal locality is leveraged to optimize memory usage and improve memory efficiency. By focusing on recent tokens and reusing activations from previously computed tokens, LLMs can minimize the amount of data that needs to be loaded and processed during inference.
The efficient utilization of temporal locality results in improved memory efficiency and faster inference times. By loading only the necessary data and disregarding irrelevant information, LLMs can maximize the utilization of limited memory resources and enhance the overall efficiency of the inference process.
The concept of temporal locality is a fundamental principle in optimizing memory usage in LLMs and plays a crucial role in achieving efficient inference on devices with limited memory.
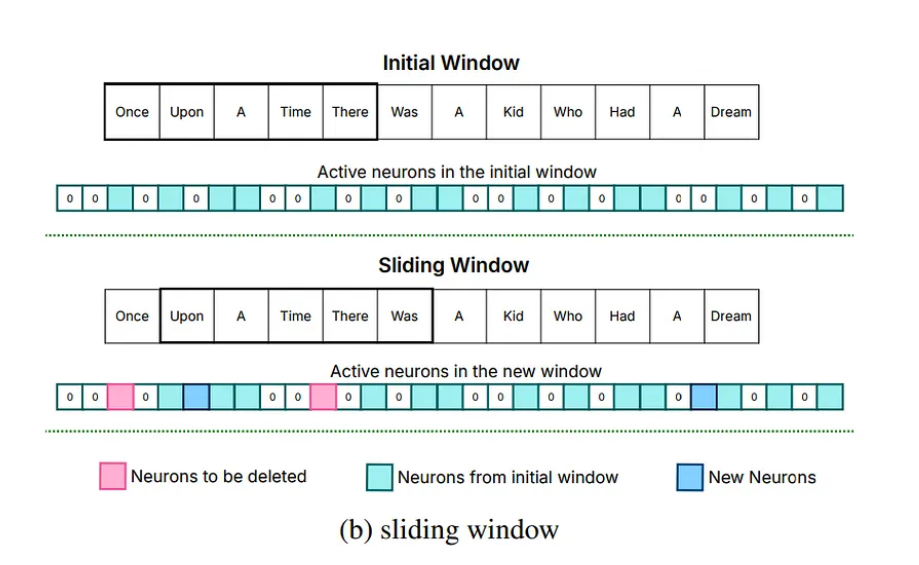
Implementing Temporal Locality in LLM Inference Processes
The implementation of temporal locality in large language model (LLM) inference processes involves strategies to efficiently access and utilize data based on its recency and relevance. By focusing on recent tokens and reusing activations from previously computed tokens, LLMs can optimize memory usage and improve memory efficiency.
In practice, the implementation of temporal locality in LLM inference involves techniques like windowing. Windowing involves loading parameters only for recent tokens and retaining activations from recently computed tokens. By keeping track of active neurons for a limited number of past tokens, only a minimal amount of data needs to be changed during inference.
This approach significantly reduces the data transfer volume and optimizes memory usage, leading to faster inference times and more efficient use of memory. By implementing temporal locality, LLMs can enhance their memory efficiency, enabling more effective inference on devices with limited memory capacity.
The implementation of temporal locality in LLM inference processes is a critical factor in maximizing efficiency and improving the overall performance of language-based AI applications.
The Significance of Sparsity in LLMs
Sparsity plays a significant role in optimizing memory efficiency in large language models (LLMs). Sparsity refers to the property that a large portion of the model’s parameters are zeros, resulting in a sparse representation.
In LLMs, sparsity is particularly prevalent in fully connected layers, such as feed-forward neural (FFN) layers, where a significant number of parameters are often zeros. By leveraging the sparsity of LLMs, memory usage can be optimized, and memory requirements can be reduced.
Sparsity in LLMs allows for more efficient storage and computation by focusing only on the non-zero elements. By ignoring the zero-valued parameters, the memory footprint of the LLM is significantly reduced, leading to more efficient memory utilization and faster inference times.
Leveraging Sparsity for Memory Efficiency
Leveraging sparsity in large language models (LLMs) is a key strategy for optimizing memory efficiency during inference. Sparsity refers to the property that a large portion of the model’s parameters are zeros, resulting in a sparse representation.
By focusing only on the non-zero elements, LLMs can reduce memory requirements and improve memory efficiency. The zeros in the model can be ignored during computations, leading to more efficient memory utilization and faster inference times.
Techniques for Anticipating and Utilizing ReLU Sparsity
The sparsity induced by the ReLU (Rectified Linear Unit) activation function in large language models (LLMs) can be effectively utilized to optimize memory efficiency and improve inference performance. ReLU zeros out negative inputs, leading to a significant reduction in the number of active neurons and, consequently, the amount of data that needs to be loaded and processed during inference.
Techniques for anticipating and utilizing ReLU sparsity involve predicting which neurons will remain active after the ReLU operation. By employing a low-rank predictor, the LLM can anticipate which neurons will contribute to the inference outcome and load only those active neurons from memory.
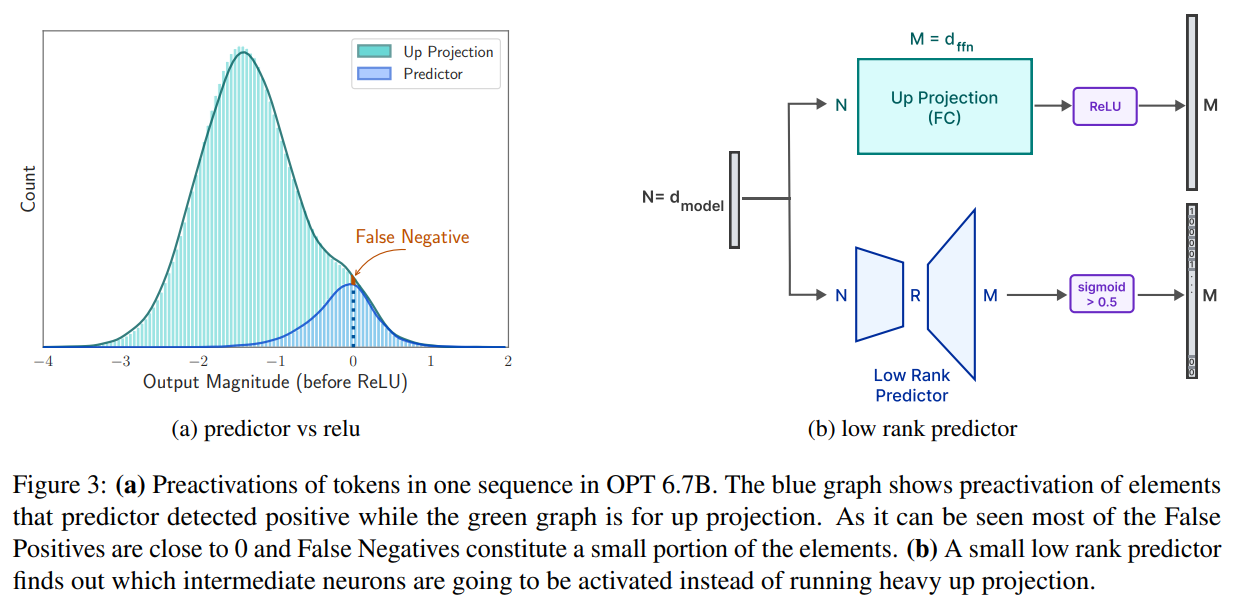
This anticipation-based approach significantly enhances memory efficiency and processing speed by proactively determining and loading only the necessary data. By leveraging ReLU sparsity, LLMs can optimize memory usage and improve inference performance on devices with limited memory.
The techniques for anticipating and utilizing ReLU sparsity complement other memory management strategies, such as windowing and dynamic computation offloading, enabling more efficient and effective LLM inference on resource-constrained devices.
Memory Management Innovations in LLMs
Memory management innovations in large language models (LLMs) address the challenges of efficiently utilizing memory resources and optimizing inference performance on devices with limited memory. These innovations involve strategies for managing memory allocation, data deletion, and renewal during the inference process.
One innovation is the use of deletion and renewal strategies to manage memory efficiently. During inference, outdated or irrelevant data is deleted to free up memory space for relevant information. By minimizing the need for rewriting existing data, these strategies accelerate the inference process and improve memory utilization.
Another innovation is memory refresh techniques, which involve bringing in new, relevant data from flash memory into dynamic random-access memory (DRAM). This process is optimized to reduce latency and avoid frequent memory reallocation, enabling the model to adapt quickly to new information with minimal delays.
These innovations, combined with other techniques such as sparsity leveraging, dynamic computation offloading, and model pruning, contribute to the efficient operation of LLMs on devices with limited memory. By optimizing memory usage and implementing innovative memory management strategies, LLMs can deliver enhanced inference speed and more effective language-based AI applications.
Streamlining Memory with Deletion and Renewal Strategies
Streamlining memory with deletion and renewal strategies is a memory management innovation in large language models (LLMs) that optimizes memory usage during inference. This strategy involves efficiently managing memory by deleting outdated or irrelevant data and incorporating new relevant data.
During inference, the model dynamically discards outdated or irrelevant data to make more memory space available for current tasks. This process, known as “deleting neurons,” efficiently removes unnecessary data from dynamic random-access memory (DRAM), freeing up space for relevant information.
Here is an example of novita.ai LLM model(API Offered ) strategies(Renewal):
Orchestrating Efficient Inference Through Memory Refresh Techniques
Efficient inference in large language models (LLMs) is achieved through the orchestration of memory refresh techniques, a memory management innovation that optimizes memory utilization during inference. Memory refresh techniques involve bringing in new, relevant data from flash memory into dynamic random-access memory (DRAM).
The orchestration of memory refresh techniques ensures smooth and efficient inference, balancing the allocation and utilization of memory resources. By optimizing memory usage, LLMs can deliver faster inference times, improved overall performance, and more efficient utilization of available memory.
Enhancing Throughput with Row-Column Bundling
Enhancing throughput in large language models (LLMs) can be achieved through the innovative technique of row-column bundling. Row-column bundling improves the efficiency of data processing and increases the throughput of LLM inference.
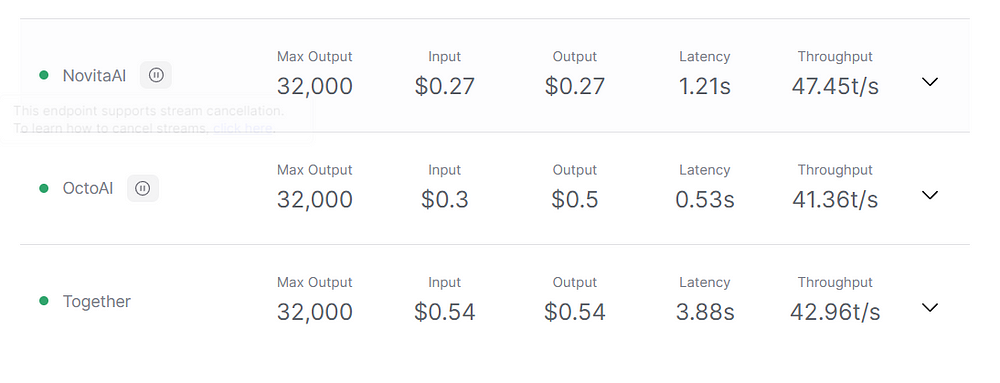
Row-column bundling involves storing related data, such as rows and columns from specific layers, together in memory. This technique allows for larger and more contiguous chunks of data to be read simultaneously, reducing the number of individual read operations and improving data access throughput.
By bundling data in larger chunks, row-column bundling enhances throughput, making the operation of LLMs smoother and faster. This technique aligns with the sequential reading capabilities of flash memory, which is commonly used for storing LLM parameters.
The Mechanics of Row-Column Bundling
The mechanics of row-column bundling in large language models (LLMs) involve storing related data, such as rows and columns from specific layers, together in memory. This technique improves data access throughput and enhances the efficiency of LLM inference.
By storing a concatenated row and column of the up-projection and down-projection layers together, the size of data chunks read from memory is increased. This strategy reduces the number of individual read operations required, improving data access throughput and enhancing overall processing speed.
Benefits of Chunk-Based Processing in LLMs
Chunk-based processing in large language models (LLMs) offers several benefits, enhancing the efficiency and performance of LLM inference. Chunk-based processing involves processing data in larger chunks, optimizing data access and improving overall processing speed.
The benefits of chunk-based processing in LLMs include:
- Increased Throughput: By processing data in larger chunks, chunk-based processing improves data access throughput, reducing processing time and enhancing overall throughput.
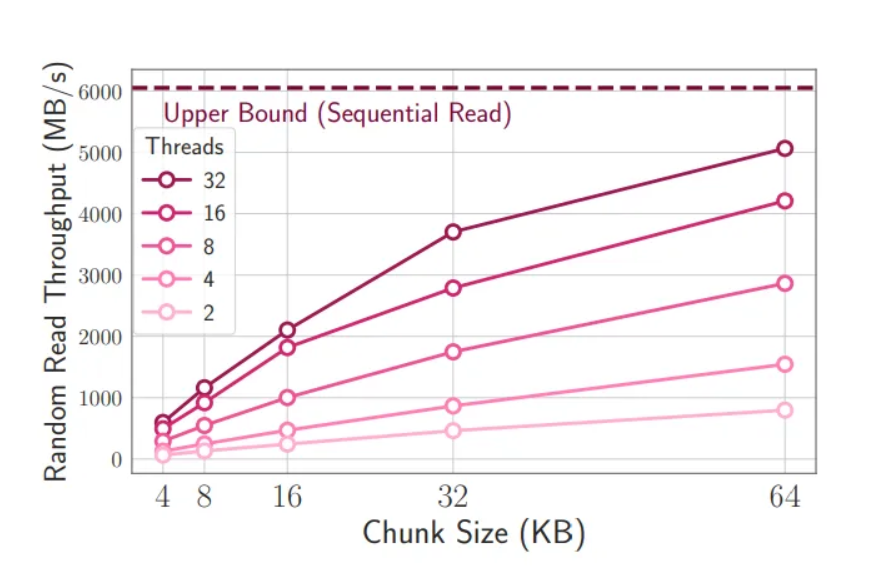
- Reduced Overhead: Chunk-based processing minimizes the overhead associated with individual read operations, improving overall efficiency and reducing computational costs.
- Improved Memory Utilization: By optimizing data access and reducing the need for frequent data transfers, chunk-based processing improves memory utilization, enabling more efficient use of available memory resources.
By leveraging the benefits of chunk-based processing, LLMs achieve faster processing times, enhanced throughput, and improved overall performance. This technique complements other memory management and optimization strategies, such as row-column bundling and memory refresh techniques, contributing to the efficient operation of LLMs on devices with limited memory.
Conclusion
In conclusion, efficient inference techniques with limited memory are crucial for optimizing the performance of Large Language Models (LLMs). Overcoming memory constraints through strategies like model pruning, quantization, and dynamic computation offloading is essential. Leveraging concepts such as temporal locality, sparsity, and innovative memory management techniques can significantly enhance LLM efficiency. By streamlining memory usage and enhancing throughput with row-column bundling, LLMs can achieve high performance even with limited memory resources. Understanding and implementing these techniques are key to maximizing the effectiveness of LLM inference processes.

Frequently Asked Questions
How Do LLMs Operate Efficiently on Devices with Limited Memory?
LLMs operate efficiently on devices with limited memory by employing innovative techniques such as model pruning, dynamic computation offloading, and memory management strategies.
Can LLM Inference Speed Be Improved Without Compromising Accuracy?
Yes, the inference speed of LLMs can be improved without compromising accuracy. The techniques of windowing and row-column bundling optimize the data transfer and memory access, resulting in faster inference times.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
LLM Leaderboard 2024 Predictions Revealed
Unlock the Power of Janitor LLM: Exploring Guide-By-Guide
TOP LLMs for 2024: How to Evaluate and Improve An Open Source LLM