Integrating Hugging Face Embeddings with LlamaIndex: A Developer's Guide

Key Highlights
- Module Overview: llama_index.embeddings.huggingface bridges LlamaIndex and Hugging Face models for tailored embeddings.
- Installation and Setup: 1. Install the package via pip. 2. Configure the module in Python. 3. Instantiate the embedding model. 4. Test with sample text.
- Choosing the Right Model: Importance of selecting models based on language and task, considering performance and resources.
- Code Examples: Demonstrates basic embedding generation, custom models, batch processing, and vector index integration.
- Optimization Tips: Efficient models, batch processing, chunk size adjustment, resource allocation, caching, and system monitoring.
- LLM API Integration: Steps to integrate with Novita AI’s LLM API for advanced NLP tasks.
Introduction
Integrating Hugging Face embeddings with LlamaIndex opens up a world of possibilities for developers working on advanced natural language processing tasks. By leveraging the power of Hugging Face’s diverse and state-of-the-art models within the LlamaIndex framework, developers can create robust, efficient, and highly accurate Retrieval-Augmented Generation (RAG) systems tailored to specific languages and domains. This guide will walk you through the process of setting up and using Hugging Face embeddings with LlamaIndex, providing you with practical insights and code examples to optimize your NLP projects.
What Is llama_index_embedding_huggingface?
The llama_index.embeddings.huggingface module serves as a bridge between LlamaIndex and the rich ecosystem of Hugging Face models. By leveraging this module, you can select from a variety of state-of-the-art embedding models, tailoring their RAG systems to specific languages, domains, or performance requirements.
Installation and Setup
Step 1: Installation
- Begin by ensuring you have Python and pip installed on your system.
- Open your terminal or command prompt and install the
llama_index_embedding_huggingfacepackage using pip:
pip install llama_index_embedding_huggingfaceStep 2: Configuration
- Once installed, you need to import the module into your Python script:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding- Decide on the Hugging Face embedding model that best suits your needs. Consider factors such as language support, model size, and performance.
Step 3: Setting Up the Module
- Instantiate the
HuggingFaceEmbeddingclass with the model name you've chosen:
embedding_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")- This setup is ready to be integrated into your RAG pipeline, where it will be used to convert textual data into embeddings.
Step 4: First Use
- With the embedding model ready, you can now proceed to integrate it with the rest of your LlamaIndex components, such as the document loader and vector index.
- Test the setup with a sample text to ensure that the embeddings are generated as expected:
sample_text = "Hello, world of RAG systems!"
embeddings = embedding_model.get_text_embedding(sample_text)
print(embeddings)For more info about RAG project with Huggingface and LlamaIndex, you can check out this blog: Building A RAG Ebook “Librarian” Using LlamaIndex.
Choosing the Right Embedding Model
Selecting the right embedding model is pivotal to the performance of your RAG system. Embeddings are the core through which your data is understood and retrieved by the system. The choice of model can affect the accuracy, relevance, and efficiency of your retrieval operations.
Exploring Available Models
Hugging Face provides a plethora of models, each with its unique characteristics. To explore available models, you can visit the Hugging Face Model Hub. Use filters to narrow down models by language, task, or dataset. Pay attention to community feedback, performance benchmarks, and the model’s compatibility with your system’s requirements.
Selecting Based on Language and Task
Your choice should be guided by the language of your data and the specific tasks your RAG system is designed to perform. For instance, if your application deals with medical literature, you might prefer a model fine-tuned for medical text. Similarly, for a multilingual application, a model that supports multiple languages would be ideal.
Performance Considerations
Consider the trade-off between the model’s size and its performance. Larger models may provide more detailed embeddings but at the cost of increased computational resources and latency.
Usage Examples in Code
Now that you have selected an appropriate model, it’s time to put it to use. Below are detailed code examples that demonstrate how to generate text embeddings using the llama_index.embeddings.huggingface module.
Basic Embedding Generation:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# Initialize the embedding model
embedding_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
# Text to embed
text = "This is a sample text for embedding."
# Generate embedding
embedding = embedding_model.get_text_embedding(text)
print(embedding)Embedding with Custom Model:
# Initialize with a different model
custom_embedding_model = HuggingFaceEmbedding(model_name="YourCustomModelName")
# Generate embedding using the custom model
custom_embedding = custom_embedding_model.get_text_embedding(text)Batch Embedding Generation:
# List of texts
texts = ["text1", "text2", "text3", ...]
# Generate embeddings for all texts
embeddings = embedding_model.get_text_embedding(texts)Tailoring to Specific Needs:
# Customize embedding generation
embeddings = embedding_model.get_text_embedding(text, max_length=512)Integration with Vector Index:
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
# Load documents
documents = SimpleDirectoryReader("./data").load_data()
# Create vector store index
index = VectorStoreIndex.from_documents(documents, embed_model=embedding_model)
# Now, `index` can be used for efficient retrieval operationsTips for Optimizing Generation of Embeddings
Tip 1: Select Efficient Models
Choose embedding models that balance accuracy with speed. Larger models may offer better performance but at the cost of increased computation time.
Tip 2: Batch Processing
Utilize batch processing capabilities of the llama_index.embeddings.huggingface module to generate embeddings for multiple texts in a single operation, reducing the overhead of repeated setup and tear down.
Tip 3: Adjust Chunk Size
Fine-tune the chunk size and overlap during the indexing phase to optimize the granularity of embeddings. A smaller chunk size can lead to more precise embeddings but may increase computation time.
Tip 4: Resource Allocation
Ensure that your system has adequate resources (CPU/GPU, memory) to handle the embedding generation process, especially when using complex models. Novita AI GPU Instance offers a cost-effective and pay-as-you-go GPU cloud to scale your innovations.
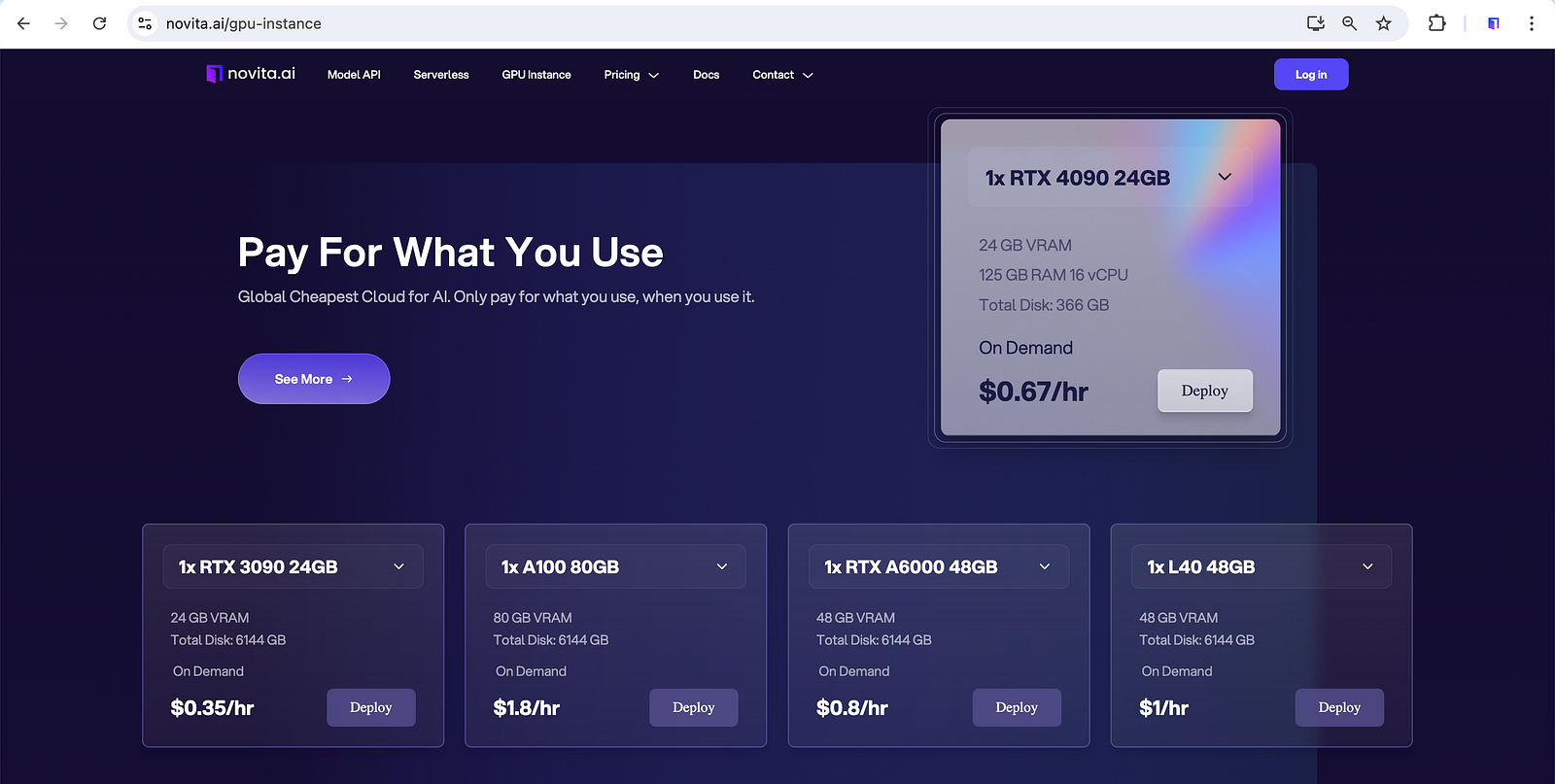
Moreover, Novita AI GPU Instance has instant access to Jupyter, pre-installed with Tensorflow, Pytorch, cuDNN, CUDA, TensorRT, Llama3 and Stable Diffusion. Novita AI enables access to GPU cloud services directly through your browser.
Tip 5: Caching Mechanisms
Implement caching strategies to store previously generated embeddings, avoiding redundant computations for texts that have already been processed.
Tip 6: Monitor System Load
Keep an eye on the system load and optimize the number of concurrent operations to prevent system overload and ensure consistent performance.
Integration with LLM API
Integrating LLM with an embedding module like llama_index.embeddings.huggingface offers significant advantages for natural language processing tasks. This integration enables the creation of highly efficient and accurate Retrieval-Augmented Generation (RAG) systems by leveraging state-of-the-art embeddings that capture the semantic nuances of text. Here’s a step-by-step guide to integrate with Novita AI’s LLM API:
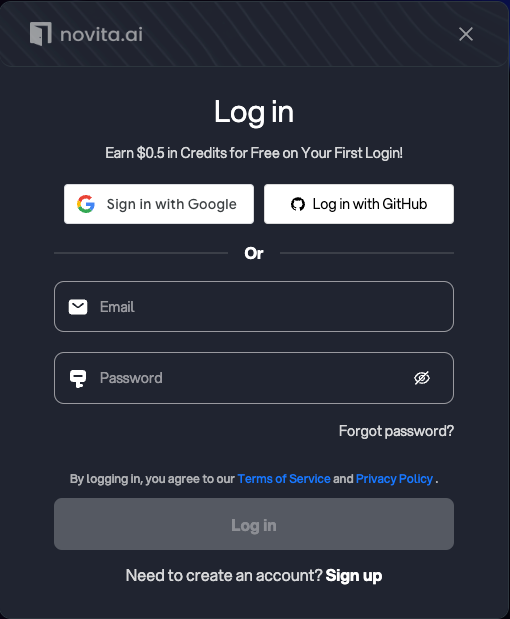
1. Go to novita.ai and log in
You can log in with Google or GitHub. A new account will be created on your first login.
Alternatively, you can sign up using your email address.
2. Manage API Key
Novita AI authenticates API access using Bearer authentication with an API Key in the request header, e.g. “Authorization: Bearer {API Key}”.
Go to “Key Management” in settings to manage your keys.
On your first login, a default key is created automatically. You can create additional keys by clicking “+ Add new key”.

3. Make API call
Here's an example with python client using Novita AI Chat Completions API.
pip install 'openai>=1.0.0'
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "Nous-Hermes-2-Mixtral-8x7B-DPO"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)For more info, please check Novita AI Model API Reference.
4. Top up credit
We offer new users a voucher with some credit to try our products. To add more credit, please visit Billing and Payments and follow the guide on Payment Methods.
Conclusion
Integrating Hugging Face embeddings with LlamaIndex significantly enhances the capabilities of your RAG systems, providing a robust framework for handling complex NLP tasks. By following the steps outlined in this guide, you can seamlessly set up and configure your embedding models, select the most suitable models for your needs, and optimize performance through various tips and best practices.
FAQs
[Bug]: No module named ‘llama_index.embeddings.huggingface’
Run pip install llama-index-embeddings-huggingface
[Bug]: Loading embedding model form Hugging Face in Llama Index throws up an attribute error
Check for your torch version !python -c “import torch; print(torch.version)”. Downgrading it may work: !python -m pip install — upgrade torch==1.13.0
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading
What is RAG: A Comprehensive Introduction to Retrieval Augmented Generation
Step-by-Step Tutorial on Integrating Retrieval-Augmented Generation (RAG) with Large Language Models
Choosing Between LlamaIndex and LangChain: A Comprehensive Guide